 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Sparse Odometry with Continuous 3D Gaussian Maps for Indoor Environments
Mar 05, 2025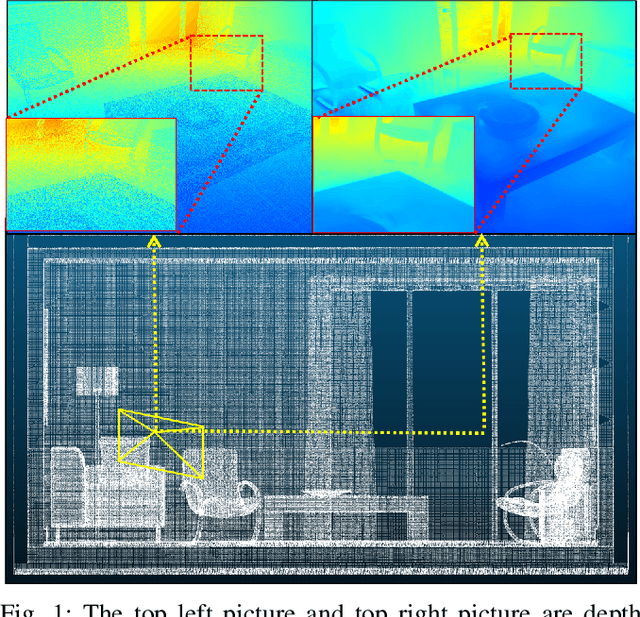
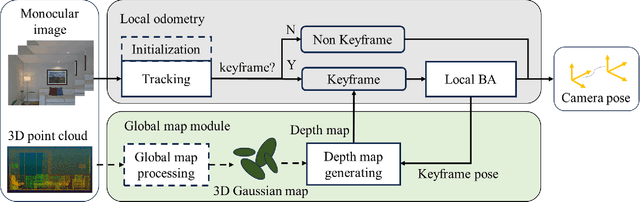
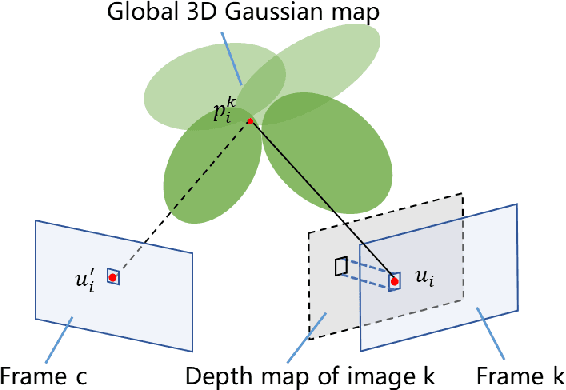
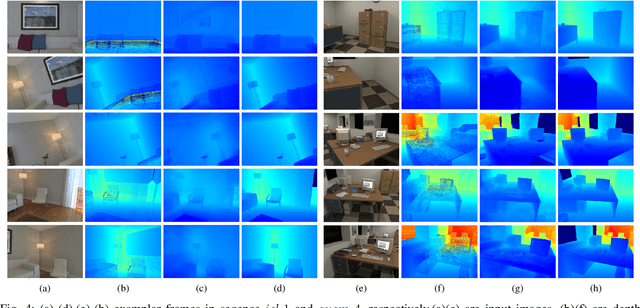
Accurate localization is essential for robotics and augmented reality applications such as autonomous navigation. Vision-based methods combining prior maps aim to integrate LiDAR-level accuracy with camera cost efficiency for robust pose estimation. Existing approaches, however, often depend on unreliable interpolation procedures when associating discrete point cloud maps with dense image pixels, which inevitably introduces depth errors and degrades pose estimation accuracy. We propose a monocular visual odometry framework utilizing a continuous 3D Gaussian map, which directly assigns geometrically consistent depth values to all extracted high-gradient points without interpolation. Evaluations on two public datasets demonstrate superior tracking accuracy compared to existing methods. We have released the source code of this work for the development of the community.
SVDC: Consistent Direct Time-of-Flight Video Depth Completion with Frequency Selective Fusion
Mar 03, 2025Lightweight direct Time-of-Flight (dToF) sensors are ideal for 3D sensing on mobile devices. However, due to the manufacturing constraints of compact devices and the inherent physical principles of imaging, dToF depth maps are sparse and noisy. In this paper, we propose a novel video depth completion method, called SVDC, by fusing the sparse dToF data with the corresponding RGB guidance. Our method employs a multi-frame fusion scheme to mitigate the spatial ambiguity resulting from the sparse dToF imaging. Misalignment between consecutive frames during multi-frame fusion could cause blending between object edges and the background, which results in a loss of detail. To address this, we introduce an adaptive frequency selective fusion (AFSF) module, which automatically selects convolution kernel sizes to fuse multi-frame features. Our AFSF utilizes a channel-spatial enhancement attention (CSEA) module to enhance features and generates an attention map as fusion weights. The AFSF ensures edge detail recovery while suppressing high-frequency noise in smooth regions. To further enhance temporal consistency, We propose a cross-window consistency loss to ensure consistent predictions across different windows, effectively reducing flickering. Our proposed SVDC achieves optimal accuracy and consistency on the TartanAir and Dynamic Replica datasets. Code is available at https://github.com/Lan1eve/SVDC.
Kiss3DGen: Repurposing Image Diffusion Models for 3D Asset Generation
Mar 03, 2025Diffusion models have achieved great success in generating 2D images. However, the quality and generalizability of 3D content generation remain limited. State-of-the-art methods often require large-scale 3D assets for training, which are challenging to collect. In this work, we introduce Kiss3DGen (Keep It Simple and Straightforward in 3D Generation), an efficient framework for generating, editing, and enhancing 3D objects by repurposing a well-trained 2D image diffusion model for 3D generation. Specifically, we fine-tune a diffusion model to generate ''3D Bundle Image'', a tiled representation composed of multi-view images and their corresponding normal maps. The normal maps are then used to reconstruct a 3D mesh, and the multi-view images provide texture mapping, resulting in a complete 3D model. This simple method effectively transforms the 3D generation problem into a 2D image generation task, maximizing the utilization of knowledge in pretrained diffusion models. Furthermore, we demonstrate that our Kiss3DGen model is compatible with various diffusion model techniques, enabling advanced features such as 3D editing, mesh and texture enhancement, etc. Through extensive experiments, we demonstrate the effectiveness of our approach, showcasing its ability to produce high-quality 3D models efficiently.
Improving Open-world Continual Learning under the Constraints of Scarce Labeled Data
Feb 28, 2025



Open-world continual learning (OWCL) adapts to sequential tasks with open samples, learning knowledge incrementally while preventing forgetting. However, existing OWCL still requires a large amount of labeled data for training, which is often impractical in real-world applications. Given that new categories/entities typically come with limited annotations and are in small quantities, a more realistic situation is OWCL with scarce labeled data, i.e., few-shot training samples. Hence, this paper investigates the problem of open-world few-shot continual learning (OFCL), challenging in (i) learning unbounded tasks without forgetting previous knowledge and avoiding overfitting, (ii) constructing compact decision boundaries for open detection with limited labeled data, and (iii) transferring knowledge about knowns and unknowns and even update the unknowns to knowns once the labels of open samples are learned. In response, we propose a novel OFCL framework that integrates three key components: (1) an instance-wise token augmentation (ITA) that represents and enriches sample representations with additional knowledge, (2) a margin-based open boundary (MOB) that supports open detection with new tasks emerge over time, and (3) an adaptive knowledge space (AKS) that endows unknowns with knowledge for the updating from unknowns to knowns. Finally, extensive experiments show the proposed OFCL framework outperforms all baselines remarkably with practical importance and reproducibility. The source code is released at https://github.com/liyj1201/OFCL.
Order-Robust Class Incremental Learning: Graph-Driven Dynamic Similarity Grouping
Feb 27, 2025Class Incremental Learning (CIL) requires a model to continuously learn new classes without forgetting previously learned ones. While recent studies have significantly alleviated the problem of catastrophic forgetting (CF), more and more research reveals that the order in which classes appear have significant influences on CIL models. Specifically, prioritizing the learning of classes with lower similarity will enhance the model's generalization performance and its ability to mitigate forgetting. Hence, it is imperative to develop an order-robust class incremental learning model that maintains stable performance even when faced with varying levels of class similarity in different orders. In response, we first provide additional theoretical analysis, which reveals that when the similarity among a group of classes is lower, the model demonstrates increased robustness to the class order. Then, we introduce a novel \textbf{G}raph-\textbf{D}riven \textbf{D}ynamic \textbf{S}imilarity \textbf{G}rouping (\textbf{GDDSG}) method, which leverages a graph coloring algorithm for class-based similarity grouping. The proposed approach trains independent CIL models for each group of classes, ultimately combining these models to facilitate joint prediction. Experimental results demonstrate that our method effectively addresses the issue of class order sensitivity while achieving optimal performance in both model accuracy and anti-forgetting capability. Our code is available at https://github.com/AIGNLAI/GDDSG.
Exploring Open-world Continual Learning with Knowns-Unknowns Knowledge Transfer
Feb 27, 2025



Open-World Continual Learning (OWCL) is a challenging paradigm where models must incrementally learn new knowledge without forgetting while operating under an open-world assumption. This requires handling incomplete training data and recognizing unknown samples during inference. However, existing OWCL methods often treat open detection and continual learning as separate tasks, limiting their ability to integrate open-set detection and incremental classification in OWCL. Moreover, current approaches primarily focus on transferring knowledge from known samples, neglecting the insights derived from unknown/open samples. To address these limitations, we formalize four distinct OWCL scenarios and conduct comprehensive empirical experiments to explore potential challenges in OWCL. Our findings reveal a significant interplay between the open detection of unknowns and incremental classification of knowns, challenging a widely held assumption that unknown detection and known classification are orthogonal processes. Building on our insights, we propose \textbf{HoliTrans} (Holistic Knowns-Unknowns Knowledge Transfer), a novel OWCL framework that integrates nonlinear random projection (NRP) to create a more linearly separable embedding space and distribution-aware prototypes (DAPs) to construct an adaptive knowledge space. Particularly, our HoliTrans effectively supports knowledge transfer for both known and unknown samples while dynamically updating representations of open samples during OWCL. Extensive experiments across various OWCL scenarios demonstrate that HoliTrans outperforms 22 competitive baselines, bridging the gap between OWCL theory and practice and providing a robust, scalable framework for advancing open-world learning paradigms.
Enhancing Audio-Visual Spiking Neural Networks through Semantic-Alignment and Cross-Modal Residual Learning
Feb 18, 2025Humans interpret and perceive the world by integrating sensory information from multiple modalities, such as vision and hearing. Spiking Neural Networks (SNNs), as brain-inspired computational models, exhibit unique advantages in emulating the brain's information processing mechanisms. However, existing SNN models primarily focus on unimodal processing and lack efficient cross-modal information fusion, thereby limiting their effectiveness in real-world multimodal scenarios. To address this challenge, we propose a semantic-alignment cross-modal residual learning (S-CMRL) framework, a Transformer-based multimodal SNN architecture designed for effective audio-visual integration. S-CMRL leverages a spatiotemporal spiking attention mechanism to extract complementary features across modalities, and incorporates a cross-modal residual learning strategy to enhance feature integration. Additionally, a semantic alignment optimization mechanism is introduced to align cross-modal features within a shared semantic space, improving their consistency and complementarity. Extensive experiments on three benchmark datasets CREMA-D, UrbanSound8K-AV, and MNISTDVS-NTIDIGITS demonstrate that S-CMRL significantly outperforms existing multimodal SNN methods, achieving the state-of-the-art performance. The code is publicly available at https://github.com/Brain-Cog-Lab/S-CMRL.
StereoGen: High-quality Stereo Image Generation from a Single Image
Jan 15, 2025State-of-the-art supervised stereo matching methods have achieved amazing results on various benchmarks. However, these data-driven methods suffer from generalization to real-world scenarios due to the lack of real-world annotated data. In this paper, we propose StereoGen, a novel pipeline for high-quality stereo image generation. This pipeline utilizes arbitrary single images as left images and pseudo disparities generated by a monocular depth estimation model to synthesize high-quality corresponding right images. Unlike previous methods that fill the occluded area in warped right images using random backgrounds or using convolutions to take nearby pixels selectively, we fine-tune a diffusion inpainting model to recover the background. Images generated by our model possess better details and undamaged semantic structures. Besides, we propose Training-free Confidence Generation and Adaptive Disparity Selection. The former suppresses the negative effect of harmful pseudo ground truth during stereo training, while the latter helps generate a wider disparity distribution and better synthetic images. Experiments show that models trained under our pipeline achieve state-of-the-art zero-shot generalization results among all published methods. The code will be available upon publication of the paper.
MonSter: Marry Monodepth to Stereo Unleashes Power
Jan 15, 2025Stereo matching recovers depth from image correspondences. Existing methods struggle to handle ill-posed regions with limited matching cues, such as occlusions and textureless areas. To address this, we propose MonSter, a novel method that leverages the complementary strengths of monocular depth estimation and stereo matching. MonSter integrates monocular depth and stereo matching into a dual-branch architecture to iteratively improve each other. Confidence-based guidance adaptively selects reliable stereo cues for monodepth scale-shift recovery. The refined monodepth is in turn guides stereo effectively at ill-posed regions. Such iterative mutual enhancement enables MonSter to evolve monodepth priors from coarse object-level structures to pixel-level geometry, fully unlocking the potential of stereo matching. As shown in Fig.1, MonSter ranks 1st across five most commonly used leaderboards -- SceneFlow, KITTI 2012, KITTI 2015, Middlebury, and ETH3D. Achieving up to 49.5% improvements (Bad 1.0 on ETH3D) over the previous best method. Comprehensive analysis verifies the effectiveness of MonSter in ill-posed regions. In terms of zero-shot generalization, MonSter significantly and consistently outperforms state-of-the-art across the board. The code is publicly available at: https://github.com/Junda24/MonSter.
A New Perspective on Privacy Protection in Federated Learning with Granular-Ball Computing
Jan 09, 2025Federated Learning (FL) facilitates collaborative model training while prioritizing privacy by avoiding direct data sharing. However, most existing articles attempt to address challenges within the model's internal parameters and corresponding outputs, while neglecting to solve them at the input level. To address this gap, we propose a novel framework called Granular-Ball Federated Learning (GrBFL) for image classification. GrBFL diverges from traditional methods that rely on the finest-grained input data. Instead, it segments images into multiple regions with optimal coarse granularity, which are then reconstructed into a graph structure. We designed a two-dimensional binary search segmentation algorithm based on variance constraints for GrBFL, which effectively removes redundant information while preserving key representative features. Extensive theoretical analysis and experiments demonstrate that GrBFL not only safeguards privacy and enhances efficiency but also maintains robust utility, consistently outperforming other state-of-the-art FL methods. The code is available at https://github.com/AIGNLAI/GrBFL.