 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeadSculpt: Crafting 3D Head Avatars with Text
Jun 05, 2023Recently, text-guided 3D generative methods have made remarkable advancements in producing high-quality textures and geometry, capitalizing on the proliferation of large vision-language and image diffusion models. However, existing methods still struggle to create high-fidelity 3D head avatars in two aspects: (1) They rely mostly on a pre-trained text-to-image diffusion model whilst missing the necessary 3D awareness and head priors. This makes them prone to inconsistency and geometric distortions in the generated avatars. (2) They fall short in fine-grained editing. This is primarily due to the inherited limitations from the pre-trained 2D image diffusion models, which become more pronounced when it comes to 3D head avatars. In this work, we address these challenges by introducing a versatile coarse-to-fine pipeline dubbed HeadSculpt for crafting (i.e., generating and editing) 3D head avatars from textual prompts. Specifically, we first equip the diffusion model with 3D awareness by leveraging landmark-based control and a learned textual embedding representing the back view appearance of heads, enabling 3D-consistent head avatar generations. We further propose a novel identity-aware editing score distillation strategy to optimize a textured mesh with a high-resolution differentiable rendering technique. This enables identity preservation while following the editing instruction. We showcase HeadSculpt's superior fidelity and editing capabilities through comprehensive experiments and comparisons with existing methods.
DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion
Mar 27, 2023We propose a new formulation of temporal action detection (TAD) with denoising diffusion, DiffTAD in short. Taking as input random temporal proposals, it can yield action proposals accurately given an untrimmed long video. This presents a generative modeling perspective, against previous discriminative learning manners. This capability is achieved by first diffusing the ground-truth proposals to random ones (i.e., the forward/noising process) and then learning to reverse the noising process (i.e., the backward/denoising process). Concretely, we establish the denoising process in the Transformer decoder (e.g., DETR) by introducing a temporal location query design with faster convergence in training. We further propose a cross-step selective conditioning algorithm for inference acceleration. Extensive evaluations on ActivityNet and THUMOS show that our DiffTAD achieves top performance compared to previous art alternatives. The code will be made available at https://github.com/sauradip/DiffusionTAD.
Generative Semantic Segmentation
Mar 20, 2023We present Generative Semantic Segmentation (GSS), a generative learning approach for semantic segmentation. Uniquely, we cast semantic segmentation as an image-conditioned mask generation problem. This is achieved by replacing the conventional per-pixel discriminative learning with a latent prior learning process. Specifically, we model the variational posterior distribution of latent variables given the segmentation mask. To that end, the segmentation mask is expressed with a special type of image (dubbed as maskige). This posterior distribution allows to generate segmentation masks unconditionally. To achieve semantic segmentation on a given image, we further introduce a conditioning network. It is optimized by minimizing the divergence between the posterior distribution of maskige (i.e., segmentation masks) and the latent prior distribution of input training images. Extensive experiments on standard benchmarks show that our GSS can perform competitively to prior art alternatives in the standard semantic segmentation setting, whilst achieving a new state of the art in the more challenging cross-domain setting.
PersonalTailor: Personalizing 2D Pattern Design from 3D Garment Point Clouds
Mar 17, 2023



Garment pattern design aims to convert a 3D garment to the corresponding 2D panels and their sewing structure. Existing methods rely either on template fitting with heuristics and prior assumptions, or on model learning with complicated shape parameterization. Importantly, both approaches do not allow for personalization of the output garment, which today has increasing demands. To fill this demand, we introduce PersonalTailor: a personalized 2D pattern design method, where the user can input specific constraints or demands (in language or sketch) for personal 2D panel fabrication from 3D point clouds. PersonalTailor first learns a multi-modal panel embeddings based on unsupervised cross-modal association and attentive fusion. It then predicts a binary panel masks individually using a transformer encoder-decoder framework. Extensive experiments show that our PersonalTailor excels on both personalized and standard pattern fabrication tasks.
FAME-ViL: Multi-Tasking Vision-Language Model for Heterogeneous Fashion Tasks
Mar 04, 2023In the fashion domain, there exists a variety of vision-and-language (V+L) tasks, including cross-modal retrieval, text-guided image retrieval, multi-modal classification, and image captioning. They differ drastically in each individual input/output format and dataset size. It has been common to design a task-specific model and fine-tune it independently from a pre-trained V+L model (e.g., CLIP). This results in parameter inefficiency and inability to exploit inter-task relatedness. To address such issues, we propose a novel FAshion-focused Multi-task Efficient learning method for Vision-and-Language tasks (FAME-ViL) in this work. Compared with existing approaches, FAME-ViL applies a single model for multiple heterogeneous fashion tasks, therefore being much more parameter-efficient. It is enabled by two novel components: (1) a task-versatile architecture with cross-attention adapters and task-specific adapters integrated into a unified V+L model, and (2) a stable and effective multi-task training strategy that supports learning from heterogeneous data and prevents negative transfer. Extensive experiments on four fashion tasks show that our FAME-ViL can save 61.5% of parameters over alternatives, while significantly outperforming the conventional independently trained single-task models. Code is available at https://github.com/BrandonHanx/FAME-ViL.
Unsupervised Hashing via Similarity Distribution Calibration
Feb 15, 2023Existing unsupervised hashing methods typically adopt a feature similarity preservation paradigm. As a result, they overlook the intrinsic similarity capacity discrepancy between the continuous feature and discrete hash code spaces. Specifically, since the feature similarity distribution is intrinsically biased (e.g., moderately positive similarity scores on negative pairs), the hash code similarities of positive and negative pairs often become inseparable (i.e., the similarity collapse problem). To solve this problem, in this paper a novel Similarity Distribution Calibration (SDC) method is introduced. Instead of matching individual pairwise similarity scores, SDC aligns the hash code similarity distribution towards a calibration distribution (e.g., beta distribution) with sufficient spread across the entire similarity capacity/range, to alleviate the similarity collapse problem. Extensive experiments show that our SDC outperforms the state-of-the-art alternatives on both coarse category-level and instance-level image retrieval tasks, often by a large margin. Code is available at https://github.com/kamwoh/sdc.
Preconditioned Score-based Generative Models
Feb 13, 2023



Score-based generative models (SGMs) have recently emerged as a promising class of generative models. However, a fundamental limitation is that their sampling process is slow due to a need for many (\eg, $2000$) iterations of sequential computations. An intuitive acceleration method is to reduce the sampling iterations which however causes severe performance degradation. We assault this problem to the ill-conditioned issues of the Langevin dynamics and reverse diffusion in the sampling process. Under this insight, we propose a model-agnostic {\bf\em preconditioned diffusion sampling} (PDS) method that leverages matrix preconditioning to alleviate the aforementioned problem. PDS alters the sampling process of a vanilla SGM at marginal extra computation cost, and without model retraining. Theoretically, we prove that PDS preserves the output distribution of the SGM, no risk of inducing systematical bias to the original sampling process. We further theoretically reveal a relation between the parameter of PDS and the sampling iterations,easing the parameter estimation under varying sampling iterations. Extensive experiments on various image datasets with a variety of resolutions and diversity validate that our PDS consistently accelerates off-the-shelf SGMs whilst maintaining the synthesis quality. In particular, PDS can accelerate by up to $29\times$ on more challenging high resolution (1024$\times$1024) image generation. Compared with the latest generative models (\eg, CLD-SGM, DDIM, and Analytic-DDIM), PDS can achieve the best sampling quality on CIFAR-10 at a FID score of 1.99. Our code is made publicly available to foster any further research https://github.com/fudan-zvg/PDS.
Multi-Modal Few-Shot Temporal Action Detection via Vision-Language Meta-Adaptation
Nov 27, 2022



Few-shot (FS) and zero-shot (ZS) learning are two different approaches for scaling temporal action detection (TAD) to new classes. The former adapts a pretrained vision model to a new task represented by as few as a single video per class, whilst the latter requires no training examples by exploiting a semantic description of the new class. In this work, we introduce a new multi-modality few-shot (MMFS) TAD problem, which can be considered as a marriage of FS-TAD and ZS-TAD by leveraging few-shot support videos and new class names jointly. To tackle this problem, we further introduce a novel MUlti-modality PromPt mETa-learning (MUPPET) method. This is enabled by efficiently bridging pretrained vision and language models whilst maximally reusing already learned capacity. Concretely, we construct multi-modal prompts by mapping support videos into the textual token space of a vision-language model using a meta-learned adapter-equipped visual semantics tokenizer. To tackle large intra-class variation, we further design a query feature regulation scheme. Extensive experiments on ActivityNetv1.3 and THUMOS14 demonstrate that our MUPPET outperforms state-of-the-art alternative methods, often by a large margin. We also show that our MUPPET can be easily extended to tackle the few-shot object detection problem and again achieves the state-of-the-art performance on MS-COCO dataset. The code will be available in https://github.com/sauradip/MUPPET
Post-Processing Temporal Action Detection
Nov 27, 2022Existing Temporal Action Detection (TAD) methods typically take a pre-processing step in converting an input varying-length video into a fixed-length snippet representation sequence, before temporal boundary estimation and action classification. This pre-processing step would temporally downsample the video, reducing the inference resolution and hampering the detection performance in the original temporal resolution. In essence, this is due to a temporal quantization error introduced during the resolution downsampling and recovery. This could negatively impact the TAD performance, but is largely ignored by existing methods. To address this problem, in this work we introduce a novel model-agnostic post-processing method without model redesign and retraining. Specifically, we model the start and end points of action instances with a Gaussian distribution for enabling temporal boundary inference at a sub-snippet level. We further introduce an efficient Taylor-expansion based approximation, dubbed as Gaussian Approximated Post-processing (GAP). Extensive experiments demonstrate that our GAP can consistently improve a wide variety of pre-trained off-the-shelf TAD models on the challenging ActivityNet (+0.2% -0.7% in average mAP) and THUMOS (+0.2% -0.5% in average mAP) benchmarks. Such performance gains are already significant and highly comparable to those achieved by novel model designs. Also, GAP can be integrated with model training for further performance gain. Importantly, GAP enables lower temporal resolutions for more efficient inference, facilitating low-resource applications. The code will be available in https://github.com/sauradip/GAP
Self-supervised Video Representation Learning with Motion-Aware Masked Autoencoders
Oct 09, 2022
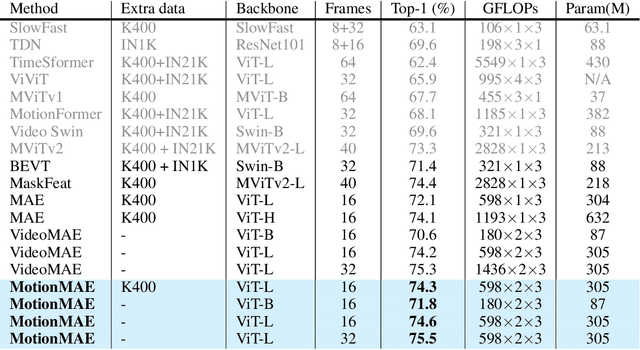
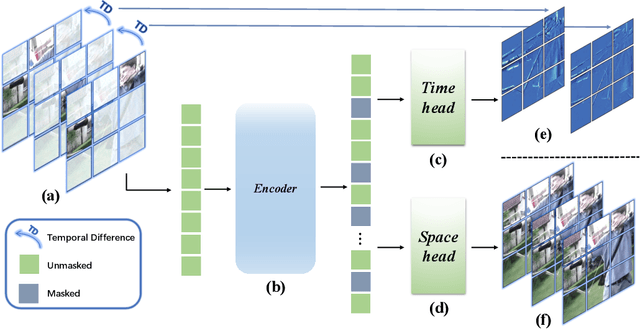
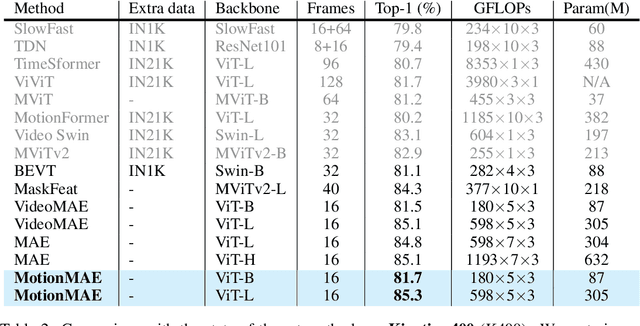
Masked autoencoders (MAEs) have emerged recently as art self-supervised spatiotemporal representation learners. Inheriting from the image counterparts, however, existing video MAEs still focus largely on static appearance learning whilst are limited in learning dynamic temporal information hence less effective for video downstream tasks. To resolve this drawback, in this work we present a motion-aware variant -- MotionMAE. Apart from learning to reconstruct individual masked patches of video frames, our model is designed to additionally predict the corresponding motion structure information over time. This motion information is available at the temporal difference of nearby frames. As a result, our model can extract effectively both static appearance and dynamic motion spontaneously, leading to superior spatiotemporal representation learning capability. Extensive experiments show that our MotionMAE outperforms significantly both supervised learning baseline and state-of-the-art MAE alternatives, under both domain-specific and domain-generic pretraining-then-finetuning settings. In particular, when using ViT-B as the backbone our MotionMAE surpasses the prior art model by a margin of 1.2% on Something-Something V2 and 3.2% on UCF101 in domain-specific pretraining setting. Encouragingly, it also surpasses the competing MAEs by a large margin of over 3% on the challenging video object segmentation task. The code is available at https://github.com/happy-hsy/MotionMAE.