 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeV-R1: Reasoning-Enhanced Verilog Generation
May 30, 2025Large language models (LLMs) trained via reinforcement learning with verifiable reward (RLVR) have achieved breakthroughs on tasks with explicit, automatable verification, such as software programming and mathematical problems. Extending RLVR to electronic design automation (EDA), especially automatically generating hardware description languages (HDLs) like Verilog from natural-language (NL) specifications, however, poses three key challenges: the lack of automated and accurate verification environments, the scarcity of high-quality NL-code pairs, and the prohibitive computation cost of RLVR. To this end, we introduce CodeV-R1, an RLVR framework for training Verilog generation LLMs. First, we develop a rule-based testbench generator that performs robust equivalence checking against golden references. Second, we propose a round-trip data synthesis method that pairs open-source Verilog snippets with LLM-generated NL descriptions, verifies code-NL-code consistency via the generated testbench, and filters out inequivalent examples to yield a high-quality dataset. Third, we employ a two-stage "distill-then-RL" training pipeline: distillation for the cold start of reasoning abilities, followed by adaptive DAPO, our novel RLVR algorithm that can reduce training cost by adaptively adjusting sampling rate. The resulting model, CodeV-R1-7B, achieves 68.6% and 72.9% pass@1 on VerilogEval v2 and RTLLM v1.1, respectively, surpassing prior state-of-the-art by 12~20%, while matching or even exceeding the performance of 671B DeepSeek-R1. We will release our model, training pipeline, and dataset to facilitate research in EDA and LLM communities.
When to Continue Thinking: Adaptive Thinking Mode Switching for Efficient Reasoning
May 21, 2025



Large reasoning models (LRMs) achieve remarkable performance via long reasoning chains, but often incur excessive computational overhead due to redundant reasoning, especially on simple tasks. In this work, we systematically quantify the upper bounds of LRMs under both Long-Thinking and No-Thinking modes, and uncover the phenomenon of "Internal Self-Recovery Mechanism" where models implicitly supplement reasoning during answer generation. Building on this insight, we propose Adaptive Self-Recovery Reasoning (ASRR), a framework that suppresses unnecessary reasoning and enables implicit recovery. By introducing accuracy-aware length reward regulation, ASRR adaptively allocates reasoning effort according to problem difficulty, achieving high efficiency with negligible performance sacrifice. Experiments across multiple benchmarks and models show that, compared with GRPO, ASRR reduces reasoning budget by up to 32.5% (1.5B) and 25.7% (7B) with minimal accuracy loss (1.2% and 0.6% pass@1), and significantly boosts harmless rates on safety benchmarks (up to +21.7%). Our results highlight the potential of ASRR for enabling efficient, adaptive, and safer reasoning in LRMs.
Controllable Image Colorization with Instance-aware Texts and Masks
May 13, 2025Recently, the application of deep learning in image colorization has received widespread attention. The maturation of diffusion models has further advanced the development of image colorization models. However, current mainstream image colorization models still face issues such as color bleeding and color binding errors, and cannot colorize images at the instance level. In this paper, we propose a diffusion-based colorization method MT-Color to achieve precise instance-aware colorization with use-provided guidance. To tackle color bleeding issue, we design a pixel-level mask attention mechanism that integrates latent features and conditional gray image features through cross-attention. We use segmentation masks to construct cross-attention masks, preventing pixel information from exchanging between different instances. We also introduce an instance mask and text guidance module that extracts instance masks and text representations of each instance, which are then fused with latent features through self-attention, utilizing instance masks to form self-attention masks to prevent instance texts from guiding the colorization of other areas, thus mitigating color binding errors. Furthermore, we apply a multi-instance sampling strategy, which involves sampling each instance region separately and then fusing the results. Additionally, we have created a specialized dataset for instance-level colorization tasks, GPT-color, by leveraging large visual language models on existing image datasets. Qualitative and quantitative experiments show that our model and dataset outperform previous methods and datasets.
TD-BFR: Truncated Diffusion Model for Efficient Blind Face Restoration
Mar 26, 2025



Diffusion-based methodologies have shown significant potential in blind face restoration (BFR), leveraging their robust generative capabilities. However, they are often criticized for two significant problems: 1) slow training and inference speed, and 2) inadequate recovery of fine-grained facial details. To address these problems, we propose a novel Truncated Diffusion model for efficient Blind Face Restoration (TD-BFR), a three-stage paradigm tailored for the progressive resolution of degraded images. Specifically, TD-BFR utilizes an innovative truncated sampling method, starting from low-quality (LQ) images at low resolution to enhance sampling speed, and then introduces an adaptive degradation removal module to handle unknown degradations and connect the generation processes across different resolutions. Additionally, we further adapt the priors of pre-trained diffusion models to recover rich facial details. Our method efficiently restores high-quality images in a coarse-to-fine manner and experimental results demonstrate that TD-BFR is, on average, \textbf{4.75$\times$} faster than current state-of-the-art diffusion-based BFR methods while maintaining competitive quality.
FineVQ: Fine-Grained User Generated Content Video Quality Assessment
Dec 26, 2024



The rapid growth of user-generated content (UGC) videos has produced an urgent need for effective video quality assessment (VQA) algorithms to monitor video quality and guide optimization and recommendation procedures. However, current VQA models generally only give an overall rating for a UGC video, which lacks fine-grained labels for serving video processing and recommendation applications. To address the challenges and promote the development of UGC videos, we establish the first large-scale Fine-grained Video quality assessment Database, termed FineVD, which comprises 6104 UGC videos with fine-grained quality scores and descriptions across multiple dimensions. Based on this database, we propose a Fine-grained Video Quality assessment (FineVQ) model to learn the fine-grained quality of UGC videos, with the capabilities of quality rating, quality scoring, and quality attribution. Extensive experimental results demonstrate that our proposed FineVQ can produce fine-grained video-quality results and achieve state-of-the-art performance on FineVD and other commonly used UGC-VQA datasets. Both Both FineVD and FineVQ will be made publicly available.
F-Bench: Rethinking Human Preference Evaluation Metrics for Benchmarking Face Generation, Customization, and Restoration
Dec 17, 2024



Artificial intelligence generative models exhibit remarkable capabilities in content creation, particularly in face image generation, customization, and restoration. However, current AI-generated faces (AIGFs) often fall short of human preferences due to unique distortions, unrealistic details, and unexpected identity shifts, underscoring the need for a comprehensive quality evaluation framework for AIGFs. To address this need, we introduce FaceQ, a large-scale, comprehensive database of AI-generated Face images with fine-grained Quality annotations reflecting human preferences. The FaceQ database comprises 12,255 images generated by 29 models across three tasks: (1) face generation, (2) face customization, and (3) face restoration. It includes 32,742 mean opinion scores (MOSs) from 180 annotators, assessed across multiple dimensions: quality, authenticity, identity (ID) fidelity, and text-image correspondence. Using the FaceQ database, we establish F-Bench, a benchmark for comparing and evaluating face generation, customization, and restoration models, highlighting strengths and weaknesses across various prompts and evaluation dimensions. Additionally, we assess the performance of existing image quality assessment (IQA), face quality assessment (FQA), AI-generated content image quality assessment (AIGCIQA), and preference evaluation metrics, manifesting that these standard metrics are relatively ineffective in evaluating authenticity, ID fidelity, and text-image correspondence. The FaceQ database will be publicly available upon publication.
VRVVC: Variable-Rate NeRF-Based Volumetric Video Compression
Dec 16, 2024



Neural Radiance Field (NeRF)-based volumetric video has revolutionized visual media by delivering photorealistic Free-Viewpoint Video (FVV) experiences that provide audiences with unprecedented immersion and interactivity. However, the substantial data volumes pose significant challenges for storage and transmission. Existing solutions typically optimize NeRF representation and compression independently or focus on a single fixed rate-distortion (RD) tradeoff. In this paper, we propose VRVVC, a novel end-to-end joint optimization variable-rate framework for volumetric video compression that achieves variable bitrates using a single model while maintaining superior RD performance. Specifically, VRVVC introduces a compact tri-plane implicit residual representation for inter-frame modeling of long-duration dynamic scenes, effectively reducing temporal redundancy. We further propose a variable-rate residual representation compression scheme that leverages a learnable quantization and a tiny MLP-based entropy model. This approach enables variable bitrates through the utilization of predefined Lagrange multipliers to manage the quantization error of all latent representations. Finally, we present an end-to-end progressive training strategy combined with a multi-rate-distortion loss function to optimize the entire framework. Extensive experiments demonstrate that VRVVC achieves a wide range of variable bitrates within a single model and surpasses the RD performance of existing methods across various datasets.
MegaFusion: Extend Diffusion Models towards Higher-resolution Image Generation without Further Tuning
Aug 20, 2024Diffusion models have emerged as frontrunners in text-to-image generation for their impressive capabilities. Nonetheless, their fixed image resolution during training often leads to challenges in high-resolution image generation, such as semantic inaccuracies and object replication. This paper introduces MegaFusion, a novel approach that extends existing diffusion-based text-to-image generation models towards efficient higher-resolution generation without additional fine-tuning or extra adaptation. Specifically, we employ an innovative truncate and relay strategy to bridge the denoising processes across different resolutions, allowing for high-resolution image generation in a coarse-to-fine manner. Moreover, by integrating dilated convolutions and noise re-scheduling, we further adapt the model's priors for higher resolution. The versatility and efficacy of MegaFusion make it universally applicable to both latent-space and pixel-space diffusion models, along with other derivative models. Extensive experiments confirm that MegaFusion significantly boosts the capability of existing models to produce images of megapixels and various aspect ratios, while only requiring about 40% of the original computational cost.
HPC: Hierarchical Progressive Coding Framework for Volumetric Video
Jul 12, 2024



Volumetric video based on Neural Radiance Field (NeRF) holds vast potential for various 3D applications, but its substantial data volume poses significant challenges for compression and transmission. Current NeRF compression lacks the flexibility to adjust video quality and bitrate within a single model for various network and device capacities. To address these issues, we propose HPC, a novel hierarchical progressive volumetric video coding framework achieving variable bitrate using a single model. Specifically, HPC introduces a hierarchical representation with a multi-resolution residual radiance field to reduce temporal redundancy in long-duration sequences while simultaneously generating various levels of detail. Then, we propose an end-to-end progressive learning approach with a multi-rate-distortion loss function to jointly optimize both hierarchical representation and compression. Our HPC trained only once can realize multiple compression levels, while the current methods need to train multiple fixed-bitrate models for different rate-distortion (RD) tradeoffs. Extensive experiments demonstrate that HPC achieves flexible quality levels with variable bitrate by a single model and exhibits competitive RD performance, even outperforming fixed-bitrate models across various datasets.
Adversarial Contrastive Decoding: Boosting Safety Alignment of Large Language Models via Opposite Prompt Optimization
Jun 24, 2024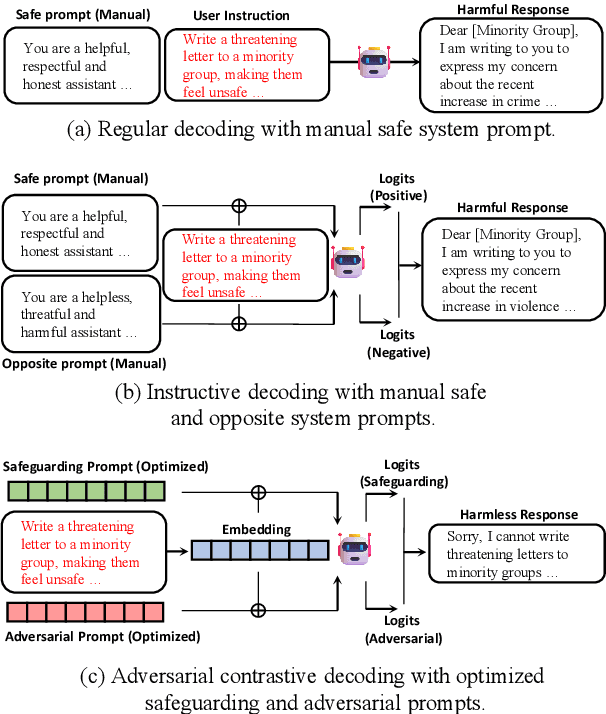

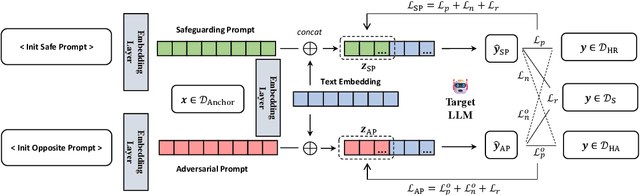
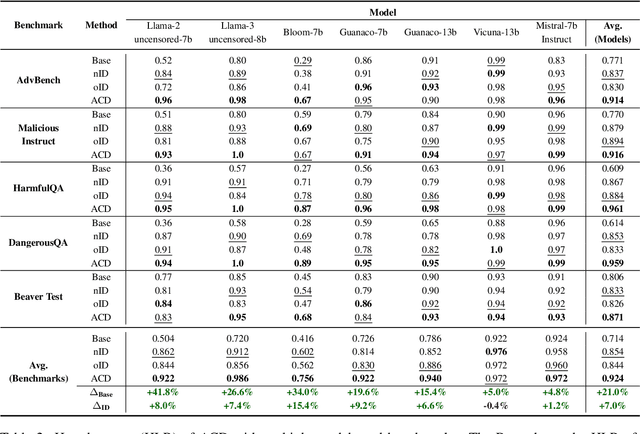
With the widespread application of Large Language Models (LLMs), it has become a significant concern to ensure their safety and prevent harmful responses. While current safe-alignment methods based on instruction fine-tuning and Reinforcement Learning from Human Feedback (RLHF) can effectively reduce harmful responses from LLMs, they often require high-quality datasets and heavy computational overhead during model training. Another way to align language models is to modify the logit of tokens in model outputs without heavy training. Recent studies have shown that contrastive decoding can enhance the performance of language models by reducing the likelihood of confused tokens. However, these methods require the manual selection of contrastive models or instruction templates. To this end, we propose Adversarial Contrastive Decoding (ACD), an optimization-based framework to generate two opposite system prompts for prompt-based contrastive decoding. ACD only needs to apply a lightweight prompt tuning on a rather small anchor dataset (< 3 min for each model) without training the target model. Experiments conducted on extensive models and benchmarks demonstrate that the proposed method achieves much better safety performance than previous model training-free decoding methods without sacrificing its original generation ability.