 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoyuan Liu
Improving Scene Graph Generation with Relation Words' Debiasing in Vision-Language Models
Mar 24, 2024
Scene Graph Generation (SGG) provides basic language representation of visual scenes, requiring models to grasp complex and diverse semantics between various objects. However, this complexity and diversity in SGG also leads to underrepresentation, where part of test triplets are rare or even unseen during training, resulting in imprecise predictions. To tackle this, we propose using the SGG models with pretrained vision-language models (VLMs) to enhance representation. However, due to the gap between the pretraining and SGG, directly ensembling the pretrained VLMs leads to severe biases across relation words. Thus, we introduce LM Estimation to approximate the words' distribution underlies in the pretraining language sets, and then use the distribution for debiasing. After that, we ensemble VLMs with SGG models to enhance representation. Considering that each model may represent better at different samples, we use a certainty-aware indicator to score each sample and dynamically adjust the ensemble weights. Our method effectively addresses the words biases, enhances SGG's representation, and achieve markable performance enhancements. It is training-free and integrates well with existing SGG models.
Effective and Efficient Federated Tree Learning on Hybrid Data
Oct 18, 2023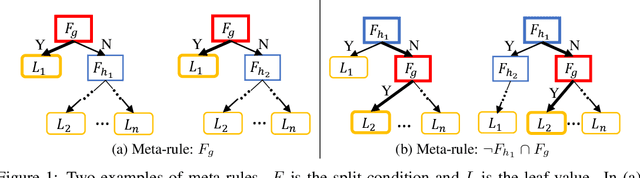
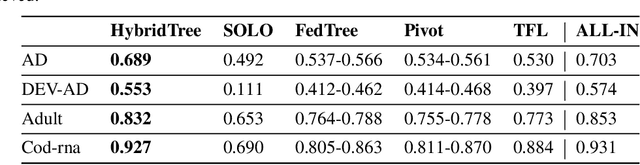
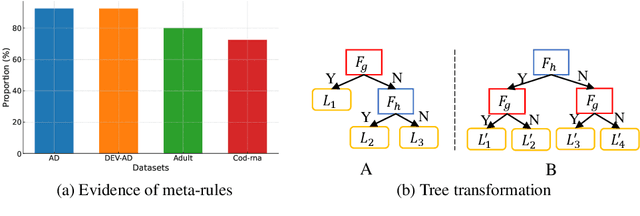
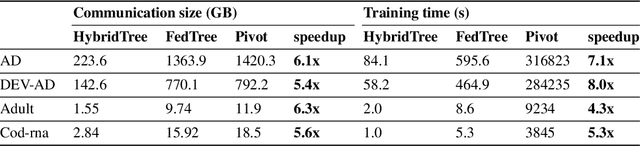
Federated learning has emerged as a promising distributed learning paradigm that facilitates collaborative learning among multiple parties without transferring raw data. However, most existing federated learning studies focus on either horizontal or vertical data settings, where the data of different parties are assumed to be from the same feature or sample space. In practice, a common scenario is the hybrid data setting, where data from different parties may differ both in the features and samples. To address this, we propose HybridTree, a novel federated learning approach that enables federated tree learning on hybrid data. We observe the existence of consistent split rules in trees. With the help of these split rules, we theoretically show that the knowledge of parties can be incorporated into the lower layers of a tree. Based on our theoretical analysis, we propose a layer-level solution that does not need frequent communication traffic to train a tree. Our experiments demonstrate that HybridTree can achieve comparable accuracy to the centralized setting with low computational and communication overhead. HybridTree can achieve up to 8 times speedup compared with the other baselines.
Model Inversion Attacks on Homogeneous and Heterogeneous Graph Neural Networks
Oct 15, 2023Recently, Graph Neural Networks (GNNs), including Homogeneous Graph Neural Networks (HomoGNNs) and Heterogeneous Graph Neural Networks (HeteGNNs), have made remarkable progress in many physical scenarios, especially in communication applications. Despite achieving great success, the privacy issue of such models has also received considerable attention. Previous studies have shown that given a well-fitted target GNN, the attacker can reconstruct the sensitive training graph of this model via model inversion attacks, leading to significant privacy worries for the AI service provider. We advocate that the vulnerability comes from the target GNN itself and the prior knowledge about the shared properties in real-world graphs. Inspired by this, we propose a novel model inversion attack method on HomoGNNs and HeteGNNs, namely HomoGMI and HeteGMI. Specifically, HomoGMI and HeteGMI are gradient-descent-based optimization methods that aim to maximize the cross-entropy loss on the target GNN and the $1^{st}$ and $2^{nd}$-order proximities on the reconstructed graph. Notably, to the best of our knowledge, HeteGMI is the first attempt to perform model inversion attacks on HeteGNNs. Extensive experiments on multiple benchmarks demonstrate that the proposed method can achieve better performance than the competitors.
Learning To Optimize Quantum Neural Network Without Gradients
Apr 15, 2023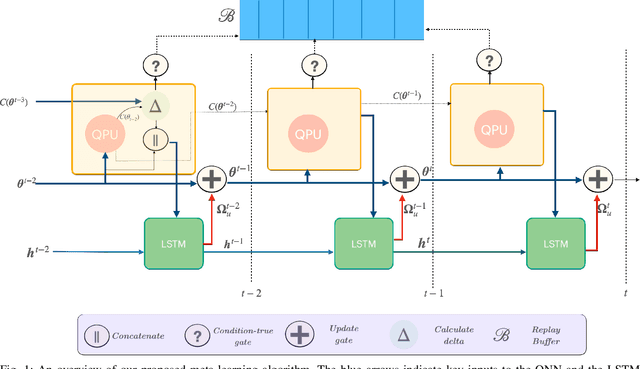
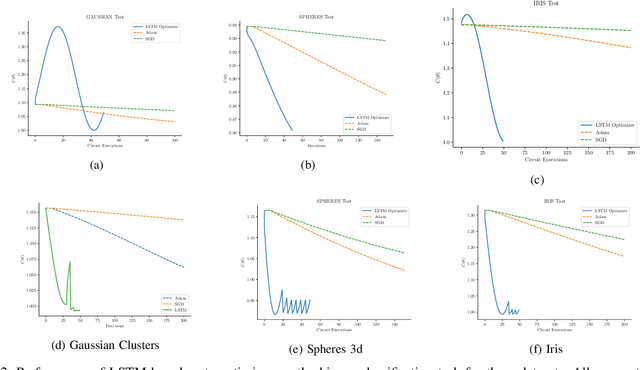
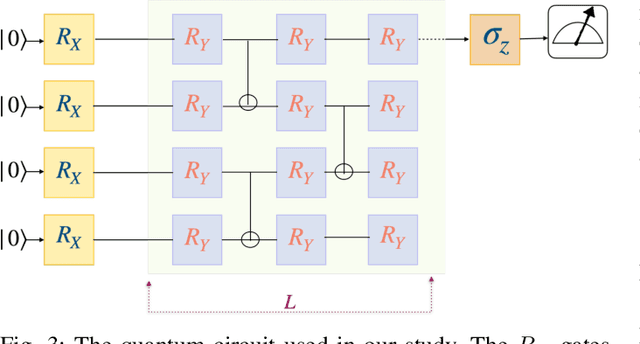
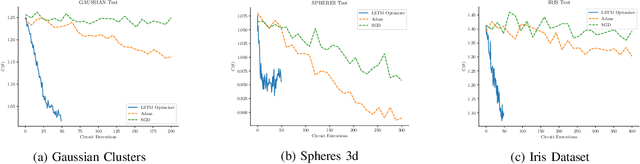
Quantum Machine Learning is an emerging sub-field in machine learning where one of the goals is to perform pattern recognition tasks by encoding data into quantum states. This extension from classical to quantum domain has been made possible due to the development of hybrid quantum-classical algorithms that allow a parameterized quantum circuit to be optimized using gradient based algorithms that run on a classical computer. The similarities in training of these hybrid algorithms and classical neural networks has further led to the development of Quantum Neural Networks (QNNs). However, in the current training regime for QNNs, the gradients w.r.t objective function have to be computed on the quantum device. This computation is highly non-scalable and is affected by hardware and sampling noise present in the current generation of quantum hardware. In this paper, we propose a training algorithm that does not rely on gradient information. Specifically, we introduce a novel meta-optimization algorithm that trains a \emph{meta-optimizer} network to output parameters for the quantum circuit such that the objective function is minimized. We empirically and theoretically show that we achieve a better quality minima in fewer circuit evaluations than existing gradient based algorithms on different datasets.
Towards Practical Explainability with Cluster Descriptors
Oct 20, 2022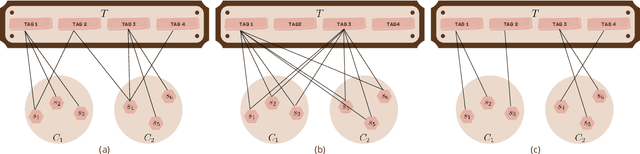

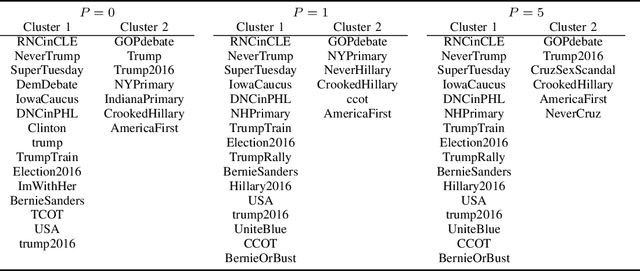

With the rapid development of machine learning, improving its explainability has become a crucial research goal. We study the problem of making the clusters more explainable by investigating the cluster descriptors. Given a set of objects $S$, a clustering of these objects $\pi$, and a set of tags $T$ that have not participated in the clustering algorithm. Each object in $S$ is associated with a subset of $T$. The goal is to find a representative set of tags for each cluster, referred to as the cluster descriptors, with the constraint that these descriptors we find are pairwise disjoint, and the total size of all the descriptors is minimized. In general, this problem is NP-hard. We propose a novel explainability model that reinforces the previous models in such a way that tags that do not contribute to explainability and do not sufficiently distinguish between clusters are not added to the optimal descriptors. The proposed model is formulated as a quadratic unconstrained binary optimization problem which makes it suitable for solving on modern optimization hardware accelerators. We experimentally demonstrate how a proposed explainability model can be solved on specialized hardware for accelerating combinatorial optimization, the Fujitsu Digital Annealer, and use real-life Twitter and PubMed datasets for use cases.
UniFed: A Benchmark for Federated Learning Frameworks
Jul 21, 2022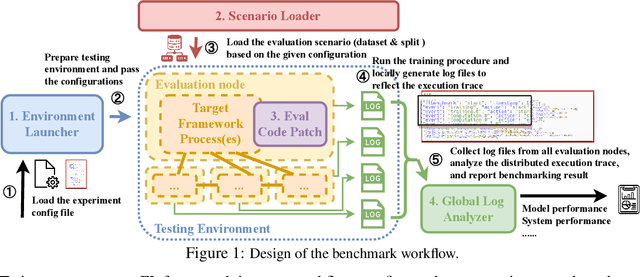
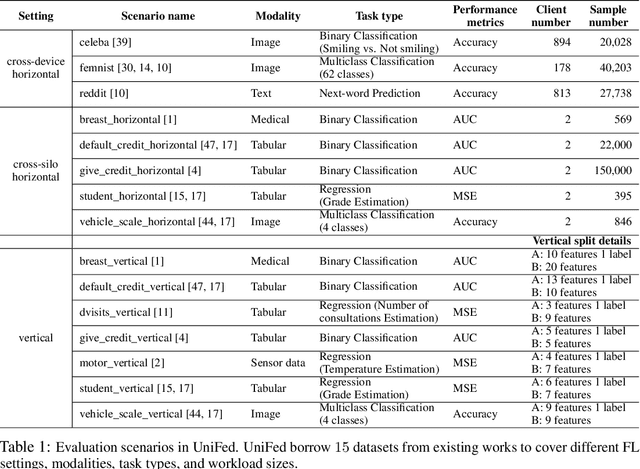
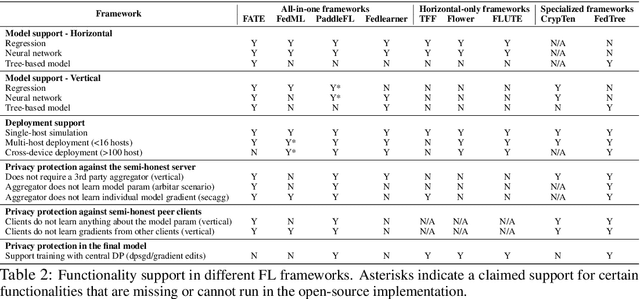
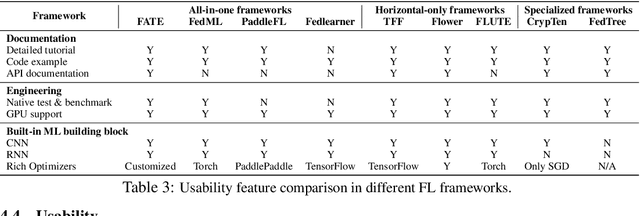
Federated Learning (FL) has become a practical and popular paradigm in machine learning. However, currently, there is no systematic solution that covers diverse use cases. Practitioners often face the challenge of how to select a matching FL framework for their use case. In this work, we present UniFed, the first unified benchmark for standardized evaluation of the existing open-source FL frameworks. With 15 evaluation scenarios, we present both qualitative and quantitative evaluation results of nine existing popular open-sourced FL frameworks, from the perspectives of functionality, usability, and system performance. We also provide suggestions on framework selection based on the benchmark conclusions and point out future improvement directions.
A System for Automated Open-Source Threat Intelligence Gathering and Management
Jan 19, 2021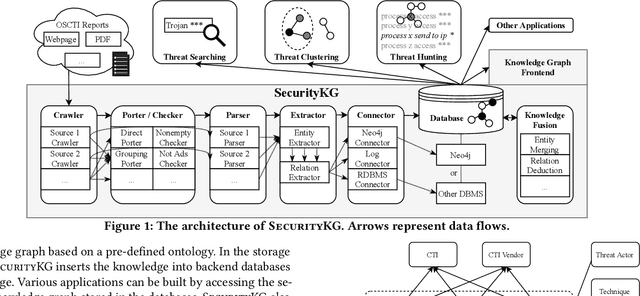
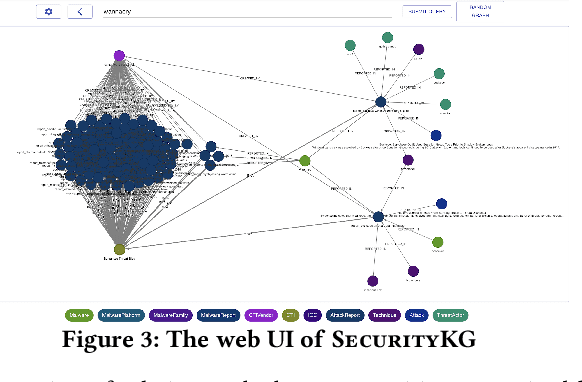
Sophisticated cyber attacks have plagued many high-profile businesses. To remain aware of the fast-evolving threat landscape, open-source Cyber Threat Intelligence (OSCTI) has received growing attention from the community. Commonly, knowledge about threats is presented in a vast number of OSCTI reports. Despite the pressing need for high-quality OSCTI, existing OSCTI gathering and management platforms, however, have primarily focused on isolated, low-level Indicators of Compromise. On the other hand, higher-level concepts (e.g., adversary tactics, techniques, and procedures) and their relationships have been overlooked, which contain essential knowledge about threat behaviors that is critical to uncovering the complete threat scenario. To bridge the gap, we propose SecurityKG, a system for automated OSCTI gathering and management. SecurityKG collects OSCTI reports from various sources, uses a combination of AI and NLP techniques to extract high-fidelity knowledge about threat behaviors, and constructs a security knowledge graph. SecurityKG also provides a UI that supports various types of interactivity to facilitate knowledge graph exploration.
A System for Efficiently Hunting for Cyber Threats in Computer Systems Using Threat Intelligence
Jan 17, 2021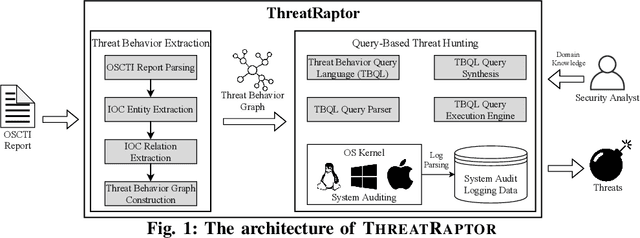


Log-based cyber threat hunting has emerged as an important solution to counter sophisticated cyber attacks. However, existing approaches require non-trivial efforts of manual query construction and have overlooked the rich external knowledge about threat behaviors provided by open-source Cyber Threat Intelligence (OSCTI). To bridge the gap, we build ThreatRaptor, a system that facilitates cyber threat hunting in computer systems using OSCTI. Built upon mature system auditing frameworks, ThreatRaptor provides (1) an unsupervised, light-weight, and accurate NLP pipeline that extracts structured threat behaviors from unstructured OSCTI text, (2) a concise and expressive domain-specific query language, TBQL, to hunt for malicious system activities, (3) a query synthesis mechanism that automatically synthesizes a TBQL query from the extracted threat behaviors, and (4) an efficient query execution engine to search the big system audit logging data.
Enabling Efficient Cyber Threat Hunting With Cyber Threat Intelligence
Oct 26, 2020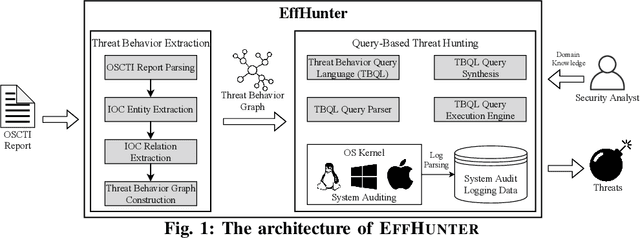



Log-based cyber threat hunting has emerged as an important solution to counter sophisticated cyber attacks. However, existing approaches require non-trivial efforts of manual query construction and have overlooked the rich external knowledge about threat behaviors provided by open-source Cyber Threat Intelligence (OSCTI). To bridge the gap, we propose EffHunter, a system that facilitates cyber threat hunting in computer systems using OSCTI. Built upon mature system auditing frameworks, EffHunter provides (1) an unsupervised, light-weight, and accurate NLP pipeline that extracts structured threat behaviors from unstructured OSCTI text, (2) a concise and expressive domain-specific query language, TBQL, to hunt for malicious system activities, (3) a query synthesis mechanism that automatically synthesizes a TBQL query for threat hunting from the extracted threat behaviors, and (4) an efficient query execution engine to search the big audit logging data. Evaluations on a broad set of attack cases demonstrate the accuracy and efficiency of EffHunter in enabling practical threat hunting.
Structured Hierarchical Dialogue Policy with Graph Neural Networks
Sep 22, 2020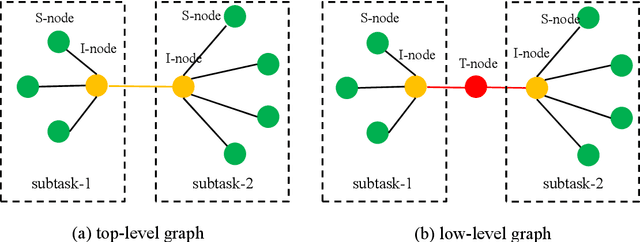
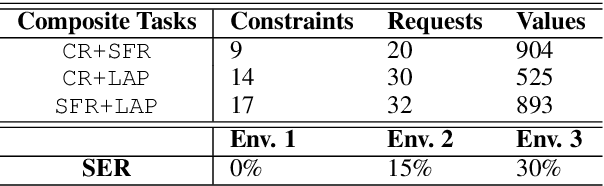
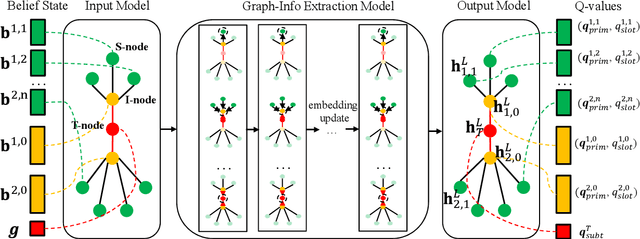

Dialogue policy training for composite tasks, such as restaurant reservation in multiple places, is a practically important and challenging problem. Recently, hierarchical deep reinforcement learning (HDRL) methods have achieved good performance in composite tasks. However, in vanilla HDRL, both top-level and low-level policies are all represented by multi-layer perceptrons (MLPs) which take the concatenation of all observations from the environment as the input for predicting actions. Thus, traditional HDRL approach often suffers from low sampling efficiency and poor transferability. In this paper, we address these problems by utilizing the flexibility of graph neural networks (GNNs). A novel ComNet is proposed to model the structure of a hierarchical agent. The performance of ComNet is tested on composited tasks of the PyDial benchmark. Experiments show that ComNet outperforms vanilla HDRL systems with performance close to the upper bound. It not only achieves sample efficiency but also is more robust to noise while maintaining the transferability to other composite tasks.