 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Don't Need All Attentions: Distributed Dynamic Fine-Tuning for Foundation Models
Apr 16, 2025Fine-tuning plays a crucial role in adapting models to downstream tasks with minimal training efforts. However, the rapidly increasing size of foundation models poses a daunting challenge for accommodating foundation model fine-tuning in most commercial devices, which often have limited memory bandwidth. Techniques like model sharding and tensor parallelism address this issue by distributing computation across multiple devices to meet memory requirements. Nevertheless, these methods do not fully leverage their foundation nature in facilitating the fine-tuning process, resulting in high computational costs and imbalanced workloads. We introduce a novel Distributed Dynamic Fine-Tuning (D2FT) framework that strategically orchestrates operations across attention modules based on our observation that not all attention modules are necessary for forward and backward propagation in fine-tuning foundation models. Through three innovative selection strategies, D2FT significantly reduces the computational workload required for fine-tuning foundation models. Furthermore, D2FT addresses workload imbalances in distributed computing environments by optimizing these selection strategies via multiple knapsack optimization. Our experimental results demonstrate that the proposed D2FT framework reduces the training computational costs by 40% and training communication costs by 50% with only 1% to 2% accuracy drops on the CIFAR-10, CIFAR-100, and Stanford Cars datasets. Moreover, the results show that D2FT can be effectively extended to recent LoRA, a state-of-the-art parameter-efficient fine-tuning technique. By reducing 40% computational cost or 50% communication cost, D2FT LoRA top-1 accuracy only drops 4% to 6% on Stanford Cars dataset.
PATROL: Privacy-Oriented Pruning for Collaborative Inference Against Model Inversion Attacks
Jul 20, 2023
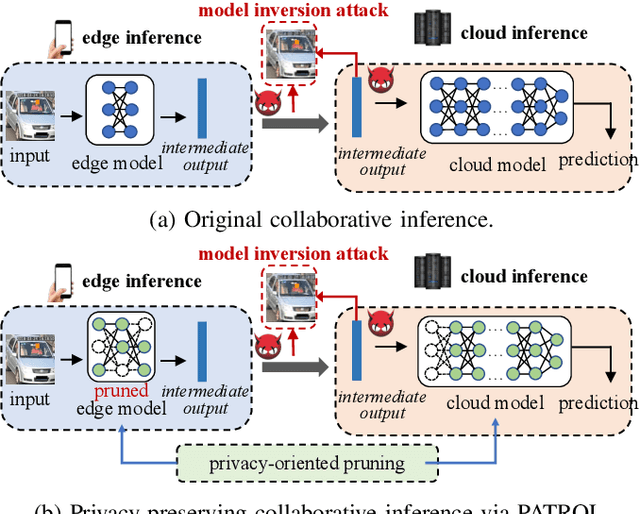

Collaborative inference has been a promising solution to enable resource-constrained edge devices to perform inference using state-of-the-art deep neural networks (DNNs). In collaborative inference, the edge device first feeds the input to a partial DNN locally and then uploads the intermediate result to the cloud to complete the inference. However, recent research indicates model inversion attacks (MIAs) can reconstruct input data from intermediate results, posing serious privacy concerns for collaborative inference. Existing perturbation and cryptography techniques are inefficient and unreliable in defending against MIAs while performing accurate inference. This paper provides a viable solution, named PATROL, which develops privacy-oriented pruning to balance privacy, efficiency, and utility of collaborative inference. PATROL takes advantage of the fact that later layers in a DNN can extract more task-specific features. Given limited local resources for collaborative inference, PATROL intends to deploy more layers at the edge based on pruning techniques to enforce task-specific features for inference and reduce task-irrelevant but sensitive features for privacy preservation. To achieve privacy-oriented pruning, PATROL introduces two key components: Lipschitz regularization and adversarial reconstruction training, which increase the reconstruction errors by reducing the stability of MIAs and enhance the target inference model by adversarial training, respectively.