 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-ELF: A Multi-Level Representation Learning Framework for Electrolyte Formulation Design
Jul 08, 2024



Advancements in lithium battery technology heavily rely on the design and engineering of electrolytes. However, current schemes for molecular design and recipe optimization of electrolytes lack an effective computational-experimental closed loop and often fall short in accurately predicting diverse electrolyte formulation properties. In this work, we introduce Uni-ELF, a novel multi-level representation learning framework to advance electrolyte design. Our approach involves two-stage pretraining: reconstructing three-dimensional molecular structures at the molecular level using the Uni-Mol model, and predicting statistical structural properties (e.g., radial distribution functions) from molecular dynamics simulations at the mixture level. Through this comprehensive pretraining, Uni-ELF is able to capture intricate molecular and mixture-level information, which significantly enhances its predictive capability. As a result, Uni-ELF substantially outperforms state-of-the-art methods in predicting both molecular properties (e.g., melting point, boiling point, synthesizability) and formulation properties (e.g., conductivity, Coulombic efficiency). Moreover, Uni-ELF can be seamlessly integrated into an automatic experimental design workflow. We believe this innovative framework will pave the way for automated AI-based electrolyte design and engineering.
Hypergrah-Enhanced Dual Convolutional Network for Bundle Recommendation
Dec 18, 2023



Bundle recommendations strive to offer users a set of items as a package named bundle, enhancing convenience and contributing to the seller's revenue. While previous approaches have demonstrated notable performance, we argue that they may compromise the ternary relationship among users, items, and bundles. This compromise can result in information loss, ultimately impacting the overall model performance. To address this gap, we develop a unified model for bundle recommendation, termed hypergraph-enhanced dual convolutional neural network (HED). Our approach is characterized by two key aspects. Firstly, we construct a complete hypergraph to capture interaction dynamics among users, items, and bundles. Secondly, we incorporate U-B interaction information to enhance the information representation derived from users and bundle embedding vectors. Extensive experimental results on the Youshu and Netease datasets have demonstrated that HED surpasses state-of-the-art baselines, proving its effectiveness. In addition, various ablation studies and sensitivity analyses revealed the working mechanism and proved our effectiveness. Codes and datasets are available at https://github.com/AAI-Lab/HED
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Multi-level Gated Bayesian Recurrent Neural Network for State Estimation
Oct 26, 2023The optimality of Bayesian filtering relies on the completeness of prior models, while deep learning holds a distinct advantage in learning models from offline data. Nevertheless, the current fusion of these two methodologies remains largely ad hoc, lacking a theoretical foundation. This paper presents a novel solution, namely a multi-level gated Bayesian recurrent neural network specifically designed to state estimation under model mismatches. Firstly, we transform the non-Markov state-space model into an equivalent first-order Markov model with memory. It is a generalized transformation that overcomes the limitations of the first-order Markov property and enables recursive filtering. Secondly, by deriving a data-assisted joint state-memory-mismatch Bayesian filtering, we design a Bayesian multi-level gated framework that includes a memory update gate for capturing the temporal regularities in state evolution, a state prediction gate with the evolution mismatch compensation, and a state update gate with the observation mismatch compensation. The Gaussian approximation implementation of the filtering process within the gated framework is derived, taking into account the computational efficiency. Finally, the corresponding internal neural network structures and end-to-end training methods are designed. The Bayesian filtering theory enhances the interpretability of the proposed gated network, enabling the effective integration of offline data and prior models within functionally explicit gated units. In comprehensive experiments, including simulations and real-world datasets, the proposed gated network demonstrates superior estimation performance compared to benchmark filters and state-of-the-art deep learning filtering methods.
Cross-Spatial Pixel Integration and Cross-Stage Feature Fusion Based Transformer Network for Remote Sensing Image Super-Resolution
Jul 06, 2023



Remote sensing image super-resolution (RSISR) plays a vital role in enhancing spatial detials and improving the quality of satellite imagery. Recently, Transformer-based models have shown competitive performance in RSISR. To mitigate the quadratic computational complexity resulting from global self-attention, various methods constrain attention to a local window, enhancing its efficiency. Consequently, the receptive fields in a single attention layer are inadequate, leading to insufficient context modeling. Furthermore, while most transform-based approaches reuse shallow features through skip connections, relying solely on these connections treats shallow and deep features equally, impeding the model's ability to characterize them. To address these issues, we propose a novel transformer architecture called Cross-Spatial Pixel Integration and Cross-Stage Feature Fusion Based Transformer Network (SPIFFNet) for RSISR. Our proposed model effectively enhances global cognition and understanding of the entire image, facilitating efficient integration of features cross-stages. The model incorporates cross-spatial pixel integration attention (CSPIA) to introduce contextual information into a local window, while cross-stage feature fusion attention (CSFFA) adaptively fuses features from the previous stage to improve feature expression in line with the requirements of the current stage. We conducted comprehensive experiments on multiple benchmark datasets, demonstrating the superior performance of our proposed SPIFFNet in terms of both quantitative metrics and visual quality when compared to state-of-the-art methods.
Multi-sensor Suboptimal Fusion Student's $t$ Filter
Apr 23, 2022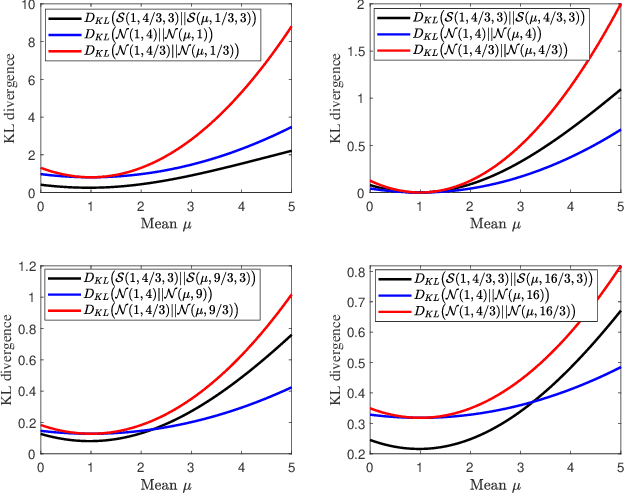
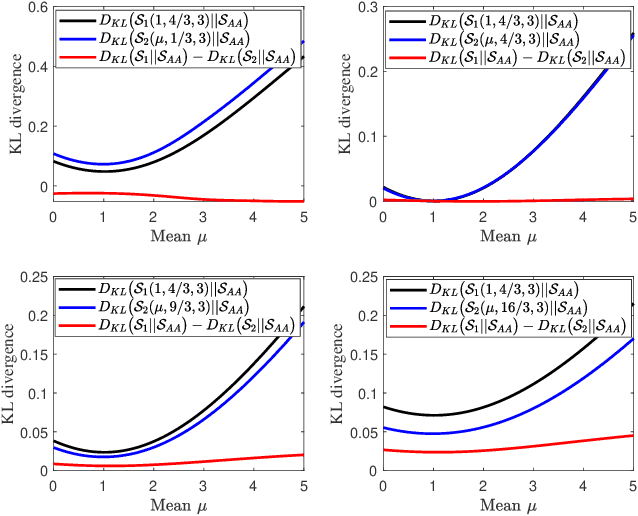
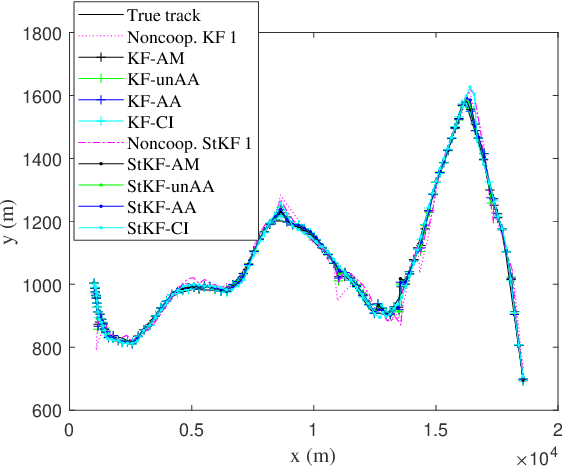

A multi-sensor fusion Student's $t$ filter is proposed for time-series recursive estimation in the presence of heavy-tailed process and measurement noises. Driven from an information-theoretic optimization, the approach extends the single sensor Student's $t$ Kalman filter based on the suboptimal arithmetic average (AA) fusion approach. To ensure computationally efficient, closed-form $t$ density recursion, reasonable approximation has been used in both local-sensor filtering and inter-sensor fusion calculation. The overall framework accommodates any Gaussian-oriented fusion approach such as the covariance intersection (CI). Simulation demonstrates the effectiveness of the proposed multi-sensor AA fusion-based $t$ filter in dealing with outliers as compared with the classic Gaussian estimator, and the advantage of the AA fusion in comparison with the CI approach and the augmented measurement fusion.
COCO-CN for Cross-Lingual Image Tagging, Captioning and Retrieval
May 22, 2018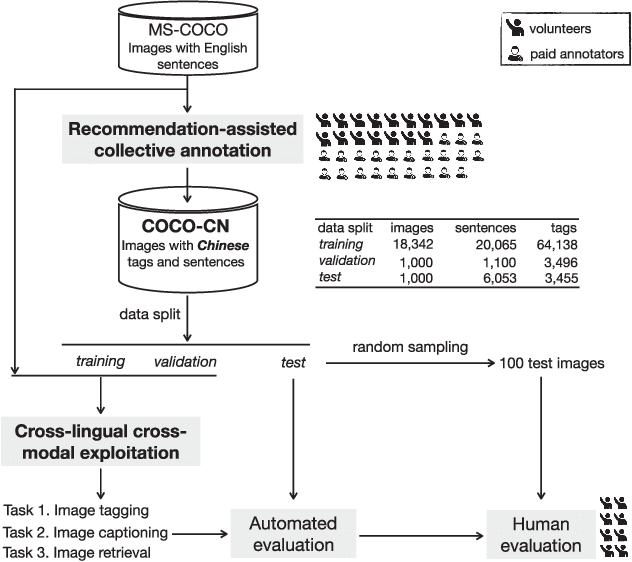
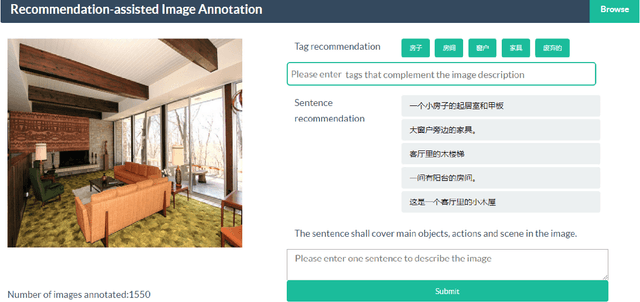
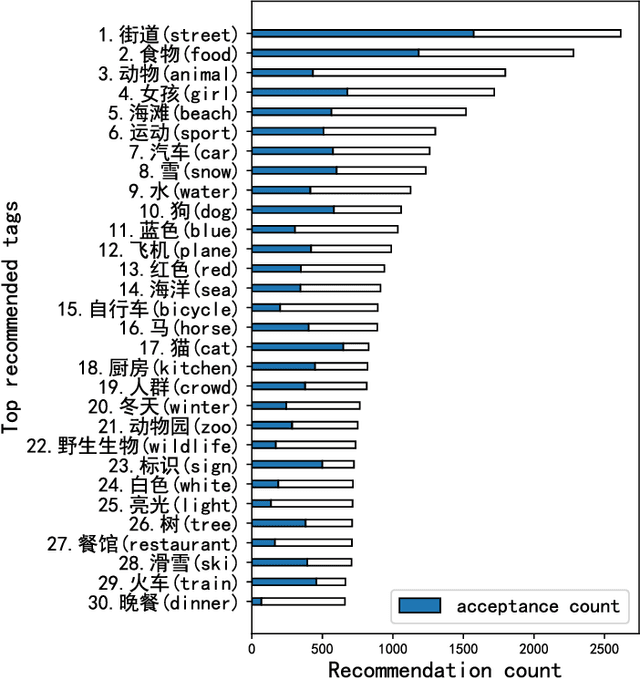
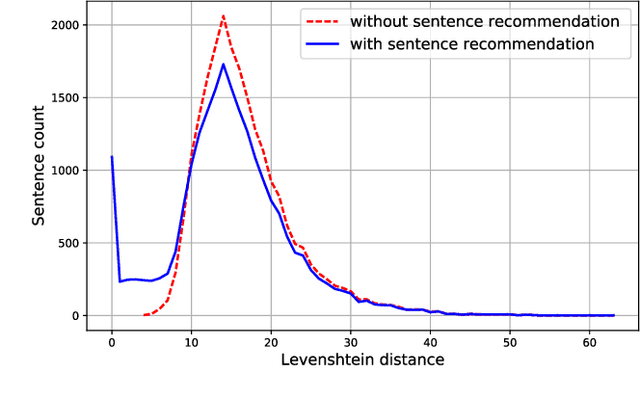
This paper contributes to cross-lingual image annotation and retrieval in terms of data and methods. We propose COCO-CN, a novel dataset enriching MS-COCO with manually written Chinese sentences and tags. For more effective annotation acquisition, we develop a recommendation-assisted collective annotation system, automatically providing an annotator with several tags and sentences deemed to be relevant with respect to the pictorial content. Having 20,342 images annotated with 27,218 Chinese sentences and 70,993 tags, COCO-CN is currently the largest Chinese-English dataset applicable for cross-lingual image tagging, captioning and retrieval. We develop methods per task for effectively learning from cross-lingual resources. Extensive experiments on the multiple tasks justify the viability of our dataset and methods.