 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlueFin: Benchmarking LLM Agents on Financial Spreadsheets
May 29, 2026We present BlueFin, a benchmark that tasks large language model (LLM) agents with synthesis, manipulation, and comprehension tasks over spreadsheet workbooks in the professional finance domain. Though estimates of the global population of paying users of spreadsheet software range in the hundreds of millions -- an order of magnitude more than the estimated global population of professional developers -- comparatively fewer resources have been devoted to exploring and expanding LLM capabilities in the spreadsheet domain, with fewer still dedicated to mirroring real occupational tasks encountered by those in professional finance roles. In response, we curate a set of 131 challenging, complex tasks with real-world relevance in the domain, containing 3,225 granular rubric criteria; notably, our rubric criteria and LM judge evaluations are validated by a team of expert human annotators, resulting in high-quality, granular evaluations of complex tasks that are difficult to verify programmatically but can be reliably evaluated by an LM judge agent. Our judge achieves parity with expert consensus ($α=0.826$) with a macro-F1 score of 0.839. Frontier LLMs demonstrate poor performance on the challenging benchmark, with the strongest LLMs achieving less than 50\% average scores across tasks -- models exhibit particular weaknesses in dynamic correctness. Our contributions include a dataset of examples across three categories of spreadsheet tasks, an open source harness and agentic evaluation framework, and a characterization of existing frontier models' performance on our benchmark.
Energy Considerations of Large Language Model Inference and Efficiency Optimizations
Apr 24, 2025



As large language models (LLMs) scale in size and adoption, their computational and environmental costs continue to rise. Prior benchmarking efforts have primarily focused on latency reduction in idealized settings, often overlooking the diverse real-world inference workloads that shape energy use. In this work, we systematically analyze the energy implications of common inference efficiency optimizations across diverse Natural Language Processing (NLP) and generative Artificial Intelligence (AI) workloads, including conversational AI and code generation. We introduce a modeling approach that approximates real-world LLM workflows through a binning strategy for input-output token distributions and batch size variations. Our empirical analysis spans software frameworks, decoding strategies, GPU architectures, online and offline serving settings, and model parallelism configurations. We show that the effectiveness of inference optimizations is highly sensitive to workload geometry, software stack, and hardware accelerators, demonstrating that naive energy estimates based on FLOPs or theoretical GPU utilization significantly underestimate real-world energy consumption. Our findings reveal that the proper application of relevant inference efficiency optimizations can reduce total energy use by up to 73% from unoptimized baselines. These insights provide a foundation for sustainable LLM deployment and inform energy-efficient design strategies for future AI infrastructure.
Scalable Data Ablation Approximations for Language Models through Modular Training and Merging
Oct 21, 2024



Training data compositions for Large Language Models (LLMs) can significantly affect their downstream performance. However, a thorough data ablation study exploring large sets of candidate data mixtures is typically prohibitively expensive since the full effect is seen only after training the models; this can lead practitioners to settle for sub-optimal data mixtures. We propose an efficient method for approximating data ablations which trains individual models on subsets of a training corpus and reuses them across evaluations of combinations of subsets. In continued pre-training experiments, we find that, given an arbitrary evaluation set, the perplexity score of a single model trained on a candidate set of data is strongly correlated with perplexity scores of parameter averages of models trained on distinct partitions of that data. From this finding, we posit that researchers and practitioners can conduct inexpensive simulations of data ablations by maintaining a pool of models that were each trained on partitions of a large training corpus, and assessing candidate data mixtures by evaluating parameter averages of combinations of these models. This approach allows for substantial improvements in amortized training efficiency -- scaling only linearly with respect to new data -- by enabling reuse of previous training computation, opening new avenues for improving model performance through rigorous, incremental data assessment and mixing.
Energy and Carbon Considerations of Fine-Tuning BERT
Nov 17, 2023



Despite the popularity of the `pre-train then fine-tune' paradigm in the NLP community, existing work quantifying energy costs and associated carbon emissions has largely focused on language model pre-training. Although a single pre-training run draws substantially more energy than fine-tuning, fine-tuning is performed more frequently by many more individual actors, and thus must be accounted for when considering the energy and carbon footprint of NLP. In order to better characterize the role of fine-tuning in the landscape of energy and carbon emissions in NLP, we perform a careful empirical study of the computational costs of fine-tuning across tasks, datasets, hardware infrastructure and measurement modalities. Our experimental results allow us to place fine-tuning energy and carbon costs into perspective with respect to pre-training and inference, and outline recommendations to NLP researchers and practitioners who wish to improve their fine-tuning energy efficiency.
To Build Our Future, We Must Know Our Past: Contextualizing Paradigm Shifts in Natural Language Processing
Oct 11, 2023NLP is in a period of disruptive change that is impacting our methodologies, funding sources, and public perception. In this work, we seek to understand how to shape our future by better understanding our past. We study factors that shape NLP as a field, including culture, incentives, and infrastructure by conducting long-form interviews with 26 NLP researchers of varying seniority, research area, institution, and social identity. Our interviewees identify cyclical patterns in the field, as well as new shifts without historical parallel, including changes in benchmark culture and software infrastructure. We complement this discussion with quantitative analysis of citation, authorship, and language use in the ACL Anthology over time. We conclude by discussing shared visions, concerns, and hopes for the future of NLP. We hope that this study of our field's past and present can prompt informed discussion of our community's implicit norms and more deliberate action to consciously shape the future.
The Framework Tax: Disparities Between Inference Efficiency in Research and Deployment
Feb 13, 2023



Increased focus on the deployment of machine learning systems has led to rapid improvements in hardware accelerator performance and neural network model efficiency. However, the resulting reductions in floating point operations and increases in computational throughput of accelerators have not directly translated to improvements in real-world inference latency. We demonstrate that these discrepancies can be largely attributed to mis-alignments between model architectures and the capabilities of underlying hardware due to bottlenecks introduced by deep learning frameworks. We denote this phenomena as the \textit{framework tax}, and observe that the disparity is growing as hardware speed increases over time. In this work, we examine this phenomena through a series of case studies analyzing the effects of model design decisions, framework paradigms, and hardware platforms on total model latency. Based on our findings, we provide actionable recommendations to ML researchers and practitioners aimed at narrowing the gap between efficient ML model research and practice.
Train Flat, Then Compress: Sharpness-Aware Minimization Learns More Compressible Models
May 25, 2022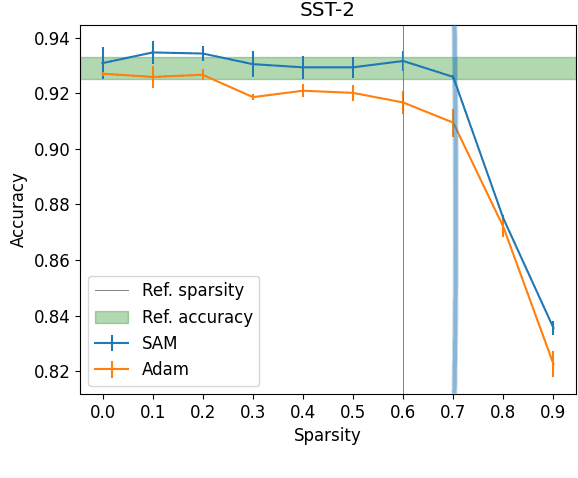
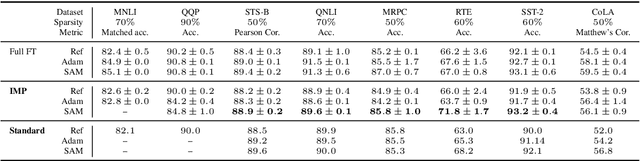
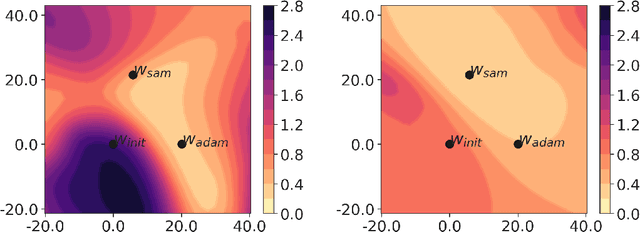
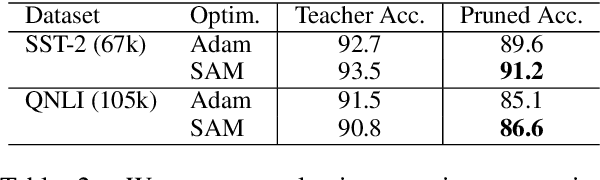
Model compression by way of parameter pruning, quantization, or distillation has recently gained popularity as an approach for reducing the computational requirements of modern deep neural network models for NLP. Pruning unnecessary parameters has emerged as a simple and effective method for compressing large models that is compatible with a wide variety of contemporary off-the-shelf hardware (unlike quantization), and that requires little additional training (unlike distillation). Pruning approaches typically take a large, accurate model as input, then attempt to discover a smaller subnetwork of that model capable of achieving end-task accuracy comparable to the full model. Inspired by previous work suggesting a connection between simpler, more generalizable models and those that lie within flat basins in the loss landscape, we propose to directly optimize for flat minima while performing task-specific pruning, which we hypothesize should lead to simpler parameterizations and thus more compressible models. In experiments combining sharpness-aware minimization with both iterative magnitude pruning and structured pruning approaches, we show that optimizing for flat minima consistently leads to greater compressibility of parameters compared to standard Adam optimization when fine-tuning BERT models, leading to higher rates of compression with little to no loss in accuracy on the GLUE classification benchmark.