 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Face Attributes in the Wild
Sep 24, 2015
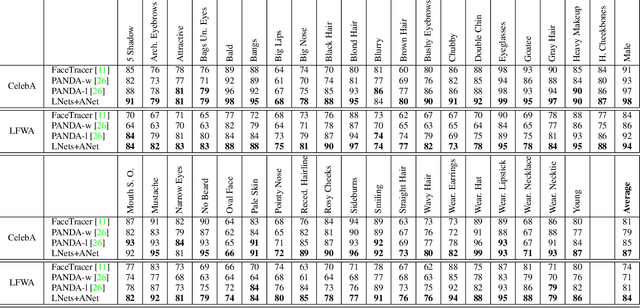
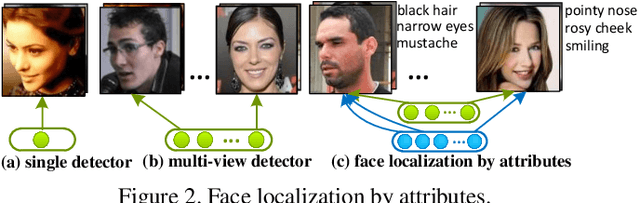
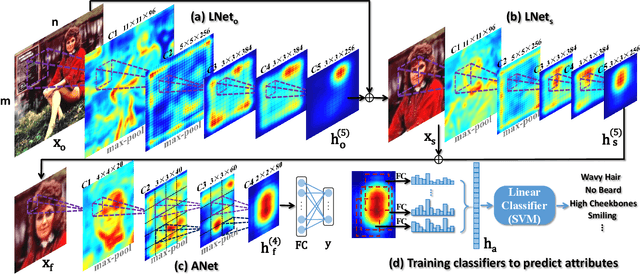
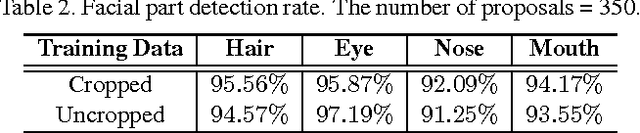
Predicting face attributes in the wild is challenging due to complex face variations. We propose a novel deep learning framework for attribute prediction in the wild. It cascades two CNNs, LNet and ANet, which are fine-tuned jointly with attribute tags, but pre-trained differently. LNet is pre-trained by massive general object categories for face localization, while ANet is pre-trained by massive face identities for attribute prediction. This framework not only outperforms the state-of-the-art with a large margin, but also reveals valuable facts on learning face representation. (1) It shows how the performances of face localization (LNet) and attribute prediction (ANet) can be improved by different pre-training strategies. (2) It reveals that although the filters of LNet are fine-tuned only with image-level attribute tags, their response maps over entire images have strong indication of face locations. This fact enables training LNet for face localization with only image-level annotations, but without face bounding boxes or landmarks, which are required by all attribute recognition works. (3) It also demonstrates that the high-level hidden neurons of ANet automatically discover semantic concepts after pre-training with massive face identities, and such concepts are significantly enriched after fine-tuning with attribute tags. Each attribute can be well explained with a sparse linear combination of these concepts.
A Large-Scale Car Dataset for Fine-Grained Categorization and Verification
Sep 24, 2015


Updated on 24/09/2015: This update provides preliminary experiment results for fine-grained classification on the surveillance data of CompCars. The train/test splits are provided in the updated dataset. See details in Section 6.
From Facial Parts Responses to Face Detection: A Deep Learning Approach
Sep 22, 2015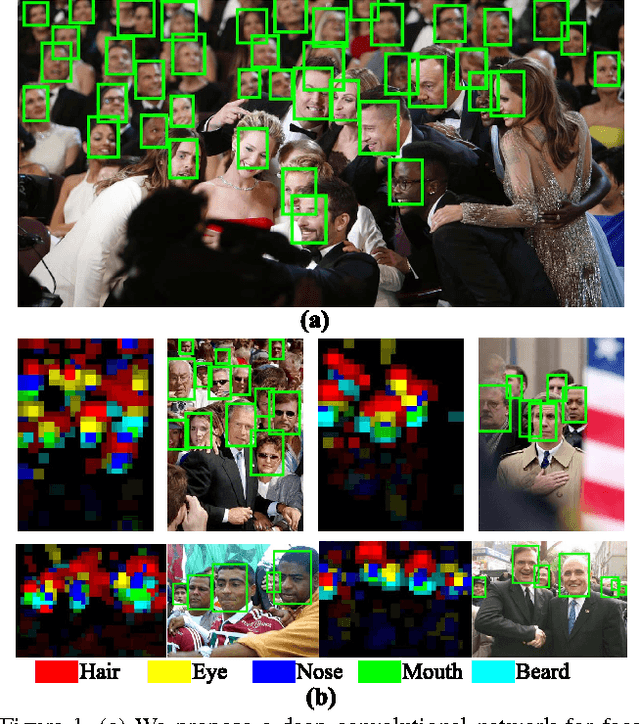

In this paper, we propose a novel deep convolutional network (DCN) that achieves outstanding performance on FDDB, PASCAL Face, and AFW. Specifically, our method achieves a high recall rate of 90.99% on the challenging FDDB benchmark, outperforming the state-of-the-art method by a large margin of 2.91%. Importantly, we consider finding faces from a new perspective through scoring facial parts responses by their spatial structure and arrangement. The scoring mechanism is carefully formulated considering challenging cases where faces are only partially visible. This consideration allows our network to detect faces under severe occlusion and unconstrained pose variation, which are the main difficulty and bottleneck of most existing face detection approaches. We show that despite the use of DCN, our network can achieve practical runtime speed.
Learning Social Relation Traits from Face Images
Sep 14, 2015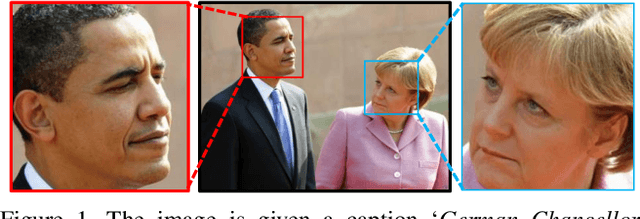



Social relation defines the association, e.g, warm, friendliness, and dominance, between two or more people. Motivated by psychological studies, we investigate if such fine-grained and high-level relation traits can be characterised and quantified from face images in the wild. To address this challenging problem we propose a deep model that learns a rich face representation to capture gender, expression, head pose, and age-related attributes, and then performs pairwise-face reasoning for relation prediction. To learn from heterogeneous attribute sources, we formulate a new network architecture with a bridging layer to leverage the inherent correspondences among these datasets. It can also cope with missing target attribute labels. Extensive experiments show that our approach is effective for fine-grained social relation learning in images and videos.
Learning Deep Representation for Face Alignment with Auxiliary Attributes
Aug 11, 2015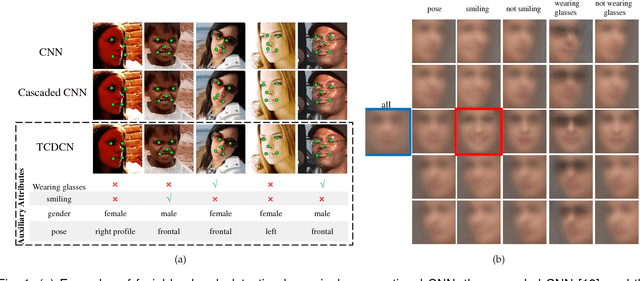
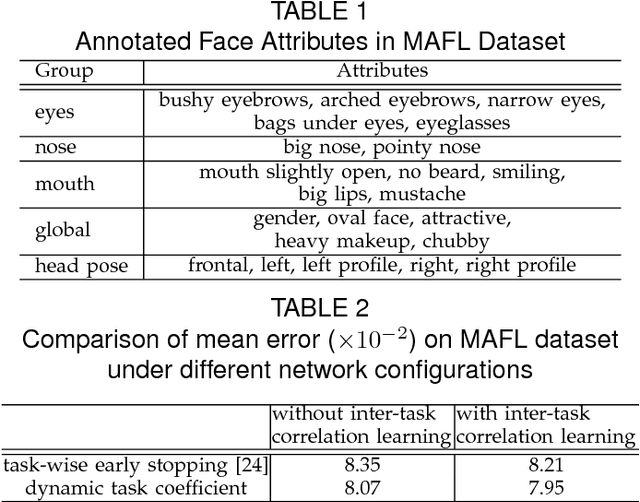
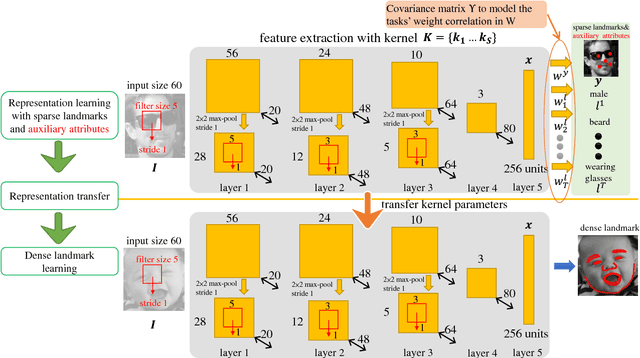

In this study, we show that landmark detection or face alignment task is not a single and independent problem. Instead, its robustness can be greatly improved with auxiliary information. Specifically, we jointly optimize landmark detection together with the recognition of heterogeneous but subtly correlated facial attributes, such as gender, expression, and appearance attributes. This is non-trivial since different attribute inference tasks have different learning difficulties and convergence rates. To address this problem, we formulate a novel tasks-constrained deep model, which not only learns the inter-task correlation but also employs dynamic task coefficients to facilitate the optimization convergence when learning multiple complex tasks. Extensive evaluations show that the proposed task-constrained learning (i) outperforms existing face alignment methods, especially in dealing with faces with severe occlusion and pose variation, and (ii) reduces model complexity drastically compared to the state-of-the-art methods based on cascaded deep model.
Image Super-Resolution Using Deep Convolutional Networks
Jul 31, 2015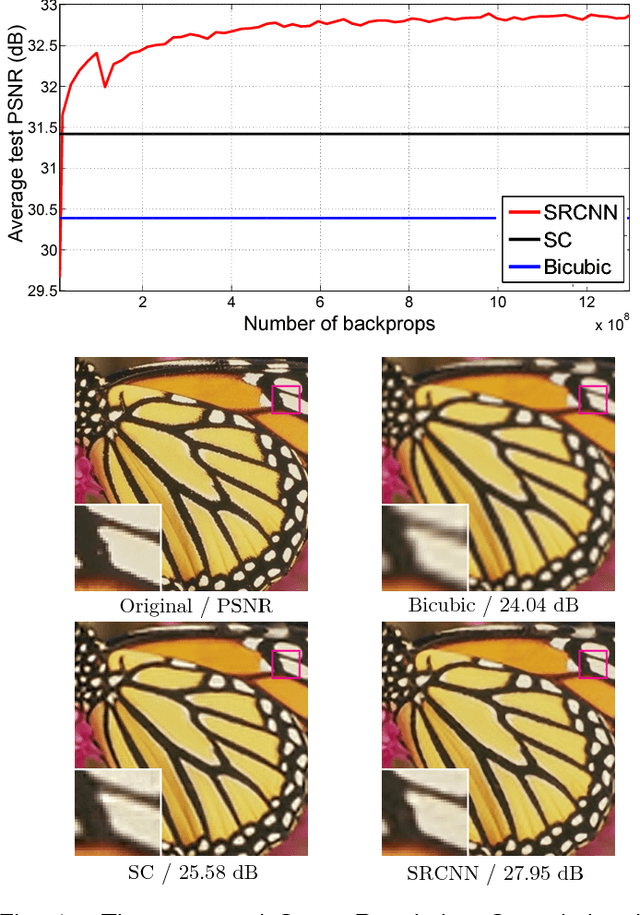
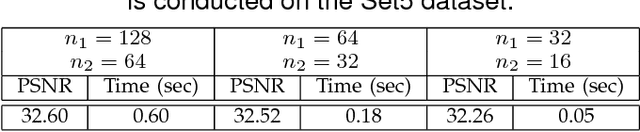
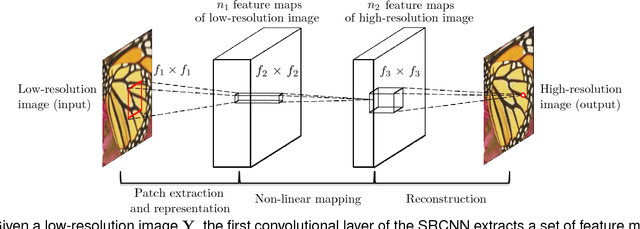
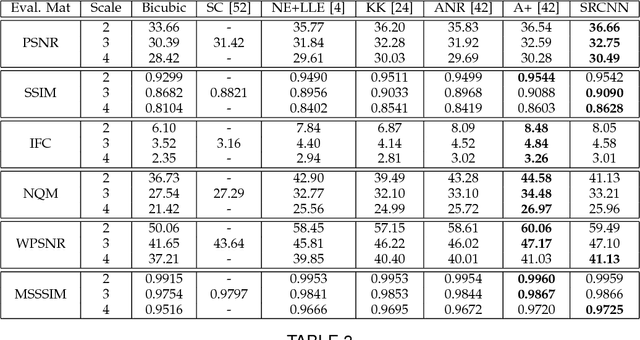
We propose a deep learning method for single image super-resolution (SR). Our method directly learns an end-to-end mapping between the low/high-resolution images. The mapping is represented as a deep convolutional neural network (CNN) that takes the low-resolution image as the input and outputs the high-resolution one. We further show that traditional sparse-coding-based SR methods can also be viewed as a deep convolutional network. But unlike traditional methods that handle each component separately, our method jointly optimizes all layers. Our deep CNN has a lightweight structure, yet demonstrates state-of-the-art restoration quality, and achieves fast speed for practical on-line usage. We explore different network structures and parameter settings to achieve trade-offs between performance and speed. Moreover, we extend our network to cope with three color channels simultaneously, and show better overall reconstruction quality.
DeepID-Net: Deformable Deep Convolutional Neural Networks for Object Detection
Jun 02, 2015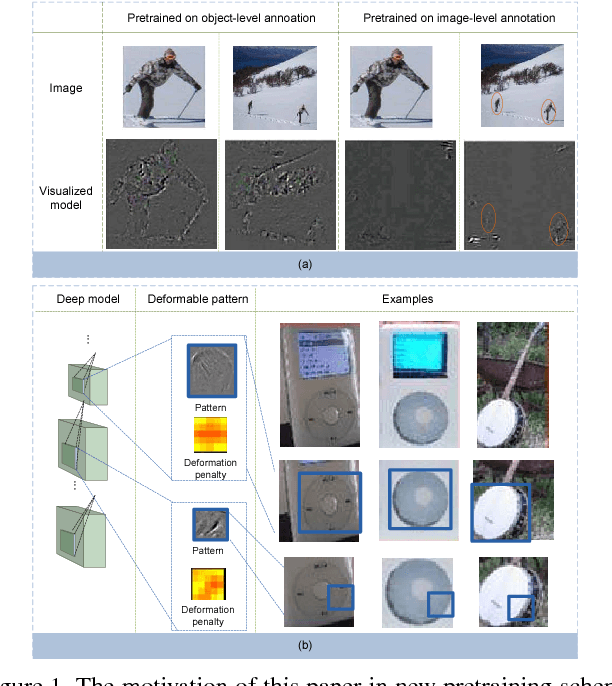
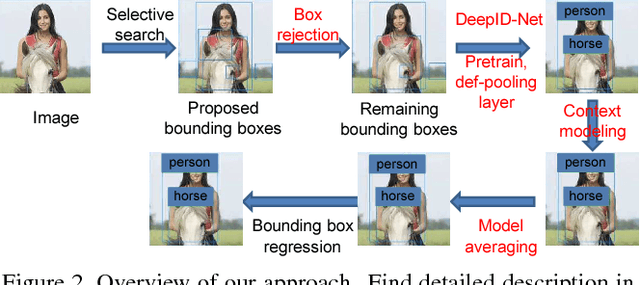
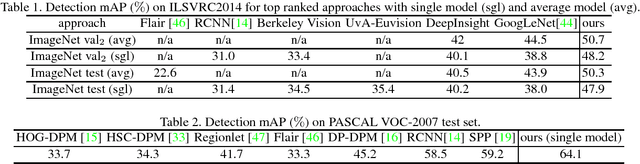
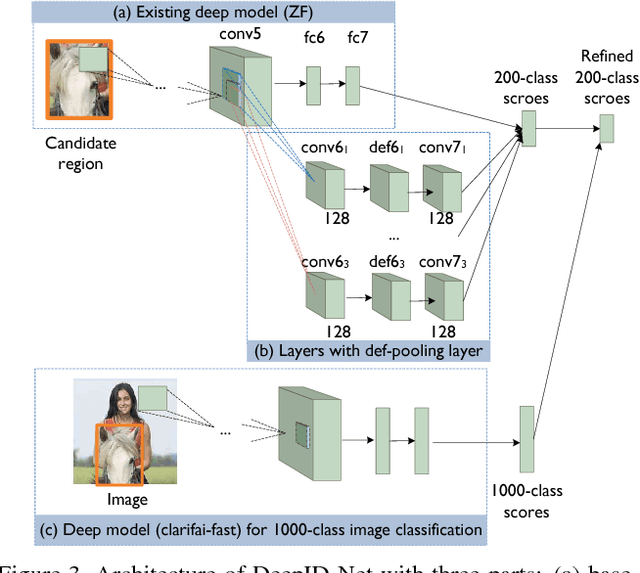
In this paper, we propose deformable deep convolutional neural networks for generic object detection. This new deep learning object detection framework has innovations in multiple aspects. In the proposed new deep architecture, a new deformation constrained pooling (def-pooling) layer models the deformation of object parts with geometric constraint and penalty. A new pre-training strategy is proposed to learn feature representations more suitable for the object detection task and with good generalization capability. By changing the net structures, training strategies, adding and removing some key components in the detection pipeline, a set of models with large diversity are obtained, which significantly improves the effectiveness of model averaging. The proposed approach improves the mean averaged precision obtained by RCNN \cite{girshick2014rich}, which was the state-of-the-art, from 31\% to 50.3\% on the ILSVRC2014 detection test set. It also outperforms the winner of ILSVRC2014, GoogLeNet, by 6.1\%. Detailed component-wise analysis is also provided through extensive experimental evaluation, which provide a global view for people to understand the deep learning object detection pipeline.
Action Recognition with Trajectory-Pooled Deep-Convolutional Descriptors
May 19, 2015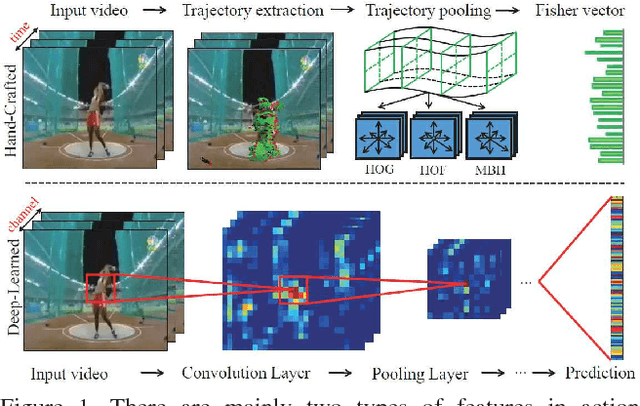

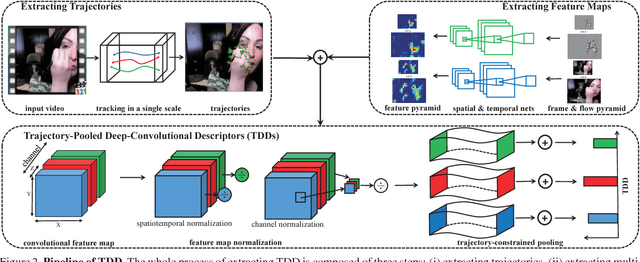

Visual features are of vital importance for human action understanding in videos. This paper presents a new video representation, called trajectory-pooled deep-convolutional descriptor (TDD), which shares the merits of both hand-crafted features and deep-learned features. Specifically, we utilize deep architectures to learn discriminative convolutional feature maps, and conduct trajectory-constrained pooling to aggregate these convolutional features into effective descriptors. To enhance the robustness of TDDs, we design two normalization methods to transform convolutional feature maps, namely spatiotemporal normalization and channel normalization. The advantages of our features come from (i) TDDs are automatically learned and contain high discriminative capacity compared with those hand-crafted features; (ii) TDDs take account of the intrinsic characteristics of temporal dimension and introduce the strategies of trajectory-constrained sampling and pooling for aggregating deep-learned features. We conduct experiments on two challenging datasets: HMDB51 and UCF101. Experimental results show that TDDs outperform previous hand-crafted features and deep-learned features. Our method also achieves superior performance to the state of the art on these datasets (HMDB51 65.9%, UCF101 91.5%).
Learning to Recognize Pedestrian Attribute
Apr 29, 2015
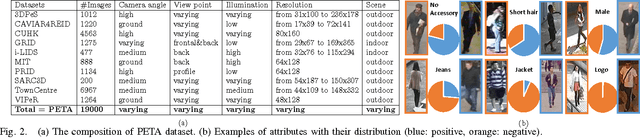
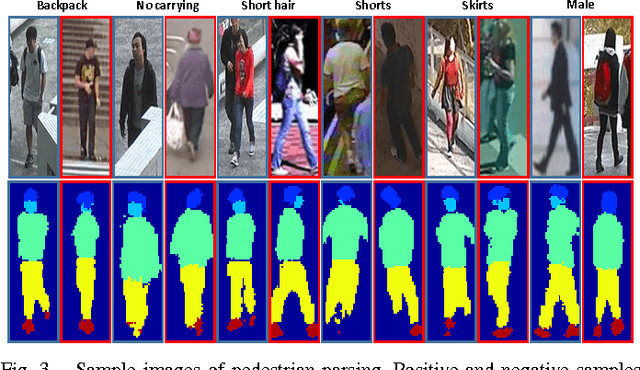

Learning to recognize pedestrian attributes at far distance is a challenging problem in visual surveillance since face and body close-shots are hardly available; instead, only far-view image frames of pedestrian are given. In this study, we present an alternative approach that exploits the context of neighboring pedestrian images for improved attribute inference compared to the conventional SVM-based method. In addition, we conduct extensive experiments to evaluate the informativeness of background and foreground features for attribute recognition. Experiments are based on our newly released pedestrian attribute dataset, which is by far the largest and most diverse of its kind.
Compression Artifacts Reduction by a Deep Convolutional Network
Apr 27, 2015
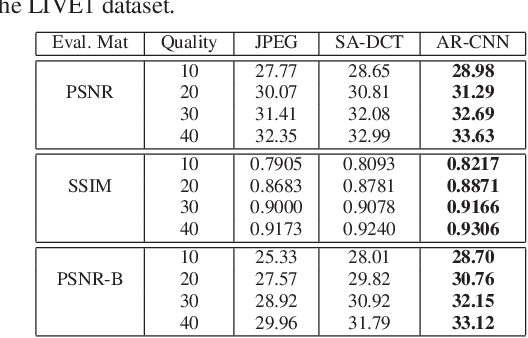
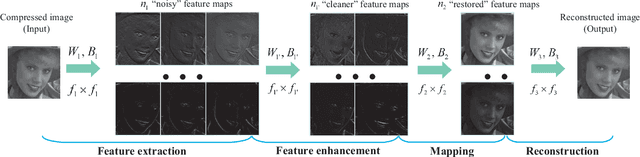
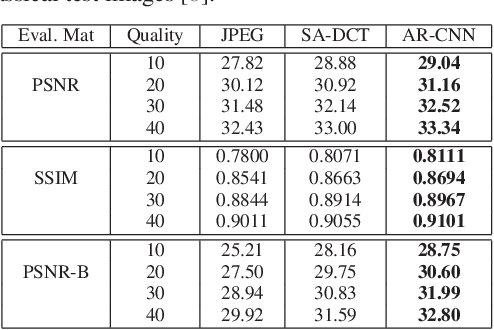
Lossy compression introduces complex compression artifacts, particularly the blocking artifacts, ringing effects and blurring. Existing algorithms either focus on removing blocking artifacts and produce blurred output, or restores sharpened images that are accompanied with ringing effects. Inspired by the deep convolutional networks (DCN) on super-resolution, we formulate a compact and efficient network for seamless attenuation of different compression artifacts. We also demonstrate that a deeper model can be effectively trained with the features learned in a shallow network. Following a similar "easy to hard" idea, we systematically investigate several practical transfer settings and show the effectiveness of transfer learning in low-level vision problems. Our method shows superior performance than the state-of-the-arts both on the benchmark datasets and the real-world use case (i.e. Twitter). In addition, we show that our method can be applied as pre-processing to facilitate other low-level vision routines when they take compressed images as input.