 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
Oracle Bone Inscriptions Multi-modal Dataset
Jul 04, 2024

Oracle bone inscriptions(OBI) is the earliest developed writing system in China, bearing invaluable written exemplifications of early Shang history and paleography. However, the task of deciphering OBI, in the current climate of the scholarship, can prove extremely challenging. Out of the 4,500 oracle bone characters excavated, only a third have been successfully identified. Therefore, leveraging the advantages of advanced AI technology to assist in the decipherment of OBI is a highly essential research topic. However, fully utilizing AI's capabilities in these matters is reliant on having a comprehensive and high-quality annotated OBI dataset at hand whereas most existing datasets are only annotated in just a single or a few dimensions, limiting the value of their potential application. For instance, the Oracle-MNIST dataset only offers 30k images classified into 10 categories. Therefore, this paper proposes an Oracle Bone Inscriptions Multi-modal Dataset(OBIMD), which includes annotation information for 10,077 pieces of oracle bones. Each piece has two modalities: pixel-level aligned rubbings and facsimiles. The dataset annotates the detection boxes, character categories, transcriptions, corresponding inscription groups, and reading sequences in the groups of each oracle bone character, providing a comprehensive and high-quality level of annotations. This dataset can be used for a variety of AI-related research tasks relevant to the field of OBI, such as OBI Character Detection and Recognition, Rubbing Denoising, Character Matching, Character Generation, Reading Sequence Prediction, Missing Characters Completion task and so on. We believe that the creation and publication of a dataset like this will help significantly advance the application of AI algorithms in the field of OBI research.
IFRNet: Intermediate Feature Refine Network for Efficient Frame Interpolation
May 29, 2022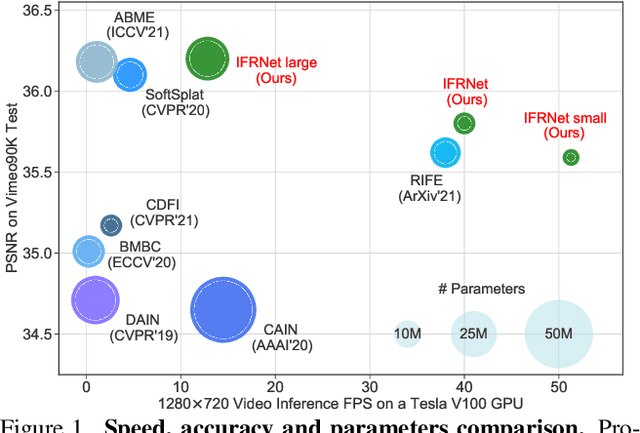
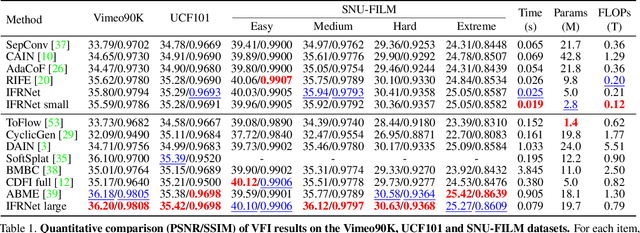

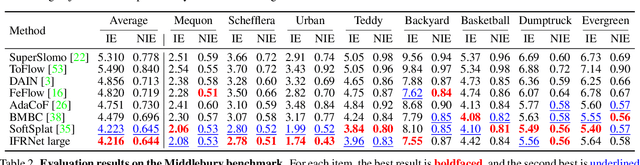
Prevailing video frame interpolation algorithms, that generate the intermediate frames from consecutive inputs, typically rely on complex model architectures with heavy parameters or large delay, hindering them from diverse real-time applications. In this work, we devise an efficient encoder-decoder based network, termed IFRNet, for fast intermediate frame synthesizing. It first extracts pyramid features from given inputs, and then refines the bilateral intermediate flow fields together with a powerful intermediate feature until generating the desired output. The gradually refined intermediate feature can not only facilitate intermediate flow estimation, but also compensate for contextual details, making IFRNet do not need additional synthesis or refinement module. To fully release its potential, we further propose a novel task-oriented optical flow distillation loss to focus on learning the useful teacher knowledge towards frame synthesizing. Meanwhile, a new geometry consistency regularization term is imposed on the gradually refined intermediate features to keep better structure layout. Experiments on various benchmarks demonstrate the excellent performance and fast inference speed of proposed approaches. Code is available at https://github.com/ltkong218/IFRNet.
ASFD: Automatic and Scalable Face Detector
Jan 26, 2022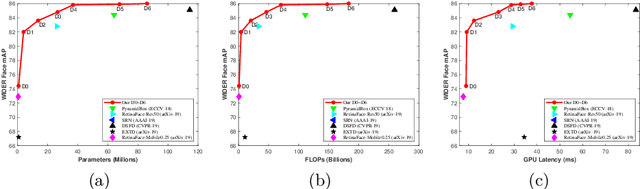

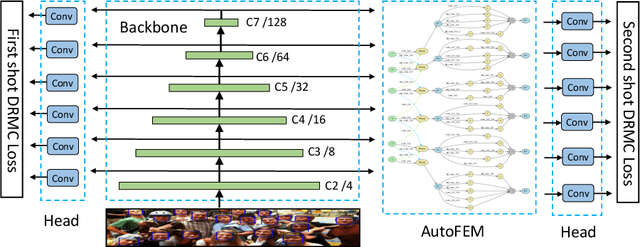
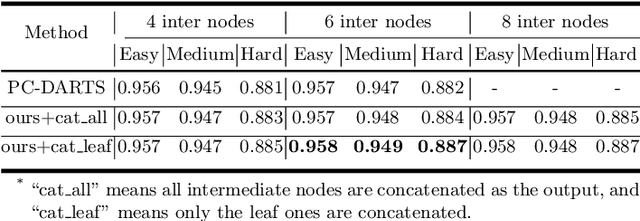
Along with current multi-scale based detectors, Feature Aggregation and Enhancement (FAE) modules have shown superior performance gains for cutting-edge object detection. However, these hand-crafted FAE modules show inconsistent improvements on face detection, which is mainly due to the significant distribution difference between its training and applying corpus, COCO vs. WIDER Face. To tackle this problem, we essentially analyse the effect of data distribution, and consequently propose to search an effective FAE architecture, termed AutoFAE by a differentiable architecture search, which outperforms all existing FAE modules in face detection with a considerable margin. Upon the found AutoFAE and existing backbones, a supernet is further built and trained, which automatically obtains a family of detectors under the different complexity constraints. Extensive experiments conducted on popular benchmarks, WIDER Face and FDDB, demonstrate the state-of-the-art performance-efficiency trade-off for the proposed automatic and scalable face detector (ASFD) family. In particular, our strong ASFD-D6 outperforms the best competitor with AP 96.7/96.2/92.1 on WIDER Face test, and the lightweight ASFD-D0 costs about 3.1 ms, more than 320 FPS, on the V100 GPU with VGA-resolution images.