 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAN: Learning Adaptive Neighbors for Real-Time Insider Threat Detection
Mar 17, 2024



Enterprises and organizations are faced with potential threats from insider employees that may lead to serious consequences. Previous studies on insider threat detection (ITD) mainly focus on detecting abnormal users or abnormal time periods (e.g., a week or a day). However, a user may have hundreds of thousands of activities in the log, and even within a day there may exist thousands of activities for a user, requiring a high investigation budget to verify abnormal users or activities given the detection results. On the other hand, existing works are mainly post-hoc methods rather than real-time detection, which can not report insider threats in time before they cause loss. In this paper, we conduct the first study towards real-time ITD at activity level, and present a fine-grained and efficient framework LAN. Specifically, LAN simultaneously learns the temporal dependencies within an activity sequence and the relationships between activities across sequences with graph structure learning. Moreover, to mitigate the data imbalance problem in ITD, we propose a novel hybrid prediction loss, which integrates self-supervision signals from normal activities and supervision signals from abnormal activities into a unified loss for anomaly detection. We evaluate the performance of LAN on two widely used datasets, i.e., CERT r4.2 and CERT r5.2. Extensive and comparative experiments demonstrate the superiority of LAN, outperforming 9 state-of-the-art baselines by at least 9.92% and 6.35% in AUC for real-time ITD on CERT r4.2 and r5.2, respectively. Moreover, LAN can be also applied to post-hoc ITD, surpassing 8 competitive baselines by at least 7.70% and 4.03% in AUC on two datasets. Finally, the ablation study, parameter analysis, and compatibility analysis evaluate the impact of each module and hyper-parameter in LAN. The source code can be obtained from https://github.com/Li1Neo/LAN.
Learning Time Slot Preferences via Mobility Tree for Next POI Recommendation
Mar 17, 2024



Next Point-of-Interests (POIs) recommendation task aims to provide a dynamic ranking of POIs based on users' current check-in trajectories. The recommendation performance of this task is contingent upon a comprehensive understanding of users' personalized behavioral patterns through Location-based Social Networks (LBSNs) data. While prior studies have adeptly captured sequential patterns and transitional relationships within users' check-in trajectories, a noticeable gap persists in devising a mechanism for discerning specialized behavioral patterns during distinct time slots, such as noon, afternoon, or evening. In this paper, we introduce an innovative data structure termed the ``Mobility Tree'', tailored for hierarchically describing users' check-in records. The Mobility Tree encompasses multi-granularity time slot nodes to learn user preferences across varying temporal periods. Meanwhile, we propose the Mobility Tree Network (MTNet), a multitask framework for personalized preference learning based on Mobility Trees. We develop a four-step node interaction operation to propagate feature information from the leaf nodes to the root node. Additionally, we adopt a multitask training strategy to push the model towards learning a robust representation. The comprehensive experimental results demonstrate the superiority of MTNet over ten state-of-the-art next POI recommendation models across three real-world LBSN datasets, substantiating the efficacy of time slot preference learning facilitated by Mobility Tree.
AoM: Detecting Aspect-oriented Information for Multimodal Aspect-Based Sentiment Analysis
May 31, 2023Multimodal aspect-based sentiment analysis (MABSA) aims to extract aspects from text-image pairs and recognize their sentiments. Existing methods make great efforts to align the whole image to corresponding aspects. However, different regions of the image may relate to different aspects in the same sentence, and coarsely establishing image-aspect alignment will introduce noise to aspect-based sentiment analysis (i.e., visual noise). Besides, the sentiment of a specific aspect can also be interfered by descriptions of other aspects (i.e., textual noise). Considering the aforementioned noises, this paper proposes an Aspect-oriented Method (AoM) to detect aspect-relevant semantic and sentiment information. Specifically, an aspect-aware attention module is designed to simultaneously select textual tokens and image blocks that are semantically related to the aspects. To accurately aggregate sentiment information, we explicitly introduce sentiment embedding into AoM, and use a graph convolutional network to model the vision-text and text-text interaction. Extensive experiments demonstrate the superiority of AoM to existing methods. The source code is publicly released at https://github.com/SilyRab/AoM.
TreeMAN: Tree-enhanced Multimodal Attention Network for ICD Coding
May 29, 2023



ICD coding is designed to assign the disease codes to electronic health records (EHRs) upon discharge, which is crucial for billing and clinical statistics. In an attempt to improve the effectiveness and efficiency of manual coding, many methods have been proposed to automatically predict ICD codes from clinical notes. However, most previous works ignore the decisive information contained in structured medical data in EHRs, which is hard to be captured from the noisy clinical notes. In this paper, we propose a Tree-enhanced Multimodal Attention Network (TreeMAN) to fuse tabular features and textual features into multimodal representations by enhancing the text representations with tree-based features via the attention mechanism. Tree-based features are constructed according to decision trees learned from structured multimodal medical data, which capture the decisive information about ICD coding. We can apply the same multi-label classifier from previous text models to the multimodal representations to predict ICD codes. Experiments on two MIMIC datasets show that our method outperforms prior state-of-the-art ICD coding approaches. The code is available at https://github.com/liu-zichen/TreeMAN.
From Alignment to Entailment: A Unified Textual Entailment Framework for Entity Alignment
May 19, 2023



Entity Alignment (EA) aims to find the equivalent entities between two Knowledge Graphs (KGs). Existing methods usually encode the triples of entities as embeddings and learn to align the embeddings, which prevents the direct interaction between the original information of the cross-KG entities. Moreover, they encode the relational triples and attribute triples of an entity in heterogeneous embedding spaces, which prevents them from helping each other. In this paper, we transform both triples into unified textual sequences, and model the EA task as a bi-directional textual entailment task between the sequences of cross-KG entities. Specifically, we feed the sequences of two entities simultaneously into a pre-trained language model (PLM) and propose two kinds of PLM-based entity aligners that model the entailment probability between sequences as the similarity between entities. Our approach captures the unified correlation pattern of two kinds of information between entities, and explicitly models the fine-grained interaction between original entity information. The experiments on five cross-lingual EA datasets show that our approach outperforms the state-of-the-art EA methods and enables the mutual enhancement of the heterogeneous information. Codes are available at https://github.com/OreOZhao/TEA.
HGWaveNet: A Hyperbolic Graph Neural Network for Temporal Link Prediction
May 03, 2023Temporal link prediction, aiming to predict future edges between paired nodes in a dynamic graph, is of vital importance in diverse applications. However, existing methods are mainly built upon uniform Euclidean space, which has been found to be conflict with the power-law distributions of real-world graphs and unable to represent the hierarchical connections between nodes effectively. With respect to the special data characteristic, hyperbolic geometry offers an ideal alternative due to its exponential expansion property. In this paper, we propose HGWaveNet, a novel hyperbolic graph neural network that fully exploits the fitness between hyperbolic spaces and data distributions for temporal link prediction. Specifically, we design two key modules to learn the spatial topological structures and temporal evolutionary information separately. On the one hand, a hyperbolic diffusion graph convolution (HDGC) module effectively aggregates information from a wider range of neighbors. On the other hand, the internal order of causal correlation between historical states is captured by hyperbolic dilated causal convolution (HDCC) modules. The whole model is built upon the hyperbolic spaces to preserve the hierarchical structural information in the entire data flow. To prove the superiority of HGWaveNet, extensive experiments are conducted on six real-world graph datasets and the results show a relative improvement by up to 6.67% on AUC for temporal link prediction over SOTA methods.
* Accepted by Web Conference (WWW) 2023
H2TNE: Temporal Heterogeneous Information Network Embedding in Hyperbolic Spaces
Apr 18, 2023Temporal heterogeneous information network (temporal HIN) embedding, aiming to represent various types of nodes of different timestamps into low dimensional spaces while preserving structural and semantic information, is of vital importance in diverse real-life tasks. Researchers have made great efforts on temporal HIN embedding in Euclidean spaces and got some considerable achievements. However, there is always a fundamental conflict that many real-world networks show hierarchical property and power-law distribution, and are not isometric of Euclidean spaces. Recently, representation learning in hyperbolic spaces has been proved to be valid for data with hierarchical and power-law structure. Inspired by this character, we propose a hyperbolic heterogeneous temporal network embedding (H2TNE) model for temporal HINs. Specifically, we leverage a temporally and heterogeneously double-constrained random walk strategy to capture the structural and semantic information, and then calculate the embedding by exploiting hyperbolic distance in proximity measurement. Experimental results show that our method has superior performance on temporal link prediction and node classification compared with SOTA models.
Joint Open Knowledge Base Canonicalization and Linking
Dec 02, 2022Open Information Extraction (OIE) methods extract a large number of OIE triples (noun phrase, relation phrase, noun phrase) from text, which compose large Open Knowledge Bases (OKBs). However, noun phrases (NPs) and relation phrases (RPs) in OKBs are not canonicalized and often appear in different paraphrased textual variants, which leads to redundant and ambiguous facts. To address this problem, there are two related tasks: OKB canonicalization (i.e., convert NPs and RPs to canonicalized form) and OKB linking (i.e., link NPs and RPs with their corresponding entities and relations in a curated Knowledge Base (e.g., DBPedia). These two tasks are tightly coupled, and one task can benefit significantly from the other. However, they have been studied in isolation so far. In this paper, we explore the task of joint OKB canonicalization and linking for the first time, and propose a novel framework JOCL based on factor graph model to make them reinforce each other. JOCL is flexible enough to combine different signals from both tasks, and able to extend to fit any new signals. A thorough experimental study over two large scale OIE triple data sets shows that our framework outperforms all the baseline methods for the task of OKB canonicalization (OKB linking) in terms of average F1 (accuracy).
BadPrompt: Backdoor Attacks on Continuous Prompts
Nov 27, 2022



The prompt-based learning paradigm has gained much research attention recently. It has achieved state-of-the-art performance on several NLP tasks, especially in the few-shot scenarios. While steering the downstream tasks, few works have been reported to investigate the security problems of the prompt-based models. In this paper, we conduct the first study on the vulnerability of the continuous prompt learning algorithm to backdoor attacks. We observe that the few-shot scenarios have posed a great challenge to backdoor attacks on the prompt-based models, limiting the usability of existing NLP backdoor methods. To address this challenge, we propose BadPrompt, a lightweight and task-adaptive algorithm, to backdoor attack continuous prompts. Specially, BadPrompt first generates candidate triggers which are indicative for predicting the targeted label and dissimilar to the samples of the non-targeted labels. Then, it automatically selects the most effective and invisible trigger for each sample with an adaptive trigger optimization algorithm. We evaluate the performance of BadPrompt on five datasets and two continuous prompt models. The results exhibit the abilities of BadPrompt to effectively attack continuous prompts while maintaining high performance on the clean test sets, outperforming the baseline models by a large margin. The source code of BadPrompt is publicly available at https://github.com/papersPapers/BadPrompt.
Overcoming Language Priors in Visual Question Answering via Distinguishing Superficially Similar Instances
Sep 18, 2022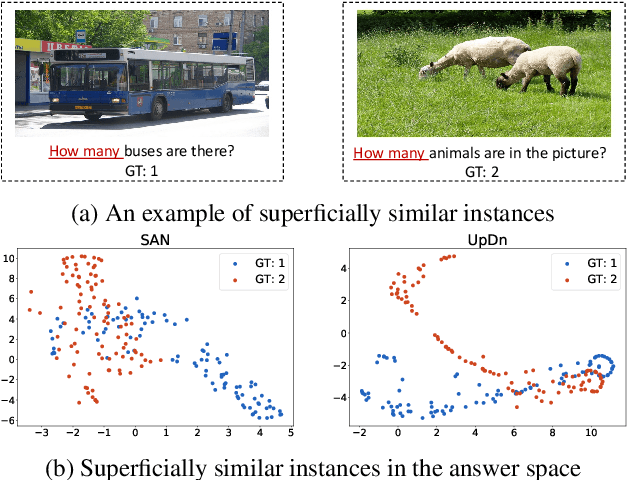
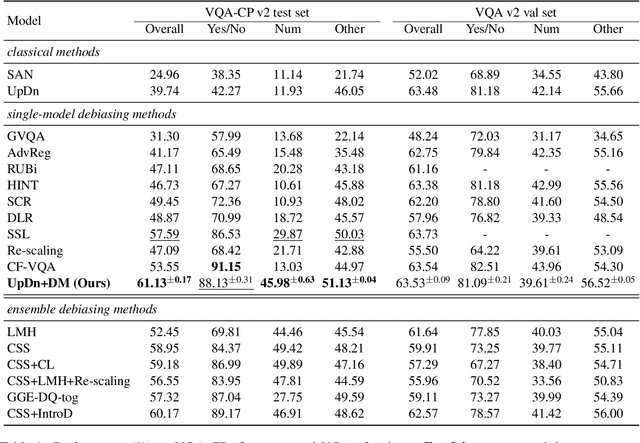
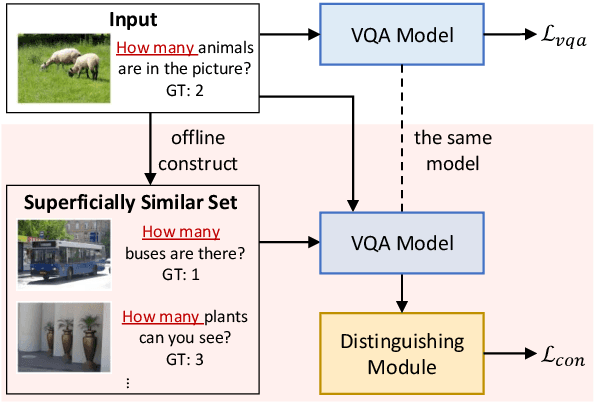
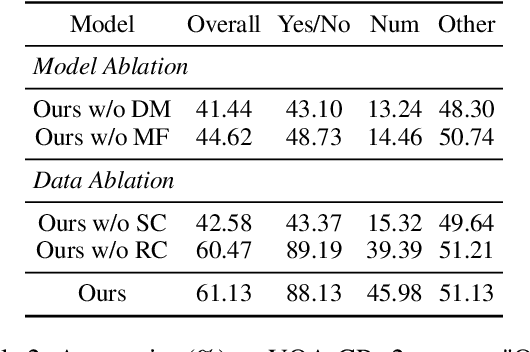
Despite the great progress of Visual Question Answering (VQA), current VQA models heavily rely on the superficial correlation between the question type and its corresponding frequent answers (i.e., language priors) to make predictions, without really understanding the input. In this work, we define the training instances with the same question type but different answers as \textit{superficially similar instances}, and attribute the language priors to the confusion of VQA model on such instances. To solve this problem, we propose a novel training framework that explicitly encourages the VQA model to distinguish between the superficially similar instances. Specifically, for each training instance, we first construct a set that contains its superficially similar counterparts. Then we exploit the proposed distinguishing module to increase the distance between the instance and its counterparts in the answer space. In this way, the VQA model is forced to further focus on the other parts of the input beyond the question type, which helps to overcome the language priors. Experimental results show that our method achieves the state-of-the-art performance on VQA-CP v2. Codes are available at \href{https://github.com/wyk-nku/Distinguishing-VQA.git}{Distinguishing-VQA}.