 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaofei Xie
Neural Episodic Control with State Abstraction
Jan 27, 2023

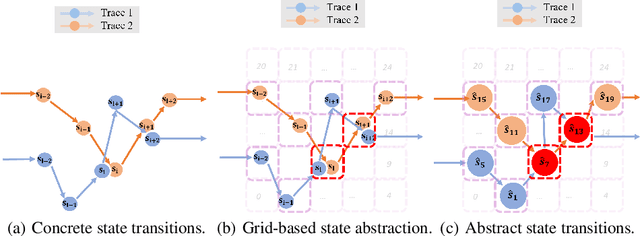
Existing Deep Reinforcement Learning (DRL) algorithms suffer from sample inefficiency. Generally, episodic control-based approaches are solutions that leverage highly-rewarded past experiences to improve sample efficiency of DRL algorithms. However, previous episodic control-based approaches fail to utilize the latent information from the historical behaviors (e.g., state transitions, topological similarities, etc.) and lack scalability during DRL training. This work introduces Neural Episodic Control with State Abstraction (NECSA), a simple but effective state abstraction-based episodic control containing a more comprehensive episodic memory, a novel state evaluation, and a multi-step state analysis. We evaluate our approach to the MuJoCo and Atari tasks in OpenAI gym domains. The experimental results indicate that NECSA achieves higher sample efficiency than the state-of-the-art episodic control-based approaches. Our data and code are available at the project website\footnote{\url{https://sites.google.com/view/drl-necsa}}.
Is Self-Attention Powerful to Learn Code Syntax and Semantics?
Dec 20, 2022

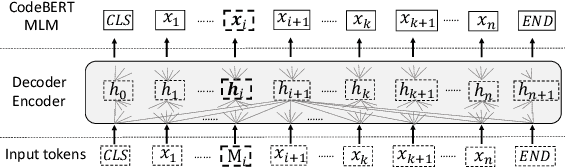
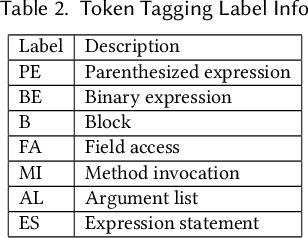
Pre-trained language models for programming languages have shown a powerful ability on processing many Software Engineering (SE) tasks, e.g., program synthesis, code completion, and code search. However, it remains to be seen what is behind their success. Recent studies have examined how pre-trained models can effectively learn syntax information based on Abstract Syntax Trees. In this paper, we figure out what role the self-attention mechanism plays in understanding code syntax and semantics based on AST and static analysis. We focus on a well-known representative code model, CodeBERT, and study how it can learn code syntax and semantics by the self-attention mechanism and Masked Language Modelling (MLM) at the token level. We propose a group of probing tasks to analyze CodeBERT. Based on AST and static analysis, we establish the relationships among the code tokens. First, Our results show that CodeBERT can acquire syntax and semantics knowledge through self-attention and MLM. Second, we demonstrate that the self-attention mechanism pays more attention to dependence-relationship tokens than to other tokens. Different attention heads play different roles in learning code semantics; we show that some of them are weak at encoding code semantics. Different layers have different competencies to represent different code properties. Deep CodeBERT layers can encode the semantic information that requires some complex inference in the code context. More importantly, we show that our analysis is helpful and leverage our conclusions to improve CodeBERT. We show an alternative approach for pre-training models, which makes fully use of the current pre-training strategy, i.e, MLM, to learn code syntax and semantics, instead of combining features from different code data formats, e.g., data-flow, running-time states, and program outputs.
Decompiling x86 Deep Neural Network Executables
Oct 04, 2022
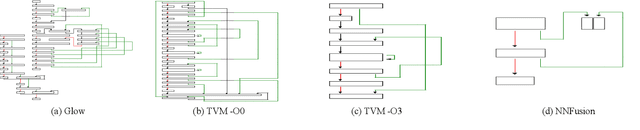
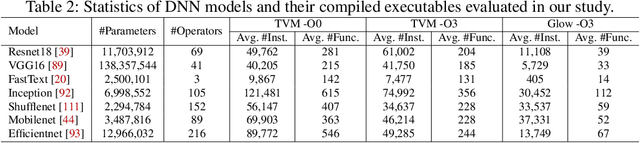
Due to their widespread use on heterogeneous hardware devices, deep learning (DL) models are compiled into executables by DL compilers to fully leverage low-level hardware primitives. This approach allows DL computations to be undertaken at low cost across a variety of computing platforms, including CPUs, GPUs, and various hardware accelerators. We present BTD (Bin to DNN), a decompiler for deep neural network (DNN) executables. BTD takes DNN executables and outputs full model specifications, including types of DNN operators, network topology, dimensions, and parameters that are (nearly) identical to those of the input models. BTD delivers a practical framework to process DNN executables compiled by different DL compilers and with full optimizations enabled on x86 platforms. It employs learning-based techniques to infer DNN operators, dynamic analysis to reveal network architectures, and symbolic execution to facilitate inferring dimensions and parameters of DNN operators. Our evaluation reveals that BTD enables accurate recovery of full specifications of complex DNNs with millions of parameters (e.g., ResNet). The recovered DNN specifications can be re-compiled into a new DNN executable exhibiting identical behavior to the input executable. We show that BTD can boost two representative attacks, adversarial example generation and knowledge stealing, against DNN executables. We also demonstrate cross-architecture legacy code reuse using BTD, and envision BTD being used for other critical downstream tasks like DNN security hardening and patching.
Efficient Testing of Deep Neural Networks via Decision Boundary Analysis
Jul 22, 2022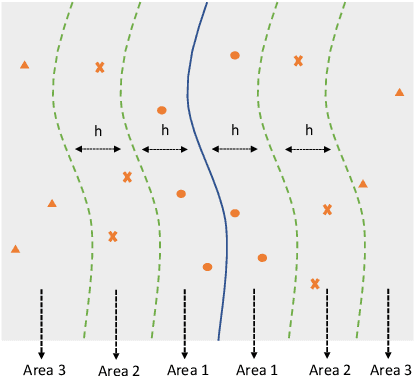


Deep learning plays a more and more important role in our daily life due to its competitive performance in multiple industrial application domains. As the core of DL-enabled systems, deep neural networks automatically learn knowledge from carefully collected and organized training data to gain the ability to predict the label of unseen data. Similar to the traditional software systems that need to be comprehensively tested, DNNs also need to be carefully evaluated to make sure the quality of the trained model meets the demand. In practice, the de facto standard to assess the quality of DNNs in industry is to check their performance (accuracy) on a collected set of labeled test data. However, preparing such labeled data is often not easy partly because of the huge labeling effort, i.e., data labeling is labor-intensive, especially with the massive new incoming unlabeled data every day. Recent studies show that test selection for DNN is a promising direction that tackles this issue by selecting minimal representative data to label and using these data to assess the model. However, it still requires human effort and cannot be automatic. In this paper, we propose a novel technique, named Aries, that can estimate the performance of DNNs on new unlabeled data using only the information obtained from the original test data. The key insight behind our technique is that the model should have similar prediction accuracy on the data which have similar distances to the decision boundary. We performed a large-scale evaluation of our technique on 13 types of data transformation methods. The results demonstrate the usefulness of our technique that the estimated accuracy by Aries is only 0.03% -- 2.60% (on average 0.61%) off the true accuracy. Besides, Aries also outperforms the state-of-the-art selection-labeling-based methods in most (96 out of 128) cases.
CodeS: A Distribution Shift Benchmark Dataset for Source Code Learning
Jun 11, 2022



Over the past few years, deep learning (DL) has been continuously expanding its applications and becoming a driving force for large-scale source code analysis in the big code era. Distribution shift, where the test set follows a different distribution from the training set, has been a longstanding challenge for the reliable deployment of DL models due to the unexpected accuracy degradation. Although recent progress on distribution shift benchmarking has been made in domains such as computer vision and natural language process. Limited progress has been made on distribution shift analysis and benchmarking for source code tasks, on which there comes a strong demand due to both its volume and its important role in supporting the foundations of almost all industrial sectors. To fill this gap, this paper initiates to propose CodeS, a distribution shift benchmark dataset, for source code learning. Specifically, CodeS supports 2 programming languages (i.e., Java and Python) and 5 types of code distribution shifts (i.e., task, programmer, time-stamp, token, and CST). To the best of our knowledge, we are the first to define the code representation-based distribution shifts. In the experiments, we first evaluate the effectiveness of existing out-of-distribution detectors and the reasonability of the distribution shift definitions and then measure the model generalization of popular code learning models (e.g., CodeBERT) on classification task. The results demonstrate that 1) only softmax score-based OOD detectors perform well on CodeS, 2) distribution shift causes the accuracy degradation in all code classification models, 3) representation-based distribution shifts have a higher impact on the model than others, and 4) pre-trained models are more resistant to distribution shifts. We make CodeS publicly available, enabling follow-up research on the quality assessment of code learning models.
Characterizing and Understanding the Behavior of Quantized Models for Reliable Deployment
Apr 08, 2022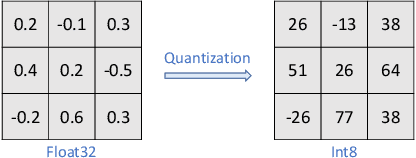
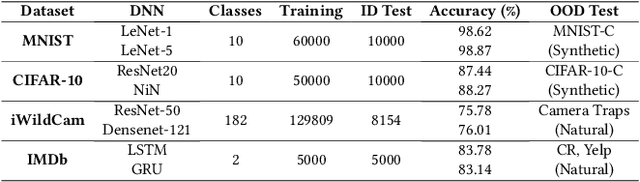
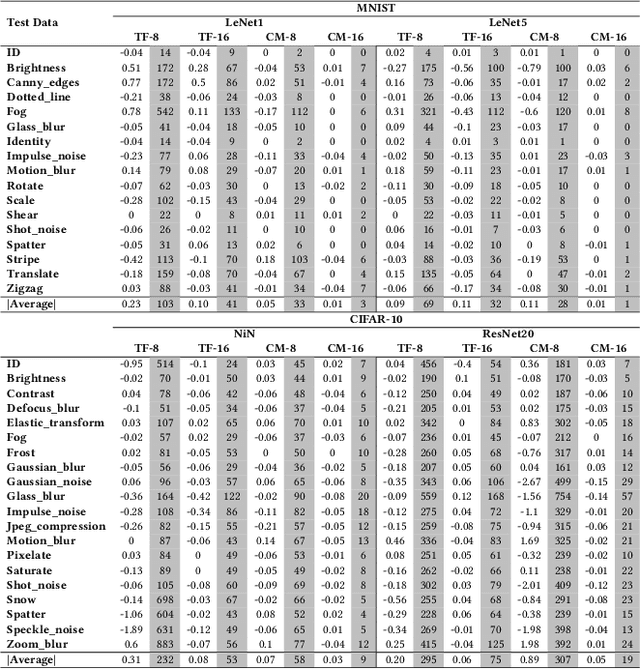
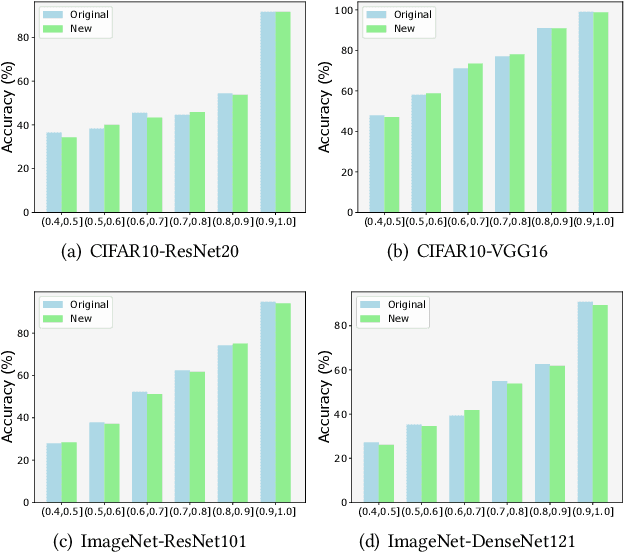
Deep Neural Networks (DNNs) have gained considerable attention in the past decades due to their astounding performance in different applications, such as natural language modeling, self-driving assistance, and source code understanding. With rapid exploration, more and more complex DNN architectures have been proposed along with huge pre-trained model parameters. The common way to use such DNN models in user-friendly devices (e.g., mobile phones) is to perform model compression before deployment. However, recent research has demonstrated that model compression, e.g., model quantization, yields accuracy degradation as well as outputs disagreements when tested on unseen data. Since the unseen data always include distribution shifts and often appear in the wild, the quality and reliability of quantized models are not ensured. In this paper, we conduct a comprehensive study to characterize and help users understand the behaviors of quantized models. Our study considers 4 datasets spanning from image to text, 8 DNN architectures including feed-forward neural networks and recurrent neural networks, and 42 shifted sets with both synthetic and natural distribution shifts. The results reveal that 1) data with distribution shifts happen more disagreements than without. 2) Quantization-aware training can produce more stable models than standard, adversarial, and Mixup training. 3) Disagreements often have closer top-1 and top-2 output probabilities, and $Margin$ is a better indicator than the other uncertainty metrics to distinguish disagreements. 4) Retraining with disagreements has limited efficiency in removing disagreements. We opensource our code and models as a new benchmark for further studying the quantized models.
Labeling-Free Comparison Testing of Deep Learning Models
Apr 08, 2022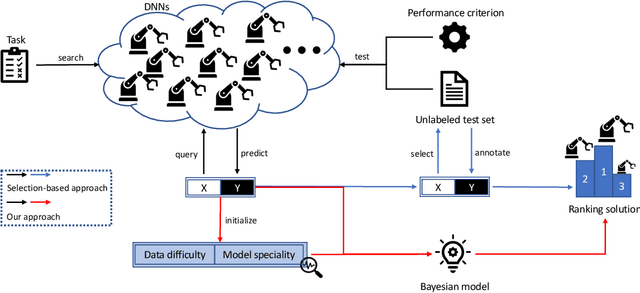

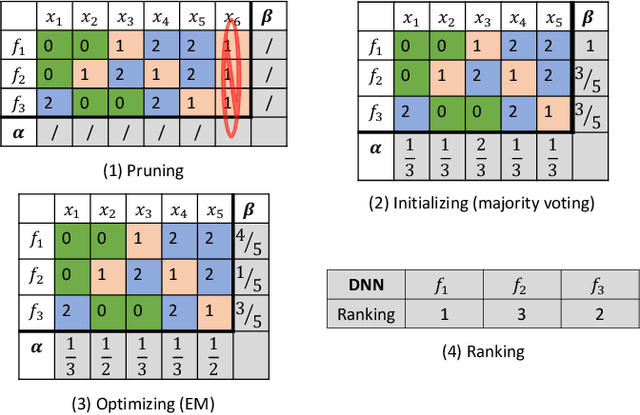
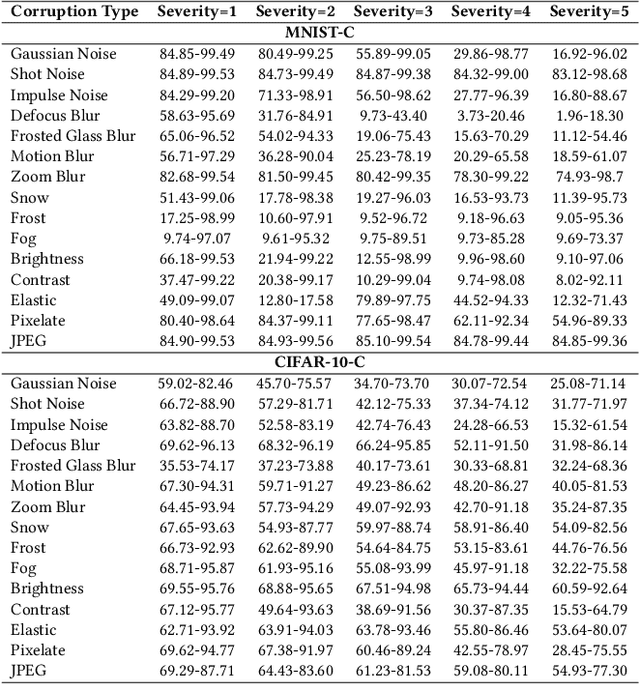
Various deep neural networks (DNNs) are developed and reported for their tremendous success in multiple domains. Given a specific task, developers can collect massive DNNs from public sources for efficient reusing and avoid redundant work from scratch. However, testing the performance (e.g., accuracy and robustness) of multiple DNNs and giving a reasonable recommendation that which model should be used is challenging regarding the scarcity of labeled data and demand of domain expertise. Existing testing approaches are mainly selection-based where after sampling, a few of the test data are labeled to discriminate DNNs. Therefore, due to the randomness of sampling, the performance ranking is not deterministic. In this paper, we propose a labeling-free comparison testing approach to overcome the limitations of labeling effort and sampling randomness. The main idea is to learn a Bayesian model to infer the models' specialty only based on predicted labels. To evaluate the effectiveness of our approach, we undertook exhaustive experiments on 9 benchmark datasets spanning in the domains of image, text, and source code, and 165 DNNs. In addition to accuracy, we consider the robustness against synthetic and natural distribution shifts. The experimental results demonstrate that the performance of existing approaches degrades under distribution shifts. Our approach outperforms the baseline methods by up to 0.74 and 0.53 on Spearman's correlation and Kendall's $\tau$, respectively, regardless of the dataset and distribution shift. Additionally, we investigated the impact of model quality (accuracy and robustness) and diversity (standard deviation of the quality) on the testing effectiveness and observe that there is a higher chance of a good result when the quality is over 50\% and the diversity is larger than 18\%.
NPC: Neuron Path Coverage via Characterizing Decision Logic of Deep Neural Networks
Mar 26, 2022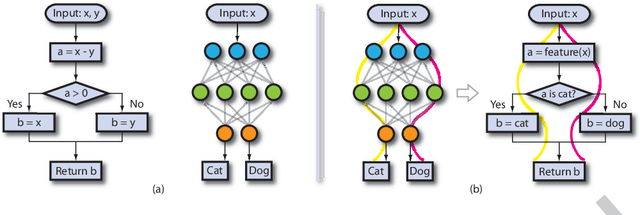
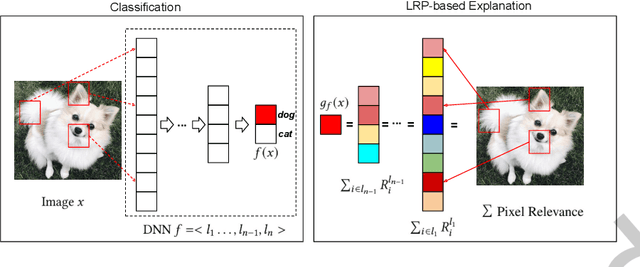
Deep learning has recently been widely applied to many applications across different domains, e.g., image classification and audio recognition. However, the quality of Deep Neural Networks (DNNs) still raises concerns in the practical operational environment, which calls for systematic testing, especially in safety-critical scenarios. Inspired by software testing, a number of structural coverage criteria are designed and proposed to measure the test adequacy of DNNs. However, due to the blackbox nature of DNN, the existing structural coverage criteria are difficult to interpret, making it hard to understand the underlying principles of these criteria. The relationship between the structural coverage and the decision logic of DNNs is unknown. Moreover, recent studies have further revealed the non-existence of correlation between the structural coverage and DNN defect detection, which further posts concerns on what a suitable DNN testing criterion should be. In this paper, we propose the interpretable coverage criteria through constructing the decision structure of a DNN. Mirroring the control flow graph of the traditional program, we first extract a decision graph from a DNN based on its interpretation, where a path of the decision graph represents a decision logic of the DNN. Based on the control flow and data flow of the decision graph, we propose two variants of path coverage to measure the adequacy of the test cases in exercising the decision logic. The higher the path coverage, the more diverse decision logic the DNN is expected to be explored. Our large-scale evaluation results demonstrate that: the path in the decision graph is effective in characterizing the decision of the DNN, and the proposed coverage criteria are also sensitive with errors including natural errors and adversarial examples, and strongly correlated with the output impartiality.
Learning Program Semantics with Code Representations: An Empirical Study
Mar 22, 2022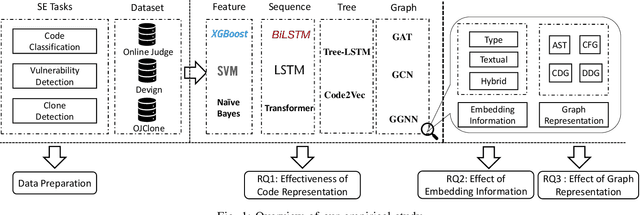
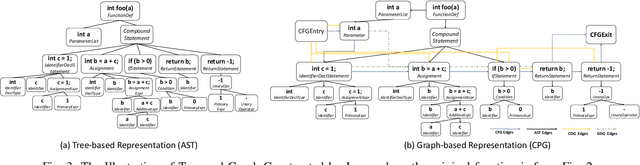

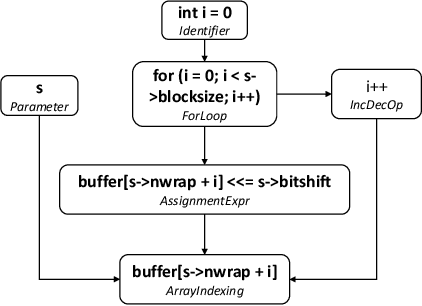
Program semantics learning is the core and fundamental for various code intelligent tasks e.g., vulnerability detection, clone detection. A considerable amount of existing works propose diverse approaches to learn the program semantics for different tasks and these works have achieved state-of-the-art performance. However, currently, a comprehensive and systematic study on evaluating different program representation techniques across diverse tasks is still missed. From this starting point, in this paper, we conduct an empirical study to evaluate different program representation techniques. Specifically, we categorize current mainstream code representation techniques into four categories i.e., Feature-based, Sequence-based, Tree-based, and Graph-based program representation technique and evaluate its performance on three diverse and popular code intelligent tasks i.e., {Code Classification}, Vulnerability Detection, and Clone Detection on the public released benchmark. We further design three {research questions (RQs)} and conduct a comprehensive analysis to investigate the performance. By the extensive experimental results, we conclude that (1) The graph-based representation is superior to the other selected techniques across these tasks. (2) Compared with the node type information used in tree-based and graph-based representations, the node textual information is more critical to learning the program semantics. (3) Different tasks require the task-specific semantics to achieve their highest performance, however combining various program semantics from different dimensions such as control dependency, data dependency can still produce promising results.
Unveiling Project-Specific Bias in Neural Code Models
Jan 19, 2022

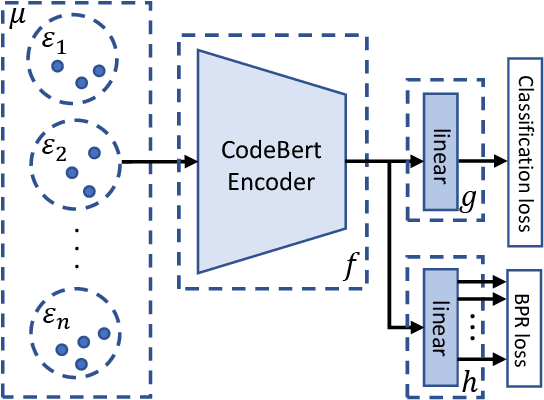
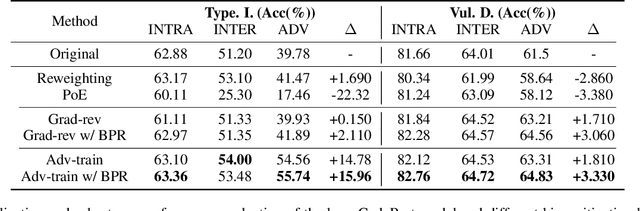
Neural code models have introduced significant improvements over many software analysis tasks like type inference, vulnerability detection, etc. Despite the good performance of such models under the common intra-project independent and identically distributed (IID) training and validation setting, we observe that they usually fail to generalize to real-world inter-project out-of-distribution (OOD) setting. In this work, we show that such phenomenon is caused by model heavily relying on project-specific, ungeneralizable tokens like self-defined variable and function names for downstream prediction, and we formulate it as the project-specific bias learning behavior. We propose a measurement to interpret such behavior, termed as Cond-Idf, which combines co-occurrence probability and inverse document frequency to measure the level of relatedness of token with label and its project-specificness. The approximation indicates that without proper regularization with prior knowledge, model tends to leverage spurious statistical cues for prediction. Equipped with these observations, we propose a bias mitigation mechanism Batch Partition Regularization (BPR) that regularizes model to infer based on proper behavior by leveraging latent logic relations among samples. Experimental results on two deep code benchmarks indicate that BPR can improve both inter-project OOD generalization and adversarial robustness while not sacrificing accuracy on IID data.