 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARO: Chain-of-Analogy Reasoning Optimization for Robust Content Moderation
Apr 12, 2026Current large language models (LLMs), even those explicitly trained for reasoning, often struggle with ambiguous content moderation cases due to misleading "decision shortcuts" embedded in context. Inspired by cognitive psychology insights into expert moderation, we introduce \caro (Chain-of-Analogy Reasoning Optimization), a novel two-stage training framework to induce robust analogical reasoning in LLMs. First, \caro bootstraps analogical reasoning chains via retrieval-augmented generation (RAG) on moderation data and performs supervised fine-tuning (SFT). Second, we propose a customized direct preference optimization (DPO) approach to reinforce analogical reasoning behaviors explicitly. Unlike static retrieval methods, \caro dynamically generates tailored analogical references during inference, effectively mitigating harmful decision shortcuts. Extensive experiments demonstrate that \caro substantially outperforms state-of-the-art reasoning models (DeepSeek R1, QwQ), specialized moderation models (LLaMA Guard), and advanced fine-tuning and retrieval-augmented methods, achieving an average F1 score improvement of 24.9\% on challenging ambiguous moderation benchmarks.
CHAIRO: Contextual Hierarchical Analogical Induction and Reasoning Optimization for LLMs
Apr 12, 2026Content moderation in online platforms faces persistent challenges due to the evolving complexity of user-generated content and the limitations of traditional rule-based and machine learning approaches. While recent advances in large language models (LLMs) have enabled more sophisticated moderation via direct prompting or fine-tuning, these approaches often exhibit limited generalization, interpretability, and adaptability to unseen or ambiguous cases. In this work, we propose a novel moderation framework that leverages analogical examples to enhance rule induction and decision reliability. Our approach integrates end-to-end optimization of analogical retrieval, rule generation, and moderation classification, enabling the dynamic adaptation of moderation rules to diverse content scenarios. Through comprehensive experiments, we demonstrate that our method significantly outperforms both rule-injected fine-tuning baselines and multi-stage static RAG pipelines in terms of moderation accuracy and rule quality. Further evaluations, including human assessments and external model generalization tests, confirm that our framework produces rules with better clarity, interpretability, and applicability. These findings show that analogical example-driven methods can advance robust, explainable, and generalizable content moderation in real-world applications.
WarPGNN: A Parametric Thermal Warpage Analysis Framework with Physics-aware Graph Neural Network
Mar 19, 2026With the advent of system-in-package (SiP) chiplet-based design and heterogeneous 2.5D/3D integration, thermal-induced warpage has become a critical reliability concern. While conventional numerical approaches can deliver highly accurate results, they often incur prohib- itively high computational costs, limiting their scalability for complex chiplet-package systems. In this paper, we present WarPGNN, an ef- ficient and accurate parametric thermal warpage analysis framework powered by Graph Neural Networks (GNNs). By operating directly on graphs constructed from the floorplans, WarPGNN enables fast warpage-aware floorplan exploration and exhibits strong transfer- ability across diverse package configurations. Our method first en- codes multi-die floorplans into reduced Transitive Closure Graphs (rTCGs), then a Graph Convolution Network (GCN)-based encoder extracts hierarchical structural features, followed by a U-Net inspired decoder that reconstructs warpage maps from graph feature embed- dings. Furthermore, to address the long-tailed pattern of warpage data distribution, we developed a physics-informed loss and revised a message-passing encoder based on Graph Isomorphic Network (GIN) that further enhance learning performance for extreme cases and expressiveness of graph embeddings. Numerical results show that WarPGNN achieves more than 205.91x speedup compared with the 2-D efficient FEM-based method and over 119766.64x acceleration with 3-D FEM method COMSOL, respectively, while maintaining comparable accuracy at only 1.26% full-scale normalized RMSE and 2.21% warpage value error. Compared with recent DeepONet-based model, our method achieved comparable prediction accuracy and in- ference speedup with 3.4x lower training time. In addition, WarPGNN demonstrates remarkable transferability on unseen datasets with up to 3.69% normalized RMSE and similar runtime.
EnerBridge-DPO: Energy-Guided Protein Inverse Folding with Markov Bridges and Direct Preference Optimization
Jun 11, 2025



Designing protein sequences with optimal energetic stability is a key challenge in protein inverse folding, as current deep learning methods are primarily trained by maximizing sequence recovery rates, often neglecting the energy of the generated sequences. This work aims to overcome this limitation by developing a model that directly generates low-energy, stable protein sequences. We propose EnerBridge-DPO, a novel inverse folding framework focused on generating low-energy, high-stability protein sequences. Our core innovation lies in: First, integrating Markov Bridges with Direct Preference Optimization (DPO), where energy-based preferences are used to fine-tune the Markov Bridge model. The Markov Bridge initiates optimization from an information-rich prior sequence, providing DPO with a pool of structurally plausible sequence candidates. Second, an explicit energy constraint loss is introduced, which enhances the energy-driven nature of DPO based on prior sequences, enabling the model to effectively learn energy representations from a wealth of prior knowledge and directly predict sequence energy values, thereby capturing quantitative features of the energy landscape. Our evaluations demonstrate that EnerBridge-DPO can design protein complex sequences with lower energy while maintaining sequence recovery rates comparable to state-of-the-art models, and accurately predicts $\Delta \Delta G$ values between various sequences.
MAVIN: Multi-Action Video Generation with Diffusion Models via Transition Video Infilling
May 28, 2024



Diffusion-based video generation has achieved significant progress, yet generating multiple actions that occur sequentially remains a formidable task. Directly generating a video with sequential actions can be extremely challenging due to the scarcity of fine-grained action annotations and the difficulty in establishing temporal semantic correspondences and maintaining long-term consistency. To tackle this, we propose an intuitive and straightforward solution: splicing multiple single-action video segments sequentially. The core challenge lies in generating smooth and natural transitions between these segments given the inherent complexity and variability of action transitions. We introduce MAVIN (Multi-Action Video INfilling model), designed to generate transition videos that seamlessly connect two given videos, forming a cohesive integrated sequence. MAVIN incorporates several innovative techniques to address challenges in the transition video infilling task. Firstly, a consecutive noising strategy coupled with variable-length sampling is employed to handle large infilling gaps and varied generation lengths. Secondly, boundary frame guidance (BFG) is proposed to address the lack of semantic guidance during transition generation. Lastly, a Gaussian filter mixer (GFM) dynamically manages noise initialization during inference, mitigating train-test discrepancy while preserving generation flexibility. Additionally, we introduce a new metric, CLIP-RS (CLIP Relative Smoothness), to evaluate temporal coherence and smoothness, complementing traditional quality-based metrics. Experimental results on horse and tiger scenarios demonstrate MAVIN's superior performance in generating smooth and coherent video transitions compared to existing methods.
Large coordinate kernel attention network for lightweight image super-resolution
May 15, 2024



The multi-scale receptive field and large kernel attention (LKA) module have been shown to significantly improve performance in the lightweight image super-resolution task. However, existing lightweight super-resolution (SR) methods seldom pay attention to designing efficient building block with multi-scale receptive field for local modeling, and their LKA modules face a quadratic increase in computational and memory footprints as the convolutional kernel size increases. To address the first issue, we propose the multi-scale blueprint separable convolutions (MBSConv) as highly efficient building block with multi-scale receptive field, it can focus on the learning for the multi-scale information which is a vital component of discriminative representation. As for the second issue, we revisit the key properties of LKA in which we find that the adjacent direct interaction of local information and long-distance dependencies is crucial to provide remarkable performance. Thus, taking this into account and in order to mitigate the complexity of LKA, we propose a large coordinate kernel attention (LCKA) module which decomposes the 2D convolutional kernels of the depth-wise convolutional layers in LKA into horizontal and vertical 1-D kernels. LCKA enables the adjacent direct interaction of local information and long-distance dependencies not only in the horizontal direction but also in the vertical. Besides, LCKA allows for the direct use of extremely large kernels in the depth-wise convolutional layers to capture more contextual information, which helps to significantly improve the reconstruction performance, and it incurs lower computational complexity and memory footprints. Integrating MBSConv and LCKA, we propose a large coordinate kernel attention network (LCAN).
DOCTOR: Dynamic On-Chip Remediation Against Temporally-Drifting Thermal Variations Toward Self-Corrected Photonic Tensor Accelerators
Mar 05, 2024Photonic computing has emerged as a promising solution for accelerating computation-intensive artificial intelligence (AI) workloads, offering unparalleled speed and energy efficiency, especially in resource-limited, latency-sensitive edge computing environments. However, the deployment of analog photonic tensor accelerators encounters reliability challenges due to hardware noises and environmental variations. While off-chip noise-aware training and on-chip training have been proposed to enhance the variation tolerance of optical neural accelerators with moderate, static noises, we observe a notable performance degradation over time due to temporally drifting variations, which requires a real-time, in-situ calibration mechanism. To tackle this challenging reliability issues, for the first time, we propose a lightweight dynamic on-chip remediation framework, dubbed DOCTOR, providing adaptive, in-situ accuracy recovery against temporally drifting noises. The DOCTOR framework intelligently monitors the chip status using adaptive probing and performs fast in-situ training-free calibration to restore accuracy when necessary. Recognizing nonuniform spatial variation distributions across devices and tensor cores, we also propose a variation-aware architectural remapping strategy to avoid executing critical tasks on noisy devices. Extensive experiments show that our proposed framework can guarantee sustained performance under drifting variations with 34% higher accuracy and 2-3 orders-of-magnitude lower overhead compared to state-of-the-art on-chip training methods.
A Synchronized Layer-by-layer Growing Approach for Plausible Neuronal Morphology Generation
Jan 17, 2024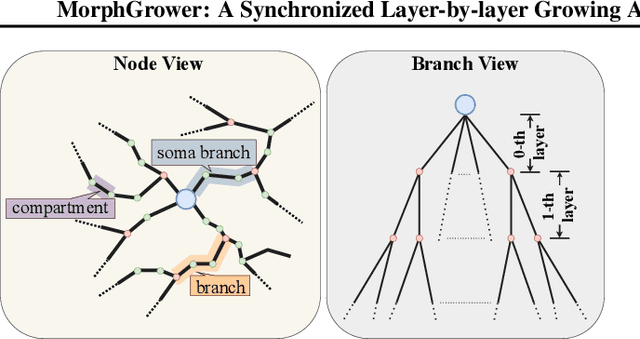
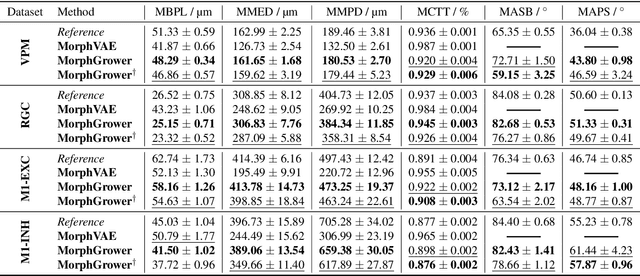
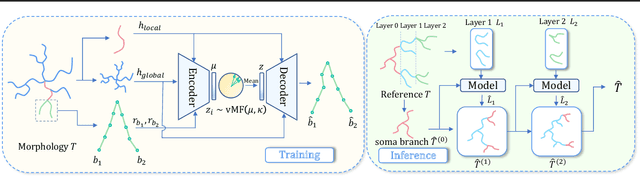

Neuronal morphology is essential for studying brain functioning and understanding neurodegenerative disorders. As the acquiring of real-world morphology data is expensive, computational approaches especially learning-based ones e.g. MorphVAE for morphology generation were recently studied, which are often conducted in a way of randomly augmenting a given authentic morphology to achieve plausibility. Under such a setting, this paper proposes \textbf{MorphGrower} which aims to generate more plausible morphology samples by mimicking the natural growth mechanism instead of a one-shot treatment as done in MorphVAE. Specifically, MorphGrower generates morphologies layer by layer synchronously and chooses a pair of sibling branches as the basic generation block, and the generation of each layer is conditioned on the morphological structure of previous layers and then generate morphologies via a conditional variational autoencoder with spherical latent space. Extensive experimental results on four real-world datasets demonstrate that MorphGrower outperforms MorphVAE by a notable margin. Our code will be publicly available to facilitate future research.