 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagonal State Space Augmented Transformers for Speech Recognition
Feb 27, 2023We improve on the popular conformer architecture by replacing the depthwise temporal convolutions with diagonal state space (DSS) models. DSS is a recently introduced variant of linear RNNs obtained by discretizing a linear dynamical system with a diagonal state transition matrix. DSS layers project the input sequence onto a space of orthogonal polynomials where the choice of basis functions, metric and support is controlled by the eigenvalues of the transition matrix. We compare neural transducers with either conformer or our proposed DSS-augmented transformer (DSSformer) encoders on three public corpora: Switchboard English conversational telephone speech 300 hours, Switchboard+Fisher 2000 hours, and a spoken archive of holocaust survivor testimonials called MALACH 176 hours. On Switchboard 300/2000 hours, we reach a single model performance of 8.9%/6.7% WER on the combined test set of the Hub5 2000 evaluation, respectively, and on MALACH we improve the WER by 7% relative over the previous best published result. In addition, we present empirical evidence suggesting that DSS layers learn damped Fourier basis functions where the attenuation coefficients are layer specific whereas the frequency coefficients converge to almost identical linearly-spaced values across all layers.
Accelerating Inference and Language Model Fusion of Recurrent Neural Network Transducers via End-to-End 4-bit Quantization
Jun 16, 2022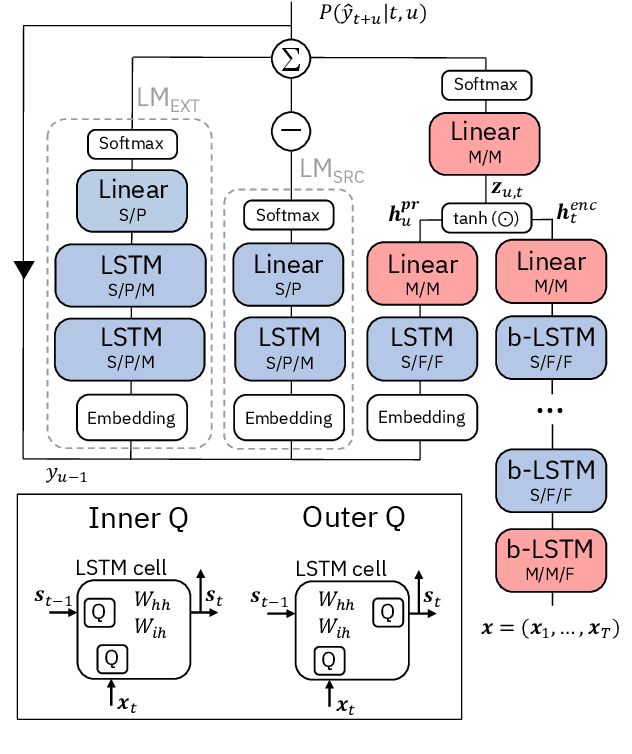
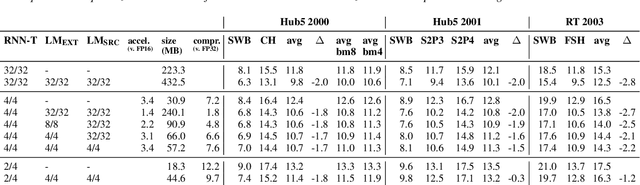
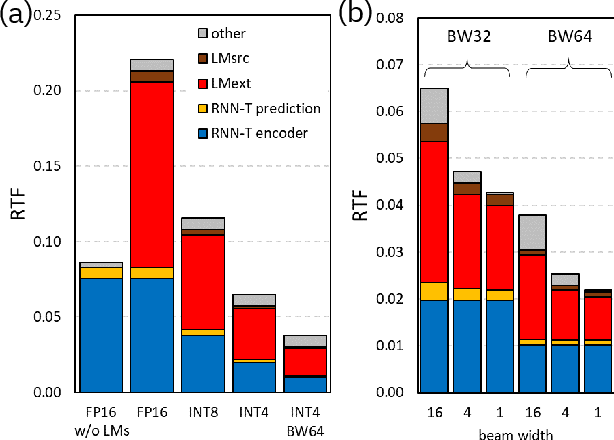
We report on aggressive quantization strategies that greatly accelerate inference of Recurrent Neural Network Transducers (RNN-T). We use a 4 bit integer representation for both weights and activations and apply Quantization Aware Training (QAT) to retrain the full model (acoustic encoder and language model) and achieve near-iso-accuracy. We show that customized quantization schemes that are tailored to the local properties of the network are essential to achieve good performance while limiting the computational overhead of QAT. Density ratio Language Model fusion has shown remarkable accuracy gains on RNN-T workloads but it severely increases the computational cost of inference. We show that our quantization strategies enable using large beam widths for hypothesis search while achieving streaming-compatible runtimes and a full model compression ratio of 7.6$\times$ compared to the full precision model. Via hardware simulations, we estimate a 3.4$\times$ acceleration from FP16 to INT4 for the end-to-end quantized RNN-T inclusive of LM fusion, resulting in a Real Time Factor (RTF) of 0.06. On the NIST Hub5 2000, Hub5 2001, and RT-03 test sets, we retain most of the gains associated with LM fusion, improving the average WER by $>$1.5%.
Improving Generalization of Deep Neural Network Acoustic Models with Length Perturbation and N-best Based Label Smoothing
Mar 29, 2022
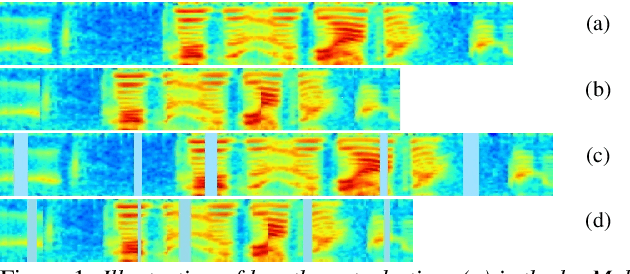

We introduce two techniques, length perturbation and n-best based label smoothing, to improve generalization of deep neural network (DNN) acoustic models for automatic speech recognition (ASR). Length perturbation is a data augmentation algorithm that randomly drops and inserts frames of an utterance to alter the length of the speech feature sequence. N-best based label smoothing randomly injects noise to ground truth labels during training in order to avoid overfitting, where the noisy labels are generated from n-best hypotheses. We evaluate these two techniques extensively on the 300-hour Switchboard (SWB300) dataset and an in-house 500-hour Japanese (JPN500) dataset using recurrent neural network transducer (RNNT) acoustic models for ASR. We show that both techniques improve the generalization of RNNT models individually and they can also be complementary. In particular, they yield good improvements over a strong SWB300 baseline and give state-of-art performance on SWB300 using RNNT models.
Loss Landscape Dependent Self-Adjusting Learning Rates in Decentralized Stochastic Gradient Descent
Dec 02, 2021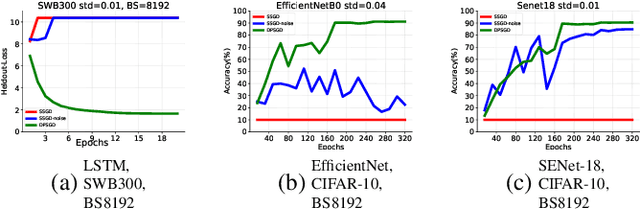
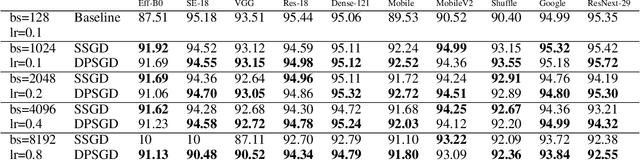
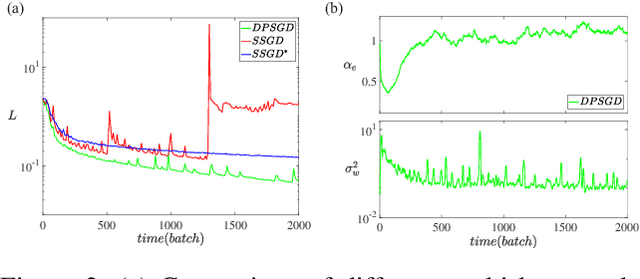
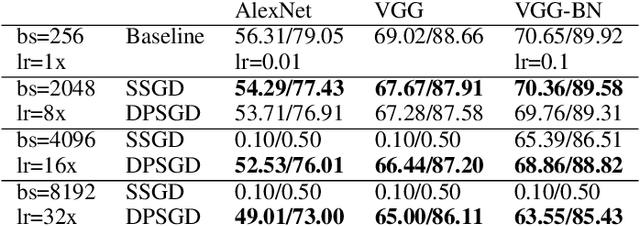
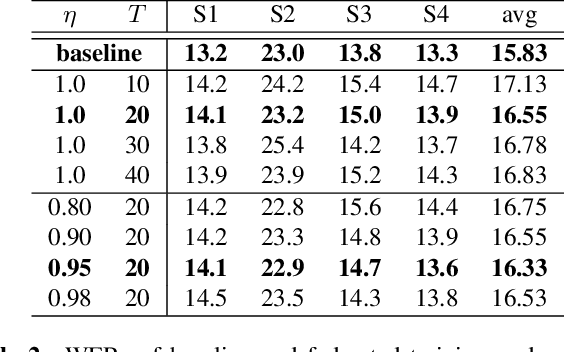
Distributed Deep Learning (DDL) is essential for large-scale Deep Learning (DL) training. Synchronous Stochastic Gradient Descent (SSGD) 1 is the de facto DDL optimization method. Using a sufficiently large batch size is critical to achieving DDL runtime speedup. In a large batch setting, the learning rate must be increased to compensate for the reduced number of parameter updates. However, a large learning rate may harm convergence in SSGD and training could easily diverge. Recently, Decentralized Parallel SGD (DPSGD) has been proposed to improve distributed training speed. In this paper, we find that DPSGD not only has a system-wise run-time benefit but also a significant convergence benefit over SSGD in the large batch setting. Based on a detailed analysis of the DPSGD learning dynamics, we find that DPSGD introduces additional landscape-dependent noise that automatically adjusts the effective learning rate to improve convergence. In addition, we theoretically show that this noise smoothes the loss landscape, hence allowing a larger learning rate. We conduct extensive studies over 18 state-of-the-art DL models/tasks and demonstrate that DPSGD often converges in cases where SSGD diverges for large learning rates in the large batch setting. Our findings are consistent across two different application domains: Computer Vision (CIFAR10 and ImageNet-1K) and Automatic Speech Recognition (SWB300 and SWB2000), and two different types of neural network models: Convolutional Neural Networks and Long Short-Term Memory Recurrent Neural Networks.
Asynchronous Decentralized Distributed Training of Acoustic Models
Oct 21, 2021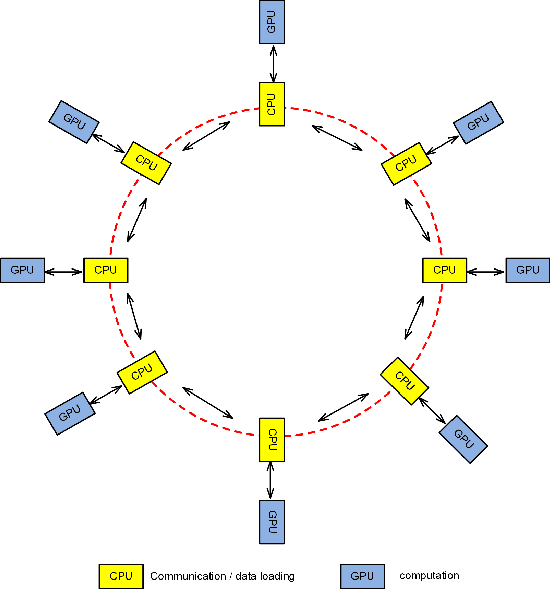
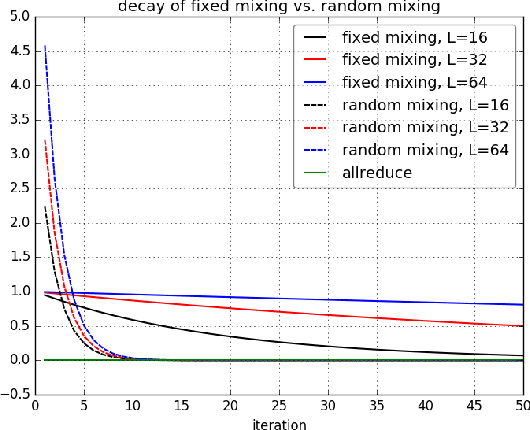
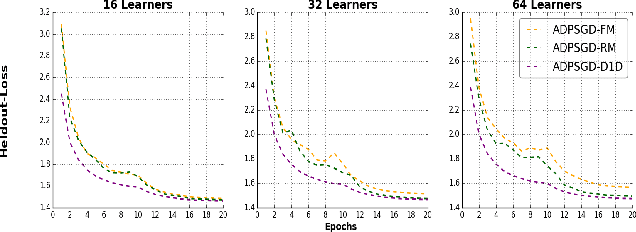
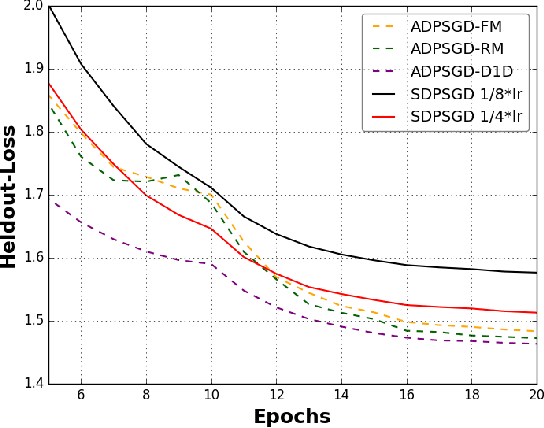
Large-scale distributed training of deep acoustic models plays an important role in today's high-performance automatic speech recognition (ASR). In this paper we investigate a variety of asynchronous decentralized distributed training strategies based on data parallel stochastic gradient descent (SGD) to show their superior performance over the commonly-used synchronous distributed training via allreduce, especially when dealing with large batch sizes. Specifically, we study three variants of asynchronous decentralized parallel SGD (ADPSGD), namely, fixed and randomized communication patterns on a ring as well as a delay-by-one scheme. We introduce a mathematical model of ADPSGD, give its theoretical convergence rate, and compare the empirical convergence behavior and straggler resilience properties of the three variants. Experiments are carried out on an IBM supercomputer for training deep long short-term memory (LSTM) acoustic models on the 2000-hour Switchboard dataset. Recognition and speedup performance of the proposed strategies are evaluated under various training configurations. We show that ADPSGD with fixed and randomized communication patterns cope well with slow learners. When learners are equally fast, ADPSGD with the delay-by-one strategy has the fastest convergence with large batches. In particular, using the delay-by-one strategy, we can train the acoustic model in less than 2 hours using 128 V100 GPUs with competitive word error rates.
4-bit Quantization of LSTM-based Speech Recognition Models
Aug 27, 2021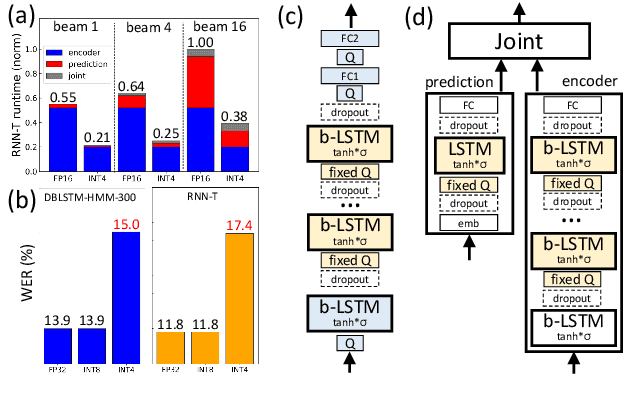
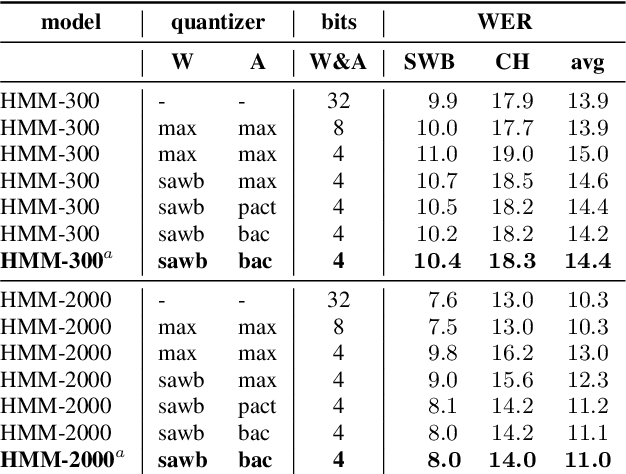
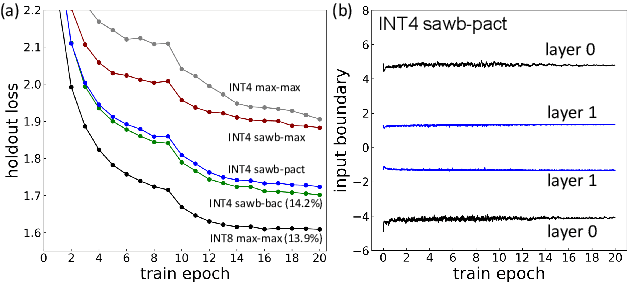
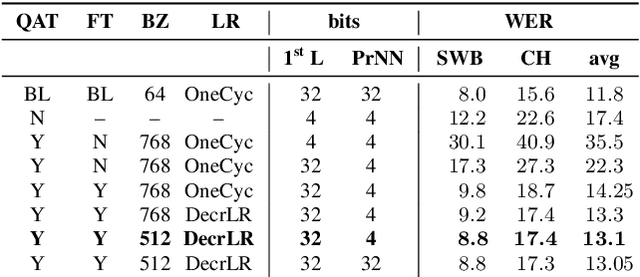
We investigate the impact of aggressive low-precision representations of weights and activations in two families of large LSTM-based architectures for Automatic Speech Recognition (ASR): hybrid Deep Bidirectional LSTM - Hidden Markov Models (DBLSTM-HMMs) and Recurrent Neural Network - Transducers (RNN-Ts). Using a 4-bit integer representation, a na\"ive quantization approach applied to the LSTM portion of these models results in significant Word Error Rate (WER) degradation. On the other hand, we show that minimal accuracy loss is achievable with an appropriate choice of quantizers and initializations. In particular, we customize quantization schemes depending on the local properties of the network, improving recognition performance while limiting computational time. We demonstrate our solution on the Switchboard (SWB) and CallHome (CH) test sets of the NIST Hub5-2000 evaluation. DBLSTM-HMMs trained with 300 or 2000 hours of SWB data achieves $<$0.5% and $<$1% average WER degradation, respectively. On the more challenging RNN-T models, our quantization strategy limits degradation in 4-bit inference to 1.3%.
Reducing Exposure Bias in Training Recurrent Neural Network Transducers
Aug 24, 2021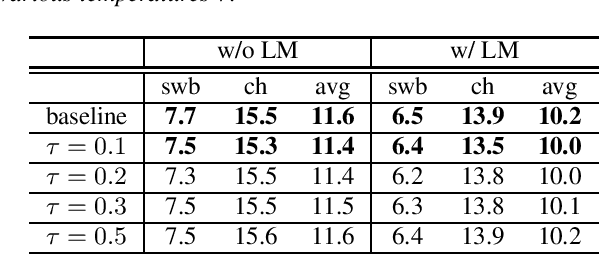
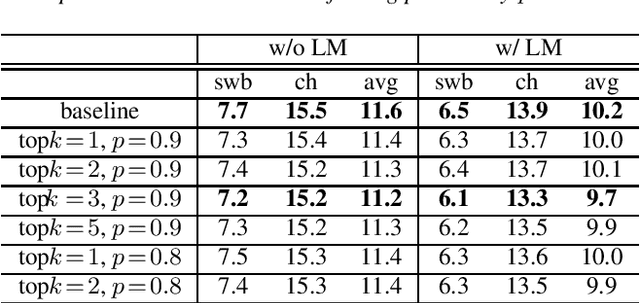
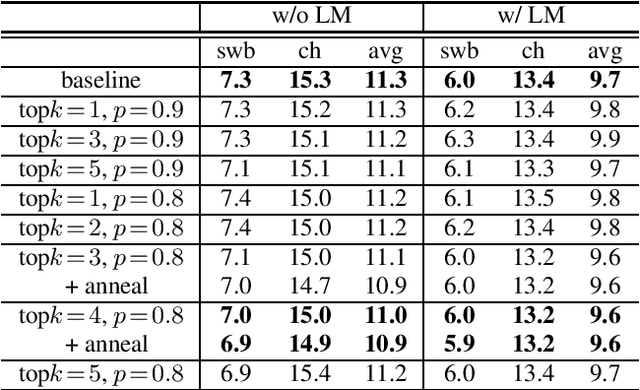
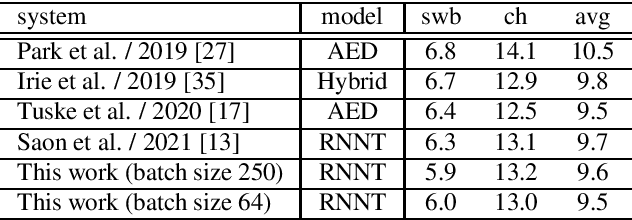
When recurrent neural network transducers (RNNTs) are trained using the typical maximum likelihood criterion, the prediction network is trained only on ground truth label sequences. This leads to a mismatch during inference, known as exposure bias, when the model must deal with label sequences containing errors. In this paper we investigate approaches to reducing exposure bias in training to improve the generalization of RNNT models for automatic speech recognition (ASR). A label-preserving input perturbation to the prediction network is introduced. The input token sequences are perturbed using SwitchOut and scheduled sampling based on an additional token language model. Experiments conducted on the 300-hour Switchboard dataset demonstrate their effectiveness. By reducing the exposure bias, we show that we can further improve the accuracy of a high-performance RNNT ASR model and obtain state-of-the-art results on the 300-hour Switchboard dataset.
On Sample Based Explanation Methods for NLP:Efficiency, Faithfulness, and Semantic Evaluation
Jun 09, 2021
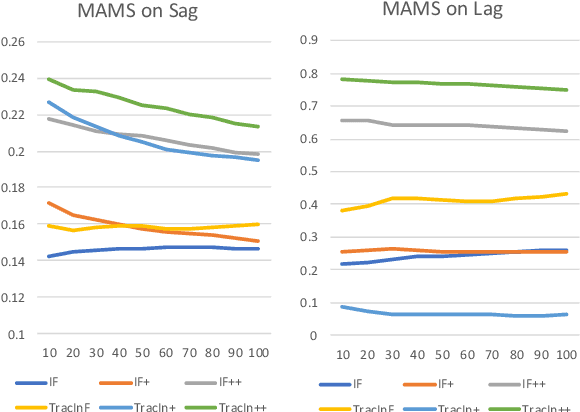

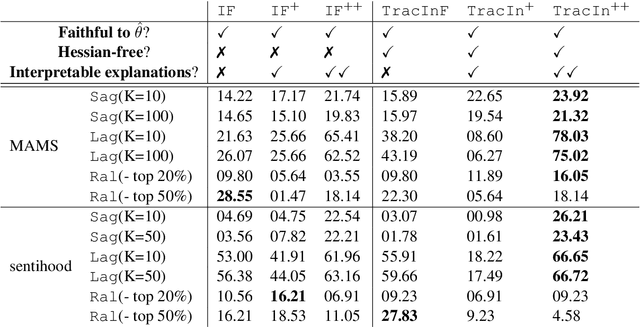
In the recent advances of natural language processing, the scale of the state-of-the-art models and datasets is usually extensive, which challenges the application of sample-based explanation methods in many aspects, such as explanation interpretability, efficiency, and faithfulness. In this work, for the first time, we can improve the interpretability of explanations by allowing arbitrary text sequences as the explanation unit. On top of this, we implement a hessian-free method with a model faithfulness guarantee. Finally, to compare our method with the others, we propose a semantic-based evaluation metric that can better align with humans' judgment of explanations than the widely adopted diagnostic or re-training measures. The empirical results on multiple real data sets demonstrate the proposed method's superior performance to popular explanation techniques such as Influence Function or TracIn on semantic evaluation.
ScaleCom: Scalable Sparsified Gradient Compression for Communication-Efficient Distributed Training
Apr 21, 2021
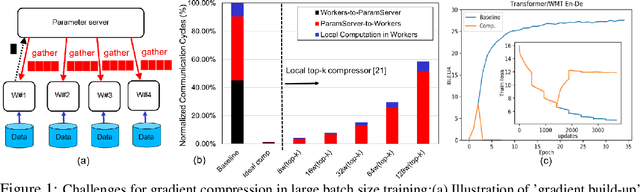
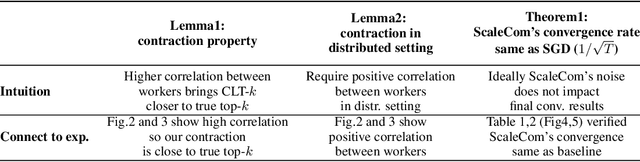
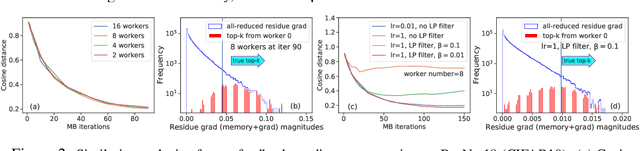
Large-scale distributed training of Deep Neural Networks (DNNs) on state-of-the-art platforms is expected to be severely communication constrained. To overcome this limitation, numerous gradient compression techniques have been proposed and have demonstrated high compression ratios. However, most existing methods do not scale well to large scale distributed systems (due to gradient build-up) and/or fail to evaluate model fidelity (test accuracy) on large datasets. To mitigate these issues, we propose a new compression technique, Scalable Sparsified Gradient Compression (ScaleCom), that leverages similarity in the gradient distribution amongst learners to provide significantly improved scalability. Using theoretical analysis, we show that ScaleCom provides favorable convergence guarantees and is compatible with gradient all-reduce techniques. Furthermore, we experimentally demonstrate that ScaleCom has small overheads, directly reduces gradient traffic and provides high compression rates (65-400X) and excellent scalability (up to 64 learners and 8-12X larger batch sizes over standard training) across a wide range of applications (image, language, and speech) without significant accuracy loss.
Federated Acoustic Modeling For Automatic Speech Recognition
Feb 08, 2021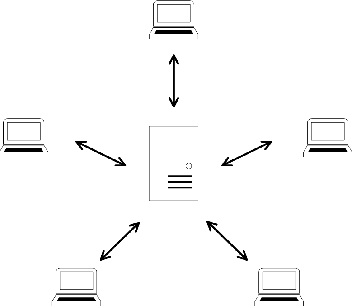


Data privacy and protection is a crucial issue for any automatic speech recognition (ASR) service provider when dealing with clients. In this paper, we investigate federated acoustic modeling using data from multiple clients. A client's data is stored on a local data server and the clients communicate only model parameters with a central server, and not their data. The communication happens infrequently to reduce the communication cost. To mitigate the non-iid issue, client adaptive federated training (CAFT) is proposed to canonicalize data across clients. The experiments are carried out on 1,150 hours of speech data from multiple domains. Hybrid LSTM acoustic models are trained via federated learning and their performance is compared to traditional centralized acoustic model training. The experimental results demonstrate the effectiveness of the proposed federated acoustic modeling strategy. We also show that CAFT can further improve the performance of the federated acoustic model.