 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleCom: Scalable Sparsified Gradient Compression for Communication-Efficient Distributed Training
Paper and Code
Apr 21, 2021
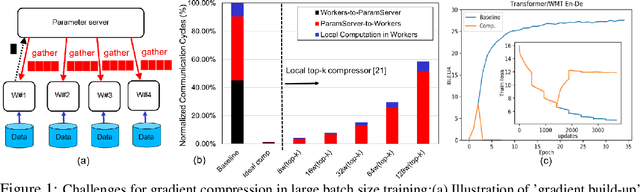
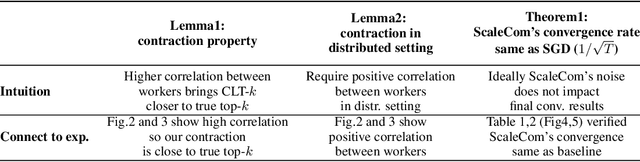
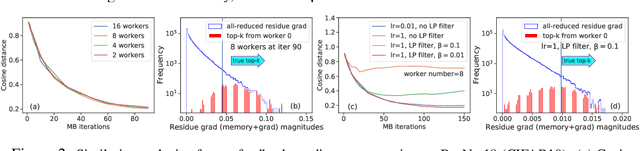
Large-scale distributed training of Deep Neural Networks (DNNs) on state-of-the-art platforms is expected to be severely communication constrained. To overcome this limitation, numerous gradient compression techniques have been proposed and have demonstrated high compression ratios. However, most existing methods do not scale well to large scale distributed systems (due to gradient build-up) and/or fail to evaluate model fidelity (test accuracy) on large datasets. To mitigate these issues, we propose a new compression technique, Scalable Sparsified Gradient Compression (ScaleCom), that leverages similarity in the gradient distribution amongst learners to provide significantly improved scalability. Using theoretical analysis, we show that ScaleCom provides favorable convergence guarantees and is compatible with gradient all-reduce techniques. Furthermore, we experimentally demonstrate that ScaleCom has small overheads, directly reduces gradient traffic and provides high compression rates (65-400X) and excellent scalability (up to 64 learners and 8-12X larger batch sizes over standard training) across a wide range of applications (image, language, and speech) without significant accuracy loss.