 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Better Intent Representations for Financial Open Intent Classification
Oct 25, 2022With the recent surge of NLP technologies in the financial domain, banks and other financial entities have adopted virtual agents (VA) to assist customers. A challenging problem for VAs in this domain is determining a user's reason or intent for contacting the VA, especially when the intent was unseen or open during the VA's training. One method for handling open intents is adaptive decision boundary (ADB) post-processing, which learns tight decision boundaries from intent representations to separate known and open intents. We propose incorporating two methods for supervised pre-training of intent representations: prefix-tuning and fine-tuning just the last layer of a large language model (LLM). With this proposal, our accuracy is 1.63% - 2.07% higher than the prior state-of-the-art ADB method for open intent classification on the banking77 benchmark amongst others. Notably, we only supplement the original ADB model with 0.1% additional trainable parameters. Ablation studies also determine that our method yields better results than full fine-tuning the entire model. We hypothesize that our findings could stimulate a new optimal method of downstream tuning that combines parameter efficient tuning modules with fine-tuning a subset of the base model's layers.
Neuro-symbolic Natural Logic with Introspective Revision for Natural Language Inference
Mar 09, 2022


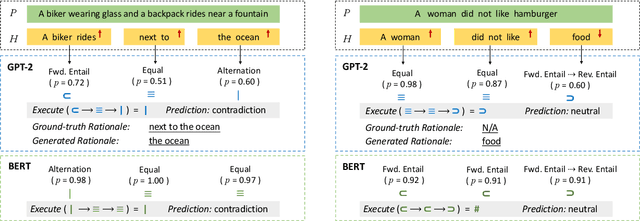
We introduce a neuro-symbolic natural logic framework based on reinforcement learning with introspective revision. The model samples and rewards specific reasoning paths through policy gradient, in which the introspective revision algorithm modifies intermediate symbolic reasoning steps to discover reward-earning operations as well as leverages external knowledge to alleviate spurious reasoning and training inefficiency. The framework is supported by properly designed local relation models to avoid input entangling, which helps ensure the interpretability of the proof paths. The proposed model has built-in interpretability and shows superior capability in monotonicity inference, systematic generalization, and interpretability, compared to previous models on the existing datasets.
Interpretable Low-Resource Legal Decision Making
Jan 01, 2022

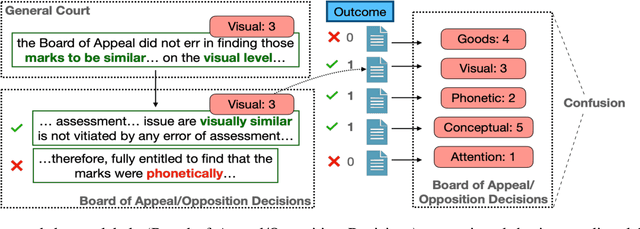
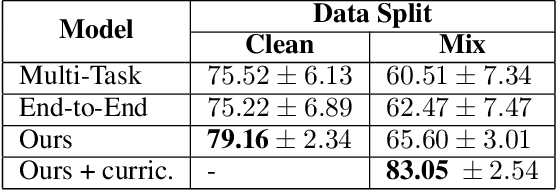
Over the past several years, legal applications of deep learning have been on the rise. However, as with other high-stakes decision making areas, the requirement for interpretability is of crucial importance. Current models utilized by legal practitioners are more of the conventional machine learning type, wherein they are inherently interpretable, yet unable to harness the performance capabilities of data-driven deep learning models. In this work, we utilize deep learning models in the area of trademark law to shed light on the issue of likelihood of confusion between trademarks. Specifically, we introduce a model-agnostic interpretable intermediate layer, a technique which proves to be effective for legal documents. Furthermore, we utilize weakly supervised learning by means of a curriculum learning strategy, effectively demonstrating the improved performance of a deep learning model. This is in contrast to the conventional models which are only able to utilize the limited number of expensive manually-annotated samples by legal experts. Although the methods presented in this work tackles the task of risk of confusion for trademarks, it is straightforward to extend them to other fields of law, or more generally, to other similar high-stakes application scenarios.
Exploring Decomposition for Table-based Fact Verification
Sep 22, 2021
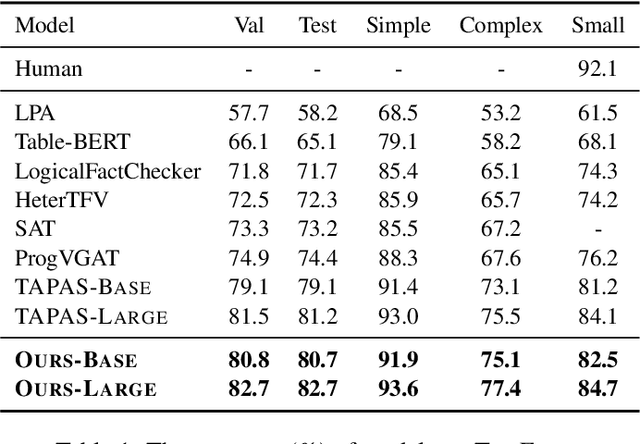


Fact verification based on structured data is challenging as it requires models to understand both natural language and symbolic operations performed over tables. Although pre-trained language models have demonstrated a strong capability in verifying simple statements, they struggle with complex statements that involve multiple operations. In this paper, we improve fact verification by decomposing complex statements into simpler subproblems. Leveraging the programs synthesized by a weakly supervised semantic parser, we propose a program-guided approach to constructing a pseudo dataset for decomposition model training. The subproblems, together with their predicted answers, serve as the intermediate evidence to enhance our fact verification model. Experiments show that our proposed approach achieves the new state-of-the-art performance, an 82.7\% accuracy, on the TabFact benchmark.
Identifying Untrustworthy Samples: Data Filtering for Open-domain Dialogues with Bayesian Optimization
Sep 14, 2021
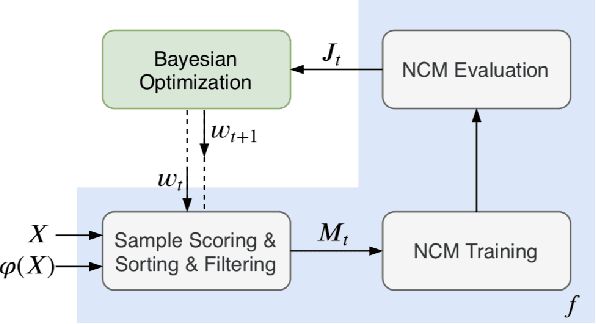
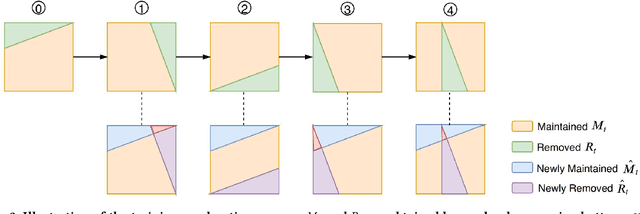
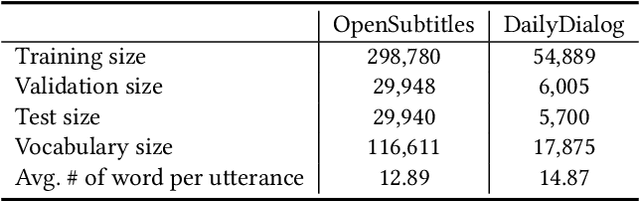
Being able to reply with a related, fluent, and informative response is an indispensable requirement for building high-quality conversational agents. In order to generate better responses, some approaches have been proposed, such as feeding extra information by collecting large-scale datasets with human annotations, designing neural conversational models (NCMs) with complex architecture and loss functions, or filtering out untrustworthy samples based on a dialogue attribute, e.g., Relatedness or Genericness. In this paper, we follow the third research branch and present a data filtering method for open-domain dialogues, which identifies untrustworthy samples from training data with a quality measure that linearly combines seven dialogue attributes. The attribute weights are obtained via Bayesian Optimization (BayesOpt) that aims to optimize an objective function for dialogue generation iteratively on the validation set. Then we score training samples with the quality measure, sort them in descending order, and filter out those at the bottom. Furthermore, to accelerate the "filter-train-evaluate" iterations involved in BayesOpt on large-scale datasets, we propose a training framework that integrates maximum likelihood estimation (MLE) and negative training method (NEG). The training method updates parameters of a trained NCMs on two small sets with newly maintained and removed samples, respectively. Specifically, MLE is applied to maximize the log-likelihood of newly maintained samples, while NEG is used to minimize the log-likelihood of newly removed ones. Experimental results on two datasets show that our method can effectively identify untrustworthy samples, and NCMs trained on the filtered datasets achieve better performance.
Unsupervised Pre-training with Structured Knowledge for Improving Natural Language Inference
Sep 08, 2021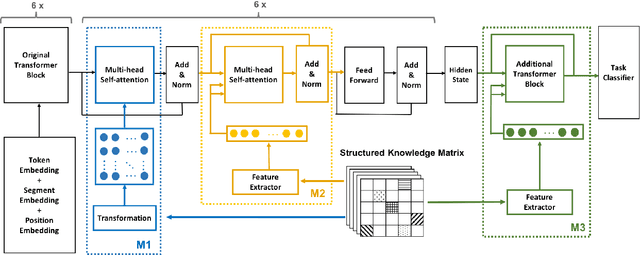
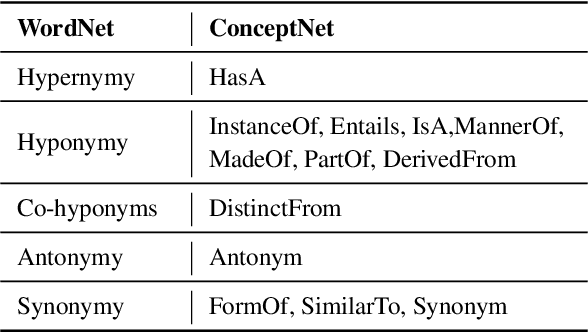
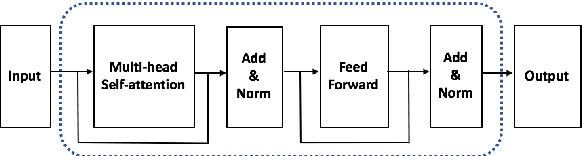
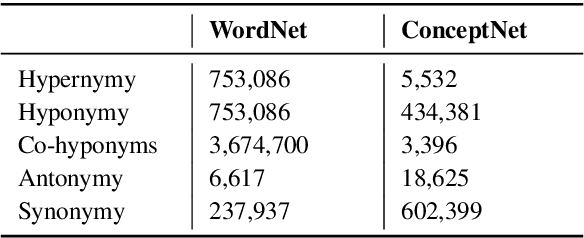
While recent research on natural language inference has considerably benefited from large annotated datasets, the amount of inference-related knowledge (including commonsense) provided in the annotated data is still rather limited. There have been two lines of approaches that can be used to further address the limitation: (1) unsupervised pretraining can leverage knowledge in much larger unstructured text data; (2) structured (often human-curated) knowledge has started to be considered in neural-network-based models for NLI. An immediate question is whether these two approaches complement each other, or how to develop models that can bring together their advantages. In this paper, we propose models that leverage structured knowledge in different components of pre-trained models. Our results show that the proposed models perform better than previous BERT-based state-of-the-art models. Although our models are proposed for NLI, they can be easily extended to other sentence or sentence-pair classification problems.
Unsupervised Conversation Disentanglement through Co-Training
Sep 07, 2021
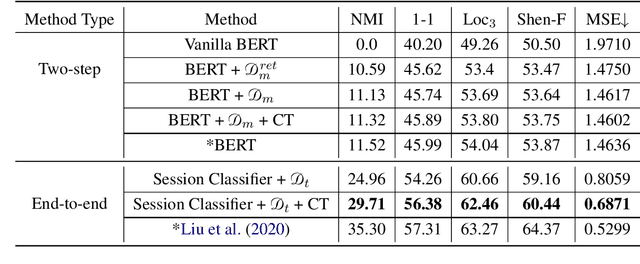
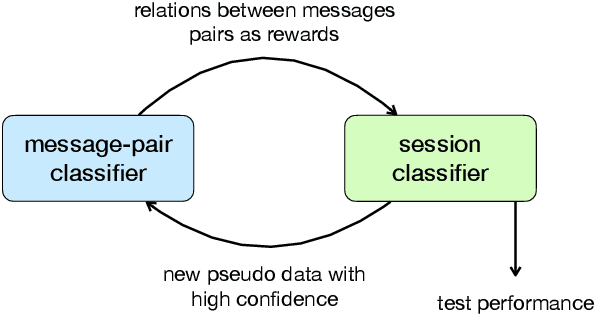
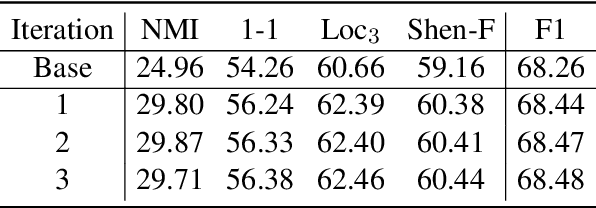
Conversation disentanglement aims to separate intermingled messages into detached sessions, which is a fundamental task in understanding multi-party conversations. Existing work on conversation disentanglement relies heavily upon human-annotated datasets, which are expensive to obtain in practice. In this work, we explore to train a conversation disentanglement model without referencing any human annotations. Our method is built upon a deep co-training algorithm, which consists of two neural networks: a message-pair classifier and a session classifier. The former is responsible for retrieving local relations between two messages while the latter categorizes a message to a session by capturing context-aware information. Both networks are initialized respectively with pseudo data built from an unannotated corpus. During the deep co-training process, we use the session classifier as a reinforcement learning component to learn a session assigning policy by maximizing the local rewards given by the message-pair classifier. For the message-pair classifier, we enrich its training data by retrieving message pairs with high confidence from the disentangled sessions predicted by the session classifier. Experimental results on the large Movie Dialogue Dataset demonstrate that our proposed approach achieves competitive performance compared to the previous supervised methods. Further experiments show that the predicted disentangled conversations can promote the performance on the downstream task of multi-party response selection.
Detecting Speaker Personas from Conversational Texts
Sep 03, 2021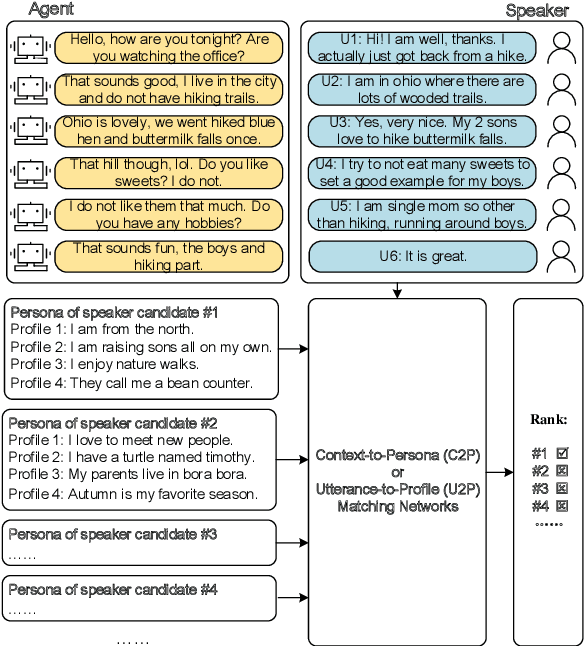
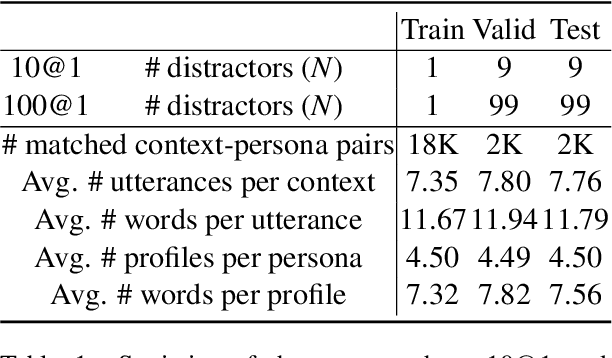
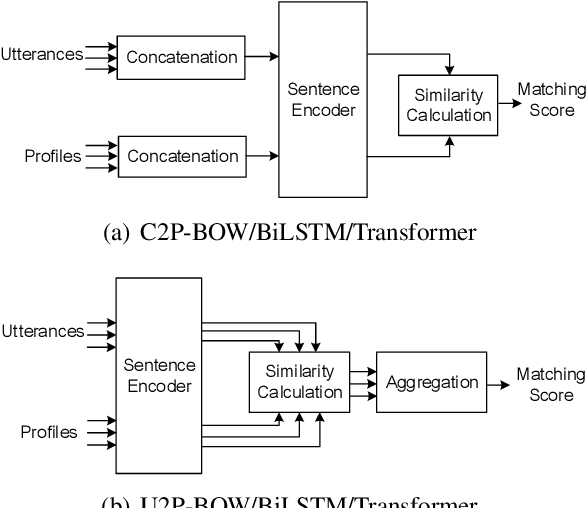
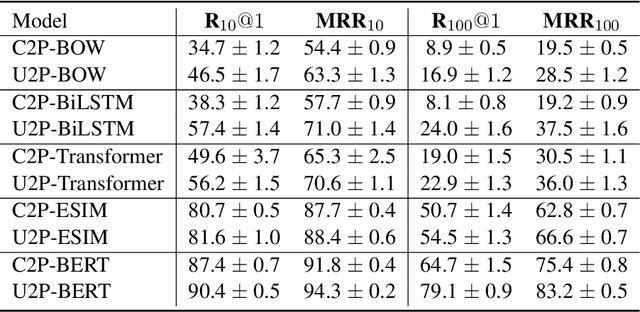
Personas are useful for dialogue response prediction. However, the personas used in current studies are pre-defined and hard to obtain before a conversation. To tackle this issue, we study a new task, named Speaker Persona Detection (SPD), which aims to detect speaker personas based on the plain conversational text. In this task, a best-matched persona is searched out from candidates given the conversational text. This is a many-to-many semantic matching task because both contexts and personas in SPD are composed of multiple sentences. The long-term dependency and the dynamic redundancy among these sentences increase the difficulty of this task. We build a dataset for SPD, dubbed as Persona Match on Persona-Chat (PMPC). Furthermore, we evaluate several baseline models and propose utterance-to-profile (U2P) matching networks for this task. The U2P models operate at a fine granularity which treat both contexts and personas as sets of multiple sequences. Then, each sequence pair is scored and an interpretable overall score is obtained for a context-persona pair through aggregation. Evaluation results show that the U2P models outperform their baseline counterparts significantly.
SemEval-2021 Task 4: Reading Comprehension of Abstract Meaning
Jun 01, 2021

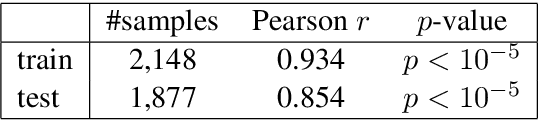
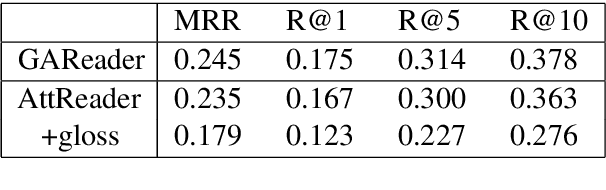
This paper introduces the SemEval-2021 shared task 4: Reading Comprehension of Abstract Meaning (ReCAM). This shared task is designed to help evaluate the ability of machines in representing and understanding abstract concepts. Given a passage and the corresponding question, a participating system is expected to choose the correct answer from five candidates of abstract concepts in a cloze-style machine reading comprehension setup. Based on two typical definitions of abstractness, i.e., the imperceptibility and nonspecificity, our task provides three subtasks to evaluate the participating models. Specifically, Subtask 1 aims to evaluate how well a system can model concepts that cannot be directly perceived in the physical world. Subtask 2 focuses on models' ability in comprehending nonspecific concepts located high in a hypernym hierarchy given the context of a passage. Subtask 3 aims to provide some insights into models' generalizability over the two types of abstractness. During the SemEval-2021 official evaluation period, we received 23 submissions to Subtask 1 and 28 to Subtask 2. The participating teams additionally made 29 submissions to Subtask 3. The leaderboard and competition website can be found at https://competitions.codalab.org/competitions/26153. The data and baseline code are available at https://github.com/boyuanzheng010/SemEval2021-Reading-Comprehension-of-Abstract-Meaning.
Preview, Attend and Review: Schema-Aware Curriculum Learning for Multi-Domain Dialog State Tracking
Jun 01, 2021
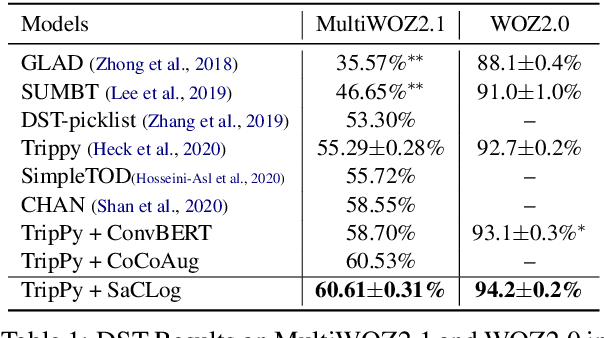
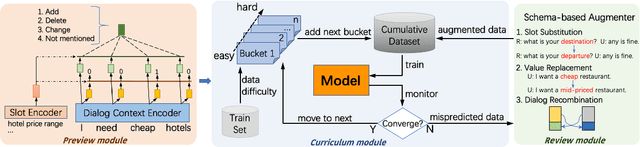
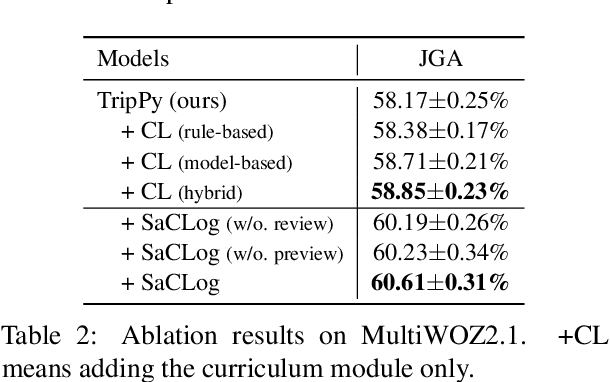
Existing dialog state tracking (DST) models are trained with dialog data in a random order, neglecting rich structural information in a dataset. In this paper, we propose to use curriculum learning (CL) to better leverage both the curriculum structure and schema structure for task-oriented dialogs. Specifically, we propose a model-agnostic framework called Schema-aware Curriculum Learning for Dialog State Tracking (SaCLog), which consists of a preview module that pre-trains a DST model with schema information, a curriculum module that optimizes the model with CL, and a review module that augments mispredicted data to reinforce the CL training. We show that our proposed approach improves DST performance over both a transformer-based and RNN-based DST model (TripPy and TRADE) and achieves new state-of-the-art results on WOZ2.0 and MultiWOZ2.1.