 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetweet-BERT: Political Leaning Detection Using Language Features and Information Diffusion on Social Networks
Jul 18, 2022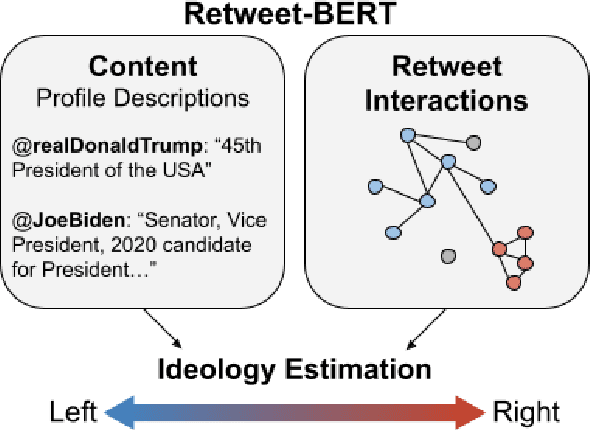
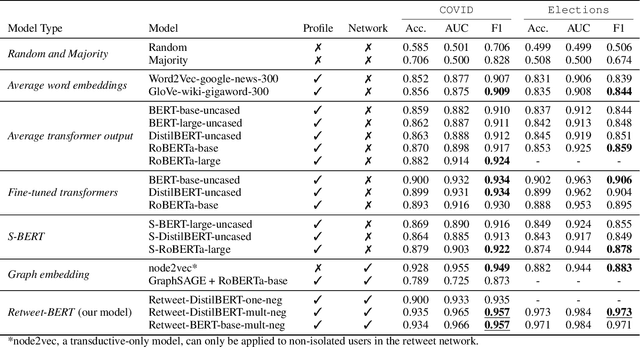
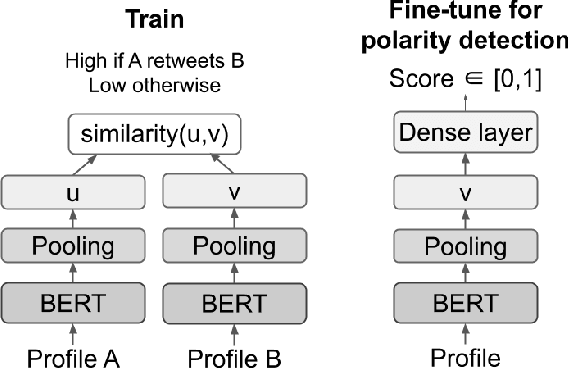

Estimating the political leanings of social media users is a challenging and ever more pressing problem given the increase in social media consumption. We introduce Retweet-BERT, a simple and scalable model to estimate the political leanings of Twitter users. Retweet-BERT leverages the retweet network structure and the language used in users' profile descriptions. Our assumptions stem from patterns of networks and linguistics homophily among people who share similar ideologies. Retweet-BERT demonstrates competitive performance against other state-of-the-art baselines, achieving 96%-97% macro-F1 on two recent Twitter datasets (a COVID-19 dataset and a 2020 United States presidential elections dataset). We also perform manual validation to validate the performance of Retweet-BERT on users not in the training data. Finally, in a case study of COVID-19, we illustrate the presence of political echo chambers on Twitter and show that it exists primarily among right-leaning users. Our code is open-sourced and our data is publicly available.
* 11 pages, 3 figures, 4 tables. arXiv admin note: text overlap with arXiv:2103.10979
FRAME: Evaluating Simulatability Metrics for Free-Text Rationales
Jul 02, 2022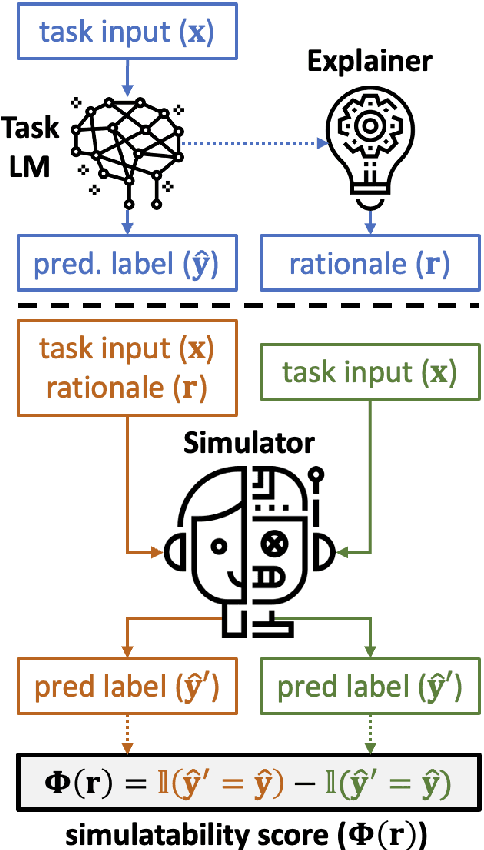
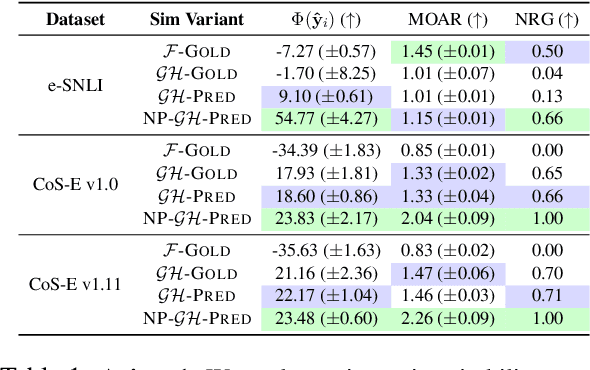

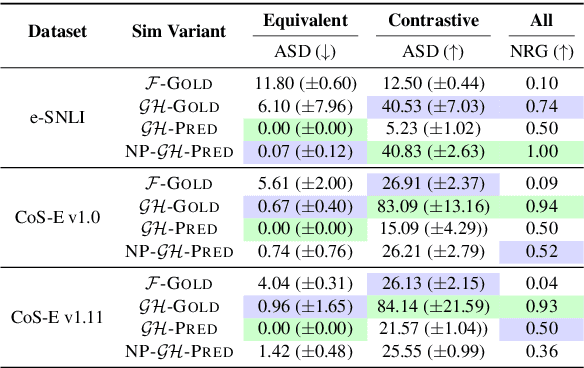
Free-text rationales aim to explain neural language model (LM) behavior more flexibly and intuitively via natural language. To ensure rationale quality, it is important to have metrics for measuring rationales' faithfulness (reflects LM's actual behavior) and plausibility (convincing to humans). All existing free-text rationale metrics are based on simulatability (association between rationale and LM's predicted label), but there is no protocol for assessing such metrics' reliability. To investigate this, we propose FRAME, a framework for evaluating free-text rationale simulatability metrics. FRAME is based on three axioms: (1) good metrics should yield highest scores for reference rationales, which maximize rationale-label association by construction; (2) good metrics should be appropriately sensitive to semantic perturbation of rationales; and (3) good metrics should be robust to variation in the LM's task performance. Across three text classification datasets, we show that existing simulatability metrics cannot satisfy all three FRAME axioms, since they are implemented via model pretraining which muddles the metric's signal. We introduce a non-pretraining simulatability variant that improves performance on (1) and (3) by an average of 41.7% and 42.9%, respectively, while performing competitively on (2).
NewsEdits: A News Article Revision Dataset and a Document-Level Reasoning Challenge
Jun 14, 2022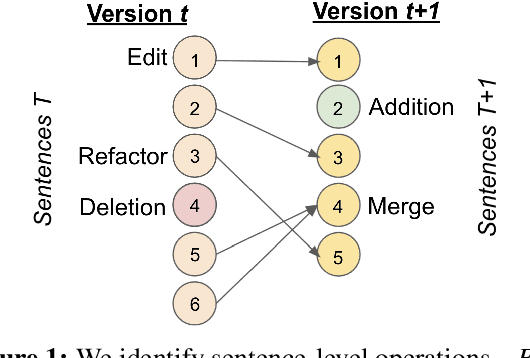
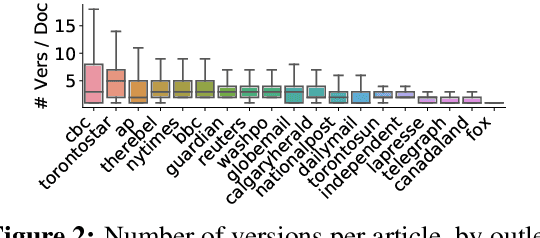
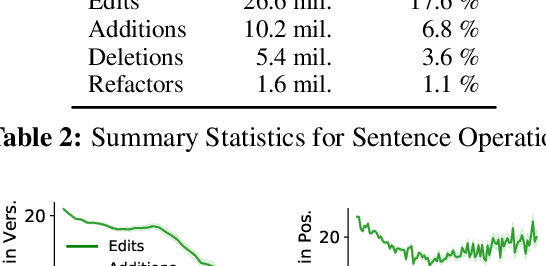
News article revision histories provide clues to narrative and factual evolution in news articles. To facilitate analysis of this evolution, we present the first publicly available dataset of news revision histories, NewsEdits. Our dataset is large-scale and multilingual; it contains 1.2 million articles with 4.6 million versions from over 22 English- and French-language newspaper sources based in three countries, spanning 15 years of coverage (2006-2021). We define article-level edit actions: Addition, Deletion, Edit and Refactor, and develop a high-accuracy extraction algorithm to identify these actions. To underscore the factual nature of many edit actions, we conduct analyses showing that added and deleted sentences are more likely to contain updating events, main content and quotes than unchanged sentences. Finally, to explore whether edit actions are predictable, we introduce three novel tasks aimed at predicting actions performed during version updates. We show that these tasks are possible for expert humans but are challenging for large NLP models. We hope this can spur research in narrative framing and help provide predictive tools for journalists chasing breaking news.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Eliciting Transferability in Multi-task Learning with Task-level Mixture-of-Experts
May 25, 2022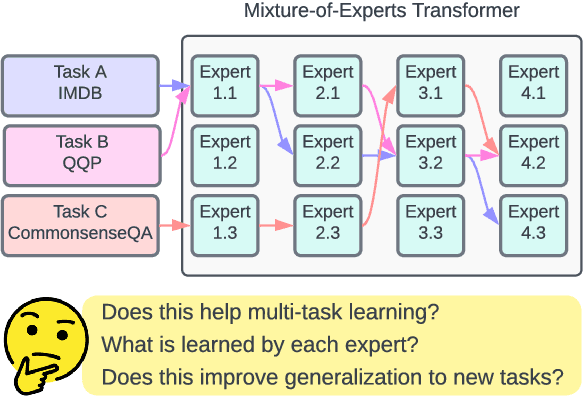
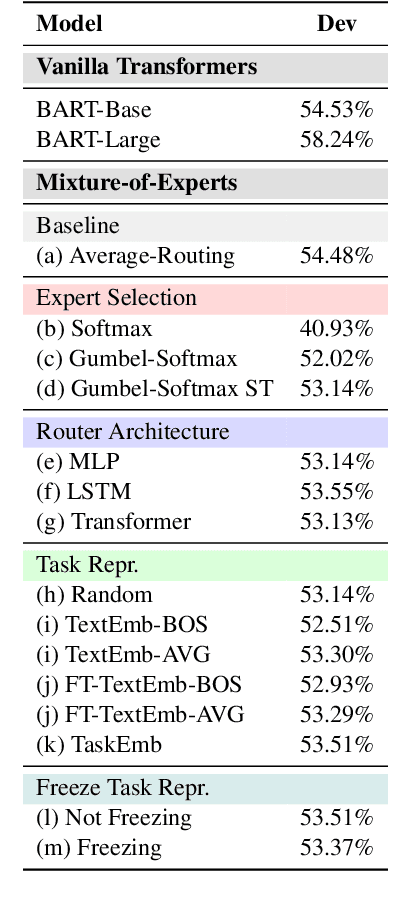
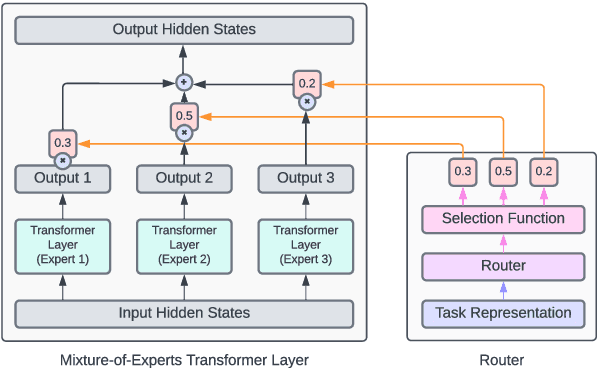
Recent work suggests that transformer models are capable of multi-task learning on diverse NLP tasks. However, the potential of these models may be limited as they use the same set of parameters for all tasks. In contrast, humans tackle tasks in a more flexible way, by making proper presumptions on what skills and knowledge are relevant and executing only the necessary computations. Inspired by this, we propose to use task-level mixture-of-expert models, which has a collection of transformer layers (i.e., experts) and a router component to choose among these experts dynamically and flexibly. We show that the learned routing decisions and experts partially rediscover human categorization of NLP tasks -- certain experts are strongly associated with extractive tasks, some with classification tasks, and some with tasks requiring world knowledge.
Textual Backdoor Attacks with Iterative Trigger Injection
May 25, 2022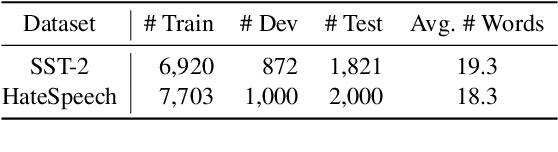
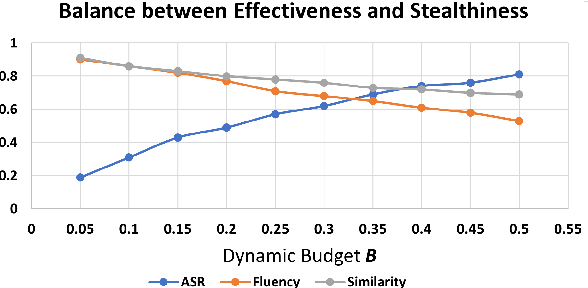
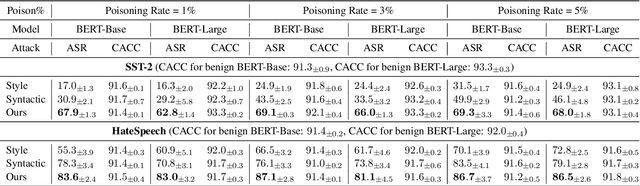
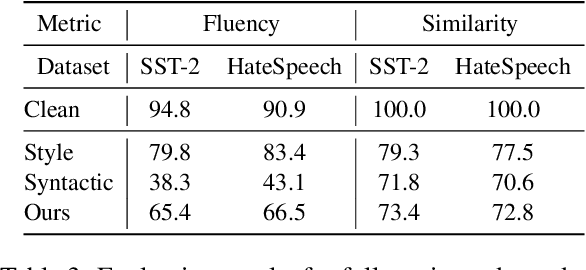
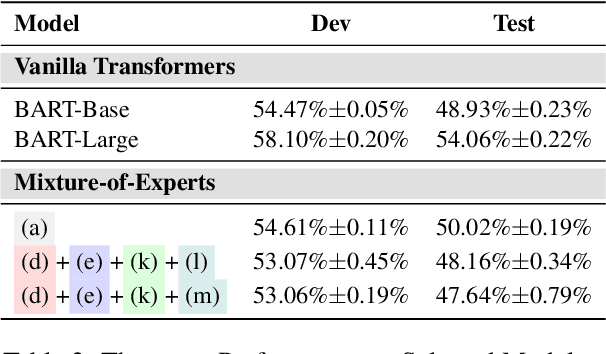
The backdoor attack has become an emerging threat for Natural Language Processing (NLP) systems. A victim model trained on poisoned data can be embedded with a "backdoor", making it predict the adversary-specified output (e.g., the positive sentiment label) on inputs satisfying the trigger pattern (e.g., containing a certain keyword). In this paper, we demonstrate that it's possible to design an effective and stealthy backdoor attack by iteratively injecting "triggers" into a small set of training data. While all triggers are common words that fit into the context, our poisoning process strongly associates them with the target label, forming the model backdoor. Experiments on sentiment analysis and hate speech detection show that our proposed attack is both stealthy and effective, raising alarm on the usage of untrusted training data. We further propose a defense method to combat this threat.
RobustLR: Evaluating Robustness to Logical Perturbation in Deductive Reasoning
May 25, 2022
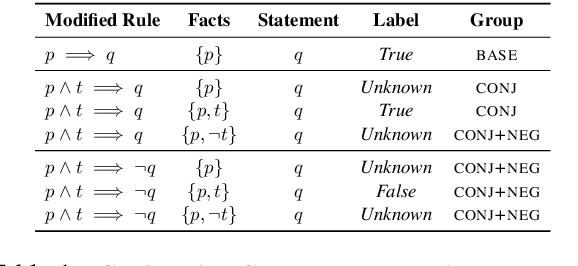

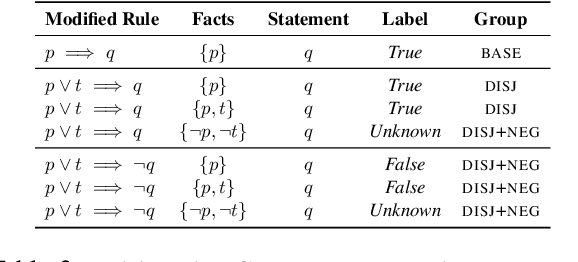
Transformers have been shown to be able to perform deductive reasoning on a logical rulebase containing rules and statements written in English natural language. While the progress is promising, it is currently unclear if these models indeed perform logical reasoning by understanding the underlying logical semantics in the language. To this end, we propose RobustLR, a suite of evaluation datasets that evaluate the robustness of these models to minimal logical edits in rulebases and some standard logical equivalence conditions. In our experiments with RoBERTa and T5, we find that the models trained in prior works do not perform consistently on the different perturbations in RobustLR, thus showing that the models are not robust to the proposed logical perturbations. Further, we find that the models find it especially hard to learn logical negation and disjunction operators. Overall, using our evaluation sets, we demonstrate some shortcomings of the deductive reasoning-based language models, which can eventually help towards designing better models for logical reasoning over natural language.
ER-TEST: Evaluating Explanation Regularization Methods for NLP Models
May 25, 2022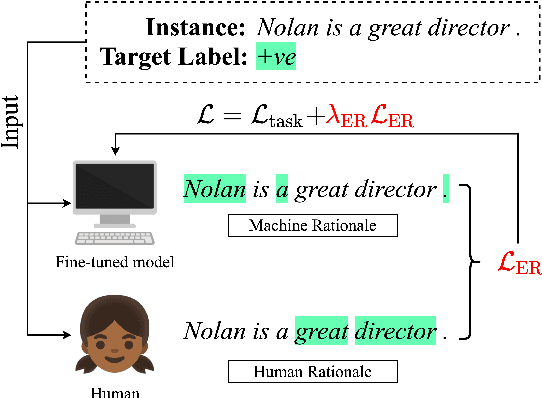
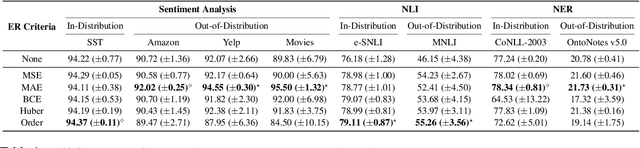
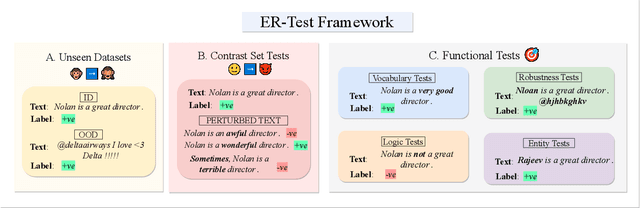
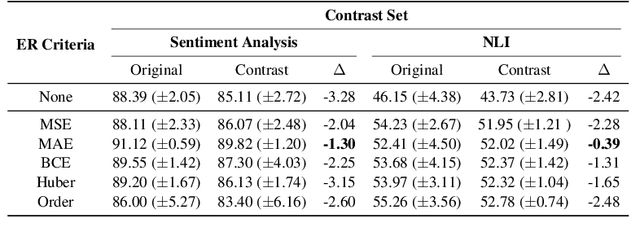
Neural language models' (NLMs') reasoning processes are notoriously hard to explain. Recently, there has been much progress in automatically generating machine rationales of NLM behavior, but less in utilizing the rationales to improve NLM behavior. For the latter, explanation regularization (ER) aims to improve NLM generalization by pushing the machine rationales to align with human rationales. Whereas prior works primarily evaluate such ER models via in-distribution (ID) generalization, ER's impact on out-of-distribution (OOD) is largely underexplored. Plus, little is understood about how ER model performance is affected by the choice of ER criteria or by the number/choice of training instances with human rationales. In light of this, we propose ER-TEST, a protocol for evaluating ER models' OOD generalization along three dimensions: (1) unseen datasets, (2) contrast set tests, and (3) functional tests. Using ER-TEST, we study three key questions: (A) Which ER criteria are most effective for the given OOD setting? (B) How is ER affected by the number/choice of training instances with human rationales? (C) Is ER effective with distantly supervised human rationales? ER-TEST enables comprehensive analysis of these questions by considering a diverse range of tasks and datasets. Through ER-TEST, we show that ER has little impact on ID performance, but can yield large gains on OOD performance w.r.t. (1)-(3). Also, we find that the best ER criterion is task-dependent, while ER can improve OOD performance even with limited and distantly-supervised human rationales.
Machine Translation Robustness to Natural Asemantic Variation
May 25, 2022
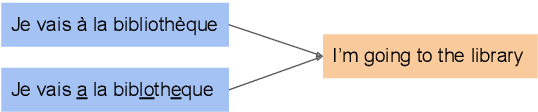

We introduce and formalize an under-studied linguistic phenomenon we call Natural Asemantic Variation (NAV) and investigate it in the context of Machine Translation (MT) robustness. Standard MT models are shown to be less robust to rarer, nuanced language forms, and current robustness techniques do not account for this kind of perturbation despite their prevalence in "real world" data. Experiment results provide more insight into the nature of NAV and we demonstrate strategies to improve performance on NAV. We also show that NAV robustness can be transferred across languages and fine that synthetic perturbations can achieve some but not all of the benefits of human-generated NAV data.
Cross-lingual Lifelong Learning
May 23, 2022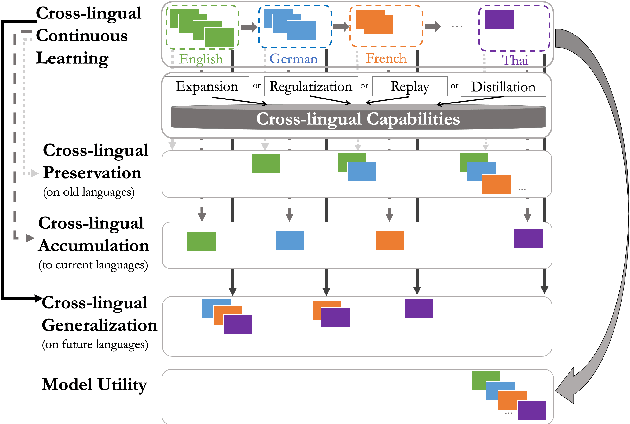
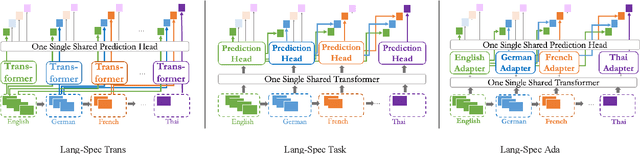

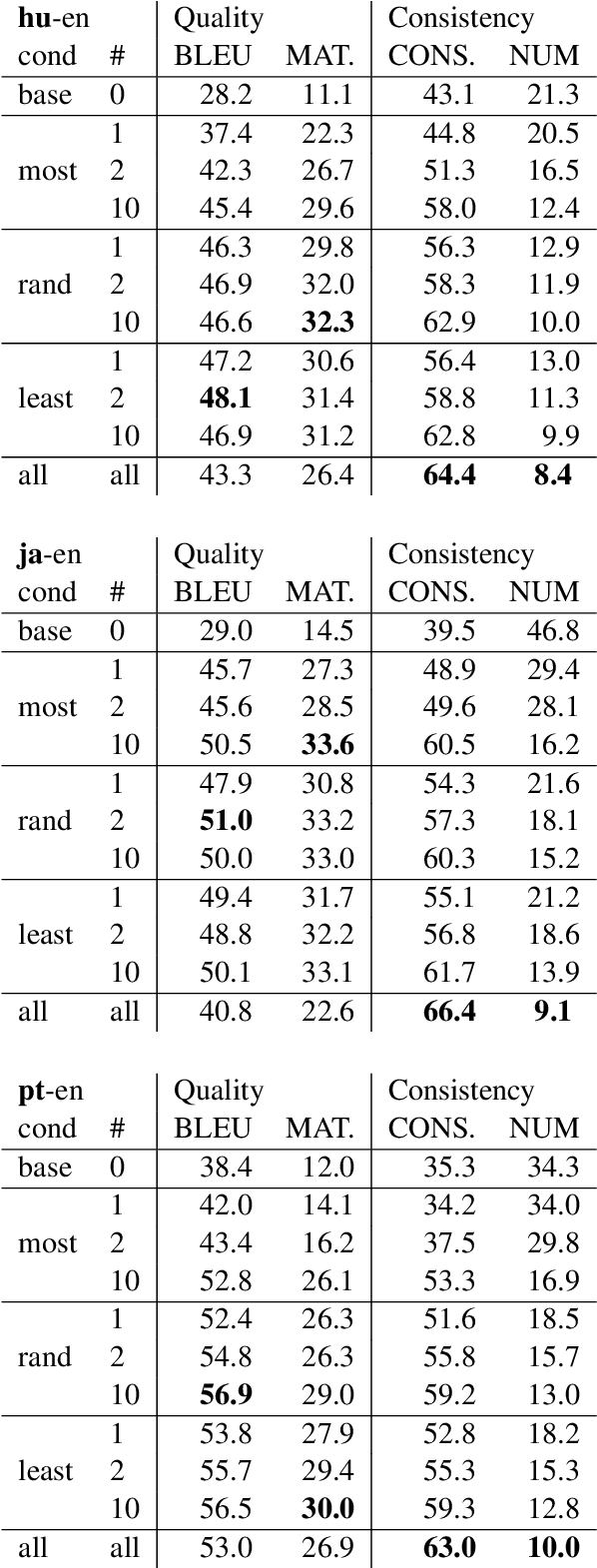
The longstanding goal of multi-lingual learning has been to develop a universal cross-lingual model that can withstand the changes in multi-lingual data distributions. However, most existing models assume full access to the target languages in advance, whereas in realistic scenarios this is not often the case, as new languages can be incorporated later on. In this paper, we present the Cross-lingual Lifelong Learning (CLL) challenge, where a model is continually fine-tuned to adapt to emerging data from different languages. We provide insights into what makes multilingual sequential learning particularly challenging. To surmount such challenges, we benchmark a representative set of cross-lingual continual learning algorithms and analyze their knowledge preservation, accumulation, and generalization capabilities compared to baselines on carefully curated datastreams. The implications of this analysis include a recipe for how to measure and balance between different cross-lingual continual learning desiderata, which goes beyond conventional transfer learning.