 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Mitigating Classification Bias via Transfer Learning
Oct 24, 2020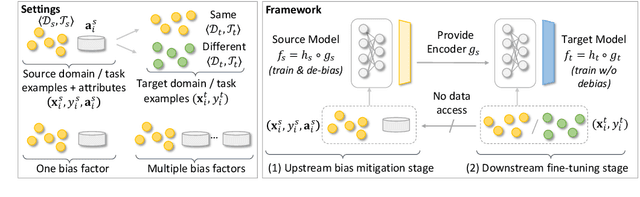
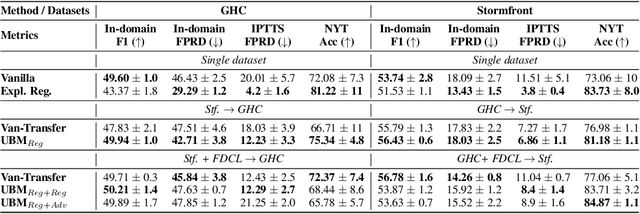
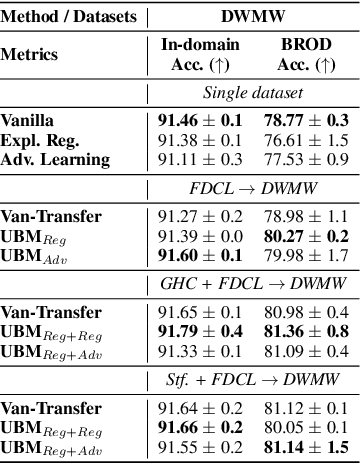
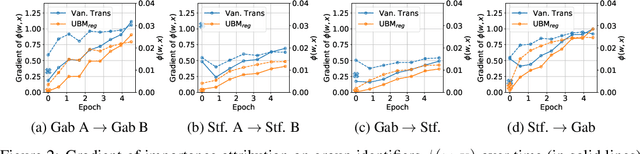
Prediction bias in machine learning models refers to unintended model behaviors that discriminate against inputs mentioning or produced by certain groups; for example, hate speech classifiers predict more false positives for neutral text mentioning specific social groups. Mitigating bias for each task or domain is inefficient, as it requires repetitive model training, data annotation (e.g., demographic information), and evaluation. In pursuit of a more accessible solution, we propose the Upstream Bias Mitigation for Downstream Fine-Tuning (UBM) framework, which mitigate one or multiple bias factors in downstream classifiers by transfer learning from an upstream model. In the upstream bias mitigation stage, explanation regularization and adversarial training are applied to mitigate multiple bias factors. In the downstream fine-tuning stage, the classifier layer of the model is re-initialized, and the entire model is fine-tuned to downstream tasks in potentially novel domains without any further bias mitigation. We expect downstream classifiers to be less biased by transfer learning from de-biased upstream models. We conduct extensive experiments varying the similarity between the source and target data, as well as varying the number of dimensions of bias (e.g., discrimination against specific social groups or dialects). Our results indicate the proposed UBM framework can effectively reduce bias in downstream classifiers.
Differentiable Open-Ended Commonsense Reasoning
Oct 24, 2020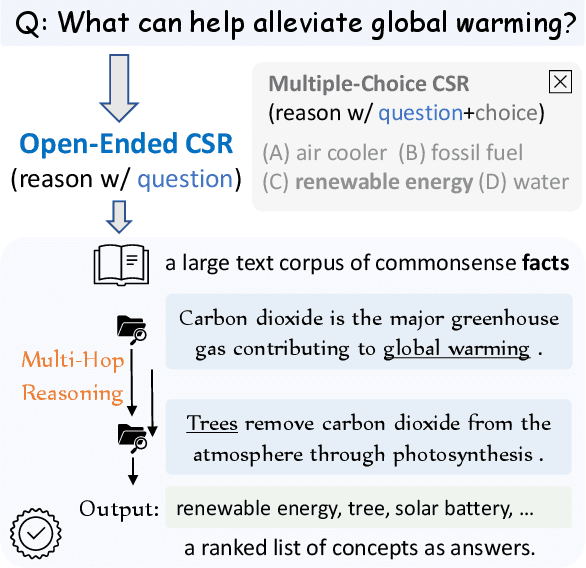

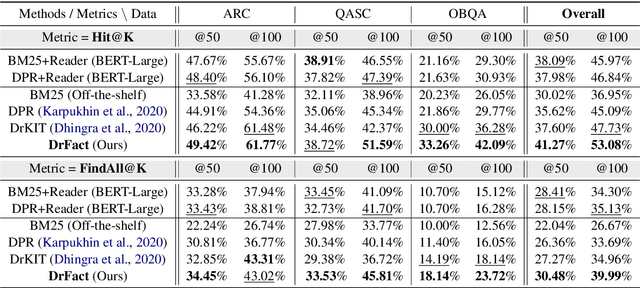
Current commonsense reasoning research mainly focuses on developing models that use commonsense knowledge to answer multiple-choice questions. However, systems designed to answer multiple-choice questions may not be useful in applications that do not provide a small list of possible candidate answers to choose from. As a step towards making commonsense reasoning research more realistic, we propose to study open-ended commonsense reasoning (OpenCSR) -- the task of answering a commonsense question without any pre-defined choices, using as a resource only a corpus of commonsense facts written in natural language. The task is challenging due to a much larger decision space, and because many commonsense questions require multi-hop reasoning. We propose an efficient differentiable model for multi-hop reasoning over knowledge facts, named DrFact. We evaluate our approach on a collection of re-formatted, open-ended versions of popular tests targeting commonsense reasoning, and show that our approach outperforms strong baseline methods by a large margin.
Fair Hate Speech Detection through Evaluation of Social Group Counterfactuals
Oct 24, 2020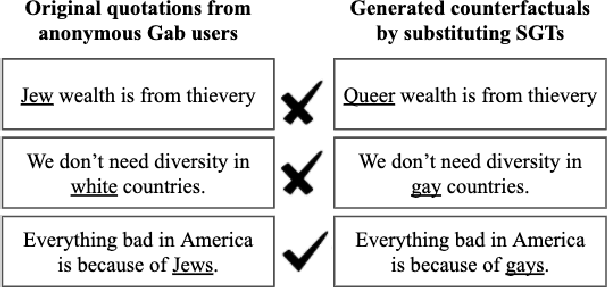
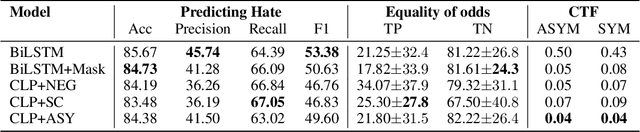
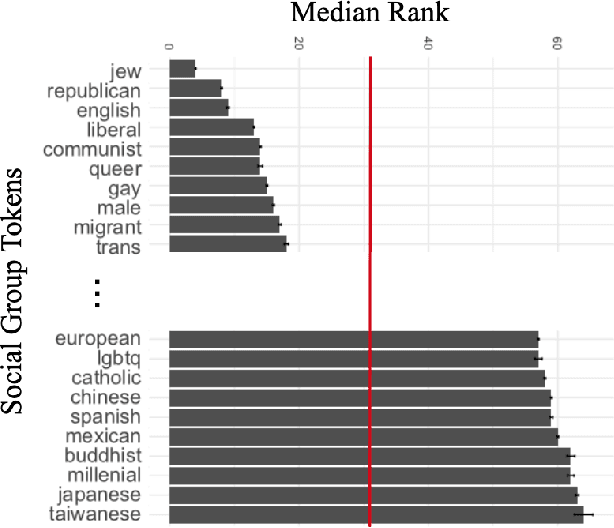
Approaches for mitigating bias in supervised models are designed to reduce models' dependence on specific sensitive features of the input data, e.g., mentioned social groups. However, in the case of hate speech detection, it is not always desirable to equalize the effects of social groups because of their essential role in distinguishing outgroup-derogatory hate, such that particular types of hateful rhetoric carry the intended meaning only when contextualized around certain social group tokens. Counterfactual token fairness for a mentioned social group evaluates the model's predictions as to whether they are the same for (a) the actual sentence and (b) a counterfactual instance, which is generated by changing the mentioned social group in the sentence. Our approach assures robust model predictions for counterfactuals that imply similar meaning as the actual sentence. To quantify the similarity of a sentence and its counterfactual, we compare their likelihood score calculated by generative language models. By equalizing model behaviors on each sentence and its counterfactuals, we mitigate bias in the proposed model while preserving the overall classification performance.
Constrained Abstractive Summarization: Preserving Factual Consistency with Constrained Generation
Oct 24, 2020
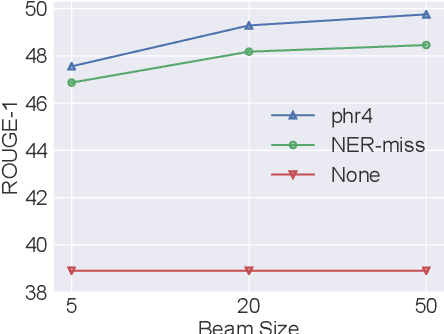
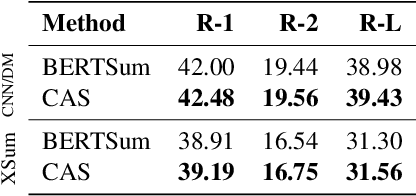
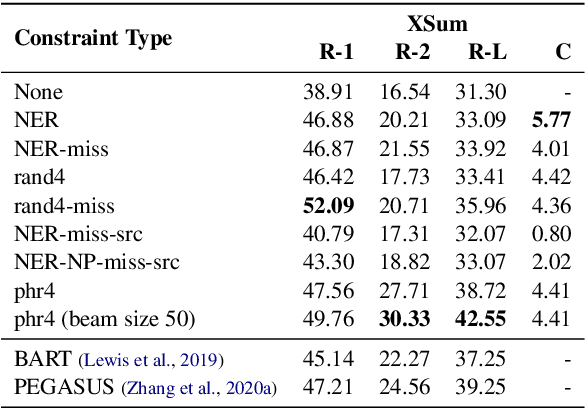
Summaries generated by abstractive summarization are supposed to only contain statements entailed by the source documents. However, state-of-the-art abstractive methods are still prone to hallucinate content inconsistent with the source documents. In this paper, we propose constrained abstractive summarization (CAS), a general setup that preserves the factual consistency of abstractive summarization by specifying tokens as constraints that must be present in the summary. We explore the feasibility of using lexically constrained decoding, a technique applicable to any abstractive method with beam search decoding, to fulfill CAS and conduct experiments in two scenarios: (1) Standard summarization without human involvement, where keyphrase extraction is used to extract constraints from source documents; (2) Interactive summarization with human feedback, which is simulated by taking missing tokens in the reference summaries as constraints. Automatic and human evaluations on two benchmark datasets demonstrate that CAS improves the quality of abstractive summaries, especially on factual consistency. In particular, we observe up to 11.2 ROUGE-2 gains when several ground-truth tokens are used as constraints in the interactive summarization scenario.
One-shot Learning for Temporal Knowledge Graphs
Oct 23, 2020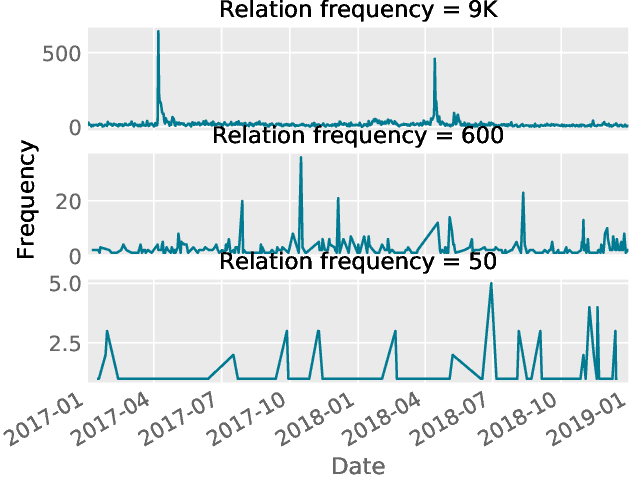
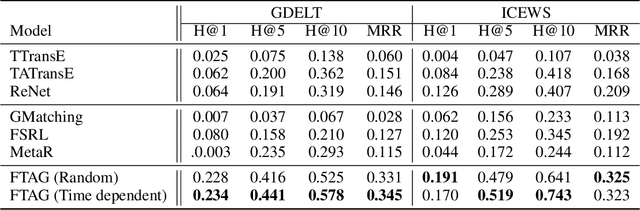
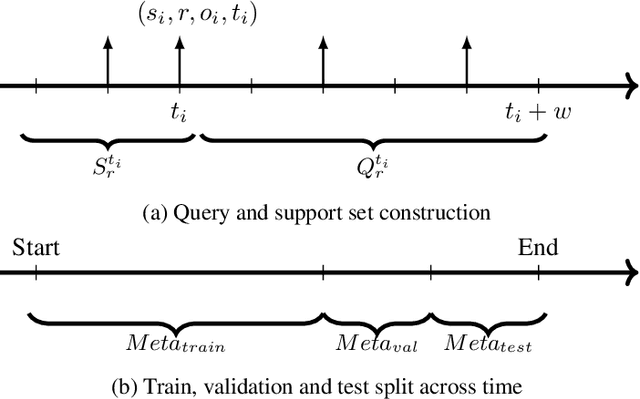

Most real-world knowledge graphs are characterized by a long-tail relation frequency distribution where a significant fraction of relations occurs only a handful of times. This observation has given rise to recent interest in low-shot learning methods that are able to generalize from only a few examples. The existing approaches, however, are tailored to static knowledge graphs and not easily generalized to temporal settings, where data scarcity poses even bigger problems, e.g., due to occurrence of new, previously unseen relations. We address this shortcoming by proposing a one-shot learning framework for link prediction in temporal knowledge graphs. Our proposed method employs a self-attention mechanism to effectively encode temporal interactions between entities, and a network to compute a similarity score between a given query and a (one-shot) example. Our experiments show that the proposed algorithm outperforms the state of the art baselines for two well-studied benchmarks while achieving significantly better performance for sparse relations.
Will This Idea Spread Beyond Academia? Understanding Knowledge Transfer of Scientific Concepts across Text Corpora
Oct 13, 2020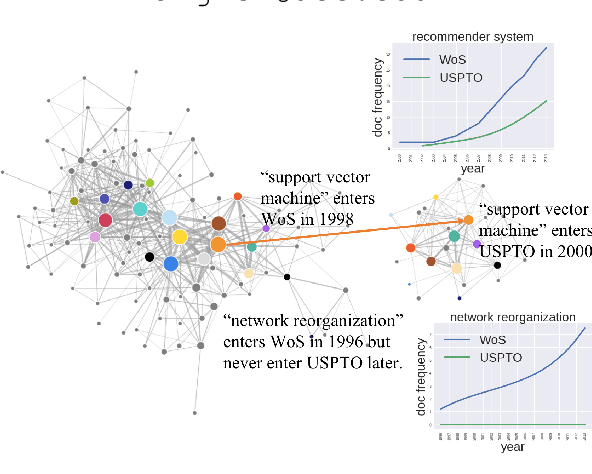
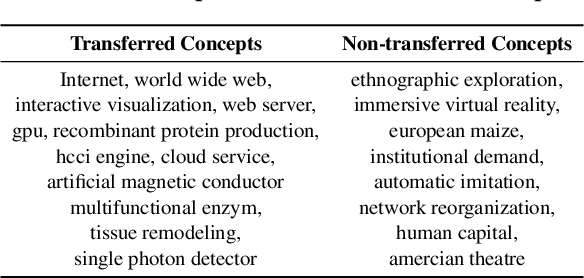
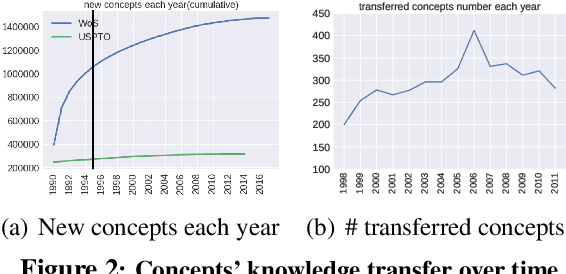
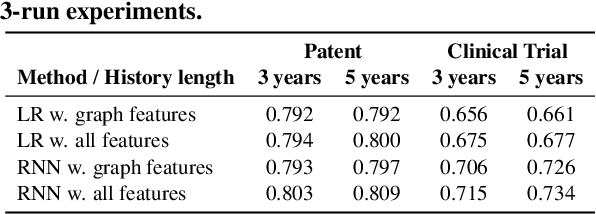
What kind of basic research ideas are more likely to get applied in practice? There is a long line of research investigating patterns of knowledge transfer, but it generally focuses on documents as the unit of analysis and follow their transfer into practice for a specific scientific domain. Here we study translational research at the level of scientific concepts for all scientific fields. We do this through text mining and predictive modeling using three corpora: 38.6 million paper abstracts, 4 million patent documents, and 0.28 million clinical trials. We extract scientific concepts (i.e., phrases) from corpora as instantiations of "research ideas", create concept-level features as motivated by literature, and then follow the trajectories of over 450,000 new concepts (emerged from 1995-2014) to identify factors that lead only a small proportion of these ideas to be used in inventions and drug trials. Results from our analysis suggest several mechanisms that distinguish which scientific concept will be adopted in practice, and which will not. We also demonstrate that our derived features can be used to explain and predict knowledge transfer with high accuracy. Our work provides greater understanding of knowledge transfer for researchers, practitioners, and government agencies interested in encouraging translational research.
Multi-document Summarization with Maximal Marginal Relevance-guided Reinforcement Learning
Sep 30, 2020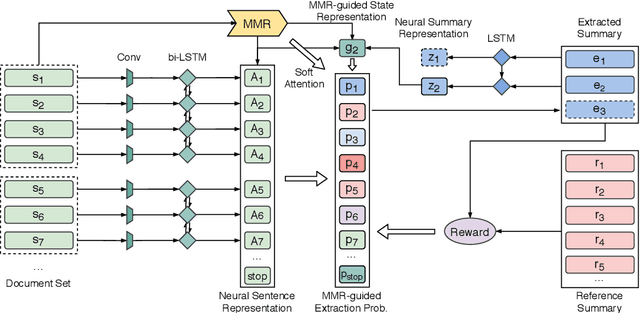
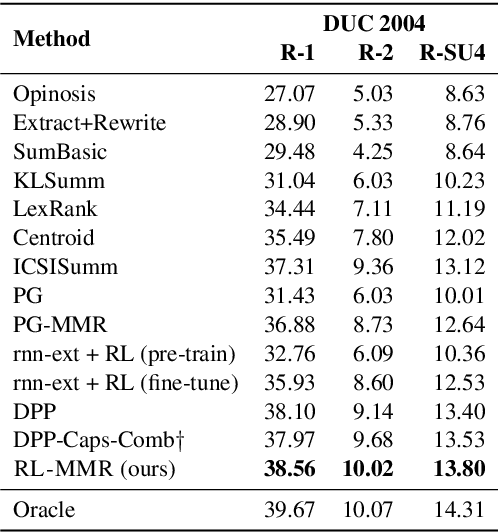
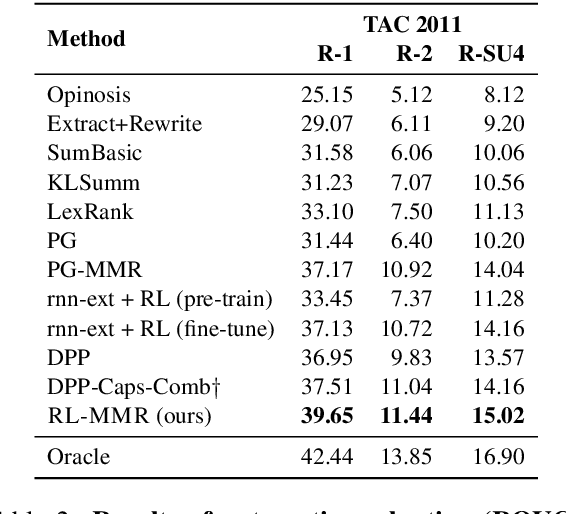
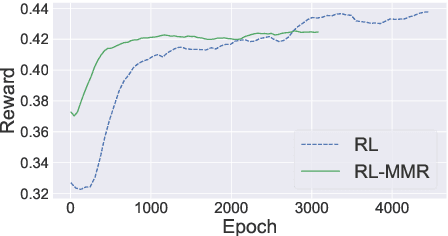
While neural sequence learning methods have made significant progress in single-document summarization (SDS), they produce unsatisfactory results on multi-document summarization (MDS). We observe two major challenges when adapting SDS advances to MDS: (1) MDS involves larger search space and yet more limited training data, setting obstacles for neural methods to learn adequate representations; (2) MDS needs to resolve higher information redundancy among the source documents, which SDS methods are less effective to handle. To close the gap, we present RL-MMR, Maximal Margin Relevance-guided Reinforcement Learning for MDS, which unifies advanced neural SDS methods and statistical measures used in classical MDS. RL-MMR casts MMR guidance on fewer promising candidates, which restrains the search space and thus leads to better representation learning. Additionally, the explicit redundancy measure in MMR helps the neural representation of the summary to better capture redundancy. Extensive experiments demonstrate that RL-MMR achieves state-of-the-art performance on benchmark MDS datasets. In particular, we show the benefits of incorporating MMR into end-to-end learning when adapting SDS to MDS in terms of both learning effectiveness and efficiency.
SynSetExpan: An Iterative Framework for Joint Entity Set Expansion and Synonym Discovery
Sep 29, 2020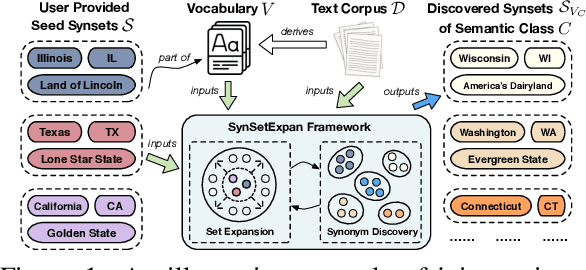
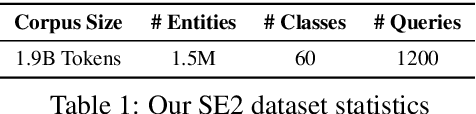
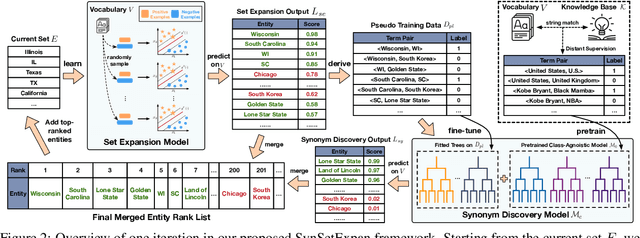
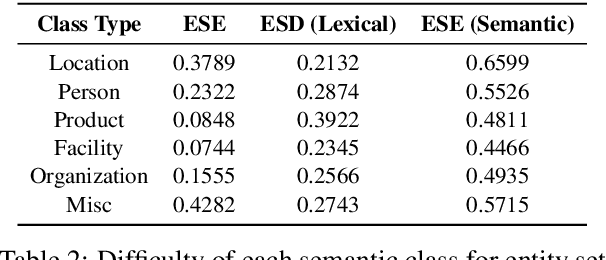
Entity set expansion and synonym discovery are two critical NLP tasks. Previous studies accomplish them separately, without exploring their interdependencies. In this work, we hypothesize that these two tasks are tightly coupled because two synonymous entities tend to have similar likelihoods of belonging to various semantic classes. This motivates us to design SynSetExpan, a novel framework that enables two tasks to mutually enhance each other. SynSetExpan uses a synonym discovery model to include popular entities' infrequent synonyms into the set, which boosts the set expansion recall. Meanwhile, the set expansion model, being able to determine whether an entity belongs to a semantic class, can generate pseudo training data to fine-tune the synonym discovery model towards better accuracy. To facilitate the research on studying the interplays of these two tasks, we create the first large-scale Synonym-Enhanced Set Expansion (SE2) dataset via crowdsourcing. Extensive experiments on the SE2 dataset and previous benchmarks demonstrate the effectiveness of SynSetExpan for both entity set expansion and synonym discovery tasks.
Two Step Joint Model for Drug Drug Interaction Extraction
Aug 28, 2020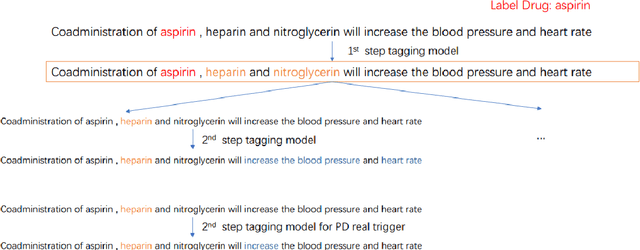

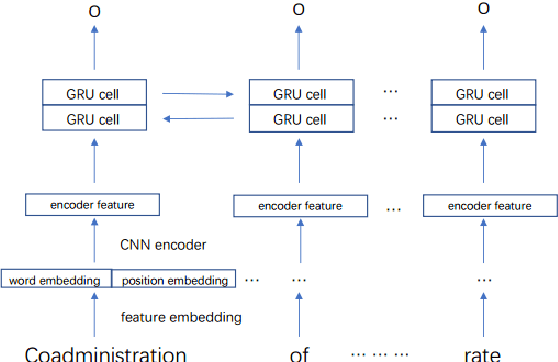

When patients need to take medicine, particularly taking more than one kind of drug simultaneously, they should be alarmed that there possibly exists drug-drug interaction. Interaction between drugs may have a negative impact on patients or even cause death. Generally, drugs that conflict with a specific drug (or label drug) are usually described in its drug label or package insert. Since more and more new drug products come into the market, it is difficult to collect such information by manual. We take part in the Drug-Drug Interaction (DDI) Extraction from Drug Labels challenge of Text Analysis Conference (TAC) 2018, choosing task1 and task2 to automatically extract DDI related mentions and DDI relations respectively. Instead of regarding task1 as named entity recognition (NER) task and regarding task2 as relation extraction (RE) task then solving it in a pipeline, we propose a two step joint model to detect DDI and it's related mentions jointly. A sequence tagging system (CNN-GRU encoder-decoder) finds precipitants first and search its fine-grained Trigger and determine the DDI for each precipitant in the second step. Moreover, a rule based model is built to determine the sub-type for pharmacokinetic interation. Our system achieved best result in both task1 and task2. F-measure reaches 0.46 in task1 and 0.40 in task2.
Gradient Based Memory Editing for Task-Free Continual Learning
Jun 27, 2020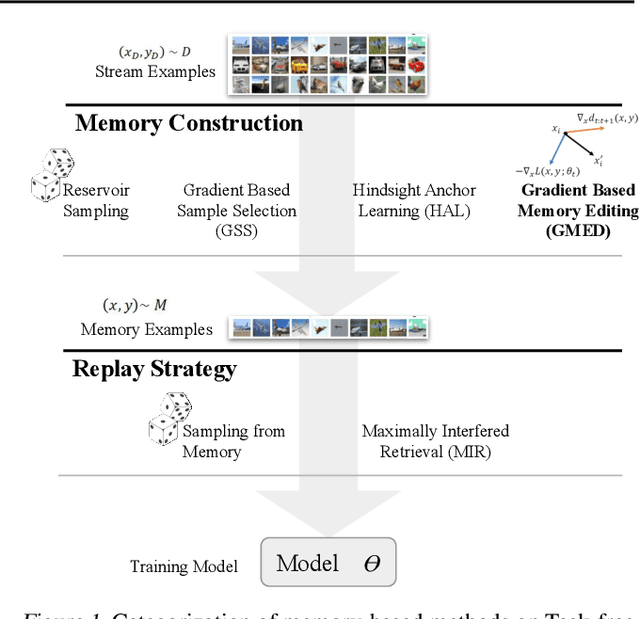
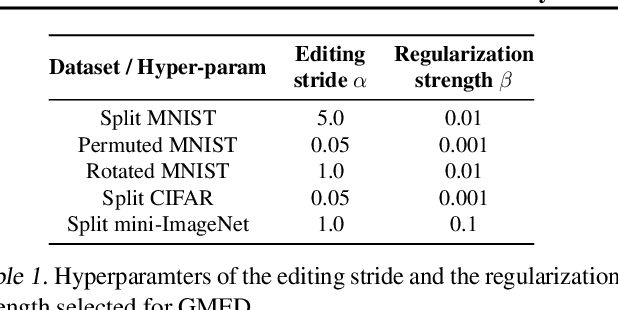
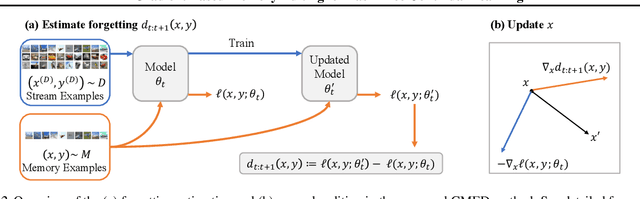
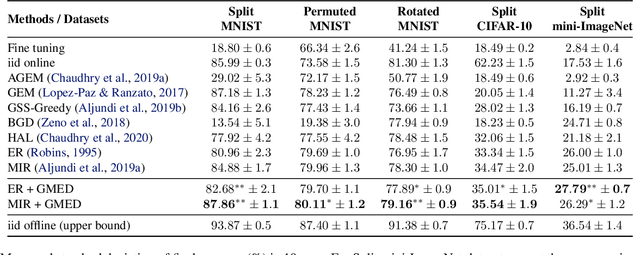
Prior work on continual learning often operate in a "task-aware" manner, by assuming that the task boundaries and identifies of the data instances are known at all times. While in practice, it is rarely the case that such information are exposed to the methods (i.e., thus called "task-free")--a setting that is relatively underexplored. Recent attempts on task-free continual learning build on previous memory replay methods and focus on developing memory management strategies such that model performance over priorly seen instances can be best retained. In this paper, looking from a complementary angle, we propose a principled approach to "edit" stored examples which aims to carry more updated information from the data stream in the memory. We use gradient updates to edit stored examples so that they are more likely to be forgotten in future updates. Experiments on five benchmark datasets show the proposed method can be seamlessly combined with baselines to significantly improve the performance. Code has been released at https://github.com/INK-USC/GMED.