 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Style Transfer based Domain Generalization Networks Integrating Shape and Spatial Information
Sep 03, 2020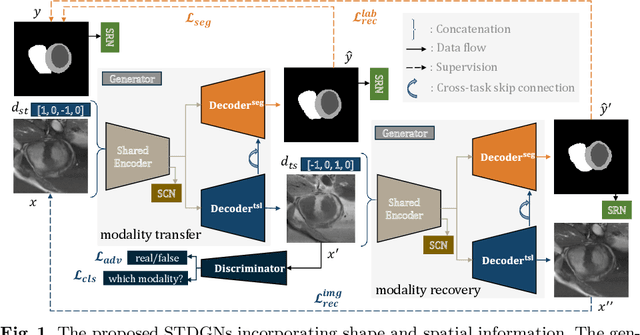
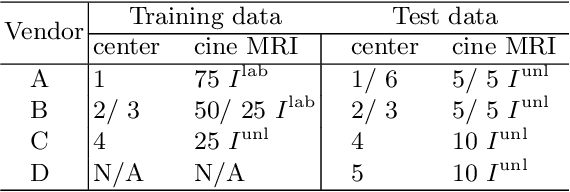
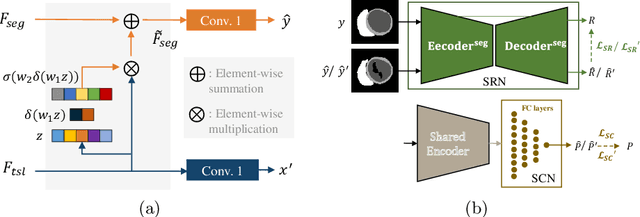
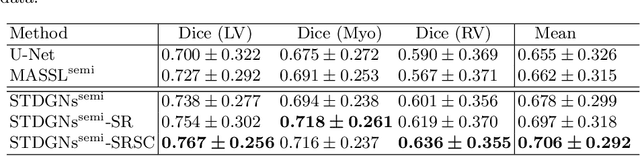
Deep learning (DL)-based models have demonstrated good performance in medical image segmentation. However, the models trained on a known dataset often fail when performed on an unseen dataset collected from different centers, vendors and disease populations. In this work, we present a random style transfer network to tackle the domain generalization problem for multi-vendor and center cardiac image segmentation. Style transfer is used to generate training data with a wider distribution/ heterogeneity, namely domain augmentation. As the target domain could be unknown, we randomly generate a modality vector for the target modality in the style transfer stage, to simulate the domain shift for unknown domains. The model can be trained in a semi-supervised manner by simultaneously optimizing a supervised segmentation and an unsupervised style translation objective. Besides, the framework incorporates the spatial information and shape prior of the target by introducing two regularization terms. We evaluated the proposed framework on 40 subjects from the M\&Ms challenge2020, and obtained promising performance in the segmentation for data from unknown vendors and centers.
AtrialJSQnet: A New Framework for Joint Segmentation and Quantification of Left Atrium and Scars Incorporating Spatial and Shape Information
Aug 11, 2020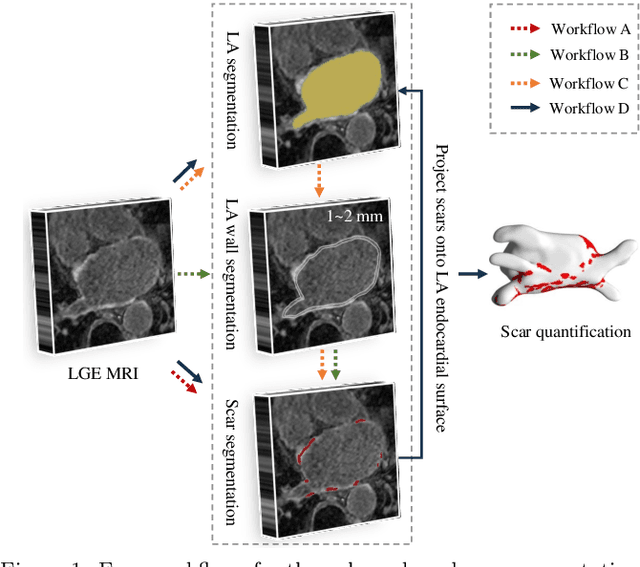
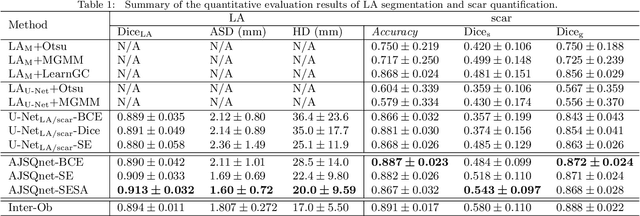
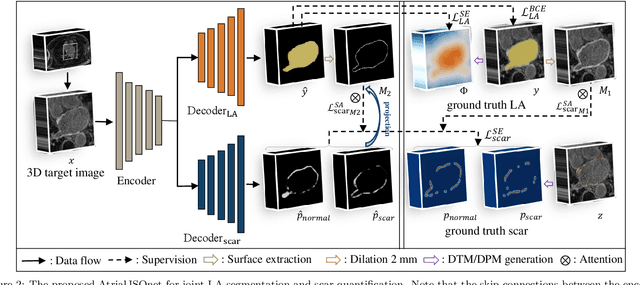
Left atrial (LA) and atrial scar segmentation from late gadolinium enhanced magnetic resonance imaging (LGE MRI) is an important task in clinical practice. %, to guide ablation therapy and predict treatment results for atrial fibrillation (AF) patients. The automatic segmentation is however still challenging, due to the poor image quality, the various LA shapes, the thin wall, and the surrounding enhanced regions. Previous methods normally solved the two tasks independently and ignored the intrinsic spatial relationship between LA and scars. In this work, we develop a new framework, namely AtrialJSQnet, where LA segmentation, scar projection onto the LA surface, and scar quantification are performed simultaneously in an end-to-end style. We propose a mechanism of shape attention (SA) via an explicit surface projection, to utilize the inherent correlation between LA and LA scars. In specific, the SA scheme is embedded into a multi-task architecture to perform joint LA segmentation and scar quantification. Besides, a spatial encoding (SE) loss is introduced to incorporate continuous spatial information of the target, in order to reduce noisy patches in the predicted segmentation. We evaluated the proposed framework on 60 LGE MRIs from the MICCAI2018 LA challenge. Extensive experiments on a public dataset demonstrated the effect of the proposed AtrialJSQnet, which achieved competitive performance over the state-of-the-art. The relatedness between LA segmentation and scar quantification was explicitly explored and has shown significant performance improvements for both tasks. The code and results will be released publicly once the manuscript is accepted for publication via https://zmiclab.github.io/projects.html.
MvMM-RegNet: A new image registration framework based on multivariate mixture model and neural network estimation
Jul 14, 2020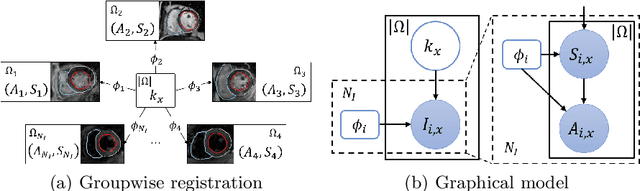
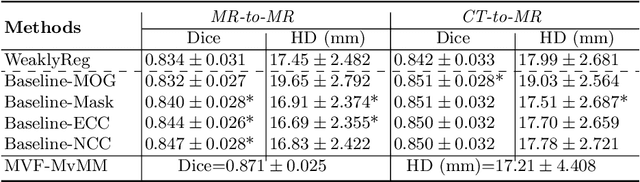
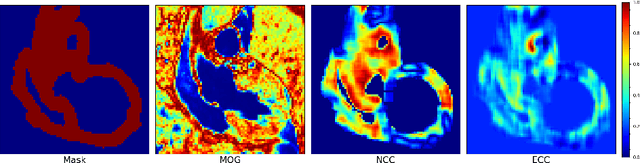
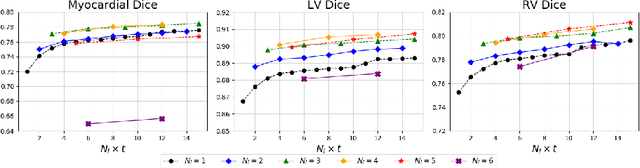
Current deep-learning-based registration algorithms often exploit intensity-based similarity measures as the loss function, where dense correspondence between a pair of moving and fixed images is optimized through backpropagation during training. However, intensity-based metrics can be misleading when the assumption of intensity class correspondence is violated, especially in cross-modality or contrast-enhanced images. Moreover, existing learning-based registration methods are predominantly applicable to pairwise registration and are rarely extended to groupwise registration or simultaneous registration with multiple images. In this paper, we propose a new image registration framework based on multivariate mixture model (MvMM) and neural network estimation. A generative model consolidating both appearance and anatomical information is established to derive a novel loss function capable of implementing groupwise registration. We highlight the versatility of the proposed framework for various applications on multimodal cardiac images, including single-atlas-based segmentation (SAS) via pairwise registration and multi-atlas segmentation (MAS) unified by groupwise registration. We evaluated performance on two publicly available datasets, i.e. MM-WHS-2017 and MS-CMRSeg-2019. The results show that the proposed framework achieved an average Dice score of $0.871\pm 0.025$ for whole-heart segmentation on MR images and $0.783\pm 0.082$ for myocardium segmentation on LGE MR images.
Joint Left Atrial Segmentation and Scar Quantification Based on a DNN with Spatial Encoding and Shape Attention
Jun 23, 2020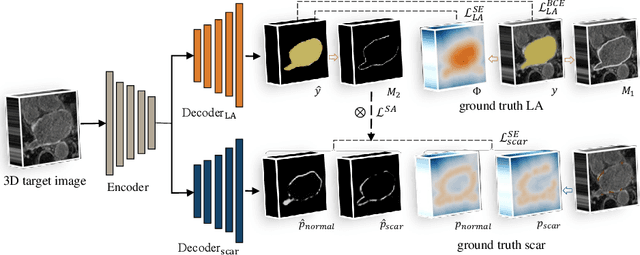
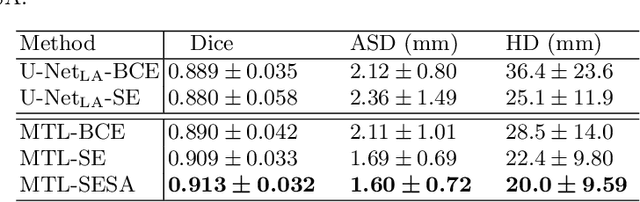
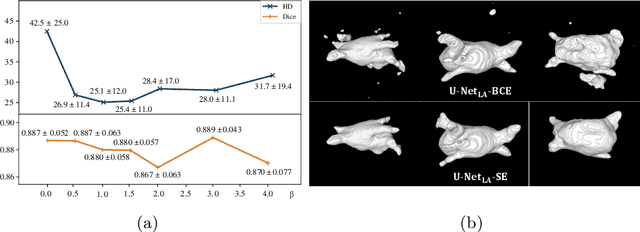
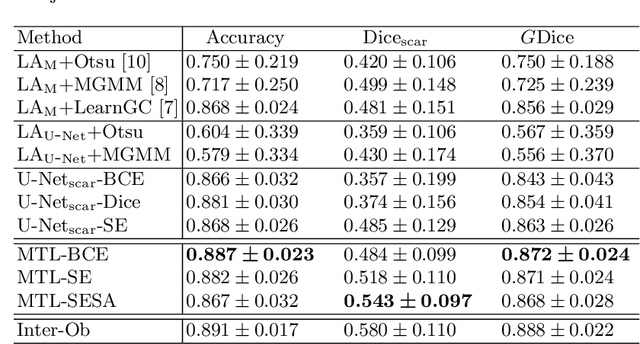
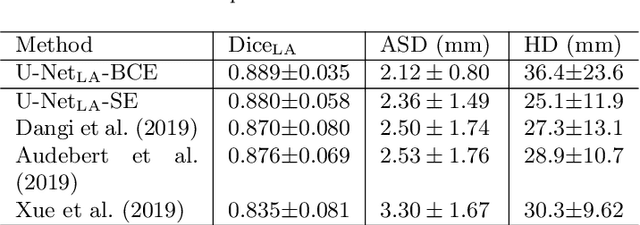
We propose an end-to-end deep neural network (DNN) which can simultaneously segment the left atrial (LA) cavity and quantify LA scars. The framework incorporates the continuous spatial information of the target by introducing a spatially encoded (SE) loss based on the distance transform map. Compared to conventional binary label based loss, the proposed SE loss can reduce noisy patches in the resulting segmentation, which is commonly seen for deep learning-based methods. To fully utilize the inherent spatial relationship between LA and LA scars, we further propose a shape attention (SA) mechanism through an explicit surface projection to build an end-to-end-trainable model. Specifically, the SA scheme is embedded into a two-task network to perform the joint LA segmentation and scar quantification. Moreover, the proposed method can alleviate the severe class-imbalance problem when detecting small and discrete targets like scars. We evaluated the proposed framework on 60 LGE MRI data from the MICCAI2018 LA challenge. For LA segmentation, the proposed method reduced the mean Hausdorff distance from 36.4 mm to 20.0 mm compared to the 3D basic U-Net using the binary cross-entropy loss. For scar quantification, the method was compared with the results or algorithms reported in the literature and demonstrated better performance.
* 10 pages
Cardiac Segmentation on Late Gadolinium Enhancement MRI: A Benchmark Study from Multi-Sequence Cardiac MR Segmentation Challenge
Jun 22, 2020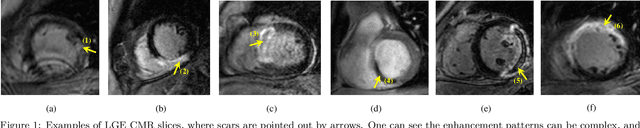
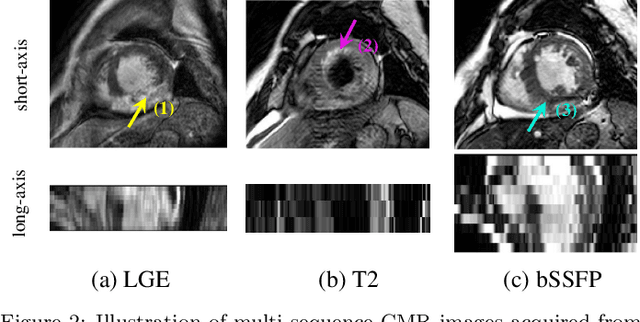

Accurate computing, analysis and modeling of the ventricles and myocardium from medical images are important, especially in the diagnosis and treatment management for patients suffering from myocardial infarction (MI). Late gadolinium enhancement (LGE) cardiac magnetic resonance (CMR) provides an important protocol to visualize MI. However, automated segmentation of LGE CMR is still challenging, due to the indistinguishable boundaries, heterogeneous intensity distribution and complex enhancement patterns of pathological myocardium from LGE CMR. Furthermore, compared with the other sequences LGE CMR images with gold standard labels are particularly limited, which represents another obstacle for developing novel algorithms for automatic segmentation of LGE CMR. This paper presents the selective results from the Multi-Sequence Cardiac MR (MS-CMR) Segmentation challenge, in conjunction with MICCAI 2019. The challenge offered a data set of paired MS-CMR images, including auxiliary CMR sequences as well as LGE CMR, from 45 patients who underwent cardiomyopathy. It was aimed to develop new algorithms, as well as benchmark existing ones for LGE CMR segmentation and compare them objectively. In addition, the paired MS-CMR images could enable algorithms to combine the complementary information from the other sequences for the segmentation of LGE CMR. Nine representative works were selected for evaluation and comparisons, among which three methods are unsupervised methods and the other six are supervised. The results showed that the average performance of the nine methods was comparable to the inter-observer variations. The success of these methods was mainly attributed to the inclusion of the auxiliary sequences from the MS-CMR images, which provide important label information for the training of deep neural networks.
A Global Benchmark of Algorithms for Segmenting Late Gadolinium-Enhanced Cardiac Magnetic Resonance Imaging
May 07, 2020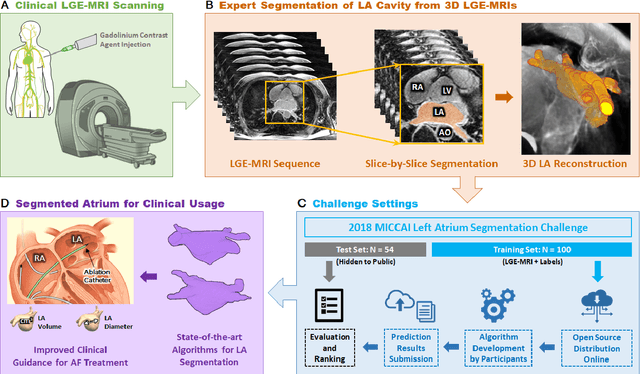
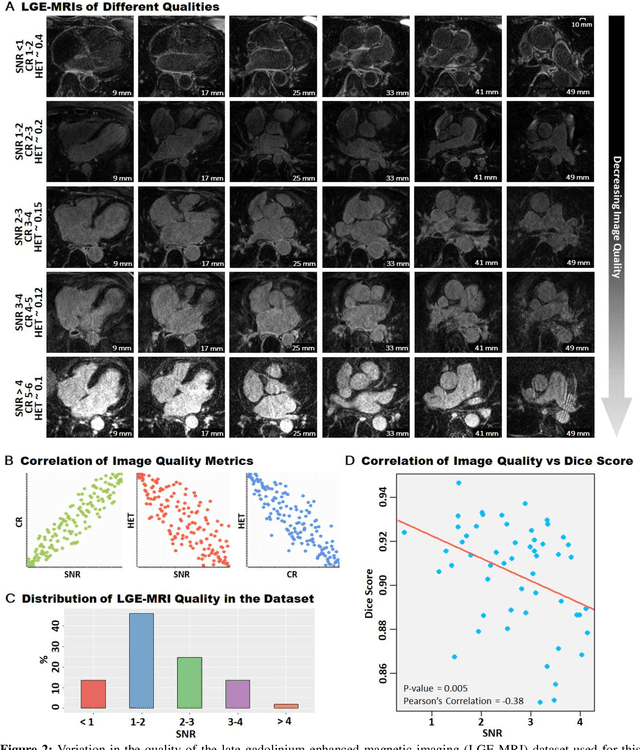
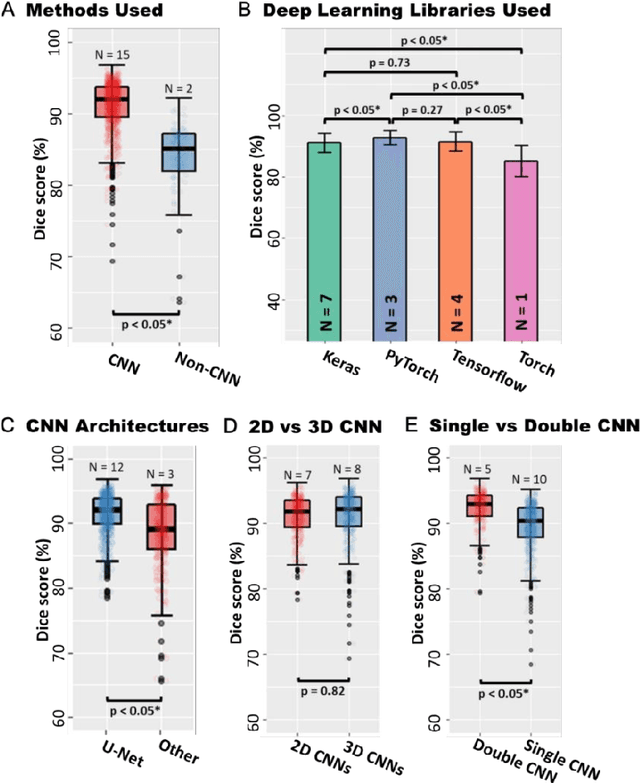
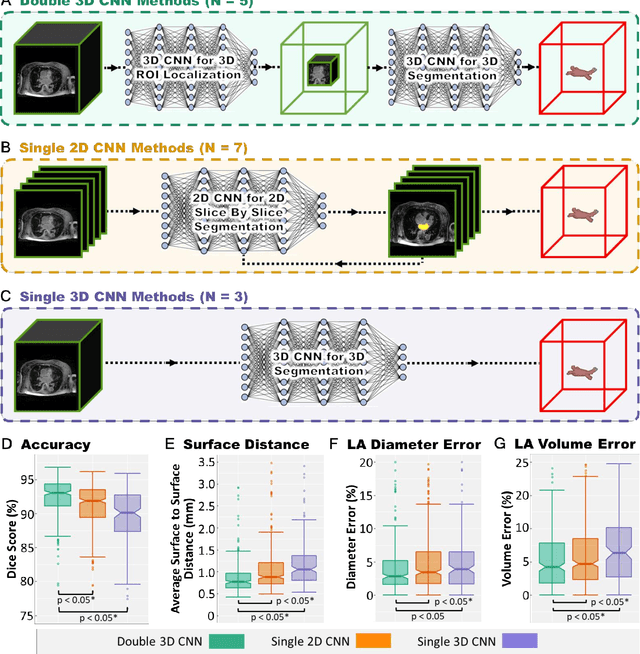
Segmentation of cardiac images, particularly late gadolinium-enhanced magnetic resonance imaging (LGE-MRI) widely used for visualizing diseased cardiac structures, is a crucial first step for clinical diagnosis and treatment. However, direct segmentation of LGE-MRIs is challenging due to its attenuated contrast. Since most clinical studies have relied on manual and labor-intensive approaches, automatic methods are of high interest, particularly optimized machine learning approaches. To address this, we organized the "2018 Left Atrium Segmentation Challenge" using 154 3D LGE-MRIs, currently the world's largest cardiac LGE-MRI dataset, and associated labels of the left atrium segmented by three medical experts, ultimately attracting the participation of 27 international teams. In this paper, extensive analysis of the submitted algorithms using technical and biological metrics was performed by undergoing subgroup analysis and conducting hyper-parameter analysis, offering an overall picture of the major design choices of convolutional neural networks (CNNs) and practical considerations for achieving state-of-the-art left atrium segmentation. Results show the top method achieved a dice score of 93.2% and a mean surface to a surface distance of 0.7 mm, significantly outperforming prior state-of-the-art. Particularly, our analysis demonstrated that double, sequentially used CNNs, in which a first CNN is used for automatic region-of-interest localization and a subsequent CNN is used for refined regional segmentation, achieved far superior results than traditional methods and pipelines containing single CNNs. This large-scale benchmarking study makes a significant step towards much-improved segmentation methods for cardiac LGE-MRIs, and will serve as an important benchmark for evaluating and comparing the future works in the field.
Mutual information neural estimation in CNN-based end-to-end medical image registration
Aug 23, 2019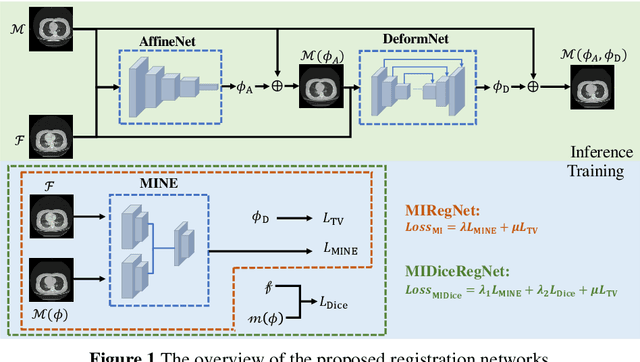
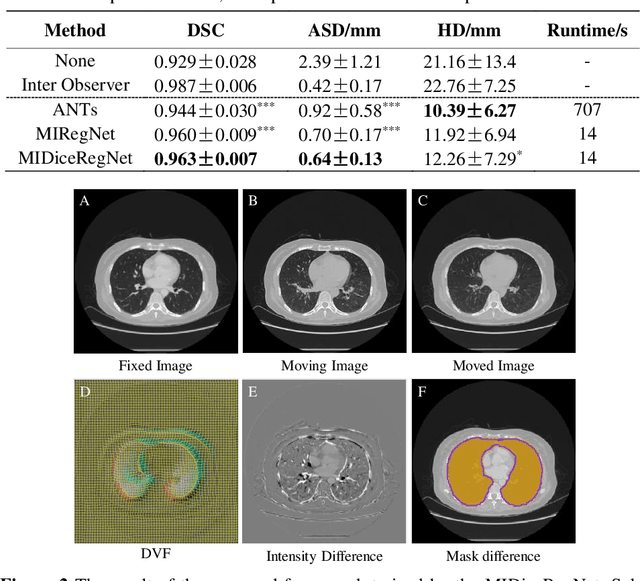
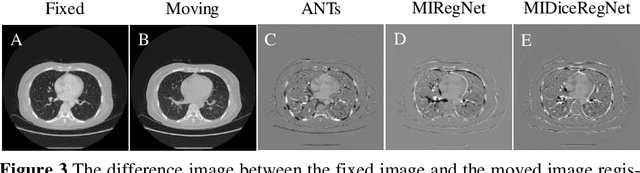
Image registration is one of the most underlined processes in medical image analysis. Recently, convolutional neural networks (CNNs) have shown significant potential in both affine and deformable registration. However, the lack of voxel-wise ground truth challenges the training of an accurate CNN-based registration. In this work, we implement a CNN-based mutual information neural estimator for image registration that evaluates the registration outputs in an unsupervised manner. Based on the estimator, we propose an end-to-end registration framework, denoted as MIRegNet, to realize one-shot affine and deformable registration. Furthermore, we propose a weakly supervised network combining mutual information with the Dice similarity coefficients (DSC) loss. We employed a dataset consisting of 190 pairs of 3D pulmonary CT images for validation. Results showed that the MIRegNet obtained an average Dice score of 0.960 for registering the pulmonary images, and the Dice score was further improved to 0.963 when the DSC was included for a weakly supervised learning of image registration.
Cardiac Segmentation from LGE MRI Using Deep Neural Network Incorporating Shape and Spatial Priors
Jun 25, 2019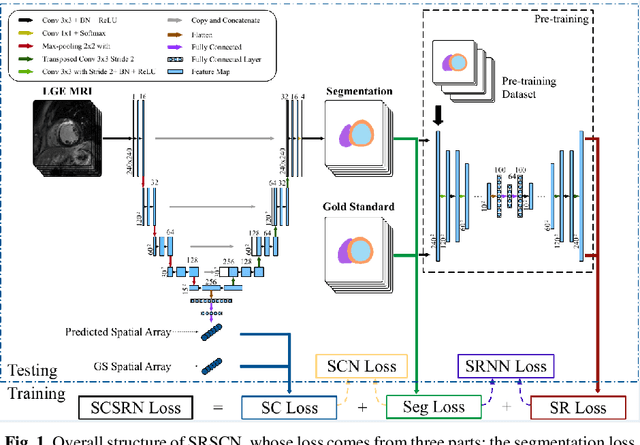
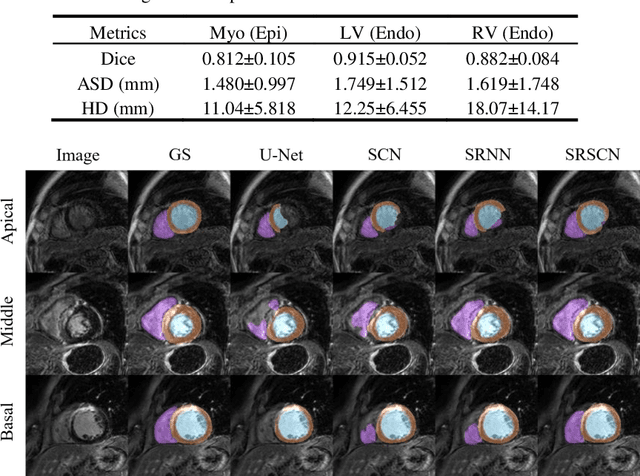
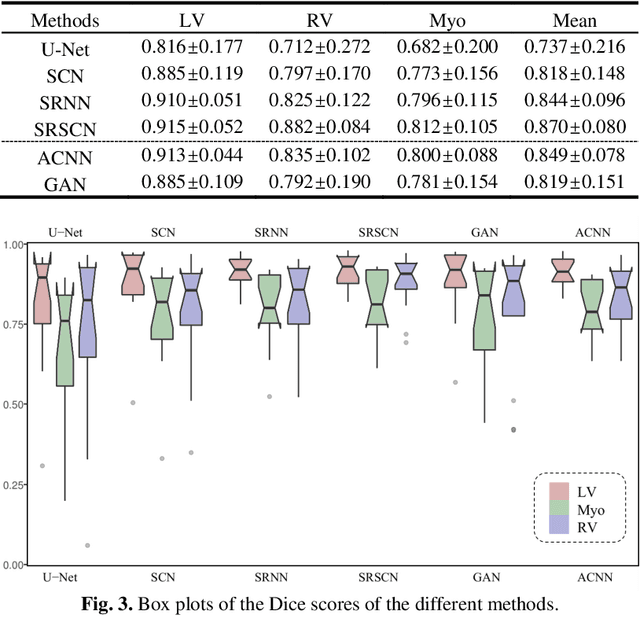
Cardiac segmentation from late gadolinium enhancement MRI is an important task in clinics to identify and evaluate the infarction of myocardium. The automatic segmentation is however still challenging, due to the heterogeneous intensity distributions and indistinct boundaries in the images. In this paper, we propose a new method, based on deep neural networks (DNN), for fully automatic segmentation. The proposed network, referred to as SRSCN, comprises a shape reconstruction neural network (SRNN) and a spatial constraint network (SCN). SRNN aims to maintain a realistic shape of the resulting segmentation. It can be pre-trained by a set of label images, and then be embedded into a unified loss function as a regularization term. Hence, no manually designed feature is needed. Furthermore, SCN incorporates the spatial information of the 2D slices. It is formulated and trained with the segmentation network via the multi-task learning strategy. We evaluated the proposed method using 45 patients and compared with two state-of-the-art regularization schemes, i.e., the anatomically constraint neural network and the adversarial neural network. The results show that the proposed SRSCN outperformed the conventional schemes, and obtained a Dice score of 0.758(std=0.227) for myocardial segmentation, which compares with 0.757(std=0.083) from the inter-observer variations.
Multi-scale deep neural networks for real image super-resolution
Apr 24, 2019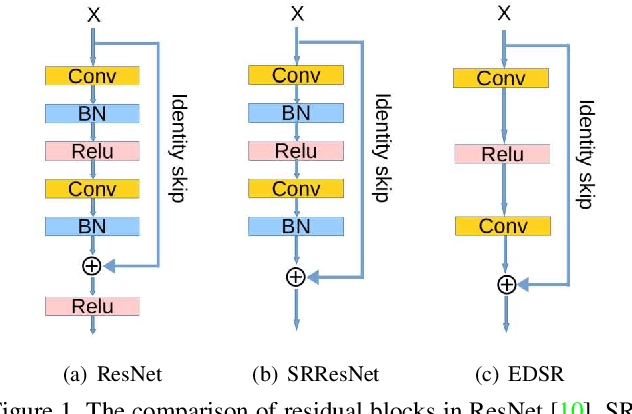

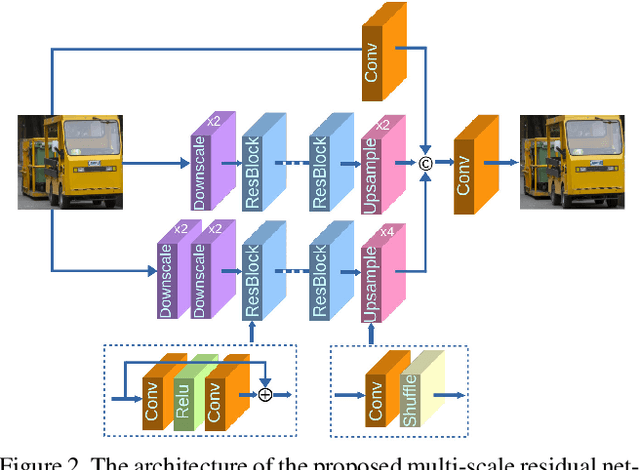

Single image super-resolution (SR) is extremely difficult if the upscaling factors of image pairs are unknown and different from each other, which is common in real image SR. To tackle the difficulty, we develop two multi-scale deep neural networks (MsDNN) in this work. Firstly, due to the high computation complexity in high-resolution spaces, we process an input image mainly in two different downscaling spaces, which could greatly lower the usage of GPU memory. Then, to reconstruct the details of an image, we design a multi-scale residual network (MsRN) in the downscaling spaces based on the residual blocks. Besides, we propose a multi-scale dense network based on the dense blocks to compare with MsRN. Finally, our empirical experiments show the robustness of MsDNN for image SR when the upscaling factor is unknown. According to the preliminary results of NTIRE 2019 image SR challenge, our team (ZXHresearch@fudan) ranks 21-st among all participants. The implementation of MsDNN is released https://github.com/shangqigao/gsq-image-SR
A Fully-Automatic Framework for Parkinson's Disease Diagnosis by Multi-Modality Images
Feb 26, 2019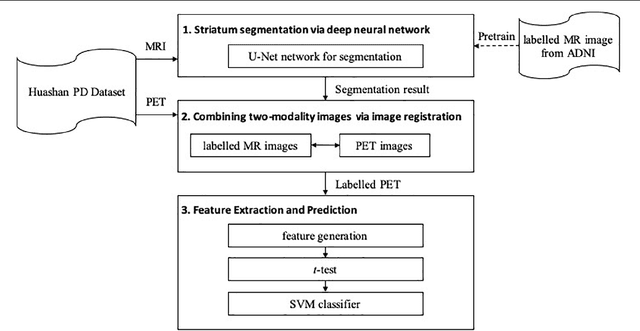
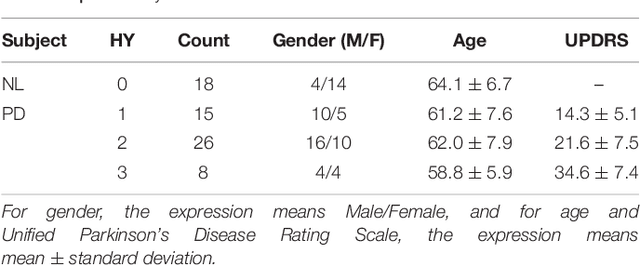
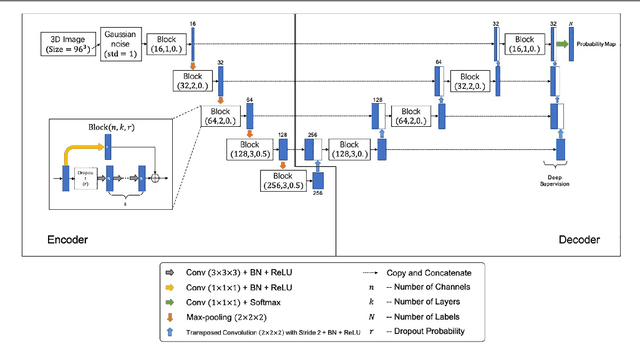
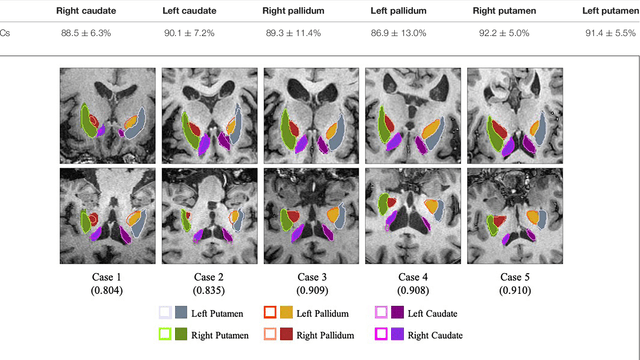
Background: Parkinson's disease (PD) is a prevalent long-term neurodegenerative disease. Though the diagnostic criteria of PD are relatively well defined, the current medical imaging diagnostic procedures are expertise-demanding, and thus call for a higher-integrated AI-based diagnostic algorithm. Methods: In this paper, we proposed an automatic, end-to-end, multi-modality diagnosis framework, including segmentation, registration, feature generation and machine learning, to process the information of the striatum for the diagnosis of PD. Multiple modalities, including T1- weighted MRI and 11C-CFT PET, were used in the proposed framework. The reliability of this framework was then validated on a dataset from the PET center of Huashan Hospital, as the dataset contains paired T1-MRI and CFT-PET images of 18 Normal (NL) subjects and 49 PD subjects. Results: We obtained an accuracy of 100% for the PD/NL classification task, besides, we conducted several comparative experiments to validate the diagnosis ability of our framework. Conclusion: Through experiment we illustrate that (1) automatic segmentation has the same classification effect as the manual segmentation, (2) the multi-modality images generates a better prediction than single modality images, and (3) volume feature is shown to be irrelevant to PD diagnosis.