 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformed Machine Learning with Knowledge Landmarks
Mar 31, 2026Informed Machine Learning has emerged as a viable generalization of Machine Learning (ML) by building a unified conceptual and algorithmic setting for constructing models on a unified basis of knowledge and data. Physics-informed ML involving physics equations is one of the developments within Informed Machine Learning. This study proposes a novel direction of Knowledge-Data ML, referred to as KD-ML, where numeric data are integrated with knowledge tidbits expressed in the form of granular knowledge landmarks. We advocate that data and knowledge are complementary in several fundamental ways: data are precise (numeric) and local, usually confined to some region of the input space, while knowledge is global and formulated at a higher level of abstraction. The knowledge can be represented as information granules and organized as a collection of input-output information granules called knowledge landmarks. In virtue of this evident complementarity, we develop a comprehensive design process of the KD-ML model and formulate an original augmented loss function L, which additively embraces the component responsible for optimizing the model based on available numeric data, while the second component, playing the role of a granular regularizer, so that it adheres to the granular constraints (knowledge landmarks). We show the role of the hyperparameter positioned in the loss function, which balances the contribution and guiding role of data and knowledge, and point to some essential tendencies associated with the quality of data (noise level) and the level of granularity of the knowledge landmarks. Experiments on two physics-governed benchmarks demonstrate that the proposed KD model consistently outperforms data-driven ML models.
Margin-aware Fuzzy Rough Feature Selection: Bridging Uncertainty Characterization and Pattern Classification
May 21, 2025Fuzzy rough feature selection (FRFS) is an effective means of addressing the curse of dimensionality in high-dimensional data. By removing redundant and irrelevant features, FRFS helps mitigate classifier overfitting, enhance generalization performance, and lessen computational overhead. However, most existing FRFS algorithms primarily focus on reducing uncertainty in pattern classification, neglecting that lower uncertainty does not necessarily result in improved classification performance, despite it commonly being regarded as a key indicator of feature selection effectiveness in the FRFS literature. To bridge uncertainty characterization and pattern classification, we propose a Margin-aware Fuzzy Rough Feature Selection (MAFRFS) framework that considers both the compactness and separation of label classes. MAFRFS effectively reduces uncertainty in pattern classification tasks, while guiding the feature selection towards more separable and discriminative label class structures. Extensive experiments on 15 public datasets demonstrate that MAFRFS is highly scalable and more effective than FRFS. The algorithms developed using MAFRFS outperform six state-of-the-art feature selection algorithms.
Rethinking Label-specific Features for Label Distribution Learning
Apr 27, 2025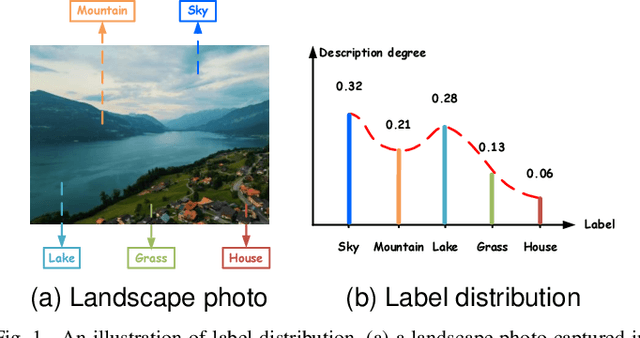
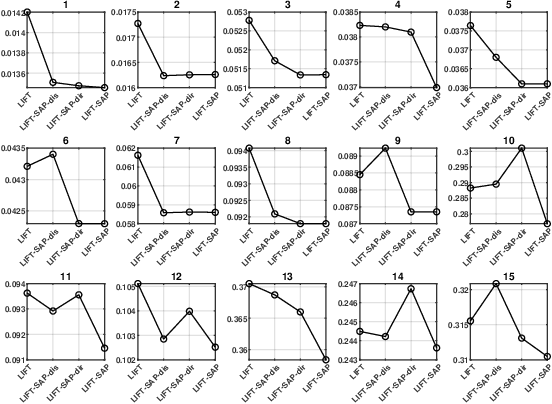
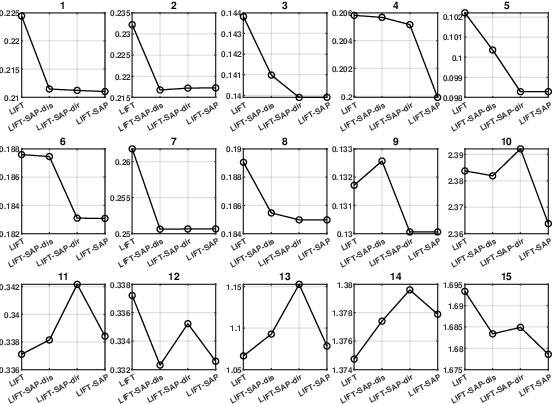
Label distribution learning (LDL) is an emerging learning paradigm designed to capture the relative importance of labels for each instance. Label-specific features (LSFs), constructed by LIFT, have proven effective for learning tasks with label ambiguity by leveraging clustering-based prototypes for each label to re-characterize instances. However, directly introducing LIFT into LDL tasks can be suboptimal, as the prototypes it collects primarily reflect intra-cluster relationships while neglecting interactions among distinct clusters. Additionally, constructing LSFs using multi-perspective information, rather than relying solely on Euclidean distance, provides a more robust and comprehensive representation of instances, mitigating noise and bias that may arise from a single distance perspective. To address these limitations, we introduce Structural Anchor Points (SAPs) to capture inter-cluster interactions. This leads to a novel LSFs construction strategy, LIFT-SAP, which enhances LIFT by integrating both distance and direction information of each instance relative to SAPs. Furthermore, we propose a novel LDL algorithm, Label Distribution Learning via Label-specifIc FeaTure with SAPs (LDL-LIFT-SAP), which unifies multiple label description degrees predicted from different LSF spaces into a cohesive label distribution. Extensive experiments on 15 real-world datasets demonstrate the effectiveness of LIFT-SAP over LIFT, as well as the superiority of LDL-LIFT-SAP compared to seven other well-established algorithms.