 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer Embedding Deep Fusion Graph Neural Network
Apr 25, 2026Graph Neural Networks (GNNs) have demonstrated impressive performance in learning representations from graph-structured data. However, their message-passing mechanism inherently relies on the assumption of label consistency among connected nodes, limiting their applicability to low-homophily settings. Moreover, since message passing operates as a hierarchical diffusion process, GNNs face challenges in capturing long-range dependencies. As network depth increases, the structural noise along heterophilic edges tends to be amplified, resulting in over-smoothing. This issue becomes especially prominent in highly heterophilic graphs, where the propagation of inconsistent semantics across the topology continually exacerbates misaggregation. To address this issue, we propose a novel framework named Layer Embedding Deep Fusion Graph Neural Network (LEDF-GNN). Specifically, we design a Layer Embedding Deep Fusion (LEDF) operator that nonlinearly fuses multi-layer embeddings to capture inter-layer dependencies and effectively alleviate deep propagation degradation. Meanwhile, to mitigate structural heterophily, LEDF-GNN employs a Dual-Topology Parallel Strategy (DTPS) that simultaneously leverages the original and reconstructed topologies, allowing for adaptive structure-semantics co-optimization under diverse homophily conditions. Extensive semi-supervised classification experiments on the citation and image benchmarks demonstrate that, under both homophilic and heterophilic settings, LEDF-GNN consistently outperforms state-of-the-art baselines, validating its effectiveness and generalization capability across diverse graph types.
Margin-aware Fuzzy Rough Feature Selection: Bridging Uncertainty Characterization and Pattern Classification
May 21, 2025Fuzzy rough feature selection (FRFS) is an effective means of addressing the curse of dimensionality in high-dimensional data. By removing redundant and irrelevant features, FRFS helps mitigate classifier overfitting, enhance generalization performance, and lessen computational overhead. However, most existing FRFS algorithms primarily focus on reducing uncertainty in pattern classification, neglecting that lower uncertainty does not necessarily result in improved classification performance, despite it commonly being regarded as a key indicator of feature selection effectiveness in the FRFS literature. To bridge uncertainty characterization and pattern classification, we propose a Margin-aware Fuzzy Rough Feature Selection (MAFRFS) framework that considers both the compactness and separation of label classes. MAFRFS effectively reduces uncertainty in pattern classification tasks, while guiding the feature selection towards more separable and discriminative label class structures. Extensive experiments on 15 public datasets demonstrate that MAFRFS is highly scalable and more effective than FRFS. The algorithms developed using MAFRFS outperform six state-of-the-art feature selection algorithms.
Rethinking Label-specific Features for Label Distribution Learning
Apr 27, 2025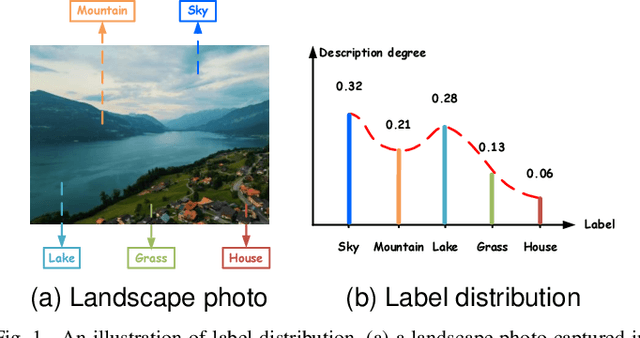
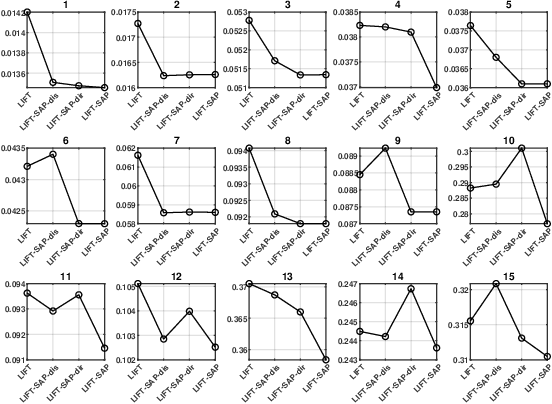
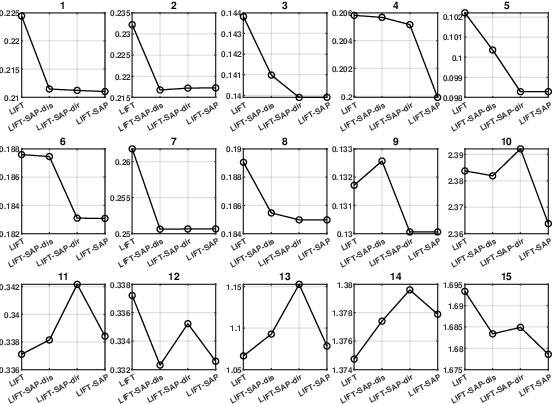
Label distribution learning (LDL) is an emerging learning paradigm designed to capture the relative importance of labels for each instance. Label-specific features (LSFs), constructed by LIFT, have proven effective for learning tasks with label ambiguity by leveraging clustering-based prototypes for each label to re-characterize instances. However, directly introducing LIFT into LDL tasks can be suboptimal, as the prototypes it collects primarily reflect intra-cluster relationships while neglecting interactions among distinct clusters. Additionally, constructing LSFs using multi-perspective information, rather than relying solely on Euclidean distance, provides a more robust and comprehensive representation of instances, mitigating noise and bias that may arise from a single distance perspective. To address these limitations, we introduce Structural Anchor Points (SAPs) to capture inter-cluster interactions. This leads to a novel LSFs construction strategy, LIFT-SAP, which enhances LIFT by integrating both distance and direction information of each instance relative to SAPs. Furthermore, we propose a novel LDL algorithm, Label Distribution Learning via Label-specifIc FeaTure with SAPs (LDL-LIFT-SAP), which unifies multiple label description degrees predicted from different LSF spaces into a cohesive label distribution. Extensive experiments on 15 real-world datasets demonstrate the effectiveness of LIFT-SAP over LIFT, as well as the superiority of LDL-LIFT-SAP compared to seven other well-established algorithms.