 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCID-Ref: A 3D Robotic Dataset with Embodied Language for Clutter Scene Grounding
Mar 13, 2021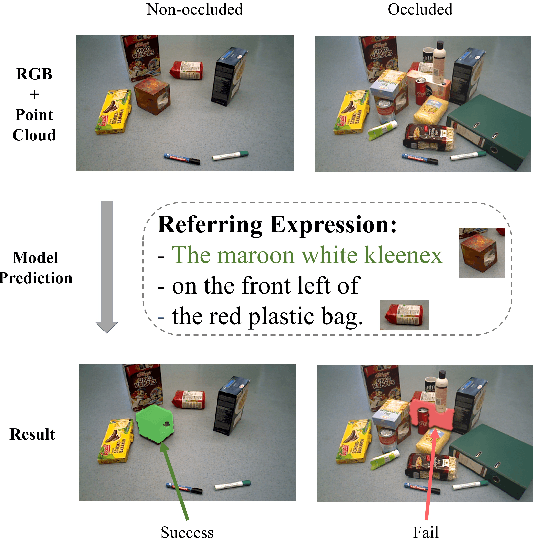

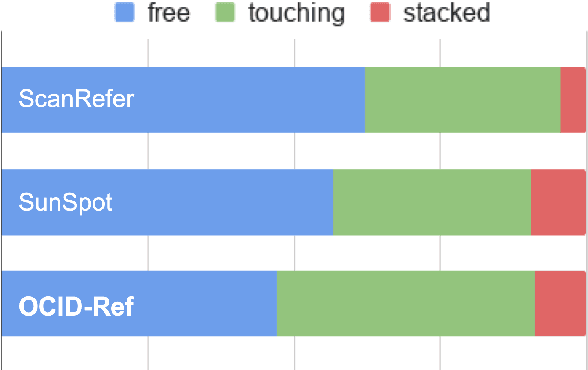

To effectively apply robots in working environments and assist humans, it is essential to develop and evaluate how visual grounding (VG) can affect machine performance on occluded objects. However, current VG works are limited in working environments, such as offices and warehouses, where objects are usually occluded due to space utilization issues. In our work, we propose a novel OCID-Ref dataset featuring a referring expression segmentation task with referring expressions of occluded objects. OCID-Ref consists of 305,694 referring expressions from 2,300 scenes with providing RGB image and point cloud inputs. To resolve challenging occlusion issues, we argue that it's crucial to take advantage of both 2D and 3D signals to resolve challenging occlusion issues. Our experimental results demonstrate the effectiveness of aggregating 2D and 3D signals but referring to occluded objects still remains challenging for the modern visual grounding systems. OCID-Ref is publicly available at https://github.com/lluma/OCID-Ref
Situation and Behavior Understanding by Trope Detection on Films
Jan 19, 2021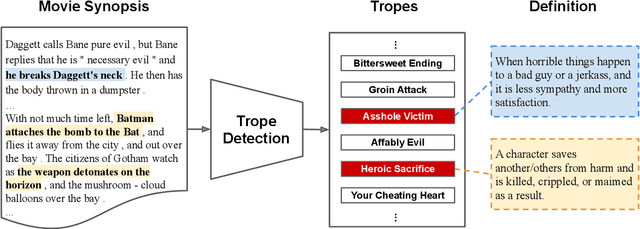
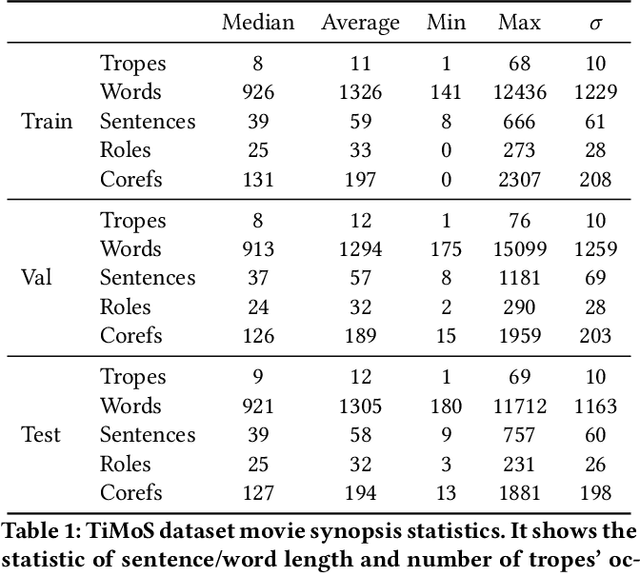
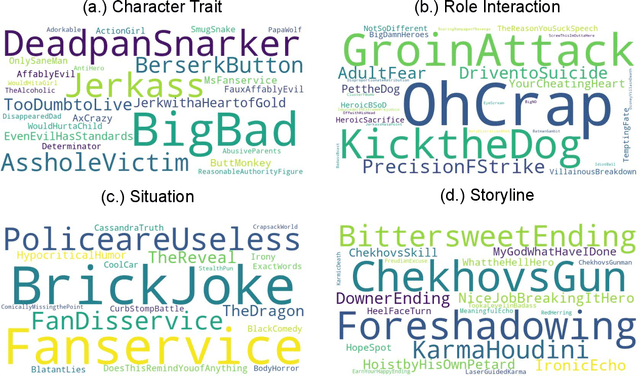
The human ability of deep cognitive skills are crucial for the development of various real-world applications that process diverse and abundant user generated input. While recent progress of deep learning and natural language processing have enabled learning system to reach human performance on some benchmarks requiring shallow semantics, such human ability still remains challenging for even modern contextual embedding models, as pointed out by many recent studies. Existing machine comprehension datasets assume sentence-level input, lack of casual or motivational inferences, or could be answered with question-answer bias. Here, we present a challenging novel task, trope detection on films, in an effort to create a situation and behavior understanding for machines. Tropes are storytelling devices that are frequently used as ingredients in recipes for creative works. Comparing to existing movie tag prediction tasks, tropes are more sophisticated as they can vary widely, from a moral concept to a series of circumstances, and embedded with motivations and cause-and-effects. We introduce a new dataset, Tropes in Movie Synopses (TiMoS), with 5623 movie synopses and 95 different tropes collecting from a Wikipedia-style database, TVTropes. We present a multi-stream comprehension network (MulCom) leveraging multi-level attention of words, sentences, and role relations. Experimental result demonstrates that modern models including BERT contextual embedding, movie tag prediction systems, and relational networks, perform at most 37% of human performance (23.97/64.87) in terms of F1 score. Our MulCom outperforms all modern baselines, by 1.5 to 5.0 F1 score and 1.5 to 3.0 mean of average precision (mAP) score. We also provide a detailed analysis and human evaluation to pave ways for future research.
End-to-End Video Question-Answer Generation with Generator-Pretester Network
Jan 05, 2021

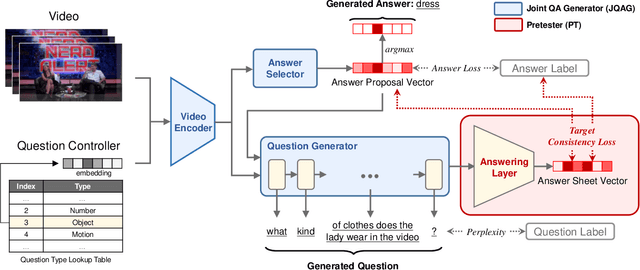

We study a novel task, Video Question-Answer Generation (VQAG), for challenging Video Question Answering (Video QA) task in multimedia. Due to expensive data annotation costs, many widely used, large-scale Video QA datasets such as Video-QA, MSVD-QA and MSRVTT-QA are automatically annotated using Caption Question Generation (CapQG) which inputs captions instead of the video itself. As captions neither fully represent a video, nor are they always practically available, it is crucial to generate question-answer pairs based on a video via Video Question-Answer Generation (VQAG). Existing video-to-text (V2T) approaches, despite taking a video as the input, only generate a question alone. In this work, we propose a novel model Generator-Pretester Network that focuses on two components: (1) The Joint Question-Answer Generator (JQAG) which generates a question with its corresponding answer to allow Video Question "Answering" training. (2) The Pretester (PT) verifies a generated question by trying to answer it and checks the pretested answer with both the model's proposed answer and the ground truth answer. We evaluate our system with the only two available large-scale human-annotated Video QA datasets and achieves state-of-the-art question generation performances. Furthermore, using our generated QA pairs only on the Video QA task, we can surpass some supervised baselines. We apply our generated questions to Video QA applications and surpasses some supervised baselines using generated questions only. As a pre-training strategy, we outperform both CapQG and transfer learning approaches when employing semi-supervised (20%) or fully supervised learning with annotated data. These experimental results suggest the novel perspectives for Video QA training.
xCos: An Explainable Cosine Metric for Face Verification Task
Mar 11, 2020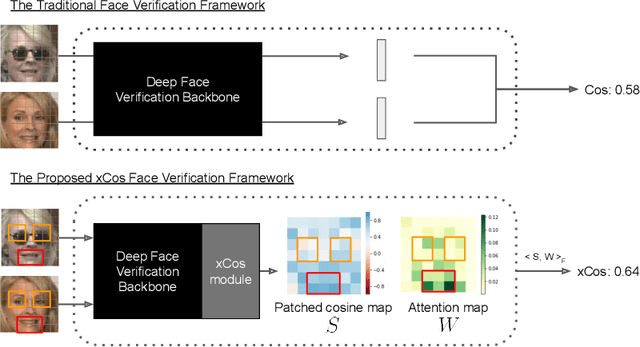
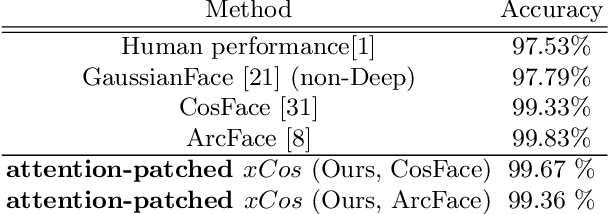
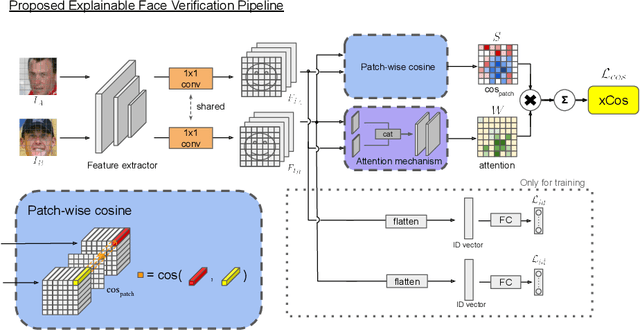
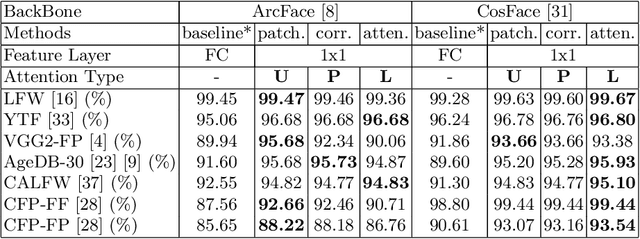
We study the XAI (explainable AI) on the face recognition task, particularly the face verification here. Face verification is a crucial task in recent days and it has been deployed to plenty of applications, such as access control, surveillance, and automatic personal log-on for mobile devices. With the increasing amount of data, deep convolutional neural networks can achieve very high accuracy for the face verification task. Beyond exceptional performances, deep face verification models need more interpretability so that we can trust the results they generate. In this paper, we propose a novel similarity metric, called explainable cosine ($xCos$), that comes with a learnable module that can be plugged into most of the verification models to provide meaningful explanations. With the help of $xCos$, we can see which parts of the 2 input faces are similar, where the model pays its attention to, and how the local similarities are weighted to form the output $xCos$ score. We demonstrate the effectiveness of our proposed method on LFW and various competitive benchmarks, resulting in not only providing novel and desiring model interpretability for face verification but also ensuring the accuracy as plugging into existing face recognition models.
Investigating the Decoders of Maximum Likelihood Sequence Models: A Look-ahead Approach
Mar 08, 2020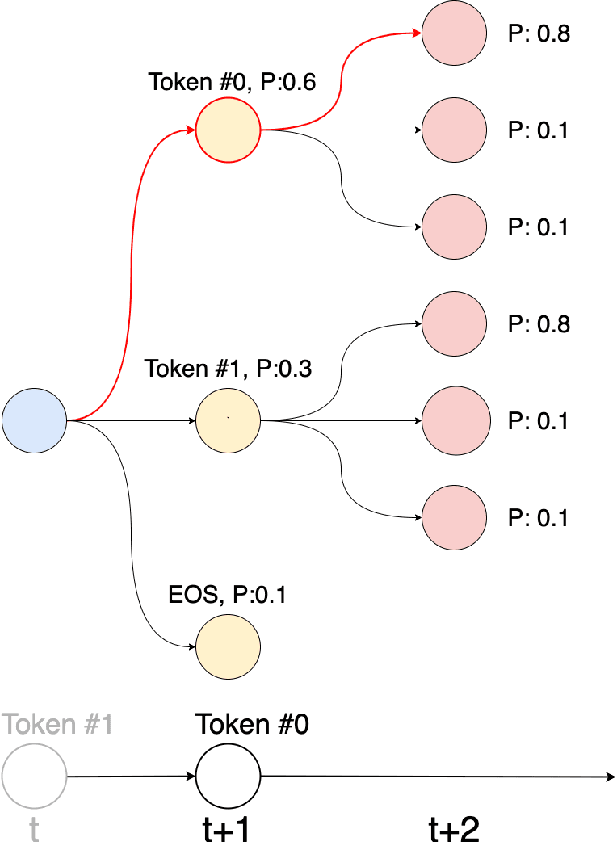



We demonstrate how we can practically incorporate multi-step future information into a decoder of maximum likelihood sequence models. We propose a "k-step look-ahead" module to consider the likelihood information of a rollout up to k steps. Unlike other approaches that need to train another value network to evaluate the rollouts, we can directly apply this look-ahead module to improve the decoding of any sequence model trained in a maximum likelihood framework. We evaluate our look-ahead module on three datasets of varying difficulties: IM2LATEX-100k OCR image to LaTeX, WMT16 multimodal machine translation, and WMT14 machine translation. Our look-ahead module improves the performance of the simpler datasets such as IM2LATEX-100k and WMT16 multimodal machine translation. However, the improvement of the more difficult dataset (e.g., containing longer sequences), WMT14 machine translation, becomes marginal. Our further investigation using the k-step look-ahead suggests that the more difficult tasks suffer from the overestimated EOS (end-of-sentence) probability. We argue that the overestimated EOS probability also causes the decreased performance of beam search when increasing its beam width. We tackle the EOS problem by integrating an auxiliary EOS loss into the training to estimate if the model should emit EOS or other words. Our experiments show that improving EOS estimation not only increases the performance of our proposed look-ahead module but also the robustness of the beam search.
Video Question Generation via Cross-Modal Self-Attention Networks Learning
Jul 05, 2019
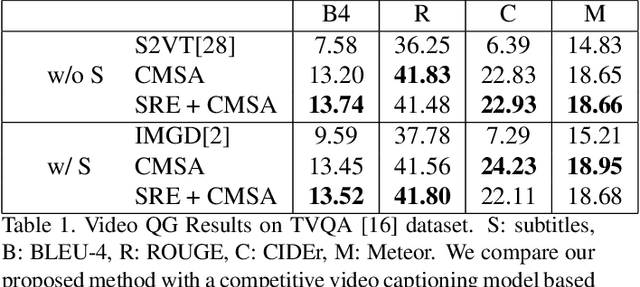
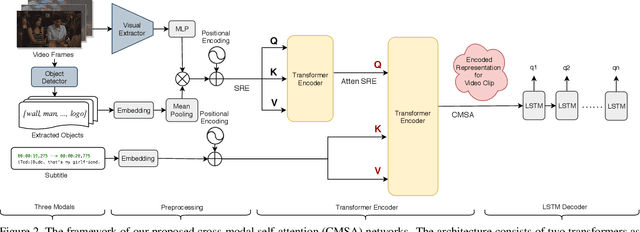
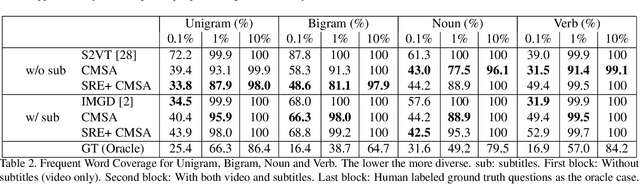
Video Question Answering (Video QA) is a critical and challenging task in multimedia comprehension. While deep learning based models are extremely capable of representing and understanding videos, these models heavily rely on massive data, which is expensive to label. In this paper, we introduce a novel task for automatically generating questions given a sequence of video frames and the corresponding subtitles from a clip of video to reduce the huge annotation cost. Learning to ask a question based on a video requires the model to comprehend the rich semantics in the scene and the interplay between the vision and the language. To address this, we propose a novel cross-modal self-attention (CMSA) network to aggregate the diverse features from video frames and subtitles. Excitingly, we demonstrate that our proposed model can improve the (strong) baseline from 0.0738 to 0.1374 in BLEU4 score -- more than 0.063 improvement (i.e., 85\% relatively). Most of all, We arguably pave a novel path toward solving the challenging Video QA task and provide detailed analysis which ushers the avenues for future investigations.
Adversarial Attacks Beyond the Image Space
Sep 10, 2018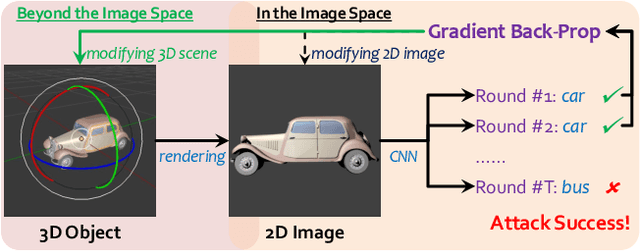



Generating adversarial examples is an intriguing problem and an important way of understanding the working mechanism of deep neural networks. Most existing approaches generated perturbations in the image space, i.e., each pixel can be modified independently. However, in this paper we pay special attention to the subset of adversarial examples that are physically authentic -- those corresponding to actual changes in 3D physical properties (like surface normals, illumination condition, etc.). These adversaries arguably pose a more serious concern, as they demonstrate the possibility of causing neural network failure by small perturbations of real-world 3D objects and scenes. In the contexts of object classification and visual question answering, we augment state-of-the-art deep neural networks that receive 2D input images with a rendering module (either differentiable or not) in front, so that a 3D scene (in the physical space) is rendered into a 2D image (in the image space), and then mapped to a prediction (in the output space). The adversarial perturbations can now go beyond the image space, and have clear meanings in the 3D physical world. Through extensive experiments, we found that a vast majority of image-space adversaries cannot be explained by adjusting parameters in the physical space, i.e., they are usually physically inauthentic. But it is still possible to successfully attack beyond the image space on the physical space (such that authenticity is enforced), though this is more difficult than image-space attacks, reflected in lower success rates and heavier perturbations required.
Scene Graph Parsing as Dependency Parsing
Mar 25, 2018

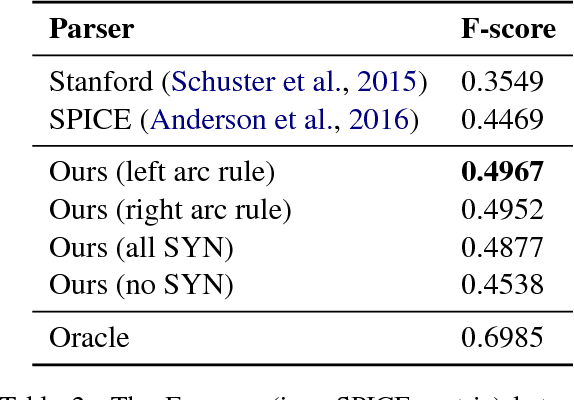
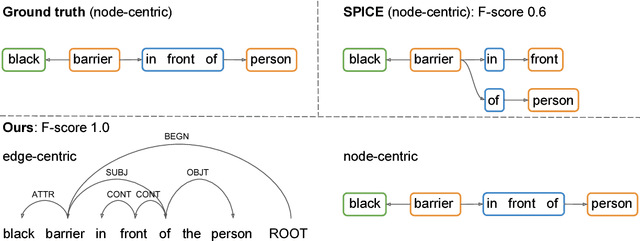
In this paper, we study the problem of parsing structured knowledge graphs from textual descriptions. In particular, we consider the scene graph representation that considers objects together with their attributes and relations: this representation has been proved useful across a variety of vision and language applications. We begin by introducing an alternative but equivalent edge-centric view of scene graphs that connect to dependency parses. Together with a careful redesign of label and action space, we combine the two-stage pipeline used in prior work (generic dependency parsing followed by simple post-processing) into one, enabling end-to-end training. The scene graphs generated by our learned neural dependency parser achieve an F-score similarity of 49.67% to ground truth graphs on our evaluation set, surpassing best previous approaches by 5%. We further demonstrate the effectiveness of our learned parser on image retrieval applications.