 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Graph: Few shot Link Prediction via Meta Learning
Dec 20, 2019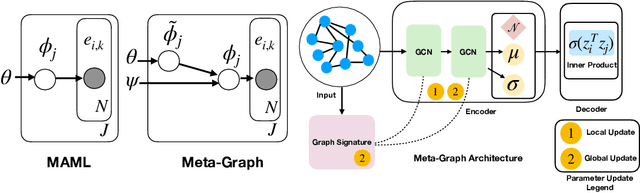
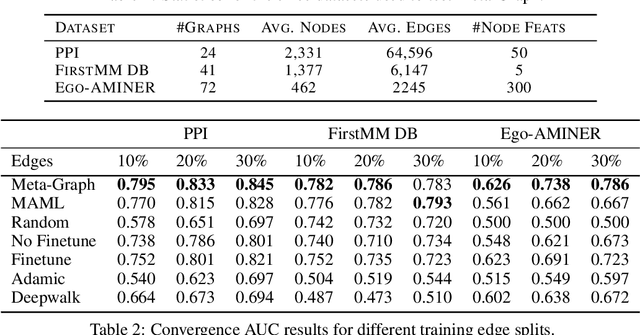
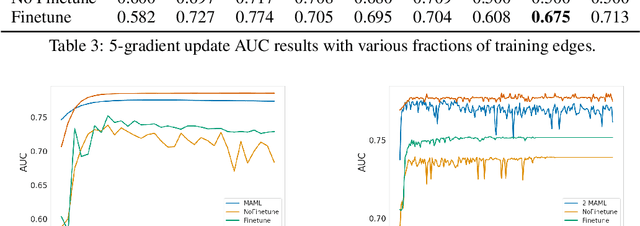
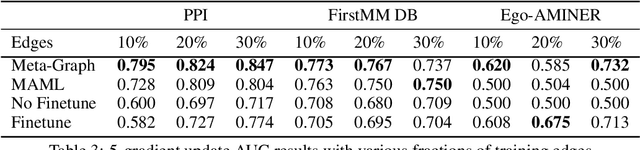
Fast adaptation to new data is one key facet of human intelligence and is an unexplored problem on graph-structured data. Few-Shot Link Prediction is a challenging task representative of real world data with evolving sub-graphs or entirely new graphs with shared structure. In this work, we present a meta-learning approach to Few Shot Link-Prediction. We further introduce Meta-Graph, a meta-learning algorithm which in addition to the global parameters learns a Graph Signature function that exploits structural information of a graph compared to other graphs from the same distribution for even faster adaptation and better convergence than vanilla Meta-Learning.
Inductive Relation Prediction on Knowledge Graphs
Nov 16, 2019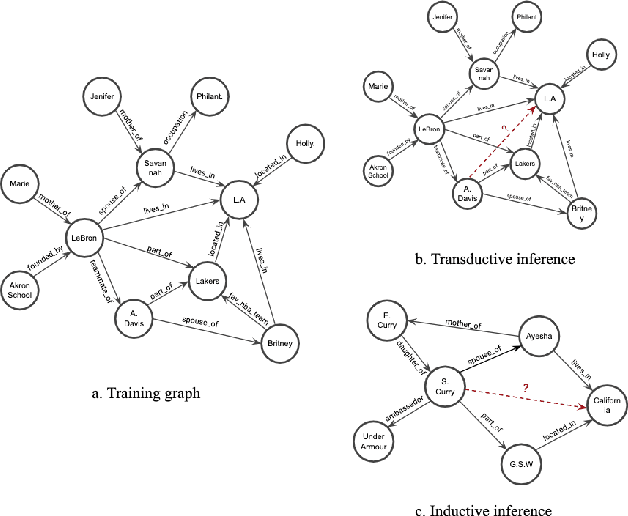

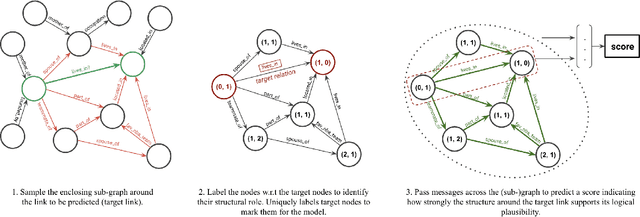

Inferring missing edges in multi-relational knowledge graphs is a fundamental task in statistical relational learning. However, previous work has largely focused on the transductive relation prediction problem, where missing edges must be predicted for a single, fixed graph. In contrast, many real-world situations require relation prediction on dynamic or previously unseen knowledge graphs (e.g., for question answering, dialogue, or e-commerce applications). Here, we develop a novel graph neural network (GNN) architecture to perform inductive relation prediction and provide a systematic comparison between this GNN approach and a strong, rule-based baseline. Our results highlight the significant difficulty of inductive relational learning, compared to the transductive case, and offer a new challenging set of inductive benchmarks for knowledge graph completion.
Efficient Graph Generation with Graph Recurrent Attention Networks
Oct 02, 2019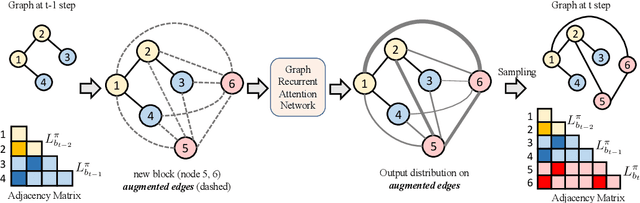
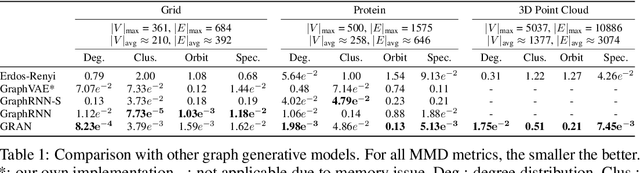
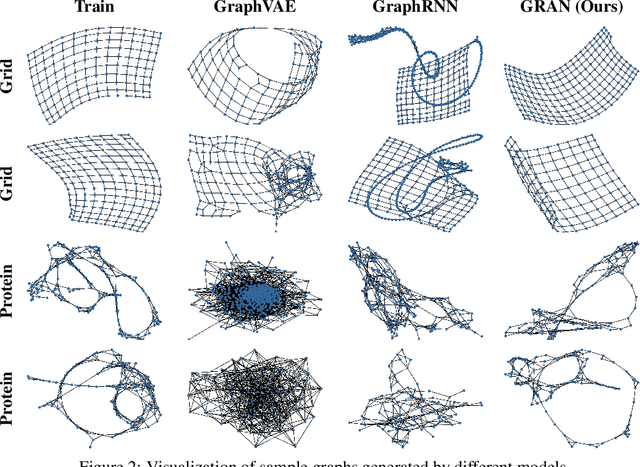
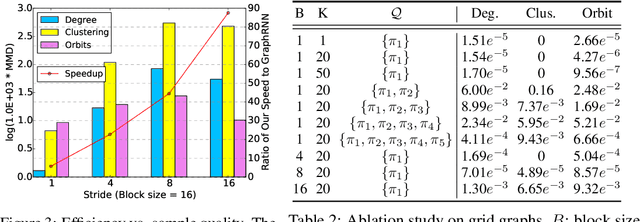
We propose a new family of efficient and expressive deep generative models of graphs, called Graph Recurrent Attention Networks (GRANs). Our model generates graphs one block of nodes and associated edges at a time. The block size and sampling stride allow us to trade off sample quality for efficiency. Compared to previous RNN-based graph generative models, our framework better captures the auto-regressive conditioning between the already-generated and to-be-generated parts of the graph using Graph Neural Networks (GNNs) with attention. This not only reduces the dependency on node ordering but also bypasses the long-term bottleneck caused by the sequential nature of RNNs. Moreover, we parameterize the output distribution per block using a mixture of Bernoulli, which captures the correlations among generated edges within the block. Finally, we propose to handle node orderings in generation by marginalizing over a family of canonical orderings. On standard benchmarks, we achieve state-of-the-art time efficiency and sample quality compared to previous models. Additionally, we show our model is capable of generating large graphs of up to 5K nodes with good quality. To the best of our knowledge, GRAN is the first deep graph generative model that can scale to this size. Our code is released at: https://github.com/lrjconan/GRAN.
CLUTRR: A Diagnostic Benchmark for Inductive Reasoning from Text
Sep 04, 2019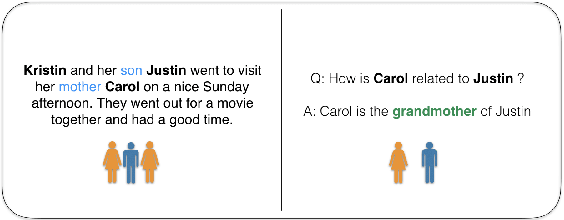
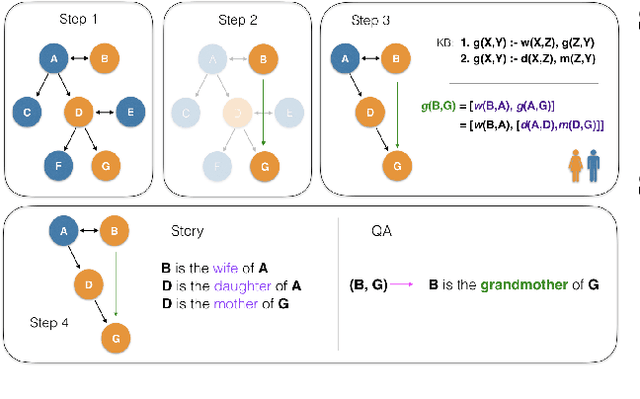
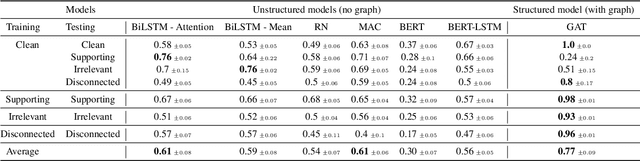
The recent success of natural language understanding (NLU) systems has been troubled by results highlighting the failure of these models to generalize in a systematic and robust way. In this work, we introduce a diagnostic benchmark suite, named CLUTRR, to clarify some key issues related to the robustness and systematicity of NLU systems. Motivated by classic work on inductive logic programming, CLUTRR requires that an NLU system infer kinship relations between characters in short stories. Successful performance on this task requires both extracting relationships between entities, as well as inferring the logical rules governing these relationships. CLUTRR allows us to precisely measure a model's ability for systematic generalization by evaluating on held-out combinations of logical rules, and it allows us to evaluate a model's robustness by adding curated noise facts. Our empirical results highlight a substantial performance gap between state-of-the-art NLU models (e.g., BERT and MAC) and a graph neural network model that works directly with symbolic inputs---with the graph-based model exhibiting both stronger generalization and greater robustness.
Neural Transfer Learning for Cry-based Diagnosis of Perinatal Asphyxia
Jul 02, 2019

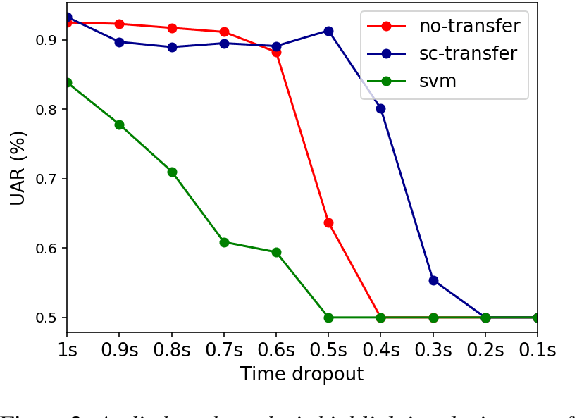
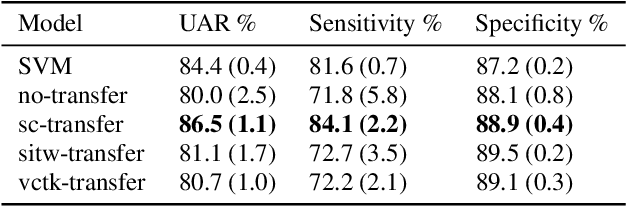
Despite continuing medical advances, the rate of newborn morbidity and mortality globally remains high, with over 6 million casualties every year. The prediction of pathologies affecting newborns based on their cry is thus of significant clinical interest, as it would facilitate the development of accessible, low-cost diagnostic tools\cut{ based on wearables and smartphones}. However, the inadequacy of clinically annotated datasets of infant cries limits progress on this task. This study explores a neural transfer learning approach to developing accurate and robust models for identifying infants that have suffered from perinatal asphyxia. In particular, we explore the hypothesis that representations learned from adult speech could inform and improve performance of models developed on infant speech. Our experiments show that models based on such representation transfer are resilient to different types and degrees of noise, as well as to signal loss in time and frequency domains.
Generalizable Adversarial Attacks Using Generative Models
Jun 12, 2019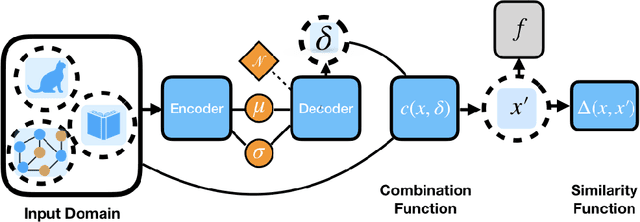



Adversarial attacks on deep neural networks traditionally rely on a constrained optimization paradigm, where an optimization procedure is used to obtain a single adversarial perturbation for a given input example. Here, we instead view adversarial attacks as a generative modelling problem, with the goal of producing entire distributions of adversarial examples given an unperturbed input. We show that this generative perspective can be used to design a unified encoder-decoder framework, which is domain-agnostic in that the same framework can be employed to attack different domains with minimal modification. Across three diverse domains---images, text, and graphs---our approach generates whitebox attacks with success rates that are competitive with or superior to existing approaches, with a new state-of-the-art achieved in the graph domain. Finally, we demonstrate that our generative framework can efficiently generate a diverse set of attacks for a single given input, and is even capable of attacking unseen test instances in a zero-shot manner, exhibiting attack generalization.
Compositional Language Understanding with Text-based Relational Reasoning
Nov 08, 2018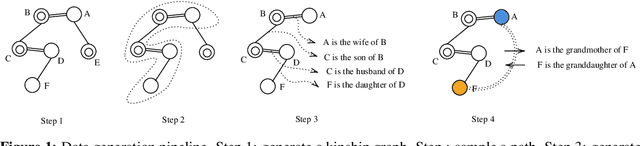

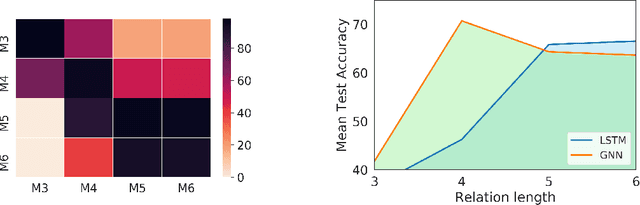

Neural networks for natural language reasoning have largely focused on extractive, fact-based question-answering (QA) and common-sense inference. However, it is also crucial to understand the extent to which neural networks can perform relational reasoning and combinatorial generalization from natural language---abilities that are often obscured by annotation artifacts and the dominance of language modeling in standard QA benchmarks. In this work, we present a novel benchmark dataset for language understanding that isolates performance on relational reasoning. We also present a neural message-passing baseline and show that this model, which incorporates a relational inductive bias, is superior at combinatorial generalization compared to a traditional recurrent neural network approach.
Hierarchical Graph Representation Learning with Differentiable Pooling
Oct 26, 2018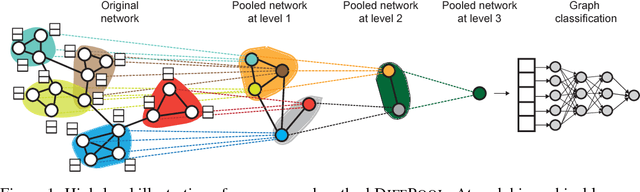
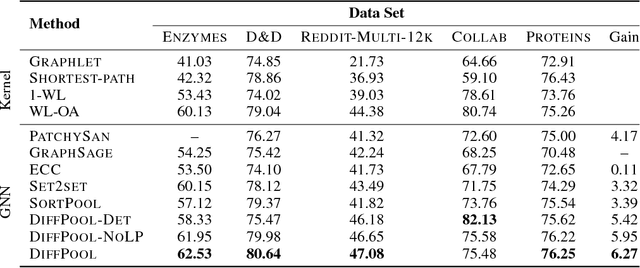

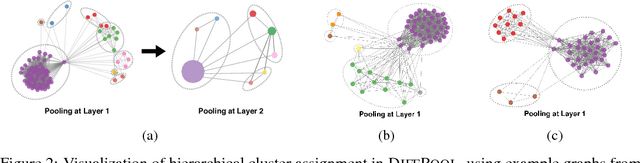
Recently, graph neural networks (GNNs) have revolutionized the field of graph representation learning through effectively learned node embeddings, and achieved state-of-the-art results in tasks such as node classification and link prediction. However, current GNN methods are inherently flat and do not learn hierarchical representations of graphs---a limitation that is especially problematic for the task of graph classification, where the goal is to predict the label associated with an entire graph. Here we propose DiffPool, a differentiable graph pooling module that can generate hierarchical representations of graphs and can be combined with various graph neural network architectures in an end-to-end fashion. DiffPool learns a differentiable soft cluster assignment for nodes at each layer of a deep GNN, mapping nodes to a set of clusters, which then form the coarsened input for the next GNN layer. Our experimental results show that combining existing GNN methods with DiffPool yields an average improvement of 5-10% accuracy on graph classification benchmarks, compared to all existing pooling approaches, achieving a new state-of-the-art on four out of five benchmark data sets.
Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change
Oct 25, 2018
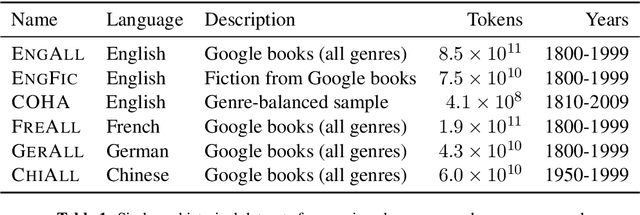

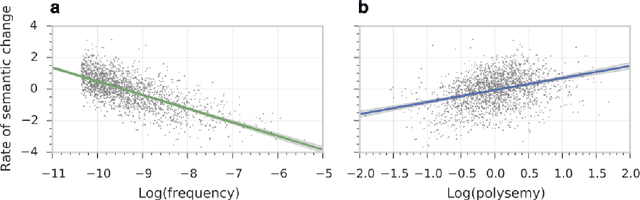
Understanding how words change their meanings over time is key to models of language and cultural evolution, but historical data on meaning is scarce, making theories hard to develop and test. Word embeddings show promise as a diachronic tool, but have not been carefully evaluated. We develop a robust methodology for quantifying semantic change by evaluating word embeddings (PPMI, SVD, word2vec) against known historical changes. We then use this methodology to reveal statistical laws of semantic evolution. Using six historical corpora spanning four languages and two centuries, we propose two quantitative laws of semantic change: (i) the law of conformity---the rate of semantic change scales with an inverse power-law of word frequency; (ii) the law of innovation---independent of frequency, words that are more polysemous have higher rates of semantic change.
Deep Graph Infomax
Sep 27, 2018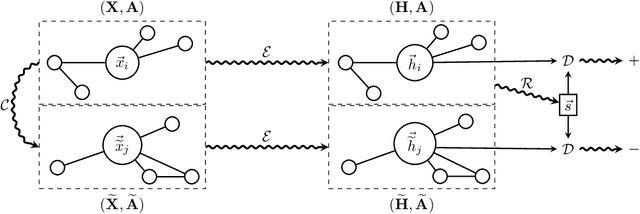
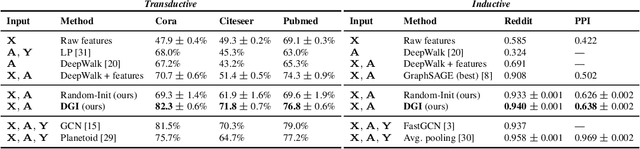
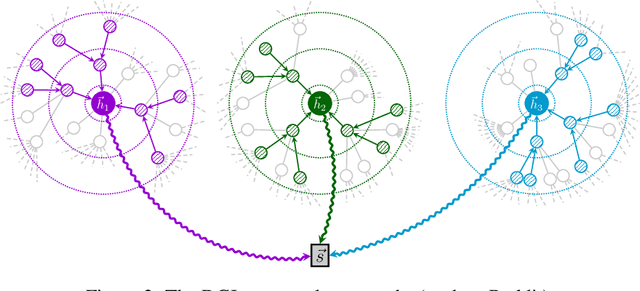

We present Deep Graph Infomax (DGI), a general approach for learning node representations within graph-structured data in an unsupervised manner. DGI relies on maximizing mutual information between patch representations and corresponding high-level summaries of graphs---both derived using established graph convolutional network architectures. The learnt patch representations summarize subgraphs centered around nodes of interest, and can thus be reused for downstream node-wise learning tasks. In contrast to most prior approaches to graph representation learning, DGI does not rely on random walks, and is readily applicable to both transductive and inductive learning setups. We demonstrate competitive performance on a variety of node classification benchmarks, which at times even exceeds the performance of supervised learning.