 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Value-Improvement Path: Towards Better Representations for Reinforcement Learning
Jun 03, 2020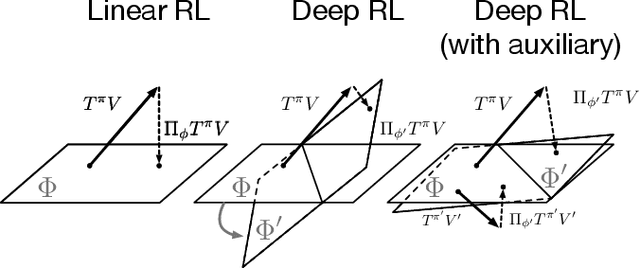

In value-based reinforcement learning (RL), unlike in supervised learning, the agent faces not a single, stationary, approximation problem, but a sequence of value prediction problems. Each time the policy improves, the nature of the problem changes, shifting both the distribution of states and their values. In this paper we take a novel perspective, arguing that the value prediction problems faced by an RL agent should not be addressed in isolation, but rather as a single, holistic, prediction problem. An RL algorithm generates a sequence of policies that, at least approximately, improve towards the optimal policy. We explicitly characterize the associated sequence of value functions and call it the value-improvement path. Our main idea is to approximate the value-improvement path holistically, rather than to solely track the value function of the current policy. Specifically, we discuss the impact that this holistic view of RL has on representation learning. We demonstrate that a representation that spans the past value-improvement path will also provide an accurate value approximation for future policy improvements. We use this insight to better understand existing approaches to auxiliary tasks and to propose new ones. To test our hypothesis empirically, we augmented a standard deep RL agent with an auxiliary task of learning the value-improvement path. In a study of Atari 2600 games, the augmented agent achieved approximately double the mean and median performance of the baseline agent.
Temporally-Extended ε-Greedy Exploration
Jun 02, 2020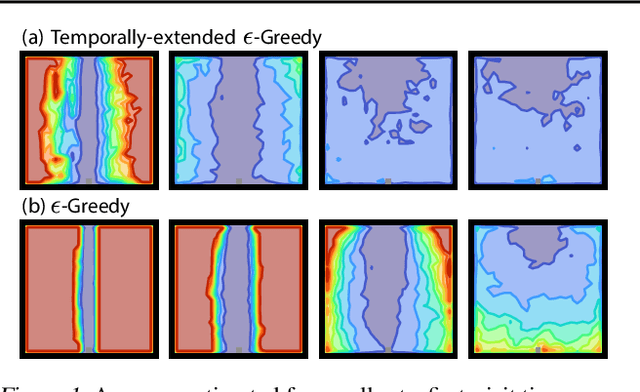
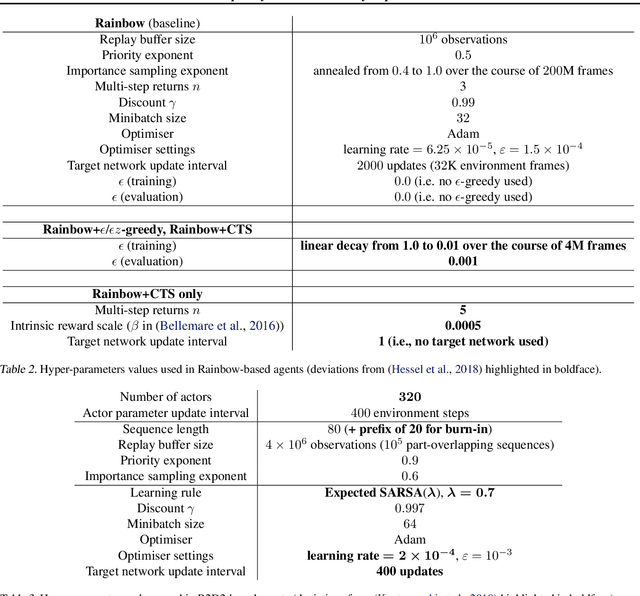
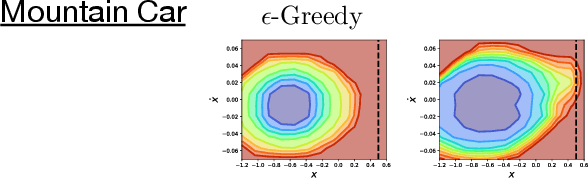
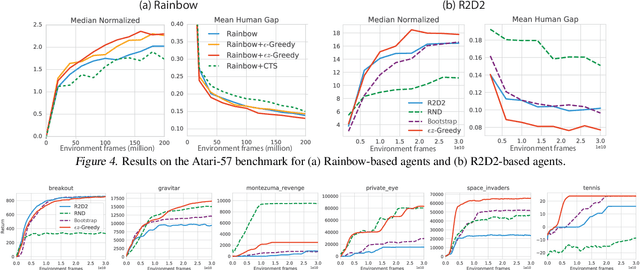
Recent work on exploration in reinforcement learning (RL) has led to a series of increasingly complex solutions to the problem. This increase in complexity often comes at the expense of generality. Recent empirical studies suggest that, when applied to a broader set of domains, some sophisticated exploration methods are outperformed by simpler counterparts, such as {\epsilon}-greedy. In this paper we propose an exploration algorithm that retains the simplicity of {\epsilon}-greedy while reducing dithering. We build on a simple hypothesis: the main limitation of {\epsilon}-greedy exploration is its lack of temporal persistence, which limits its ability to escape local optima. We propose a temporally extended form of {\epsilon}-greedy that simply repeats the sampled action for a random duration. It turns out that, for many duration distributions, this suffices to improve exploration on a large set of domains. Interestingly, a class of distributions inspired by ecological models of animal foraging behaviour yields particularly strong performance.
Adapting Behaviour for Learning Progress
Dec 14, 2019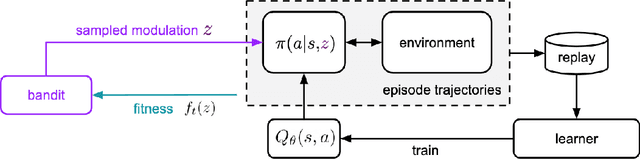

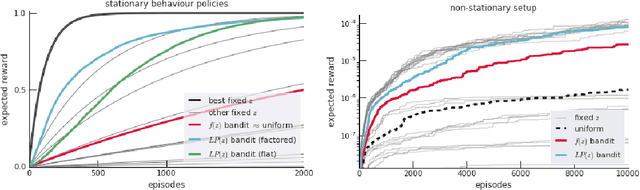
Determining what experience to generate to best facilitate learning (i.e. exploration) is one of the distinguishing features and open challenges in reinforcement learning. The advent of distributed agents that interact with parallel instances of the environment has enabled larger scales and greater flexibility, but has not removed the need to tune exploration to the task, because the ideal data for the learning algorithm necessarily depends on its process of learning. We propose to dynamically adapt the data generation by using a non-stationary multi-armed bandit to optimize a proxy of the learning progress. The data distribution is controlled by modulating multiple parameters of the policy (such as stochasticity, consistency or optimism) without significant overhead. The adaptation speed of the bandit can be increased by exploiting the factored modulation structure. We demonstrate on a suite of Atari 2600 games how this unified approach produces results comparable to per-task tuning at a fraction of the cost.
Hindsight Credit Assignment
Dec 05, 2019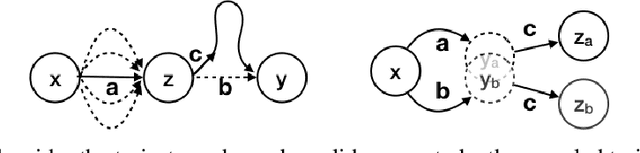

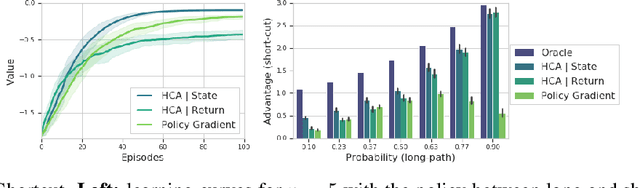
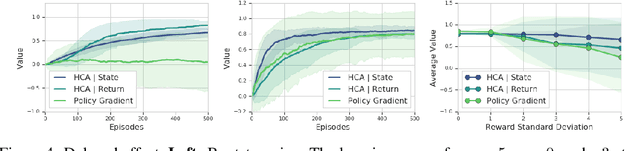
We consider the problem of efficient credit assignment in reinforcement learning. In order to efficiently and meaningfully utilize new data, we propose to explicitly assign credit to past decisions based on the likelihood of them having led to the observed outcome. This approach uses new information in hindsight, rather than employing foresight. Somewhat surprisingly, we show that value functions can be rewritten through this lens, yielding a new family of algorithms. We study the properties of these algorithms, and empirically show that they successfully address important credit assignment challenges, through a set of illustrative tasks.
Conditional Importance Sampling for Off-Policy Learning
Oct 16, 2019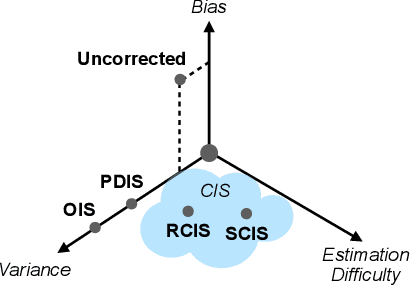

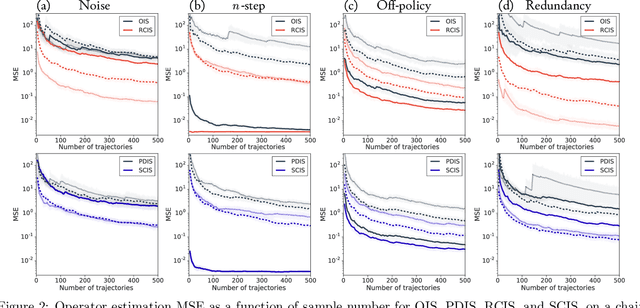
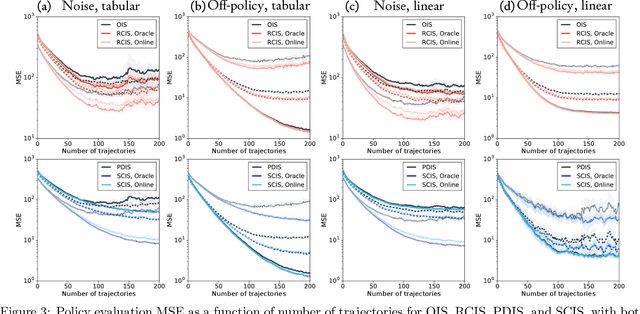
The principal contribution of this paper is a conceptual framework for off-policy reinforcement learning, based on conditional expectations of importance sampling ratios. This framework yields new perspectives and understanding of existing off-policy algorithms, and reveals a broad space of unexplored algorithms. We theoretically analyse this space, and concretely investigate several algorithms that arise from this framework.
Adaptive Trade-Offs in Off-Policy Learning
Oct 16, 2019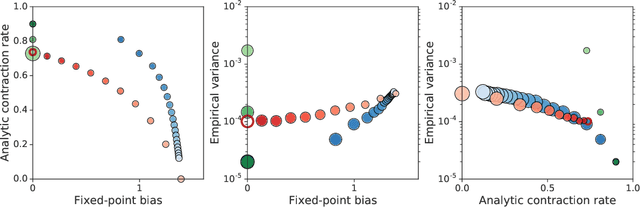

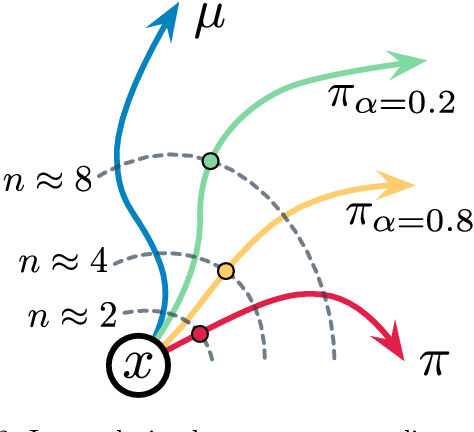
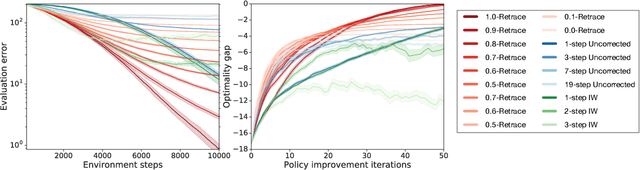
A great variety of off-policy learning algorithms exist in the literature, and new breakthroughs in this area continue to be made, improving theoretical understanding and yielding state-of-the-art reinforcement learning algorithms. In this paper, we take a unifying view of this space of algorithms, and consider their trade-offs of three fundamental quantities: update variance, fixed-point bias, and contraction rate. This leads to new perspectives of existing methods, and also naturally yields novel algorithms for off-policy evaluation and control. We develop one such algorithm, C-trace, demonstrating that it is able to more efficiently make these trade-offs than existing methods in use, and that it can be scaled to yield state-of-the-art performance in large-scale environments.
Fast Task Inference with Variational Intrinsic Successor Features
Jun 12, 2019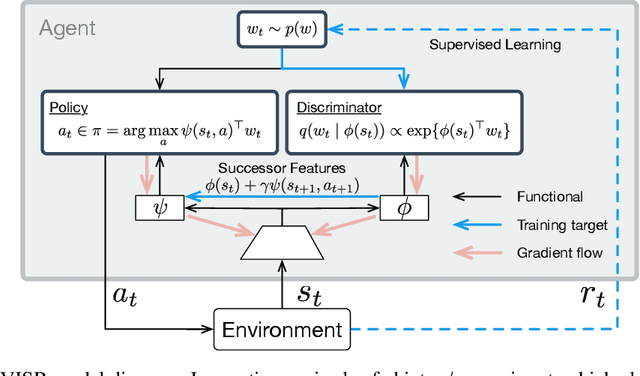
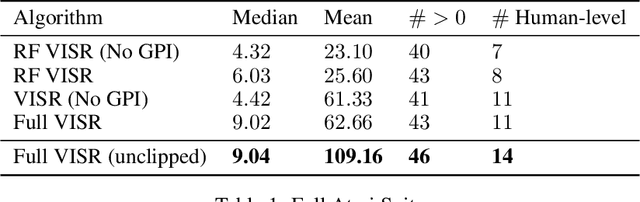
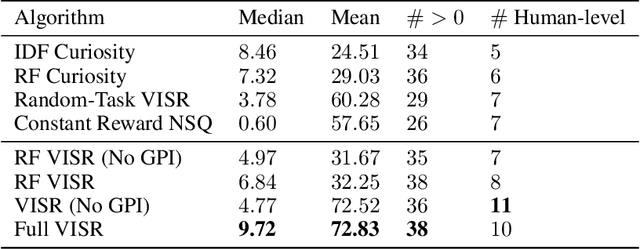
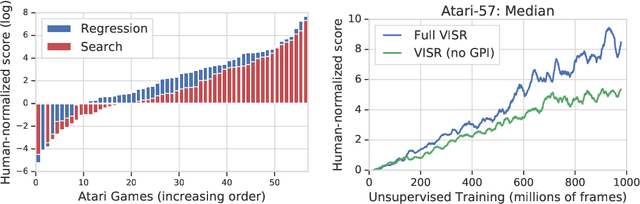
It has been established that diverse behaviors spanning the controllable subspace of an Markov decision process can be trained by rewarding a policy for being distinguishable from other policies \citep{gregor2016variational, eysenbach2018diversity, warde2018unsupervised}. However, one limitation of this formulation is generalizing behaviors beyond the finite set being explicitly learned, as is needed for use on subsequent tasks. Successor features \citep{dayan93improving, barreto2017successor} provide an appealing solution to this generalization problem, but require defining the reward function as linear in some grounded feature space. In this paper, we show that these two techniques can be combined, and that each method solves the other's primary limitation. To do so we introduce Variational Intrinsic Successor FeatuRes (VISR), a novel algorithm which learns controllable features that can be leveraged to provide enhanced generalization and fast task inference through the successor feature framework. We empirically validate VISR on the full Atari suite, in a novel setup wherein the rewards are only exposed briefly after a long unsupervised phase. Achieving human-level performance on 14 games and beating all baselines, we believe VISR represents a step towards agents that rapidly learn from limited feedback.
The Termination Critic
Feb 26, 2019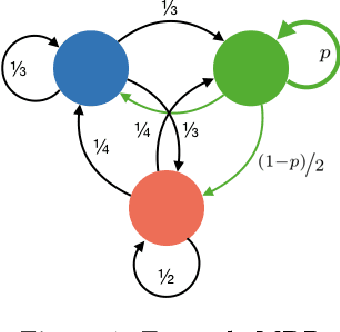
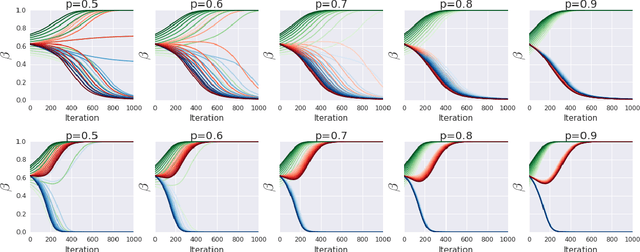
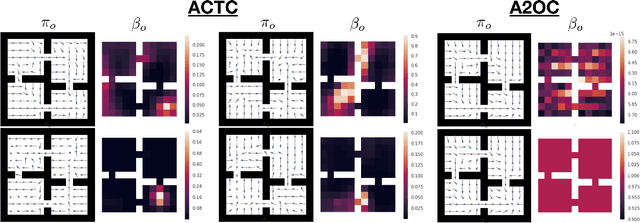
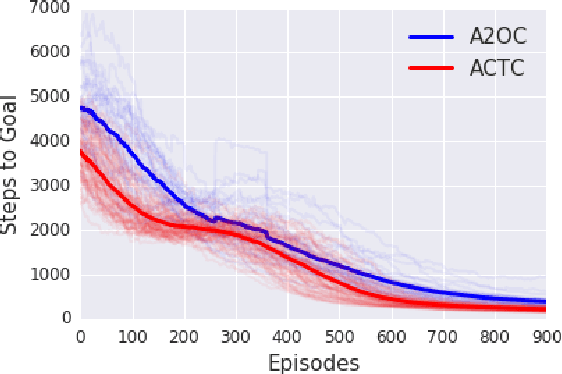
In this work, we consider the problem of autonomously discovering behavioral abstractions, or options, for reinforcement learning agents. We propose an algorithm that focuses on the termination condition, as opposed to -- as is common -- the policy. The termination condition is usually trained to optimize a control objective: an option ought to terminate if another has better value. We offer a different, information-theoretic perspective, and propose that terminations should focus instead on the compressibility of the option's encoding -- arguably a key reason for using abstractions. To achieve this algorithmically, we leverage the classical options framework, and learn the option transition model as a "critic" for the termination condition. Using this model, we derive gradients that optimize the desired criteria. We show that the resulting options are non-trivial, intuitively meaningful, and useful for learning and planning.
Statistics and Samples in Distributional Reinforcement Learning
Feb 21, 2019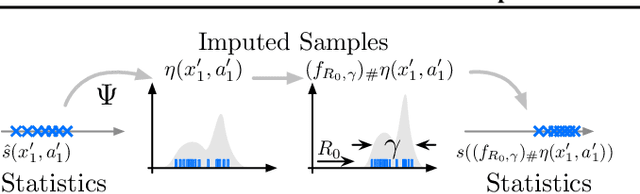
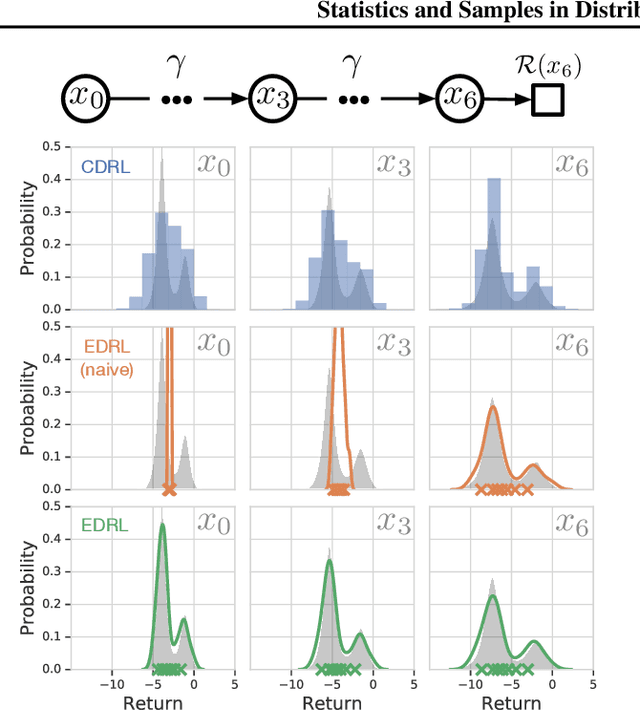
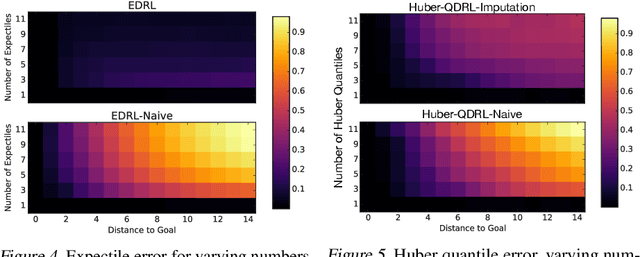
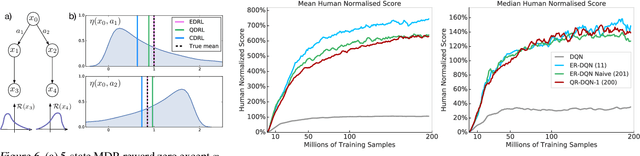
We present a unifying framework for designing and analysing distributional reinforcement learning (DRL) algorithms in terms of recursively estimating statistics of the return distribution. Our key insight is that DRL algorithms can be decomposed as the combination of some statistical estimator and a method for imputing a return distribution consistent with that set of statistics. With this new understanding, we are able to provide improved analyses of existing DRL algorithms as well as construct a new algorithm (EDRL) based upon estimation of the expectiles of the return distribution. We compare EDRL with existing methods on a variety of MDPs to illustrate concrete aspects of our analysis, and develop a deep RL variant of the algorithm, ER-DQN, which we evaluate on the Atari-57 suite of games.
A Geometric Perspective on Optimal Representations for Reinforcement Learning
Jan 31, 2019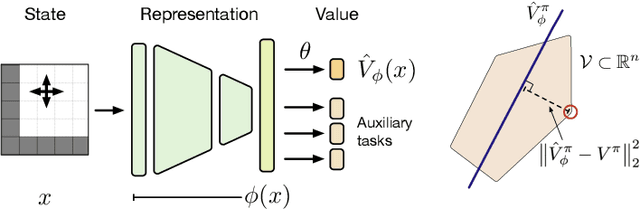
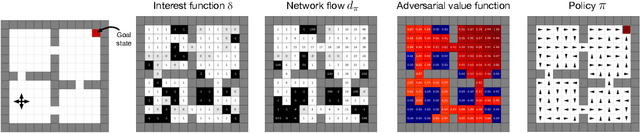
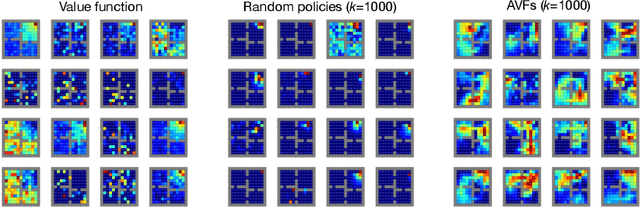
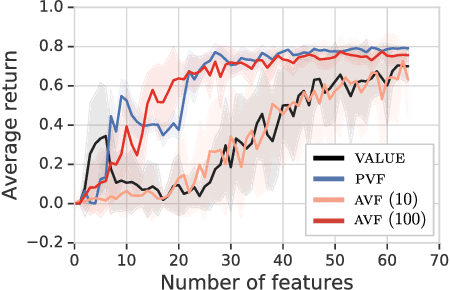
This paper proposes a new approach to representation learning based on geometric properties of the space of value functions. We study a two-part approximation of the value function: a nonlinear map from states to vectors, or representation, followed by a linear map from vectors to values. Our formulation considers adapting the representation to minimize the (linear) approximation of the value function of all stationary policies for a given environment. We show that this optimization reduces to making accurate predictions regarding a special class of value functions which we call adversarial value functions (AVFs). We argue that these AVFs make excellent auxiliary tasks, and use them to construct a loss which can be efficiently minimized to find a near-optimal representation for reinforcement learning. We highlight characteristics of the method in a series of experiments on the four-room domain.