 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Low-Resource Sequence Labeling by Sample-Aware Dynamic Sparse Finetuning
Nov 07, 2023



Unified Sequence Labeling that articulates different sequence labeling problems such as Named Entity Recognition, Relation Extraction, Semantic Role Labeling, etc. in a generalized sequence-to-sequence format opens up the opportunity to make the maximum utilization of large language model knowledge toward structured prediction. Unfortunately, this requires formatting them into specialized augmented format unknown to the base pretrained language model (PLMs) necessitating finetuning to the target format. This significantly bounds its usefulness in data-limited settings where finetuning large models cannot properly generalize to the target format. To address this challenge and leverage PLM knowledge effectively, we propose FISH-DIP, a sample-aware dynamic sparse finetuning strategy that selectively focuses on a fraction of parameters, informed by feedback from highly regressing examples, during the fine-tuning process. By leveraging the dynamism of sparsity, our approach mitigates the impact of well-learned samples and prioritizes underperforming instances for improvement in generalization. Across five tasks of sequence labeling, we demonstrate that FISH-DIP can smoothly optimize the model in low resource settings offering upto 40% performance improvements over full fine-tuning depending on target evaluation settings. Also, compared to in-context learning and other parameter-efficient fine-tuning approaches, FISH-DIP performs comparably or better, notably in extreme low-resource settings.
All Labels Together: Low-shot Intent Detection with an Efficient Label Semantic Encoding Paradigm
Sep 08, 2023



In intent detection tasks, leveraging meaningful semantic information from intent labels can be particularly beneficial for few-shot scenarios. However, existing few-shot intent detection methods either ignore the intent labels, (e.g. treating intents as indices) or do not fully utilize this information (e.g. only using part of the intent labels). In this work, we present an end-to-end One-to-All system that enables the comparison of an input utterance with all label candidates. The system can then fully utilize label semantics in this way. Experiments on three few-shot intent detection tasks demonstrate that One-to-All is especially effective when the training resource is extremely scarce, achieving state-of-the-art performance in 1-, 3- and 5-shot settings. Moreover, we present a novel pretraining strategy for our model that utilizes indirect supervision from paraphrasing, enabling zero-shot cross-domain generalization on intent detection tasks. Our code is at https://github.com/jiangshdd/AllLablesTogether.
Forget Demonstrations, Focus on Learning from Textual Instructions
Aug 04, 2023This work studies a challenging yet more realistic setting for zero-shot cross-task generalization: demonstration-free learning from textual instructions, presuming the existence of a paragraph-style task definition while no demonstrations exist. To better learn the task supervision from the definition, we propose two strategies: first, to automatically find out the critical sentences in the definition; second, a ranking objective to force the model to generate the gold outputs with higher probabilities when those critical parts are highlighted in the definition. The joint efforts of the two strategies yield state-of-the-art performance on the challenging benchmark. Our code will be released in the final version of the paper.
Is Prompt All You Need? No. A Comprehensive and Broader View of Instruction Learning
Mar 21, 2023Task semantics can be expressed by a set of input-to-output examples or a piece of textual instruction. Conventional machine learning approaches for natural language processing (NLP) mainly rely on the availability of large-scale sets of task-specific examples. Two issues arise: first, collecting task-specific labeled examples does not apply to scenarios where tasks may be too complicated or costly to annotate, or the system is required to handle a new task immediately; second, this is not user-friendly since end-users are probably more willing to provide task description rather than a set of examples before using the system. Therefore, the community is paying increasing interest in a new supervision-seeking paradigm for NLP: learning from task instructions. Despite its impressive progress, there are some common issues that the community struggles with. This survey paper tries to summarize the current research on instruction learning, particularly, by answering the following questions: (i) what is task instruction, and what instruction types exist? (ii) how to model instructions? (iii) what factors influence and explain the instructions' performance? (iv) what challenges remain in instruction learning? To our knowledge, this is the first comprehensive survey about textual instructions.
Robustness of Learning from Task Instructions
Dec 07, 2022



Traditional supervised learning mostly works on individual tasks and requires training on a large set of task-specific examples. This paradigm seriously hinders the development of task generalization since preparing a task-specific example set is costly. To build a system that can quickly and easily generalize to new tasks, task instructions have been adopted as an emerging trend of supervision recently. These instructions give the model the definition of the task and allow the model to output the appropriate answer based on the instructions and inputs. However, task instructions are often expressed in different forms, which can be interpreted from two threads: first, some instructions are short sentences and are pretrained language model (PLM) oriented, such as prompts, while other instructions are paragraphs and are human-oriented, such as those in Amazon MTurk; second, different end-users very likely explain the same task with instructions of different textual expressions. A robust system for task generalization should be able to handle any new tasks regardless of the variability of instructions. However, the system robustness in dealing with instruction-driven task generalization is still unexplored. This work investigates the system robustness when the instructions of new tasks are (i) maliciously manipulated, (ii) paraphrased, or (iii) from different levels of conciseness. To our knowledge, this is the first work that systematically studies how robust a PLM is when it is supervised by instructions with different factors of variability.
Learning to Select from Multiple Options
Dec 01, 2022



Many NLP tasks can be regarded as a selection problem from a set of options, such as classification tasks, multi-choice question answering, etc. Textual entailment (TE) has been shown as the state-of-the-art (SOTA) approach to dealing with those selection problems. TE treats input texts as premises (P), options as hypotheses (H), then handles the selection problem by modeling (P, H) pairwise. Two limitations: first, the pairwise modeling is unaware of other options, which is less intuitive since humans often determine the best options by comparing competing candidates; second, the inference process of pairwise TE is time-consuming, especially when the option space is large. To deal with the two issues, this work first proposes a contextualized TE model (Context-TE) by appending other k options as the context of the current (P, H) modeling. Context-TE is able to learn more reliable decision for the H since it considers various context. Second, we speed up Context-TE by coming up with Parallel-TE, which learns the decisions of multiple options simultaneously. Parallel-TE significantly improves the inference speed while keeping comparable performance with Context-TE. Our methods are evaluated on three tasks (ultra-fine entity typing, intent detection and multi-choice QA) that are typical selection problems with different sizes of options. Experiments show our models set new SOTA performance; particularly, Parallel-TE is faster than the pairwise TE by k times in inference. Our code is publicly available at https://github.com/jiangshdd/LearningToSelect.
OpenStance: Real-world Zero-shot Stance Detection
Oct 25, 2022Prior studies of zero-shot stance detection identify the attitude of texts towards unseen topics occurring in the same document corpus. Such task formulation has three limitations: (i) Single domain/dataset. A system is optimized on a particular dataset from a single domain; therefore, the resulting system cannot work well on other datasets; (ii) the model is evaluated on a limited number of unseen topics; (iii) it is assumed that part of the topics has rich annotations, which might be impossible in real-world applications. These drawbacks will lead to an impractical stance detection system that fails to generalize to open domains and open-form topics. This work defines OpenStance: open-domain zero-shot stance detection, aiming to handle stance detection in an open world with neither domain constraints nor topic-specific annotations. The key challenge of OpenStance lies in the open-domain generalization: learning a system with fully unspecific supervision but capable of generalizing to any dataset. To solve OpenStance, we propose to combine indirect supervision, from textual entailment datasets, and weak supervision, from data generated automatically by pre-trained Language Models. Our single system, without any topic-specific supervision, outperforms the supervised method on three popular datasets. To our knowledge, this is the first work that studies stance detection under the open-domain zero-shot setting. All data and code are publicly released.
Anti-Overestimation Dialogue Policy Learning for Task-Completion Dialogue System
Jul 24, 2022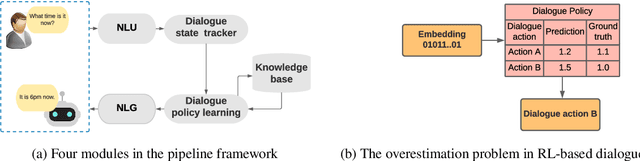



A dialogue policy module is an essential part of task-completion dialogue systems. Recently, increasing interest has focused on reinforcement learning (RL)-based dialogue policy. Its favorable performance and wise action decisions rely on an accurate estimation of action values. The overestimation problem is a widely known issue of RL since its estimate of the maximum action value is larger than the ground truth, which results in an unstable learning process and suboptimal policy. This problem is detrimental to RL-based dialogue policy learning. To mitigate this problem, this paper proposes a dynamic partial average estimator (DPAV) of the ground truth maximum action value. DPAV calculates the partial average between the predicted maximum action value and minimum action value, where the weights are dynamically adaptive and problem-dependent. We incorporate DPAV into a deep Q-network as the dialogue policy and show that our method can achieve better or comparable results compared to top baselines on three dialogue datasets of different domains with a lower computational load. In addition, we also theoretically prove the convergence and derive the upper and lower bounds of the bias compared with those of other methods.
Converse: A Tree-Based Modular Task-Oriented Dialogue System
Mar 30, 2022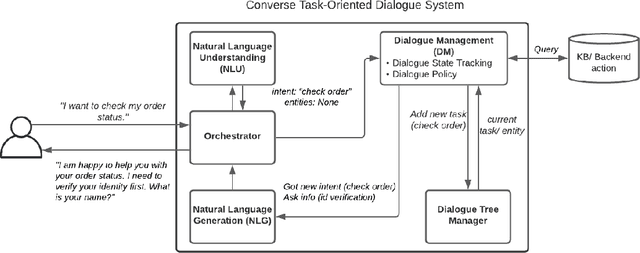

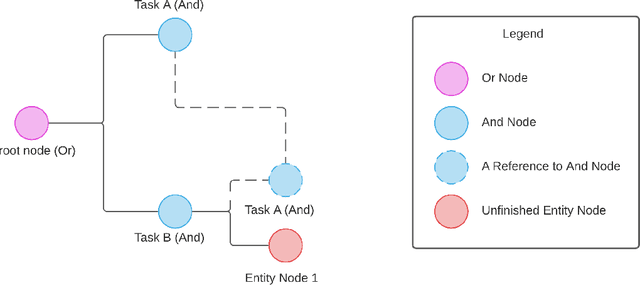
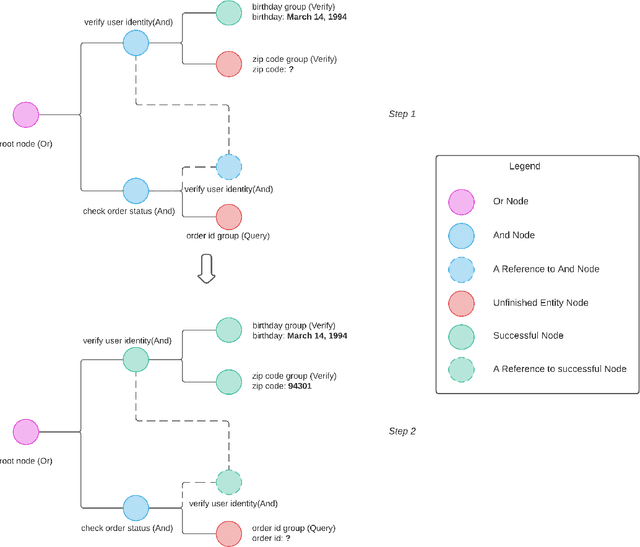
Creating a system that can have meaningful conversations with humans to help accomplish tasks is one of the ultimate goals of Artificial Intelligence (AI). It has defined the meaning of AI since the beginning. A lot has been accomplished in this area recently, with voice assistant products entering our daily lives and chat bot systems becoming commonplace in customer service. At first glance there seems to be no shortage of options for dialogue systems. However, the frequently deployed dialogue systems today seem to all struggle with a critical weakness - they are hard to build and harder to maintain. At the core of the struggle is the need to script every single turn of interactions between the bot and the human user. This makes the dialogue systems more difficult to maintain as the tasks become more complex and more tasks are added to the system. In this paper, we propose Converse, a flexible tree-based modular task-oriented dialogue system. Converse uses an and-or tree structure to represent tasks and offers powerful multi-task dialogue management. Converse supports task dependency and task switching, which are unique features compared to other open-source dialogue frameworks. At the same time, Converse aims to make the bot building process easy and simple, for both professional and non-professional software developers. The code is available at https://github.com/salesforce/Converse.
ConTinTin: Continual Learning from Task Instructions
Mar 18, 2022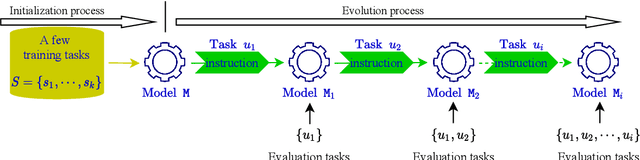

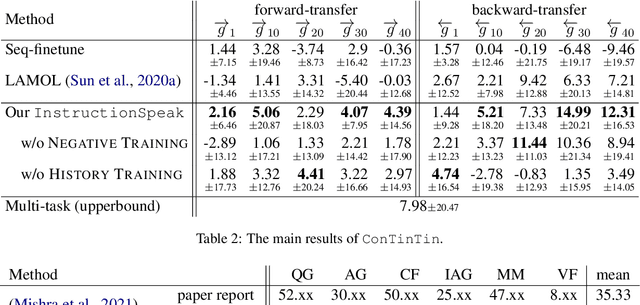
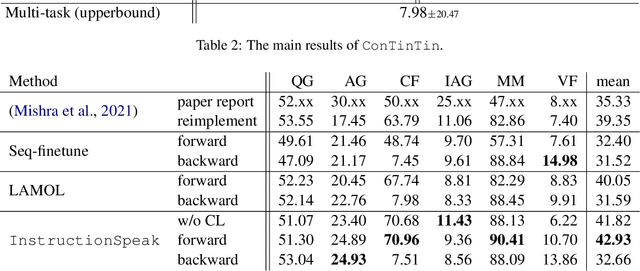
The mainstream machine learning paradigms for NLP often work with two underlying presumptions. First, the target task is predefined and static; a system merely needs to learn to solve it exclusively. Second, the supervision of a task mainly comes from a set of labeled examples. A question arises: how to build a system that can keep learning new tasks from their instructions? This work defines a new learning paradigm ConTinTin (Continual Learning from Task Instructions), in which a system should learn a sequence of new tasks one by one, each task is explained by a piece of textual instruction. The system is required to (i) generate the expected outputs of a new task by learning from its instruction, (ii) transfer the knowledge acquired from upstream tasks to help solve downstream tasks (i.e., forward-transfer), and (iii) retain or even improve the performance on earlier tasks after learning new tasks (i.e., backward-transfer). This new problem is studied on a stream of more than 60 tasks, each equipped with an instruction. Technically, our method InstructionSpeak contains two strategies that make full use of task instructions to improve forward-transfer and backward-transfer: one is to learn from negative outputs, the other is to re-visit instructions of previous tasks. To our knowledge, this is the first time to study ConTinTin in NLP. In addition to the problem formulation and our promising approach, this work also contributes to providing rich analyses for the community to better understand this novel learning problem.