 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJIZHI: A Fast and Cost-Effective Model-As-A-Service System for Web-Scale Online Inference at Baidu
Jun 03, 2021
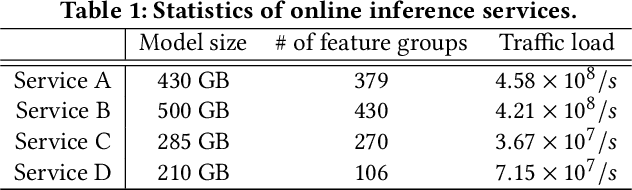
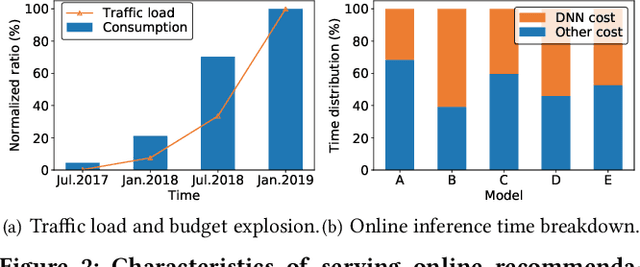
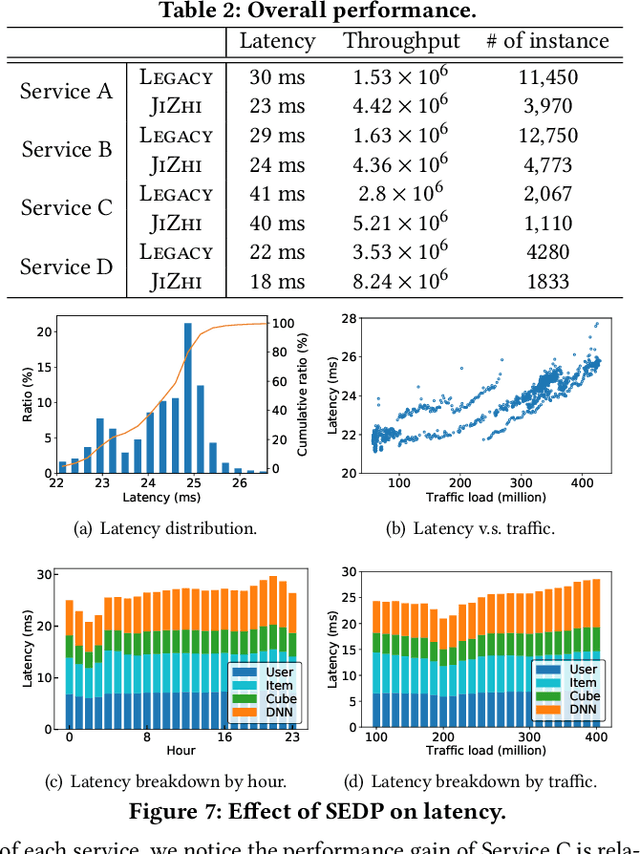
In modern internet industries, deep learning based recommender systems have became an indispensable building block for a wide spectrum of applications, such as search engine, news feed, and short video clips. However, it remains challenging to carry the well-trained deep models for online real-time inference serving, with respect to the time-varying web-scale traffics from billions of users, in a cost-effective manner. In this work, we present JIZHI - a Model-as-a-Service system - that per second handles hundreds of millions of online inference requests to huge deep models with more than trillions of sparse parameters, for over twenty real-time recommendation services at Baidu, Inc. In JIZHI, the inference workflow of every recommendation request is transformed to a Staged Event-Driven Pipeline (SEDP), where each node in the pipeline refers to a staged computation or I/O intensive task processor. With traffics of real-time inference requests arrived, each modularized processor can be run in a fully asynchronized way and managed separately. Besides, JIZHI introduces heterogeneous and hierarchical storage to further accelerate the online inference process by reducing unnecessary computations and potential data access latency induced by ultra-sparse model parameters. Moreover, an intelligent resource manager has been deployed to maximize the throughput of JIZHI over the shared infrastructure by searching the optimal resource allocation plan from historical logs and fine-tuning the load shedding policies over intermediate system feedback. Extensive experiments have been done to demonstrate the advantages of JIZHI from the perspectives of end-to-end service latency, system-wide throughput, and resource consumption. JIZHI has helped Baidu saved more than ten million US dollars in hardware and utility costs while handling 200% more traffics without sacrificing inference efficiency.
Improving Text Generation with Student-Forcing Optimal Transport
Oct 12, 2020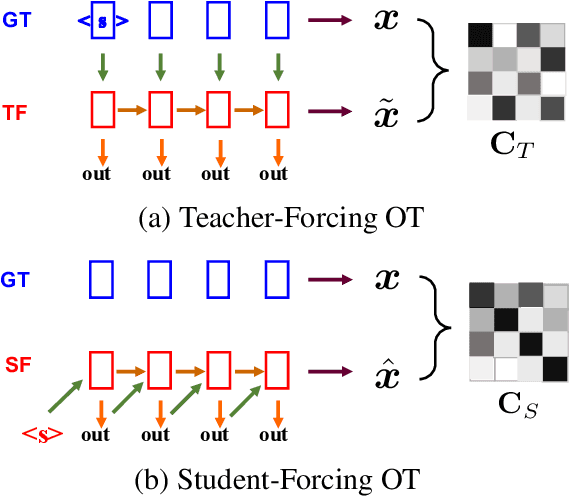
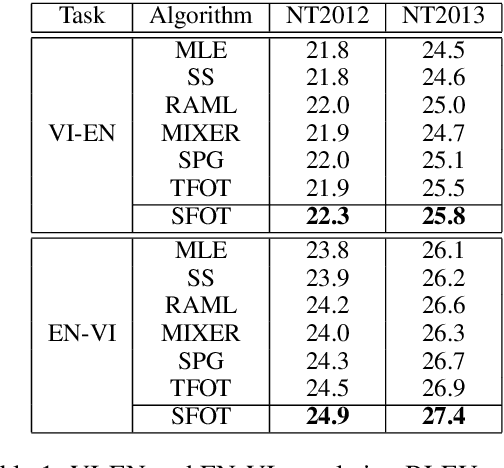
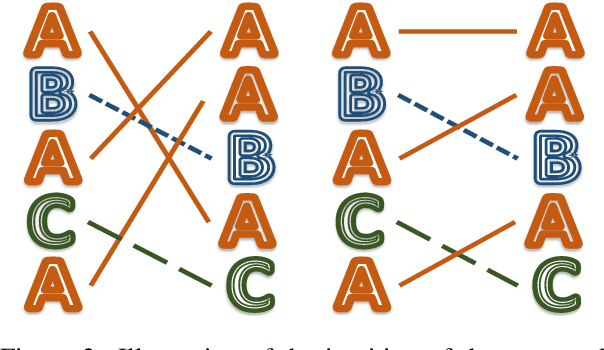
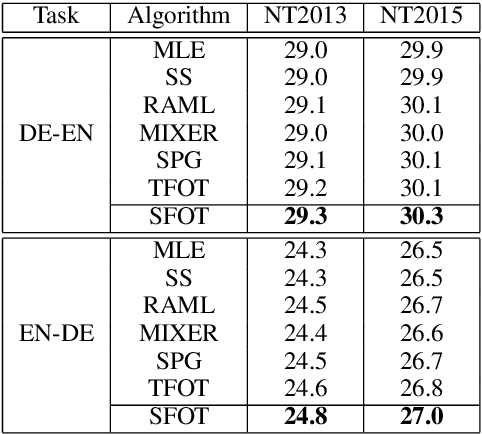
Neural language models are often trained with maximum likelihood estimation (MLE), where the next word is generated conditioned on the ground-truth word tokens. During testing, however, the model is instead conditioned on previously generated tokens, resulting in what is termed exposure bias. To reduce this gap between training and testing, we propose using optimal transport (OT) to match the sequences generated in these two modes. An extension is further proposed to improve the OT learning, based on the structural and contextual information of the text sequences. The effectiveness of the proposed method is validated on machine translation, text summarization, and text generation tasks.
Improving Adversarial Text Generation by Modeling the Distant Future
May 04, 2020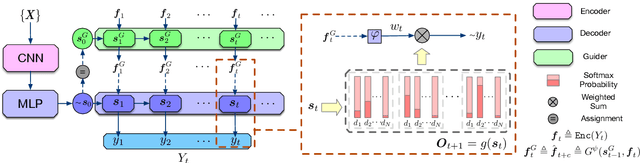
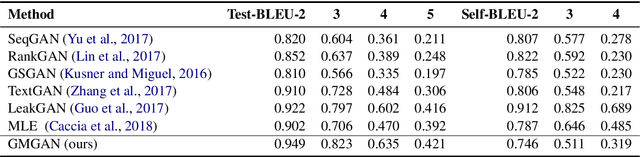
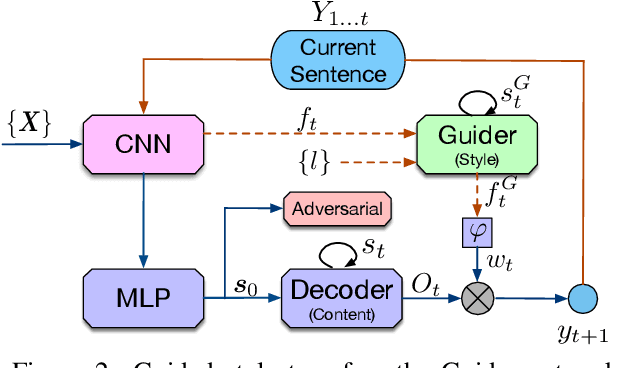
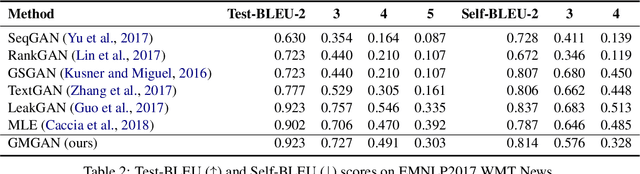
Auto-regressive text generation models usually focus on local fluency, and may cause inconsistent semantic meaning in long text generation. Further, automatically generating words with similar semantics is challenging, and hand-crafted linguistic rules are difficult to apply. We consider a text planning scheme and present a model-based imitation-learning approach to alleviate the aforementioned issues. Specifically, we propose a novel guider network to focus on the generative process over a longer horizon, which can assist next-word prediction and provide intermediate rewards for generator optimization. Extensive experiments demonstrate that the proposed method leads to improved performance.
Nested-Wasserstein Self-Imitation Learning for Sequence Generation
Jan 20, 2020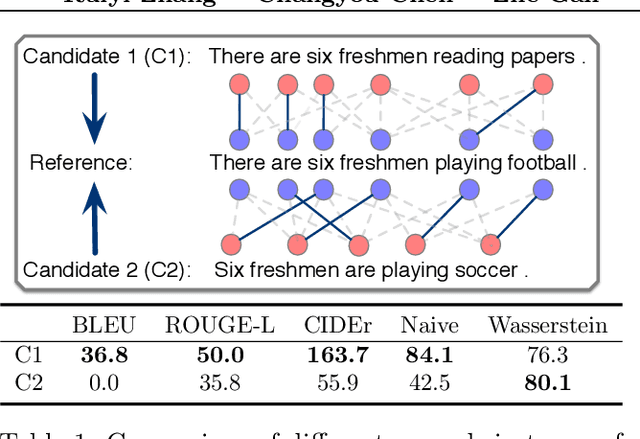
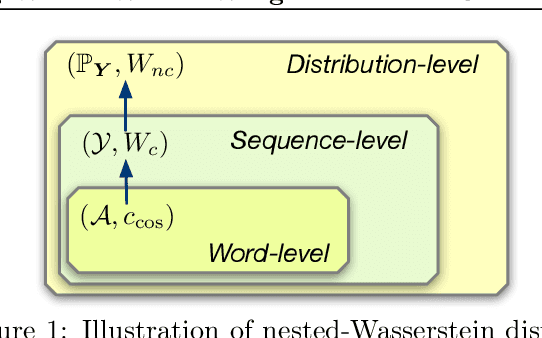
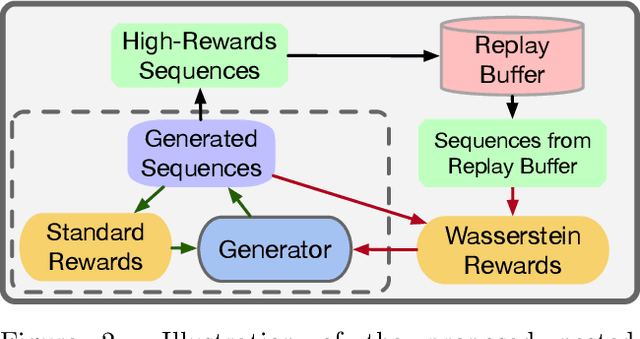
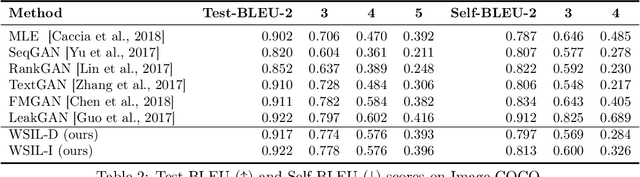
Reinforcement learning (RL) has been widely studied for improving sequence-generation models. However, the conventional rewards used for RL training typically cannot capture sufficient semantic information and therefore render model bias. Further, the sparse and delayed rewards make RL exploration inefficient. To alleviate these issues, we propose the concept of nested-Wasserstein distance for distributional semantic matching. To further exploit it, a novel nested-Wasserstein self-imitation learning framework is developed, encouraging the model to exploit historical high-rewarded sequences for enhanced exploration and better semantic matching. Our solution can be understood as approximately executing proximal policy optimization with Wasserstein trust-regions. Experiments on a variety of unconditional and conditional sequence-generation tasks demonstrate the proposed approach consistently leads to improved performance.
Graph-Driven Generative Models for Heterogeneous Multi-Task Learning
Nov 20, 2019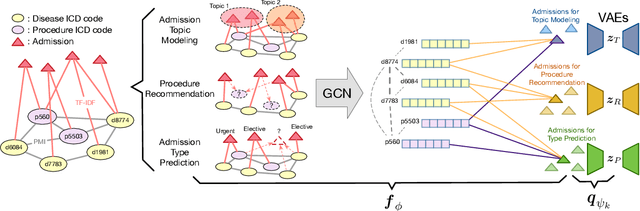

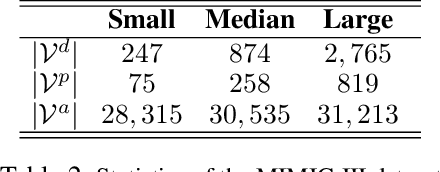

We propose a novel graph-driven generative model, that unifies multiple heterogeneous learning tasks into the same framework. The proposed model is based on the fact that heterogeneous learning tasks, which correspond to different generative processes, often rely on data with a shared graph structure. Accordingly, our model combines a graph convolutional network (GCN) with multiple variational autoencoders, thus embedding the nodes of the graph i.e., samples for the tasks) in a uniform manner while specializing their organization and usage to different tasks. With a focus on healthcare applications (tasks), including clinical topic modeling, procedure recommendation and admission-type prediction, we demonstrate that our method successfully leverages information across different tasks, boosting performance in all tasks and outperforming existing state-of-the-art approaches.
Collaborative Filtering with A Synthetic Feedback Loop
Oct 21, 2019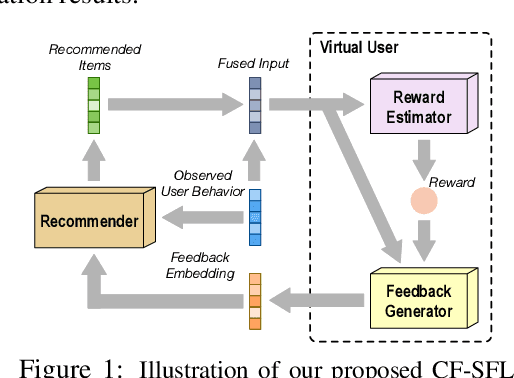
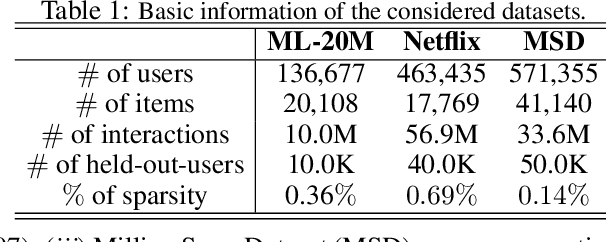
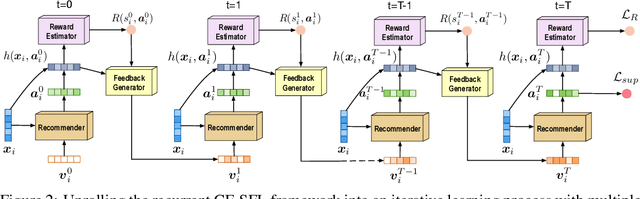

We propose a novel learning framework for recommendation systems, assisting collaborative filtering with a synthetic feedback loop. The proposed framework consists of a "recommender" and a "virtual user." The recommender is formulizd as a collaborative-filtering method, recommending items according to observed user behavior. The virtual user estimates rewards from the recommended items and generates the influence of the rewards on observed user behavior. The recommender connected with the virtual user constructs a closed loop, that recommends users with items and imitates the unobserved feedback of the users to the recommended items. The synthetic feedback is used to augment observed user behavior and improve recommendation results. Such a model can be interpreted as the inverse reinforcement learning, which can be learned effectively via rollout (simulation). Experimental results show that the proposed framework is able to boost the performance of existing collaborative filtering methods on multiple datasets.
An Optimal Transport Framework for Zero-Shot Learning
Oct 20, 2019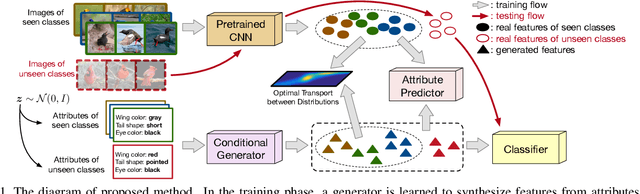
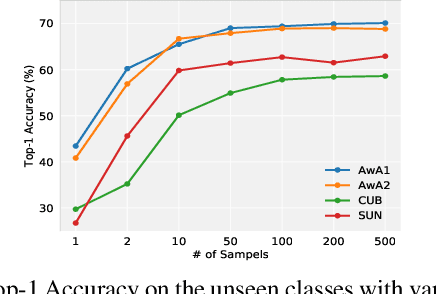
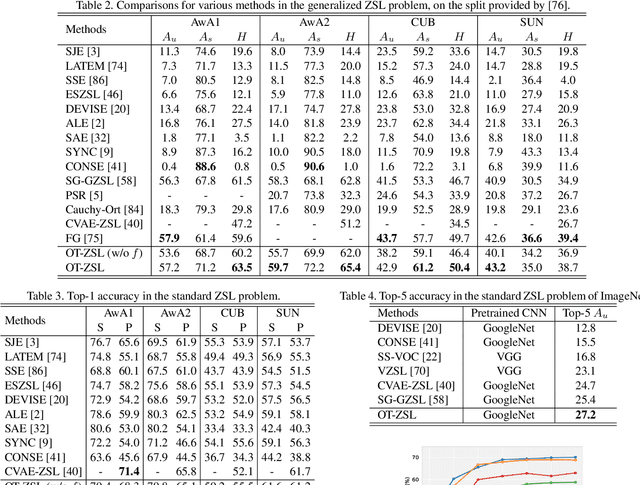
We present an optimal transport (OT) framework for generalized zero-shot learning (GZSL) of imaging data, seeking to distinguish samples for both seen and unseen classes, with the help of auxiliary attributes. The discrepancy between features and attributes is minimized by solving an optimal transport problem. {Specifically, we build a conditional generative model to generate features from seen-class attributes, and establish an optimal transport between the distribution of the generated features and that of the real features.} The generative model and the optimal transport are optimized iteratively with an attribute-based regularizer, that further enhances the discriminative power of the generated features. A classifier is learned based on the features generated for both the seen and unseen classes. In addition to generalized zero-shot learning, our framework is also applicable to standard and transductive ZSL problems. Experiments show that our optimal transport-based method outperforms state-of-the-art methods on several benchmark datasets.
Improving Textual Network Learning with Variational Homophilic Embeddings
Sep 30, 2019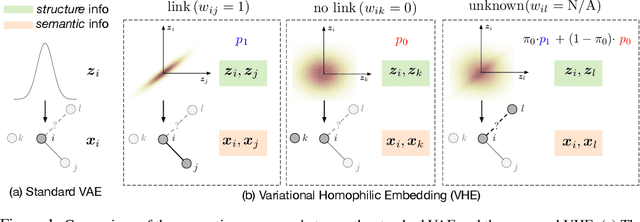
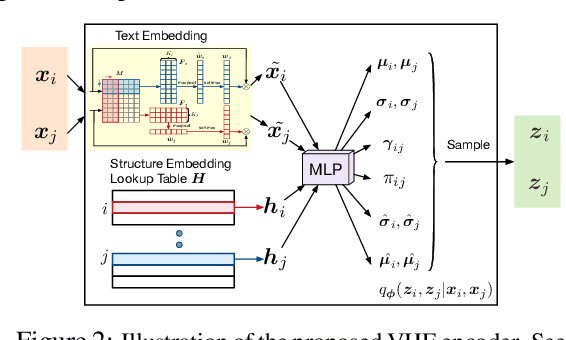
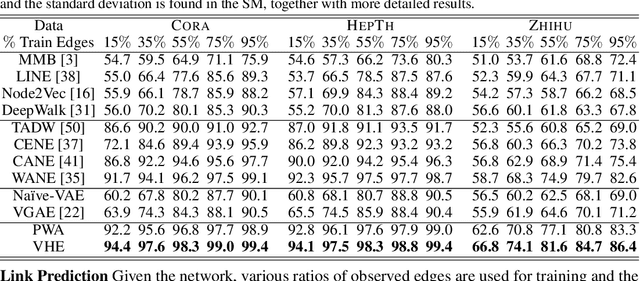
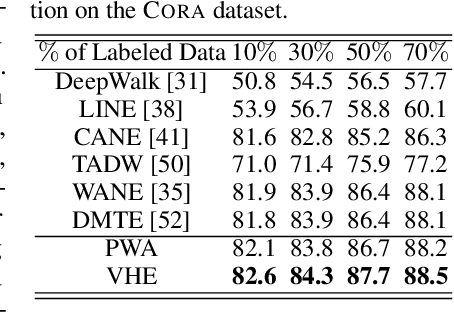
The performance of many network learning applications crucially hinges on the success of network embedding algorithms, which aim to encode rich network information into low-dimensional vertex-based vector representations. This paper considers a novel variational formulation of network embeddings, with special focus on textual networks. Different from most existing methods that optimize a discriminative objective, we introduce Variational Homophilic Embedding (VHE), a fully generative model that learns network embeddings by modeling the semantic (textual) information with a variational autoencoder, while accounting for the structural (topology) information through a novel homophilic prior design. Homophilic vertex embeddings encourage similar embedding vectors for related (connected) vertices. The proposed VHE promises better generalization for downstream tasks, robustness to incomplete observations, and the ability to generalize to unseen vertices. Extensive experiments on real-world networks, for multiple tasks, demonstrate that the proposed method consistently achieves superior performance relative to competing state-of-the-art approaches.
Ouroboros: On Accelerating Training of Transformer-Based Language Models
Sep 14, 2019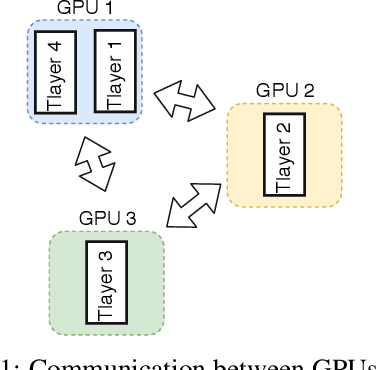

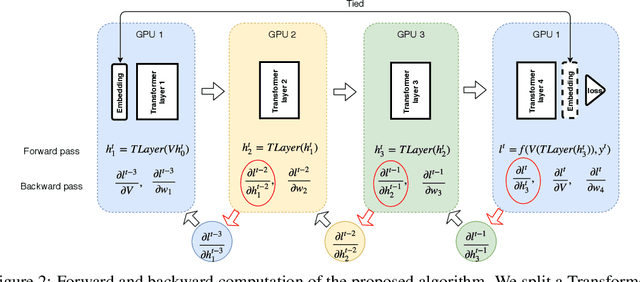
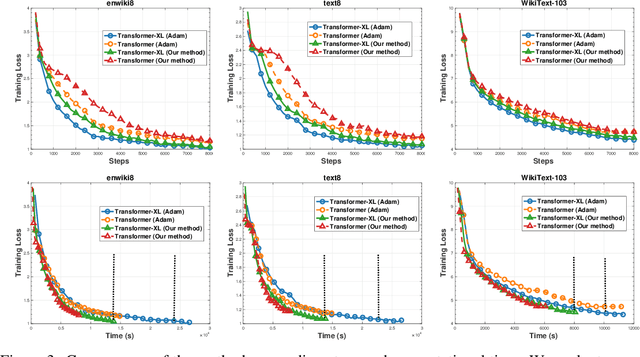
Language models are essential for natural language processing (NLP) tasks, such as machine translation and text summarization. Remarkable performance has been demonstrated recently across many NLP domains via a Transformer-based language model with over a billion parameters, verifying the benefits of model size. Model parallelism is required if a model is too large to fit in a single computing device. Current methods for model parallelism either suffer from backward locking in backpropagation or are not applicable to language models. We propose the first model-parallel algorithm that speeds the training of Transformer-based language models. We also prove that our proposed algorithm is guaranteed to converge to critical points for non-convex problems. Extensive experiments on Transformer and Transformer-XL language models demonstrate that the proposed algorithm obtains a much faster speedup beyond data parallelism, with comparable or better accuracy. Code to reproduce experiments is to be found at \url{https://github.com/LaraQianYang/Ouroboros}.
Improving Textual Network Embedding with Global Attention via Optimal Transport
Jun 05, 2019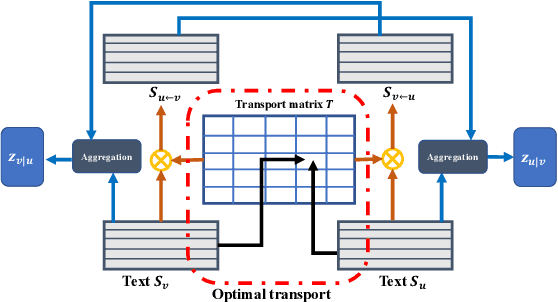
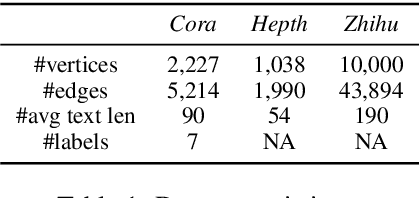
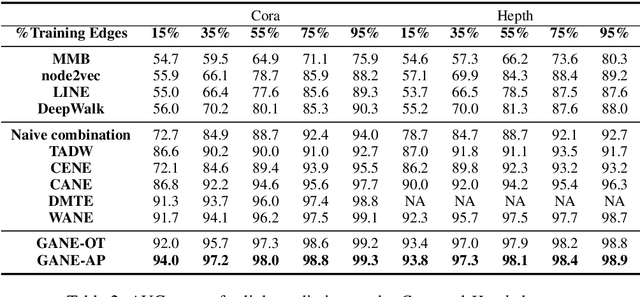
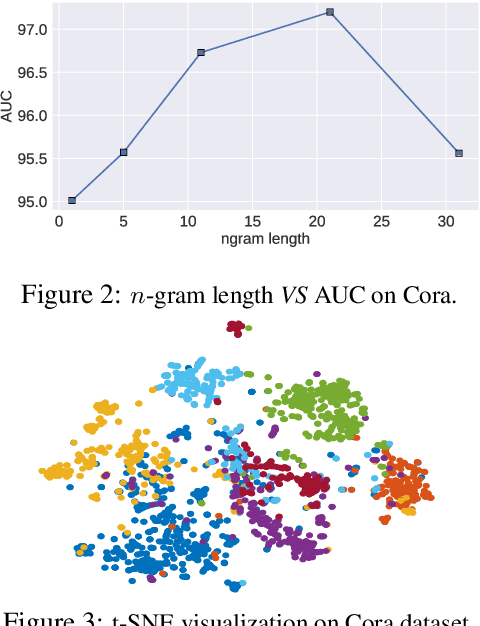
Constituting highly informative network embeddings is an important tool for network analysis. It encodes network topology, along with other useful side information, into low-dimensional node-based feature representations that can be exploited by statistical modeling. This work focuses on learning context-aware network embeddings augmented with text data. We reformulate the network-embedding problem, and present two novel strategies to improve over traditional attention mechanisms: ($i$) a content-aware sparse attention module based on optimal transport, and ($ii$) a high-level attention parsing module. Our approach yields naturally sparse and self-normalized relational inference. It can capture long-term interactions between sequences, thus addressing the challenges faced by existing textual network embedding schemes. Extensive experiments are conducted to demonstrate our model can consistently outperform alternative state-of-the-art methods.