 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARL-GT: Evaluating Causal Reasoning Capabilities of Large Language Models
Dec 23, 2024



Causal reasoning capabilities are essential for large language models (LLMs) in a wide range of applications, such as education and healthcare. But there is still a lack of benchmarks for a better understanding of such capabilities. Current LLM benchmarks are mainly based on conversational tasks, academic math tests, and coding tests. Such benchmarks evaluate LLMs in well-regularized settings, but they are limited in assessing the skills and abilities to solve real-world problems. In this work, we provide a benchmark, named by CARL-GT, which evaluates CAusal Reasoning capabilities of large Language models using Graphs and Tabular data. The benchmark has a diverse range of tasks for evaluating LLMs from causal graph reasoning, knowledge discovery, and decision-making aspects. In addition, effective zero-shot learning prompts are developed for the tasks. In our experiments, we leverage the benchmark for evaluating open-source LLMs and provide a detailed comparison of LLMs for causal reasoning abilities. We found that LLMs are still weak in casual reasoning, especially with tabular data to discover new insights. Furthermore, we investigate and discuss the relationships of different benchmark tasks by analyzing the performance of LLMs. The experimental results show that LLMs have different strength over different tasks and that their performance on tasks in different categories, i.e., causal graph reasoning, knowledge discovery, and decision-making, shows stronger correlation than tasks in the same category.
Causality for Tabular Data Synthesis: A High-Order Structure Causal Benchmark Framework
Jun 12, 2024Tabular synthesis models remain ineffective at capturing complex dependencies, and the quality of synthetic data is still insufficient for comprehensive downstream tasks, such as prediction under distribution shifts, automated decision-making, and cross-table understanding. A major challenge is the lack of prior knowledge about underlying structures and high-order relationships in tabular data. We argue that a systematic evaluation on high-order structural information for tabular data synthesis is the first step towards solving the problem. In this paper, we introduce high-order structural causal information as natural prior knowledge and provide a benchmark framework for the evaluation of tabular synthesis models. The framework allows us to generate benchmark datasets with a flexible range of data generation processes and to train tabular synthesis models using these datasets for further evaluation. We propose multiple benchmark tasks, high-order metrics, and causal inference tasks as downstream tasks for evaluating the quality of synthetic data generated by the trained models. Our experiments demonstrate to leverage the benchmark framework for evaluating the model capability of capturing high-order structural causal information. Furthermore, our benchmarking results provide an initial assessment of state-of-the-art tabular synthesis models. They have clearly revealed significant gaps between ideal and actual performance and how baseline methods differ. Our benchmark framework is available at URL https://github.com/TURuibo/CauTabBench.
Self-Supervised Learning of Time Series Representation via Diffusion Process and Imputation-Interpolation-Forecasting Mask
May 09, 2024



Time Series Representation Learning (TSRL) focuses on generating informative representations for various Time Series (TS) modeling tasks. Traditional Self-Supervised Learning (SSL) methods in TSRL fall into four main categories: reconstructive, adversarial, contrastive, and predictive, each with a common challenge of sensitivity to noise and intricate data nuances. Recently, diffusion-based methods have shown advanced generative capabilities. However, they primarily target specific application scenarios like imputation and forecasting, leaving a gap in leveraging diffusion models for generic TSRL. Our work, Time Series Diffusion Embedding (TSDE), bridges this gap as the first diffusion-based SSL TSRL approach. TSDE segments TS data into observed and masked parts using an Imputation-Interpolation-Forecasting (IIF) mask. It applies a trainable embedding function, featuring dual-orthogonal Transformer encoders with a crossover mechanism, to the observed part. We train a reverse diffusion process conditioned on the embeddings, designed to predict noise added to the masked part. Extensive experiments demonstrate TSDE's superiority in imputation, interpolation, forecasting, anomaly detection, classification, and clustering. We also conduct an ablation study, present embedding visualizations, and compare inference speed, further substantiating TSDE's efficiency and validity in learning representations of TS data.
Unified speech and gesture synthesis using flow matching
Oct 08, 2023


As text-to-speech technologies achieve remarkable naturalness in read-aloud tasks, there is growing interest in multimodal synthesis of verbal and non-verbal communicative behaviour, such as spontaneous speech and associated body gestures. This paper presents a novel, unified architecture for jointly synthesising speech acoustics and skeleton-based 3D gesture motion from text, trained using optimal-transport conditional flow matching (OT-CFM). The proposed architecture is simpler than the previous state of the art, has a smaller memory footprint, and can capture the joint distribution of speech and gestures, generating both modalities together in one single process. The new training regime, meanwhile, enables better synthesis quality in much fewer steps (network evaluations) than before. Uni- and multimodal subjective tests demonstrate improved speech naturalness, gesture human-likeness, and cross-modal appropriateness compared to existing benchmarks.
Matcha-TTS: A fast TTS architecture with conditional flow matching
Sep 06, 2023



We introduce Matcha-TTS, a new encoder-decoder architecture for speedy TTS acoustic modelling, trained using optimal-transport conditional flow matching (OT-CFM). This yields an ODE-based decoder capable of high output quality in fewer synthesis steps than models trained using score matching. Careful design choices additionally ensure each synthesis step is fast to run. The method is probabilistic, non-autoregressive, and learns to speak from scratch without external alignments. Compared to strong pre-trained baseline models, the Matcha-TTS system has the smallest memory footprint, rivals the speed of the fastest models on long utterances, and attains the highest mean opinion score in a listening test. Please see https://shivammehta25.github.io/Matcha-TTS/ for audio examples, code, and pre-trained models.
Controllable Motion Synthesis and Reconstruction with Autoregressive Diffusion Models
Apr 03, 2023



Data-driven and controllable human motion synthesis and prediction are active research areas with various applications in interactive media and social robotics. Challenges remain in these fields for generating diverse motions given past observations and dealing with imperfect poses. This paper introduces MoDiff, an autoregressive probabilistic diffusion model over motion sequences conditioned on control contexts of other modalities. Our model integrates a cross-modal Transformer encoder and a Transformer-based decoder, which are found effective in capturing temporal correlations in motion and control modalities. We also introduce a new data dropout method based on the diffusion forward process to provide richer data representations and robust generation. We demonstrate the superior performance of MoDiff in controllable motion synthesis for locomotion with respect to two baselines and show the benefits of diffusion data dropout for robust synthesis and reconstruction of high-fidelity motion close to recorded data.
Causal-Discovery Performance of ChatGPT in the context of Neuropathic Pain Diagnosis
Jan 24, 2023



ChatGPT has demonstrated exceptional proficiency in natural language conversation, e.g., it can answer a wide range of questions while no previous large language models can. Thus, we would like to push its limit and explore its ability to answer causal discovery questions by using a medical benchmark (Tu et al. 2019) in causal discovery.
Optimal transport for causal discovery
Jan 23, 2022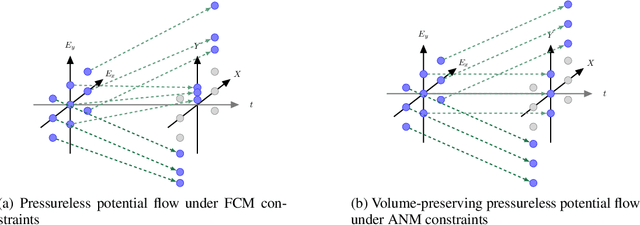

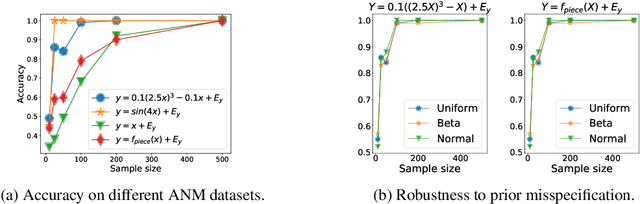
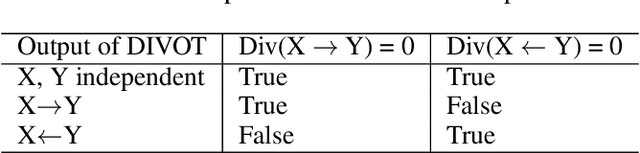
Approaches based on Functional Causal Models (FCMs) have been proposed to determine causal direction between two variables, by properly restricting model classes; however, their performance is sensitive to the model assumptions, which makes it difficult for practitioners to use. In this paper, we provide a novel dynamical-system view of FCMs and propose a new framework for identifying causal direction in the bivariate case. We first show the connection between FCMs and optimal transport, and then study optimal transport under the constraints of FCMs. Furthermore, by exploiting the dynamical interpretation of optimal transport under the FCM constraints, we determine the corresponding underlying dynamical process of the static cause-effect pair data under the least action principle. It provides a new dimension for describing static causal discovery tasks, while enjoying more freedom for modeling the quantitative causal influences. In particular, we show that Additive Noise Models (ANMs) correspond to volume-preserving pressureless flows. Consequently, based on their velocity field divergence, we introduce a criterion to determine causal direction. With this criterion, we propose a novel optimal transport-based algorithm for ANMs which is robust to the choice of models and extend it to post-noninear models. Our method demonstrated state-of-the-art results on both synthetic and causal discovery benchmark datasets.
Causal discovery from conditionally stationary time-series
Oct 12, 2021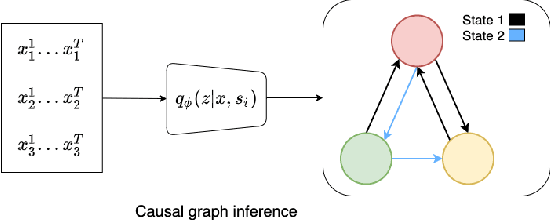

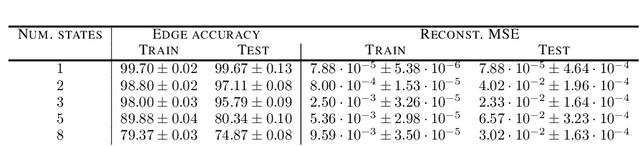
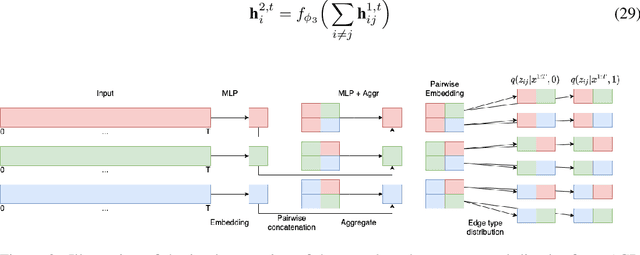
Causal discovery, i.e., inferring underlying cause-effect relationships from observations of a scene or system, is an inherent mechanism in human cognition, but has been shown to be highly challenging to automate. The majority of approaches in the literature aiming for this task consider constrained scenarios with fully observed variables or data from stationary time-series. In this work we aim for causal discovery in a more general class of scenarios, scenes with non-stationary behavior over time. For our purposes we here regard a scene as a composition objects interacting with each other over time. Non-stationarity is modeled as stationarity conditioned on an underlying variable, a state, which can be of varying dimension, more or less hidden given observations of the scene, and also depend more or less directly on these observations. We propose a probabilistic deep learning approach called State-Dependent Causal Inference (SDCI) for causal discovery in such conditionally stationary time-series data. Results in two different synthetic scenarios show that this method is able to recover the underlying causal dependencies with high accuracy even in cases with hidden states.
How Do Fair Decisions Fare in Long-term Qualification?
Oct 21, 2020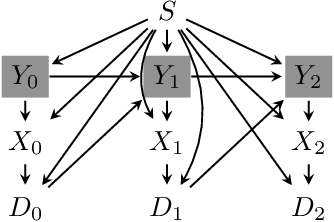
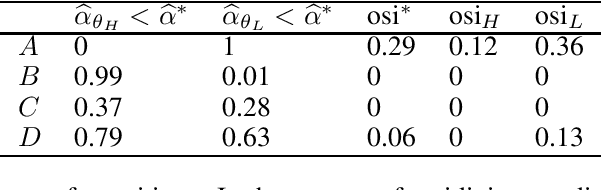
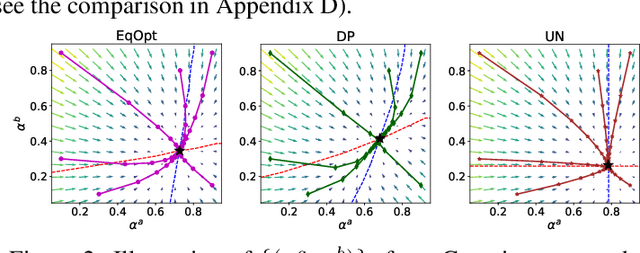

Although many fairness criteria have been proposed for decision making, their long-term impact on the well-being of a population remains unclear. In this work, we study the dynamics of population qualification and algorithmic decisions under a partially observed Markov decision problem setting. By characterizing the equilibrium of such dynamics, we analyze the long-term impact of static fairness constraints on the equality and improvement of group well-being. Our results show that static fairness constraints can either promote equality or exacerbate disparity depending on the driving factor of qualification transitions and the effect of sensitive attributes on feature distributions. We also consider possible interventions that can effectively improve group qualification or promote equality of group qualification. Our theoretical results and experiments on static real-world datasets with simulated dynamics show that our framework can be used to facilitate social science studies.