 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Effective Mask Sampling Modeling for Neural Image Compression
Jun 09, 2023



Image compression aims to reduce the information redundancy in images. Most existing neural image compression methods rely on side information from hyperprior or context models to eliminate spatial redundancy, but rarely address the channel redundancy. Inspired by the mask sampling modeling in recent self-supervised learning methods for natural language processing and high-level vision, we propose a novel pretraining strategy for neural image compression. Specifically, Cube Mask Sampling Module (CMSM) is proposed to apply both spatial and channel mask sampling modeling to image compression in the pre-training stage. Moreover, to further reduce channel redundancy, we propose the Learnable Channel Mask Module (LCMM) and the Learnable Channel Completion Module (LCCM). Our plug-and-play CMSM, LCMM, LCCM modules can apply to both CNN-based and Transformer-based architectures, significantly reduce the computational cost, and improve the quality of images. Experiments on the public Kodak and Tecnick datasets demonstrate that our method achieves competitive performance with lower computational complexity compared to state-of-the-art image compression methods.
MA2CL:Masked Attentive Contrastive Learning for Multi-Agent Reinforcement Learning
Jun 03, 2023



Recent approaches have utilized self-supervised auxiliary tasks as representation learning to improve the performance and sample efficiency of vision-based reinforcement learning algorithms in single-agent settings. However, in multi-agent reinforcement learning (MARL), these techniques face challenges because each agent only receives partial observation from an environment influenced by others, resulting in correlated observations in the agent dimension. So it is necessary to consider agent-level information in representation learning for MARL. In this paper, we propose an effective framework called \textbf{M}ulti-\textbf{A}gent \textbf{M}asked \textbf{A}ttentive \textbf{C}ontrastive \textbf{L}earning (MA2CL), which encourages learning representation to be both temporal and agent-level predictive by reconstructing the masked agent observation in latent space. Specifically, we use an attention reconstruction model for recovering and the model is trained via contrastive learning. MA2CL allows better utilization of contextual information at the agent level, facilitating the training of MARL agents for cooperation tasks. Extensive experiments demonstrate that our method significantly improves the performance and sample efficiency of different MARL algorithms and outperforms other methods in various vision-based and state-based scenarios. Our code can be found in \url{https://github.com/ustchlsong/MA2CL}
Detect Any Shadow: Segment Anything for Video Shadow Detection
May 26, 2023



Segment anything model (SAM) has achieved great success in the field of natural image segmentation. Nevertheless, SAM tends to classify shadows as background, resulting in poor segmentation performance for shadow detection task. In this paper, we propose an simple but effective approach for fine tuning SAM to detect shadows. Additionally, we also combine it with long short-term attention mechanism to extend its capabilities to video shadow detection. Specifically, we first fine tune SAM by utilizing shadow data combined with sparse prompts and apply the fine-tuned model to detect a specific frame (e.g., first frame) in the video with a little user assistance. Subsequently, using the detected frame as a reference, we employ a long short-term network to learn spatial correlations between distant frames and temporal consistency between contiguous frames, thereby achieving shadow information propagation across frames. Extensive experimental results demonstrate that our method outperforms the state-of-the-art techniques, with improvements of 17.2% and 3.3% in terms of MAE and IoU, respectively, validating the effectiveness of our method.
Hybrid and Collaborative Passage Reranking
May 16, 2023



In passage retrieval system, the initial passage retrieval results may be unsatisfactory, which can be refined by a reranking scheme. Existing solutions to passage reranking focus on enriching the interaction between query and each passage separately, neglecting the context among the top-ranked passages in the initial retrieval list. To tackle this problem, we propose a Hybrid and Collaborative Passage Reranking (HybRank) method, which leverages the substantial similarity measurements of upstream retrievers for passage collaboration and incorporates the lexical and semantic properties of sparse and dense retrievers for reranking. Besides, built on off-the-shelf retriever features, HybRank is a plug-in reranker capable of enhancing arbitrary passage lists including previously reranked ones. Extensive experiments demonstrate the stable improvements of performance over prevalent retrieval and reranking methods, and verify the effectiveness of the core components of HybRank.
SignBERT+: Hand-model-aware Self-supervised Pre-training for Sign Language Understanding
May 08, 2023



Hand gesture serves as a crucial role during the expression of sign language. Current deep learning based methods for sign language understanding (SLU) are prone to over-fitting due to insufficient sign data resource and suffer limited interpretability. In this paper, we propose the first self-supervised pre-trainable SignBERT+ framework with model-aware hand prior incorporated. In our framework, the hand pose is regarded as a visual token, which is derived from an off-the-shelf detector. Each visual token is embedded with gesture state and spatial-temporal position encoding. To take full advantage of current sign data resource, we first perform self-supervised learning to model its statistics. To this end, we design multi-level masked modeling strategies (joint, frame and clip) to mimic common failure detection cases. Jointly with these masked modeling strategies, we incorporate model-aware hand prior to better capture hierarchical context over the sequence. After the pre-training, we carefully design simple yet effective prediction heads for downstream tasks. To validate the effectiveness of our framework, we perform extensive experiments on three main SLU tasks, involving isolated and continuous sign language recognition (SLR), and sign language translation (SLT). Experimental results demonstrate the effectiveness of our method, achieving new state-of-the-art performance with a notable gain.
DocMAE: Document Image Rectification via Self-supervised Representation Learning
Apr 20, 2023



Tremendous efforts have been made on document image rectification, but how to learn effective representation of such distorted images is still under-explored. In this paper, we present DocMAE, a novel self-supervised framework for document image rectification. Our motivation is to encode the structural cues in document images by leveraging masked autoencoder to benefit the rectification, i.e., the document boundaries, and text lines. Specifically, we first mask random patches of the background-excluded document images and then reconstruct the missing pixels. With such a self-supervised learning approach, the network is encouraged to learn the intrinsic structure of deformed documents by restoring document boundaries and missing text lines. Transfer performance in the downstream rectification task validates the effectiveness of our method. Extensive experiments are conducted to demonstrate the effectiveness of our method.
Deep Unrestricted Document Image Rectification
Apr 18, 2023In recent years, tremendous efforts have been made on document image rectification, but existing advanced algorithms are limited to processing restricted document images, i.e., the input images must incorporate a complete document. Once the captured image merely involves a local text region, its rectification quality is degraded and unsatisfactory. Our previously proposed DocTr, a transformer-assisted network for document image rectification, also suffers from this limitation. In this work, we present DocTr++, a novel unified framework for document image rectification, without any restrictions on the input distorted images. Our major technical improvements can be concluded in three aspects. Firstly, we upgrade the original architecture by adopting a hierarchical encoder-decoder structure for multi-scale representation extraction and parsing. Secondly, we reformulate the pixel-wise mapping relationship between the unrestricted distorted document images and the distortion-free counterparts. The obtained data is used to train our DocTr++ for unrestricted document image rectification. Thirdly, we contribute a real-world test set and metrics applicable for evaluating the rectification quality. To our best knowledge, this is the first learning-based method for the rectification of unrestricted document images. Extensive experiments are conducted, and the results demonstrate the effectiveness and superiority of our method. We hope our DocTr++ will serve as a strong baseline for generic document image rectification, prompting the further advancement and application of learning-based algorithms. The source code and the proposed dataset are publicly available at https://github.com/fh2019ustc/DocTr-Plus.
Learning Transferable Pedestrian Representation from Multimodal Information Supervision
Apr 12, 2023



Recent researches on unsupervised person re-identification~(reID) have demonstrated that pre-training on unlabeled person images achieves superior performance on downstream reID tasks than pre-training on ImageNet. However, those pre-trained methods are specifically designed for reID and suffer flexible adaption to other pedestrian analysis tasks. In this paper, we propose VAL-PAT, a novel framework that learns transferable representations to enhance various pedestrian analysis tasks with multimodal information. To train our framework, we introduce three learning objectives, \emph{i.e.,} self-supervised contrastive learning, image-text contrastive learning and multi-attribute classification. The self-supervised contrastive learning facilitates the learning of the intrinsic pedestrian properties, while the image-text contrastive learning guides the model to focus on the appearance information of pedestrians.Meanwhile, multi-attribute classification encourages the model to recognize attributes to excavate fine-grained pedestrian information. We first perform pre-training on LUPerson-TA dataset, where each image contains text and attribute annotations, and then transfer the learned representations to various downstream tasks, including person reID, person attribute recognition and text-based person search. Extensive experiments demonstrate that our framework facilitates the learning of general pedestrian representations and thus leads to promising results on various pedestrian analysis tasks.
HandNeRF: Neural Radiance Fields for Animatable Interacting Hands
Mar 24, 2023We propose a novel framework to reconstruct accurate appearance and geometry with neural radiance fields (NeRF) for interacting hands, enabling the rendering of photo-realistic images and videos for gesture animation from arbitrary views. Given multi-view images of a single hand or interacting hands, an off-the-shelf skeleton estimator is first employed to parameterize the hand poses. Then we design a pose-driven deformation field to establish correspondence from those different poses to a shared canonical space, where a pose-disentangled NeRF for one hand is optimized. Such unified modeling efficiently complements the geometry and texture cues in rarely-observed areas for both hands. Meanwhile, we further leverage the pose priors to generate pseudo depth maps as guidance for occlusion-aware density learning. Moreover, a neural feature distillation method is proposed to achieve cross-domain alignment for color optimization. We conduct extensive experiments to verify the merits of our proposed HandNeRF and report a series of state-of-the-art results both qualitatively and quantitatively on the large-scale InterHand2.6M dataset.
Focus on Your Target: A Dual Teacher-Student Framework for Domain-adaptive Semantic Segmentation
Mar 16, 2023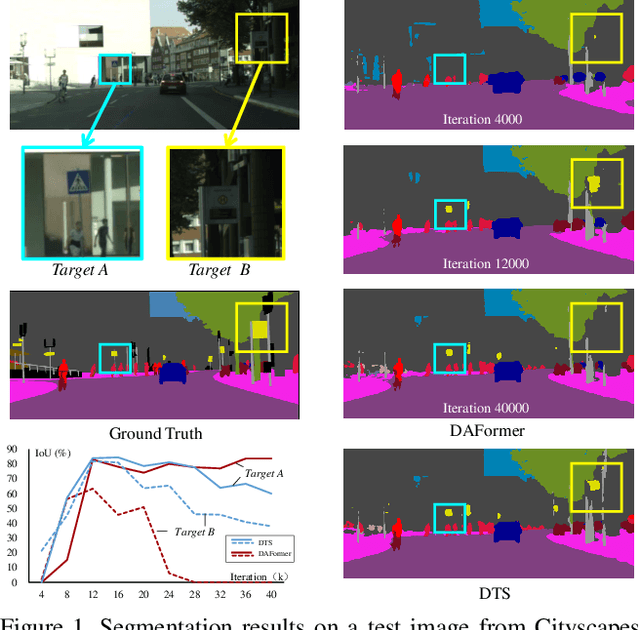
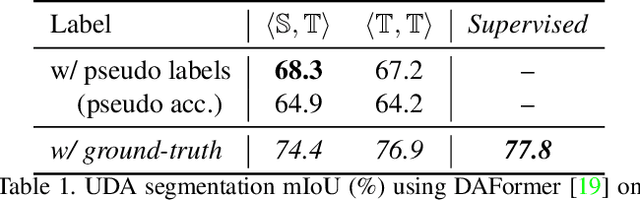
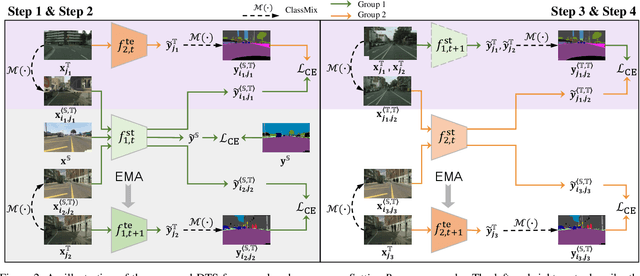
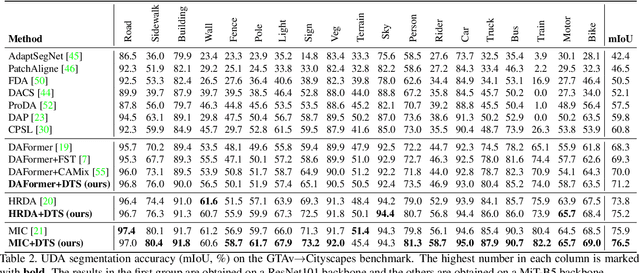
We study unsupervised domain adaptation (UDA) for semantic segmentation. Currently, a popular UDA framework lies in self-training which endows the model with two-fold abilities: (i) learning reliable semantics from the labeled images in the source domain, and (ii) adapting to the target domain via generating pseudo labels on the unlabeled images. We find that, by decreasing/increasing the proportion of training samples from the target domain, the 'learning ability' is strengthened/weakened while the 'adapting ability' goes in the opposite direction, implying a conflict between these two abilities, especially for a single model. To alleviate the issue, we propose a novel dual teacher-student (DTS) framework and equip it with a bidirectional learning strategy. By increasing the proportion of target-domain data, the second teacher-student model learns to 'Focus on Your Target' while the first model is not affected. DTS is easily plugged into existing self-training approaches. In a standard UDA scenario (training on synthetic, labeled data and real, unlabeled data), DTS shows consistent gains over the baselines and sets new state-of-the-art results of 76.5\% and 75.1\% mIoUs on GTAv$\rightarrow$Cityscapes and SYNTHIA$\rightarrow$Cityscapes, respectively.