 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Graph Neural Networks for Molecular Property Prediction
Jun 12, 2020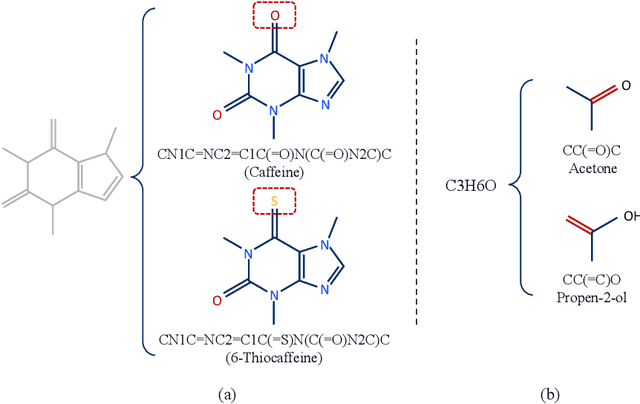
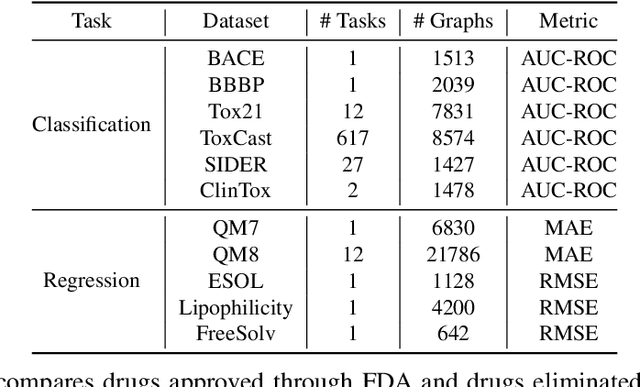
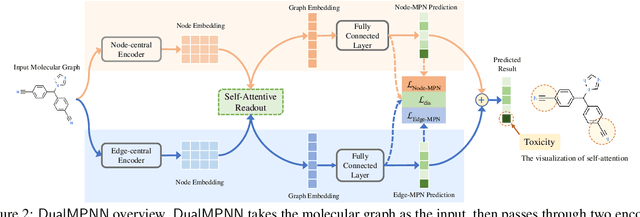
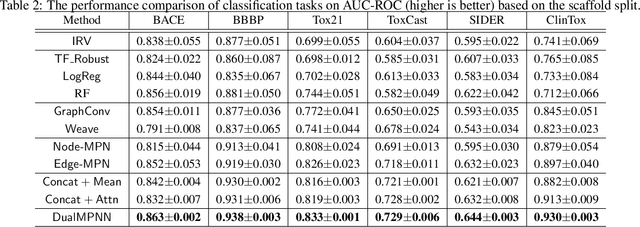
The crux of molecular property prediction is to generate meaningful representations of the molecules. One promising route is to exploit the molecular graph structure through Graph Neural Networks (GNNs). It is well known that both atoms and bonds significantly affect the chemical properties of a molecule, so an expressive model shall be able to exploit both node (atom) and edge (bond) information simultaneously. Guided by this observation, we present Multi-View Graph Neural Network (MV-GNN), a multi-view message passing architecture to enable more accurate predictions of molecular properties. In MV-GNN, we introduce a shared self-attentive readout component and disagreement loss to stabilize the training process. This readout component also renders the whole architecture interpretable. We further boost the expressive power of MV-GNN by proposing a cross-dependent message passing scheme that enhances information communication of the two views, which results in the MV-GNN^cross variant. Lastly, we theoretically justify the expressiveness of the two proposed models in terms of distinguishing non-isomorphism graphs. Extensive experiments demonstrate that MV-GNN models achieve remarkably superior performance over the state-of-the-art models on a variety of challenging benchmarks. Meanwhile, visualization results of the node importance are consistent with prior knowledge, which confirms the interpretability power of MV-GNN models.
Dense Regression Network for Video Grounding
Apr 07, 2020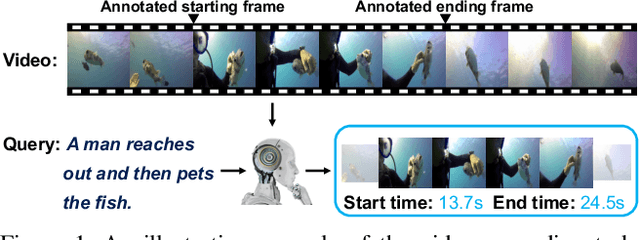
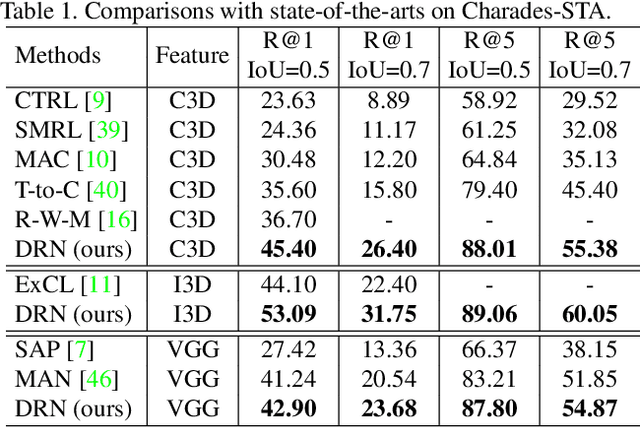
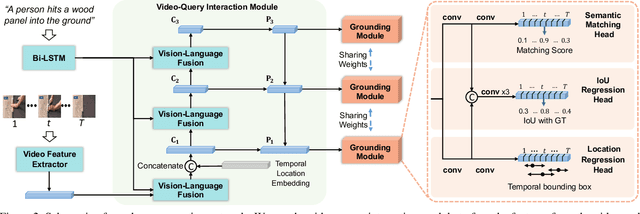
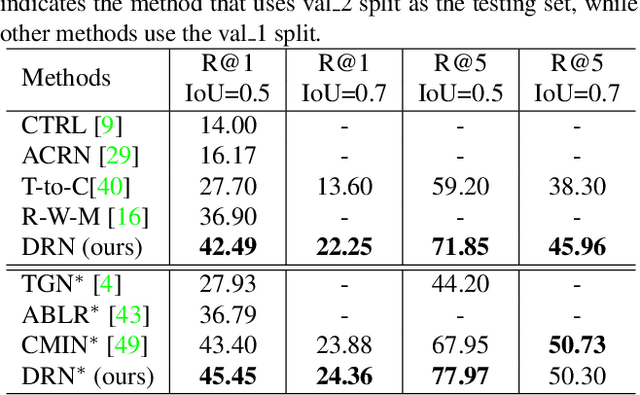
We address the problem of video grounding from natural language queries. The key challenge in this task is that one training video might only contain a few annotated starting/ending frames that can be used as positive examples for model training. Most conventional approaches directly train a binary classifier using such imbalance data, thus achieving inferior results. The key idea of this paper is to use the distances between the frame within the ground truth and the starting (ending) frame as dense supervisions to improve the video grounding accuracy. Specifically, we design a novel dense regression network (DRN) to regress the distances from each frame to the starting (ending) frame of the video segment described by the query. We also propose a simple but effective IoU regression head module to explicitly consider the localization quality of the grounding results (i.e., the IoU between the predicted location and the ground truth). Experimental results show that our approach significantly outperforms state-of-the-arts on three datasets (i.e., Charades-STA, ActivityNet-Captions, and TACoS).
Reusing Discriminators for Encoding: Towards Unsupervised Image-to-Image Translation
Mar 28, 2020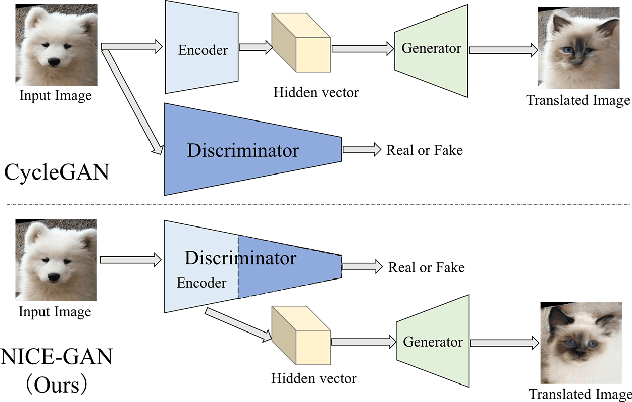
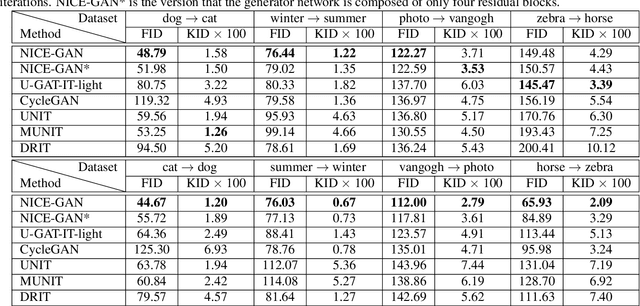
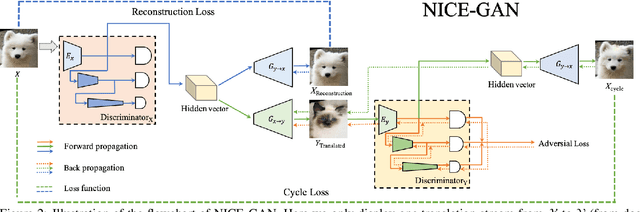
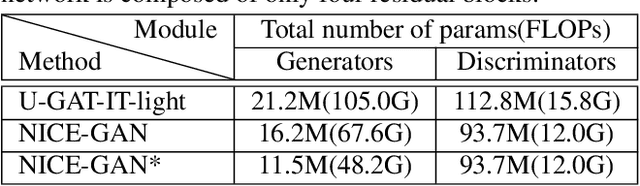
Unsupervised image-to-image translation is a central task in computer vision. Current translation frameworks will abandon the discriminator once the training process is completed. This paper contends a novel role of the discriminator by reusing it for encoding the images of the target domain. The proposed architecture, termed as NICE-GAN, exhibits two advantageous patterns over previous approaches: First, it is more compact since no independent encoding component is required; Second, this plug-in encoder is directly trained by the adversary loss, making it more informative and trained more effectively if a multi-scale discriminator is applied. The main issue in NICE-GAN is the coupling of translation with discrimination along the encoder, which could incur training inconsistency when we play the min-max game via GAN. To tackle this issue, we develop a decoupled training strategy by which the encoder is only trained when maximizing the adversary loss while keeping frozen otherwise. Extensive experiments on four popular benchmarks demonstrate the superior performance of NICE-GAN over state-of-the-art methods in terms of FID, KID, and also human preference. Comprehensive ablation studies are also carried out to isolate the validity of each proposed component. Our codes are available at https://github.com/alpc91/NICE-GAN-pytorch.
Spectral Graph Attention Network
Mar 16, 2020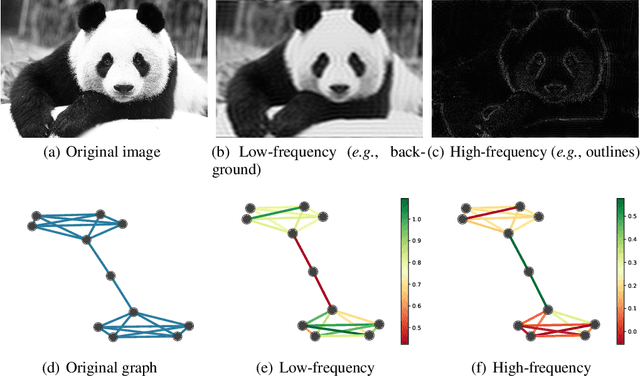
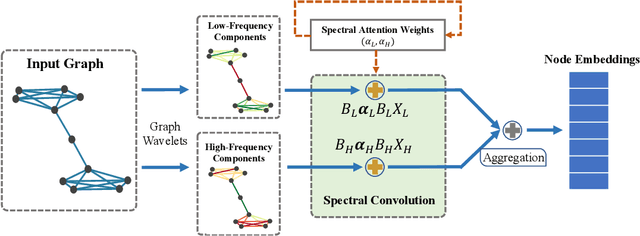
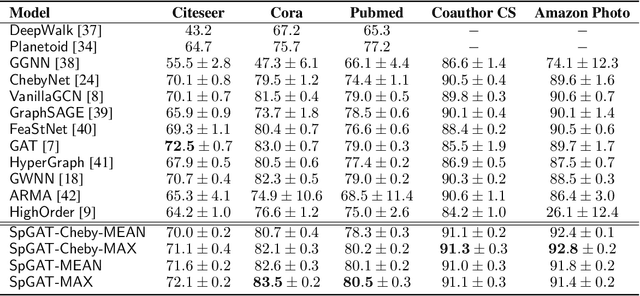
Variants of Graph Neural Networks (GNNs) for representation learning have been proposed recently and achieved fruitful results in various fields. Among them, graph attention networks (GATs) first employ a self-attention strategy to learn attention weights for each edge in the spatial domain. However, learning the attentions over edges only pays attention to the local information of graphs and greatly increases the number of parameters. In this paper, we first introduce attentions in the spectral domain of graphs. Accordingly, we present Spectral Graph Attention Network (SpGAT) that learn representations for different frequency components regarding weighted filters and graph wavelets bases. In this way, SpGAT can better capture global patterns of graphs in an efficient manner with much fewer learned parameters than that of GAT. We thoroughly evaluate the performance of SpGAT in the semi-supervised node classification task and verified the effectiveness of the learned attentions in the spectral domain.
Multi-AI competing and winning against humans in iterated Rock-Paper-Scissors game
Mar 15, 2020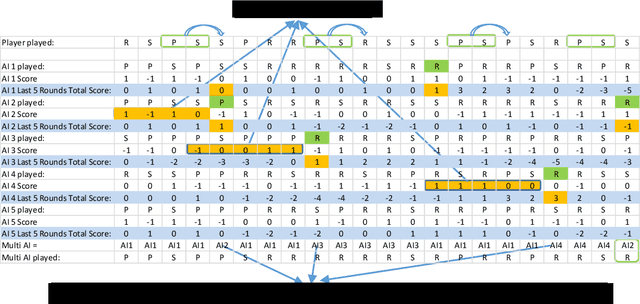
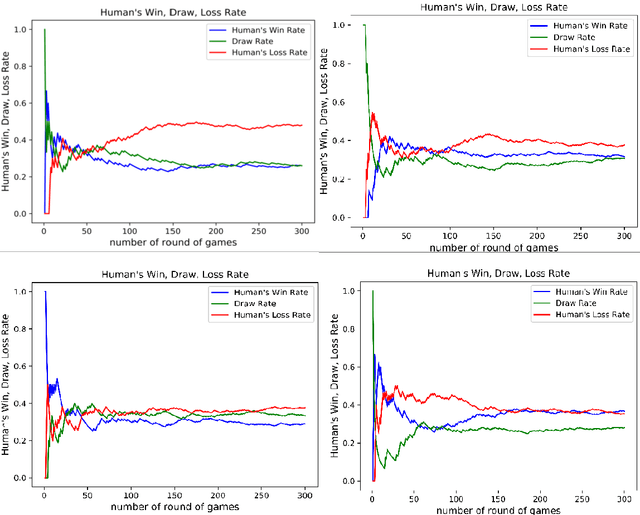
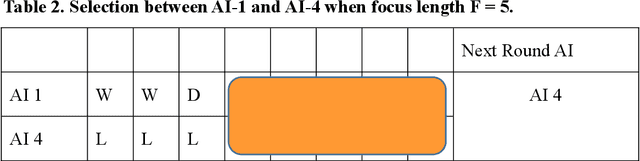
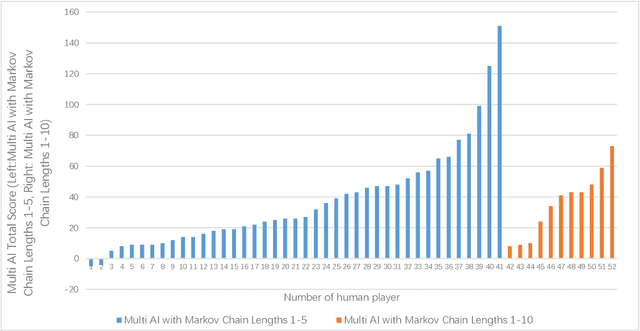
Predicting and modeling human behavior and finding trends within human decision-making process is a major social sciences'problem. Rock Paper Scissors (RPS) is the fundamental strategic question in many game theory problems and real-world competitions. Finding the right approach to beat a particular human opponent is challenging. Here we use Markov Chains with set chain lengths as the single AIs (artificial intelligences) to compete against humans in iterated RPS game. This is the first time that an AI algorithm is applied in RPS human competition behavior studies. We developed an architecture of multi-AI with changeable parameters to adapt to different competition strategies. We introduce a parameter "focus length" (an integer of e.g. 5 or 10) to control the speed and sensitivity for our multi-AI to adapt to the opponent's strategy change. We experimented with 52 different people, each playing 300 rounds continuously against one specific multi-AI model, and demonstrated that our strategy could win over more than 95% of human opponents.
Graph Representation Learning via Graphical Mutual Information Maximization
Feb 04, 2020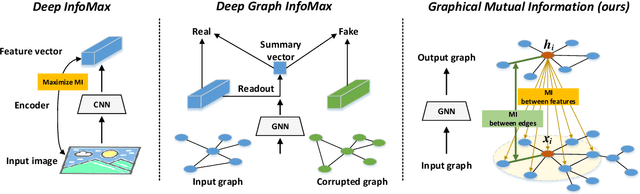
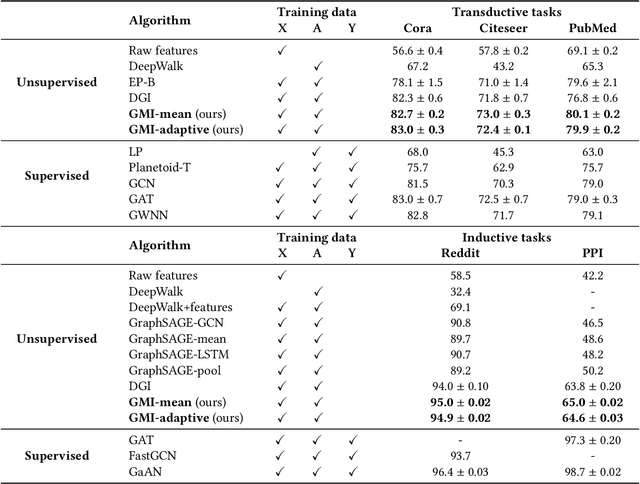
The richness in the content of various information networks such as social networks and communication networks provides the unprecedented potential for learning high-quality expressive representations without external supervision. This paper investigates how to preserve and extract the abundant information from graph-structured data into embedding space in an unsupervised manner. To this end, we propose a novel concept, Graphical Mutual Information (GMI), to measure the correlation between input graphs and high-level hidden representations. GMI generalizes the idea of conventional mutual information computations from vector space to the graph domain where measuring mutual information from two aspects of node features and topological structure is indispensable. GMI exhibits several benefits: First, it is invariant to the isomorphic transformation of input graphs---an inevitable constraint in many existing graph representation learning algorithms; Besides, it can be efficiently estimated and maximized by current mutual information estimation methods such as MINE; Finally, our theoretical analysis confirms its correctness and rationality. With the aid of GMI, we develop an unsupervised learning model trained by maximizing GMI between the input and output of a graph neural encoder. Considerable experiments on transductive as well as inductive node classification and link prediction demonstrate that our method outperforms state-of-the-art unsupervised counterparts, and even sometimes exceeds the performance of supervised ones.
Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks
Jan 17, 2020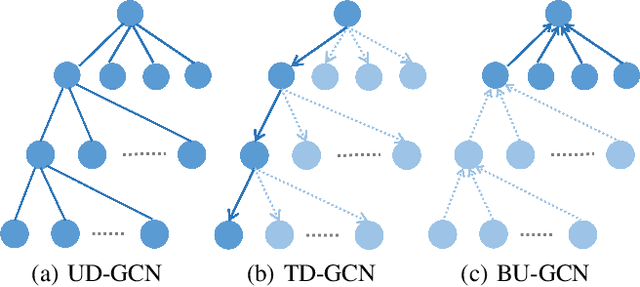
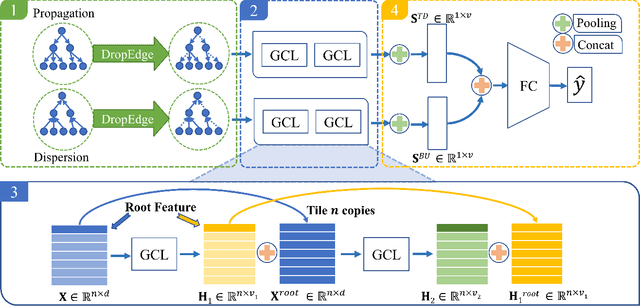
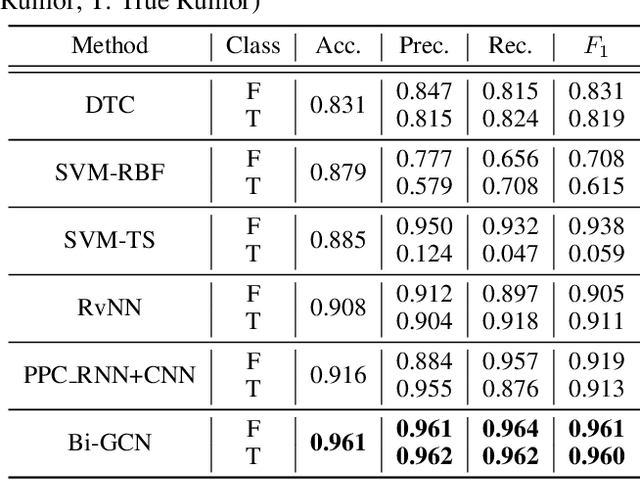
Social media has been developing rapidly in public due to its nature of spreading new information, which leads to rumors being circulated. Meanwhile, detecting rumors from such massive information in social media is becoming an arduous challenge. Therefore, some deep learning methods are applied to discover rumors through the way they spread, such as Recursive Neural Network (RvNN) and so on. However, these deep learning methods only take into account the patterns of deep propagation but ignore the structures of wide dispersion in rumor detection. Actually, propagation and dispersion are two crucial characteristics of rumors. In this paper, we propose a novel bi-directional graph model, named Bi-Directional Graph Convolutional Networks (Bi-GCN), to explore both characteristics by operating on both top-down and bottom-up propagation of rumors. It leverages a GCN with a top-down directed graph of rumor spreading to learn the patterns of rumor propagation, and a GCN with an opposite directed graph of rumor diffusion to capture the structures of rumor dispersion. Moreover, the information from the source post is involved in each layer of GCN to enhance the influences from the roots of rumors. Encouraging empirical results on several benchmarks confirm the superiority of the proposed method over the state-of-the-art approaches.
Reinforcement Learning from Imperfect Demonstrations under Soft Expert Guidance
Nov 23, 2019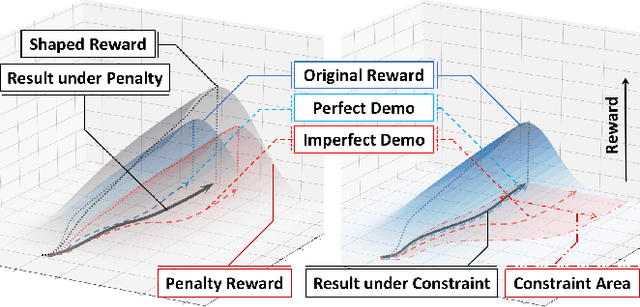
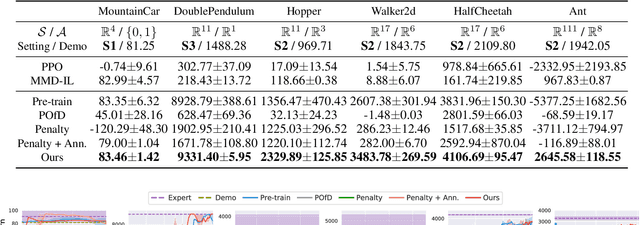
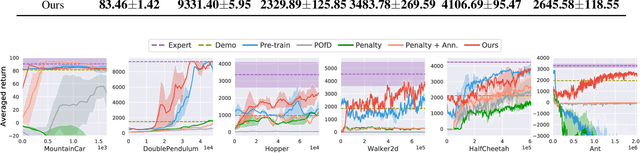
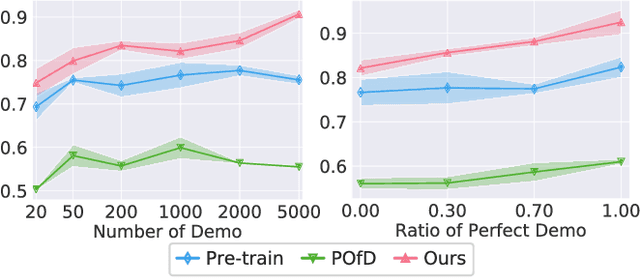
In this paper, we study Reinforcement Learning from Demonstrations (RLfD) that improves the exploration efficiency of Reinforcement Learning (RL) by providing expert demonstrations. Most of existing RLfD methods require demonstrations to be perfect and sufficient, which yet is unrealistic to meet in practice. To work on imperfect demonstrations, we first define an imperfect expert setting for RLfD in a formal way, and then point out that previous methods suffer from two issues in terms of optimality and convergence, respectively. Upon the theoretical findings we have derived, we tackle these two issues by regarding the expert guidance as a soft constraint on regulating the policy exploration of the agent, which eventually leads to a constrained optimization problem. We further demonstrate that such problem is able to be addressed efficiently by performing a local linear search on its dual form. Considerable empirical evaluations on a comprehensive collection of benchmarks indicate our method attains consistent improvement over other RLfD counterparts.
Imitation Learning from Observations by Minimizing Inverse Dynamics Disagreement
Nov 18, 2019
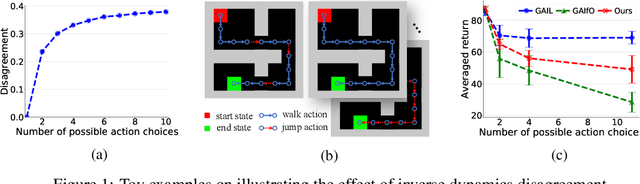

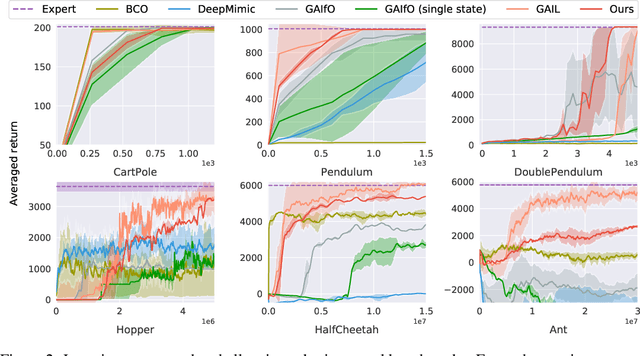
This paper studies Learning from Observations (LfO) for imitation learning with access to state-only demonstrations. In contrast to Learning from Demonstration (LfD) that involves both action and state supervision, LfO is more practical in leveraging previously inapplicable resources (e.g. videos), yet more challenging due to the incomplete expert guidance. In this paper, we investigate LfO and its difference with LfD in both theoretical and practical perspectives. We first prove that the gap between LfD and LfO actually lies in the disagreement of inverse dynamics models between the imitator and the expert, if following the modeling approach of GAIL. More importantly, the upper bound of this gap is revealed by a negative causal entropy which can be minimized in a model-free way. We term our method as Inverse-Dynamics-Disagreement-Minimization (IDDM) which enhances the conventional LfO method through further bridging the gap to LfD. Considerable empirical results on challenging benchmarks indicate that our method attains consistent improvements over other LfO counterparts.
DropEdge: Towards the Very Deep Graph Convolutional Networks for Node Classification
Sep 09, 2019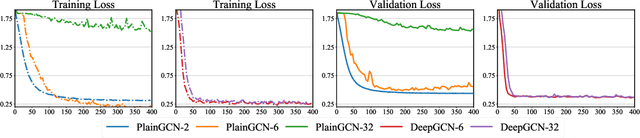
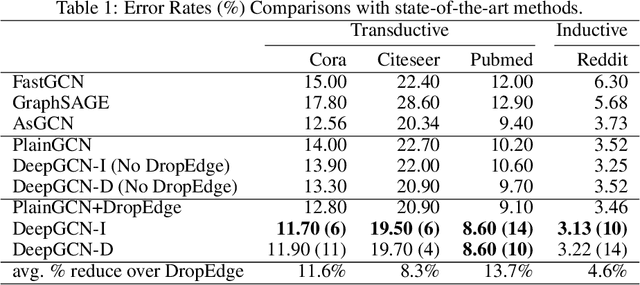
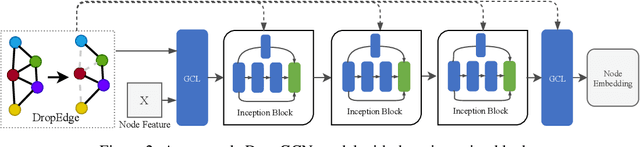

Existing Graph Convolutional Networks (GCNs) are shallow---the number of the layers is usually not larger than 2. The deeper variants by simply stacking more layers, unfortunately perform worse, even involving well-known tricks like weight penalizing, dropout, and residual connections. This paper reveals that developing deep GCNs mainly encounters two obstacles: \emph{over-fitting} and \emph{over-smoothing}. The over-fitting issue weakens the generalization ability on small graphs, while over-smoothing impedes model training by isolating output representations from the input features with the increase in network depth. Hence, we propose DropEdge, a novel technique to alleviate both issues. At its core, DropEdge randomly removes a certain number of edges from the input graphs, acting like a data augmenter and also a message passing reducer. More importantly, DropEdge enables us to recast a wider range of Convolutional Neural Networks (CNNs) from the image field to the graph domain; in particular, we study DenseNet and InceptionNet in this paper. Extensive experiments on several benchmarks demonstrate that our method allows deep GCNs to achieve promising performance, even when the number of layers exceeds 30---the deepest GCN that has ever been proposed.