 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Temporal Transformer Networks for Traffic Flow Forecasting
Jan 09, 2020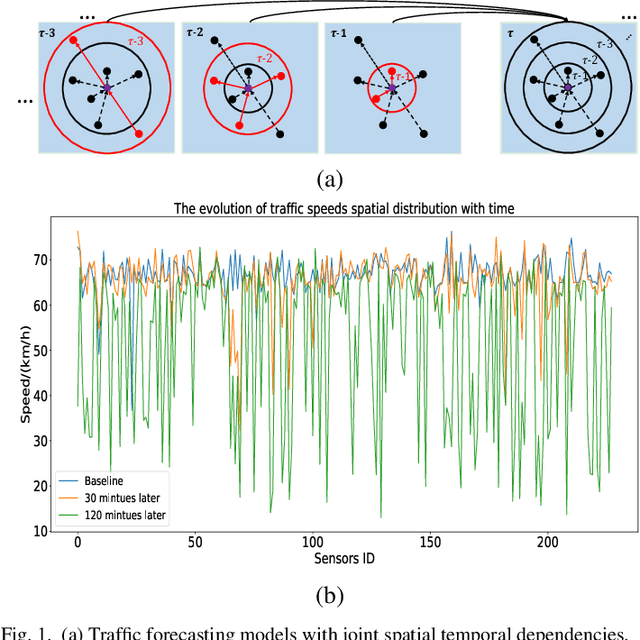
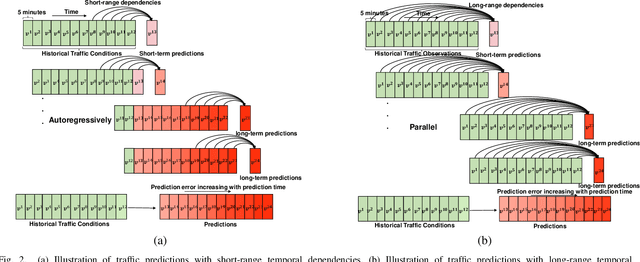
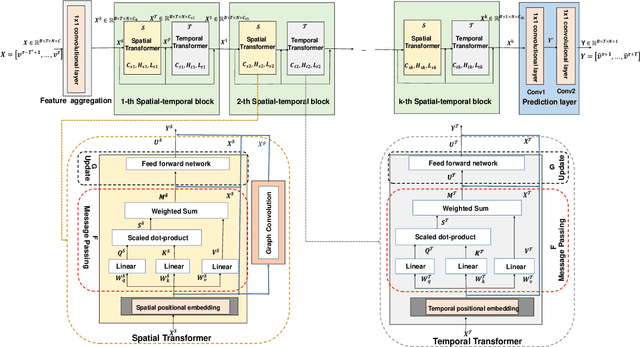
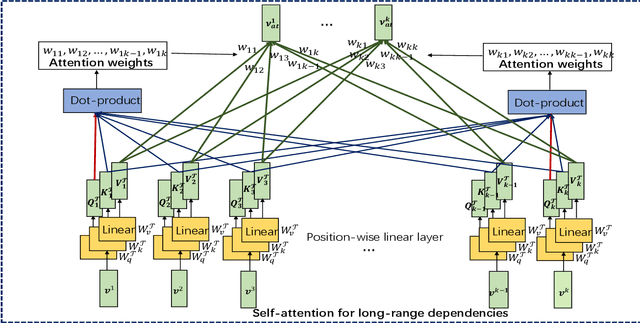
Traffic forecasting has emerged as a core component of intelligent transportation systems. However, timely accurate traffic forecasting, especially long-term forecasting, still remains an open challenge due to the highly nonlinear and dynamic spatial-temporal dependencies of traffic flows. In this paper, we propose a novel paradigm of Spatial-Temporal Transformer Networks (STTNs) that leverages dynamical directed spatial dependencies and long-range temporal dependencies to improve the accuracy of long-term traffic forecasting. Specifically, we present a new variant of graph neural networks, named spatial transformer, by dynamically modeling directed spatial dependencies with self-attention mechanism to capture realtime traffic conditions as well as the directionality of traffic flows. Furthermore, different spatial dependency patterns can be jointly modeled with multi-heads attention mechanism to consider diverse relationships related to different factors (e.g. similarity, connectivity and covariance). On the other hand, the temporal transformer is utilized to model long-range bidirectional temporal dependencies across multiple time steps. Finally, they are composed as a block to jointly model the spatial-temporal dependencies for accurate traffic prediction. Compared to existing works, the proposed model enables fast and scalable training over a long range spatial-temporal dependencies. Experiment results demonstrate that the proposed model achieves competitive results compared with the state-of-the-arts, especially forecasting long-term traffic flows on real-world PeMS-Bay and PeMSD7(M) datasets.
Trained Rank Pruning for Efficient Deep Neural Networks
Oct 11, 2019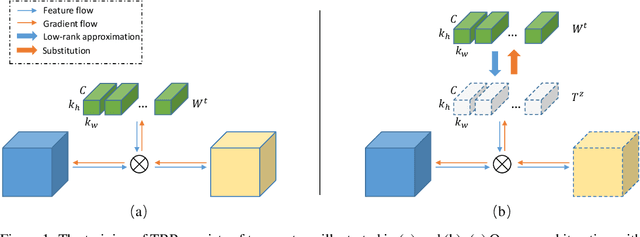
To accelerate DNNs inference, low-rank approximation has been widely adopted because of its solid theoretical rationale and efficient implementations. Several previous works attempted to directly approximate a pre-trained model by low-rank decomposition; however, small approximation errors in parameters can ripple over a large prediction loss. Apparently, it is not optimal to separate low-rank approximation from training. Unlike previous works, this paper integrates low rank approximation and regularization into the training process. We propose Trained Rank Pruning (TRP), which alternates between low rank approximation and training. TRP maintains the capacity of the original network while imposing low-rank constraints during training. A nuclear regularization optimized by stochastic sub-gradient descent is utilized to further promote low rank in TRP. Networks trained with TRP has a low-rank structure in nature, and is approximated with negligible performance loss, thus eliminating fine-tuning after low rank approximation. The proposed method is comprehensively evaluated on CIFAR-10 and ImageNet, outperforming previous compression counterparts using low rank approximation. Our code is available at: https://github.com/yuhuixu1993/Trained-Rank-Pruning.
Amur Tiger Re-identification in the Wild
Jun 14, 2019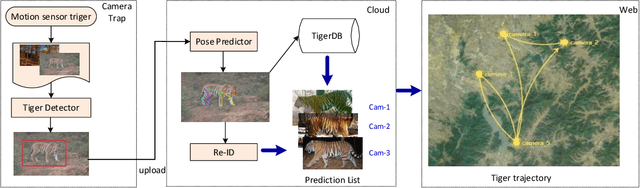

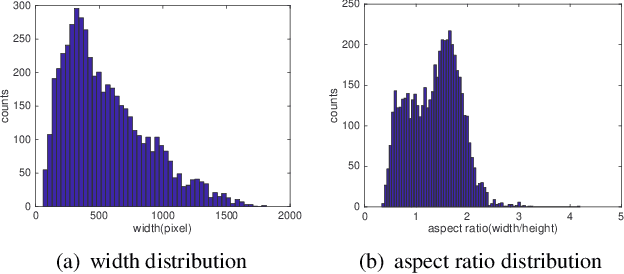
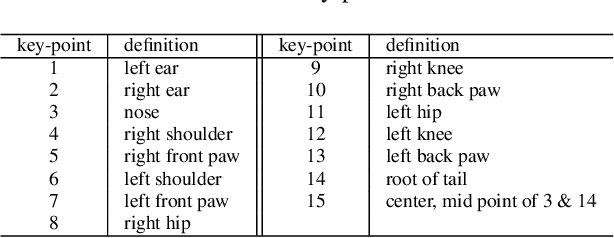
Monitoring the population and movements of endangered species is an important task to wildlife conversation. Traditional tagging methods do not scale to large populations, while applying computer vision methods to camera sensor data requires re-identification (re-ID) algorithms to obtain accurate counts and moving trajectory of wildlife. However, existing re-ID methods are largely targeted at persons and cars, which have limited pose variations and constrained capture environments. This paper tries to fill the gap by introducing a novel large-scale dataset, the Amur Tiger Re-identification in the Wild (ATRW) dataset. ATRW contains over 8,000 video clips from 92 Amur tigers, with bounding box, pose keypoint, and tiger identity annotations. In contrast to typical re-ID datasets, the tigers are captured in a diverse set of unconstrained poses and lighting conditions. We demonstrate with a set of baseline algorithms that ATRW is a challenging dataset for re-ID. Lastly, we propose a novel method for tiger re-identification, which introduces precise pose parts modeling in deep neural networks to handle large pose variation of tigers, and reaches notable performance improvement over existing re-ID methods. The dataset will be public available at https://cvwc2019.github.io/ .
Group Re-Identification with Multi-grained Matching and Integration
May 26, 2019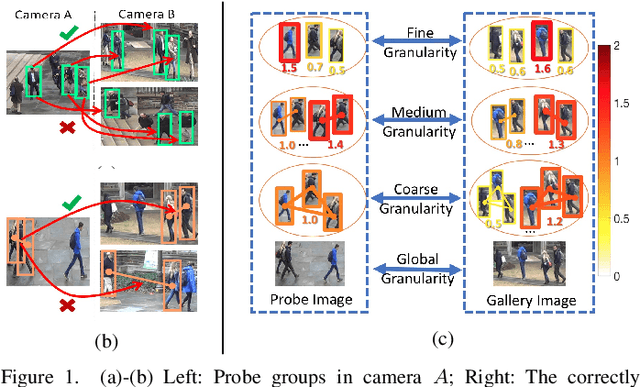
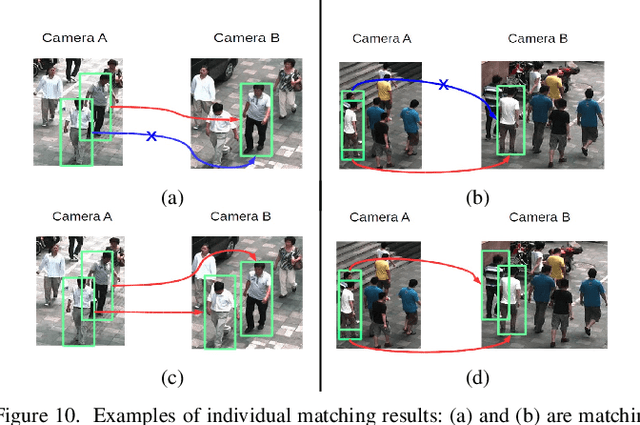
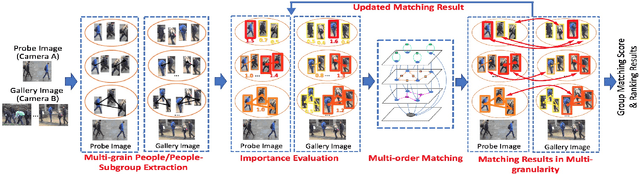
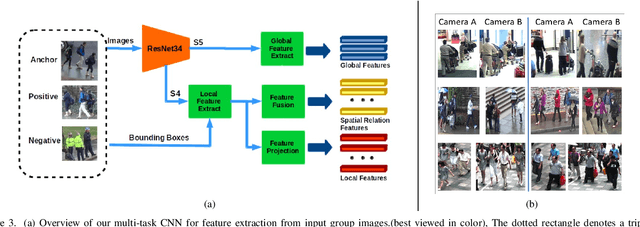
The task of re-identifying groups of people underdifferent camera views is an important yet less-studied problem.Group re-identification (Re-ID) is a very challenging task sinceit is not only adversely affected by common issues in traditionalsingle object Re-ID problems such as viewpoint and human posevariations, but it also suffers from changes in group layout andgroup membership. In this paper, we propose a novel conceptof group granularity by characterizing a group image by multi-grained objects: individual persons and sub-groups of two andthree people within a group. To achieve robust group Re-ID,we first introduce multi-grained representations which can beextracted via the development of two separate schemes, i.e. onewith hand-crafted descriptors and another with deep neuralnetworks. The proposed representation seeks to characterize bothappearance and spatial relations of multi-grained objects, and isfurther equipped with importance weights which capture varia-tions in intra-group dynamics. Optimal group-wise matching isfacilitated by a multi-order matching process which in turn,dynamically updates the importance weights in iterative fashion.We evaluated on three multi-camera group datasets containingcomplex scenarios and large dynamics, with experimental resultsdemonstrating the effectiveness of our approach. The published dataset can be found in \url{http://min.sjtu.edu.cn/lwydemo/GroupReID.html}
Towards Accurate One-Stage Object Detection with AP-Loss
Apr 12, 2019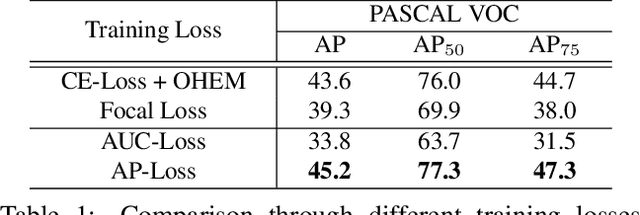
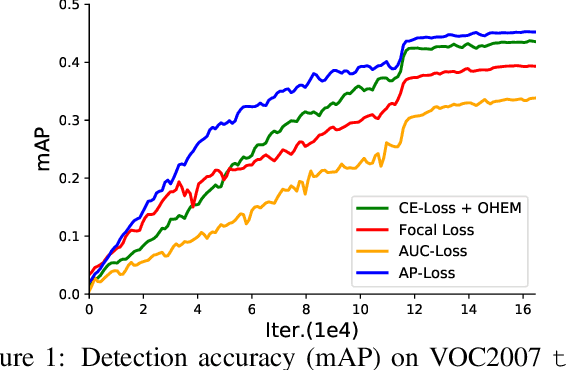
One-stage object detectors are trained by optimizing classification-loss and localization-loss simultaneously, with the former suffering much from extreme foreground-background class imbalance issue due to the large number of anchors. This paper alleviates this issue by proposing a novel framework to replace the classification task in one-stage detectors with a ranking task, and adopting the Average-Precision loss (AP-loss) for the ranking problem. Due to its non-differentiability and non-convexity, the AP-loss cannot be optimized directly. For this purpose, we develop a novel optimization algorithm, which seamlessly combines the error-driven update scheme in perceptron learning and backpropagation algorithm in deep networks. We verify good convergence property of the proposed algorithm theoretically and empirically. Experimental results demonstrate notable performance improvement in state-of-the-art one-stage detectors based on AP-loss over different kinds of classification-losses on various benchmarks, without changing the network architectures.
DNQ: Dynamic Network Quantization
Dec 06, 2018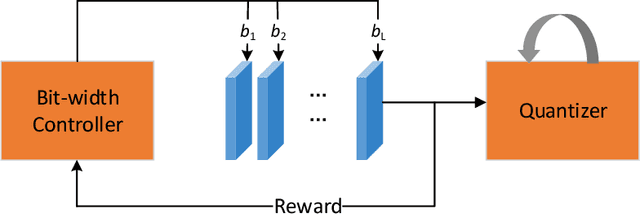
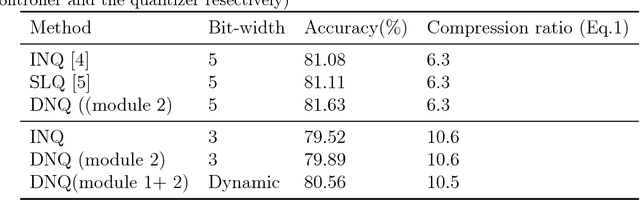
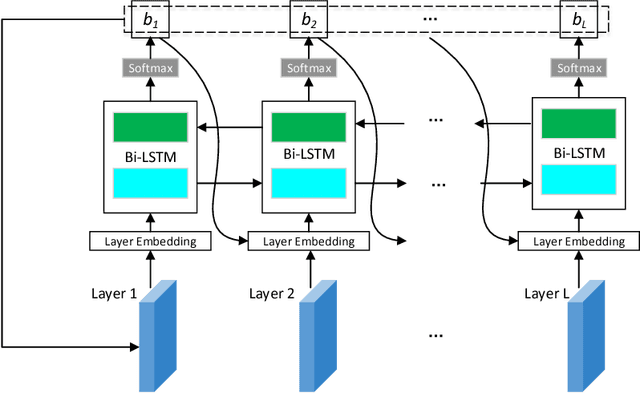
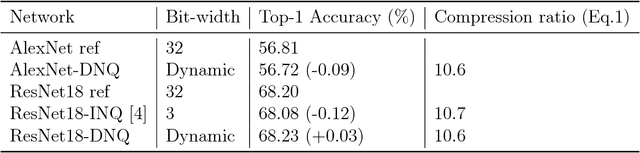
Network quantization is an effective method for the deployment of neural networks on memory and energy constrained mobile devices. In this paper, we propose a Dynamic Network Quantization (DNQ) framework which is composed of two modules: a bit-width controller and a quantizer. Unlike most existing quantization methods that use a universal quantization bit-width for the whole network, we utilize policy gradient to train an agent to learn the bit-width of each layer by the bit-width controller. This controller can make a trade-off between accuracy and compression ratio. Given the quantization bit-width sequence, the quantizer adopts the quantization distance as the criterion of the weights importance during quantization. We extensively validate the proposed approach on various main-stream neural networks and obtain impressive results.
Network Decoupling: From Regular to Depthwise Separable Convolutions
Aug 16, 2018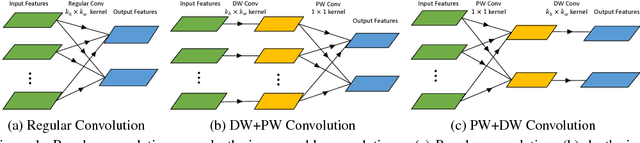
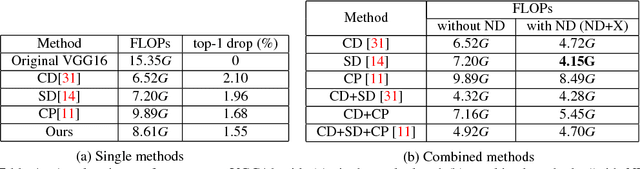
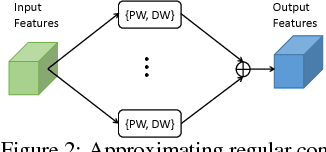
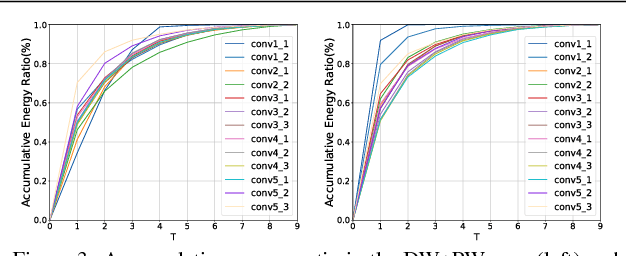
Depthwise separable convolution has shown great efficiency in network design, but requires time-consuming training procedure with full training-set available. This paper first analyzes the mathematical relationship between regular convolutions and depthwise separable convolutions, and proves that the former one could be approximated with the latter one in closed form. We show depthwise separable convolutions are principal components of regular convolutions. And then we propose network decoupling (ND), a training-free method to accelerate convolutional neural networks (CNNs) by transferring pre-trained CNN models into the MobileNet-like depthwise separable convolution structure, with a promising speedup yet negligible accuracy loss. We further verify through experiments that the proposed method is orthogonal to other training-free methods like channel decomposition, spatial decomposition, etc. Combining the proposed method with them will bring even larger CNN speedup. For instance, ND itself achieves about 2X speedup for the widely used VGG16, and combined with other methods, it reaches 3.7X speedup with graceful accuracy degradation. We demonstrate that ND is widely applicable to classification networks like ResNet, and object detection network like SSD300.
Tiny-DSOD: Lightweight Object Detection for Resource-Restricted Usages
Jul 29, 2018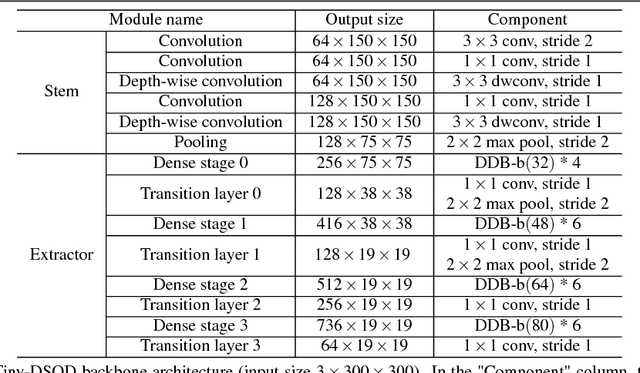

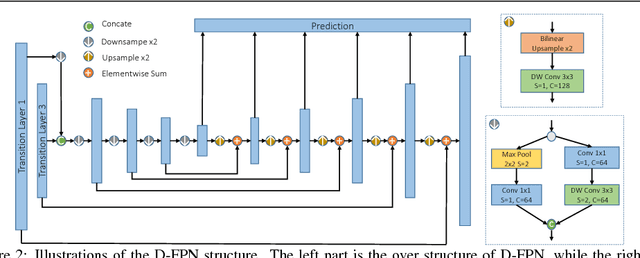

Object detection has made great progress in the past few years along with the development of deep learning. However, most current object detection methods are resource hungry, which hinders their wide deployment to many resource restricted usages such as usages on always-on devices, battery-powered low-end devices, etc. This paper considers the resource and accuracy trade-off for resource-restricted usages during designing the whole object detection framework. Based on the deeply supervised object detection (DSOD) framework, we propose Tiny-DSOD dedicating to resource-restricted usages. Tiny-DSOD introduces two innovative and ultra-efficient architecture blocks: depthwise dense block (DDB) based backbone and depthwise feature-pyramid-network (D-FPN) based front-end. We conduct extensive experiments on three famous benchmarks (PASCAL VOC 2007, KITTI, and COCO), and compare Tiny-DSOD to the state-of-the-art ultra-efficient object detection solutions such as Tiny-YOLO, MobileNet-SSD (v1 & v2), SqueezeDet, Pelee, etc. Results show that Tiny-DSOD outperforms these solutions in all the three metrics (parameter-size, FLOPs, accuracy) in each comparison. For instance, Tiny-DSOD achieves 72.1% mAP with only 0.95M parameters and 1.06B FLOPs, which is by far the state-of-the-arts result with such a low resource requirement.
Enriched Long-term Recurrent Convolutional Network for Facial Micro-Expression Recognition
May 22, 2018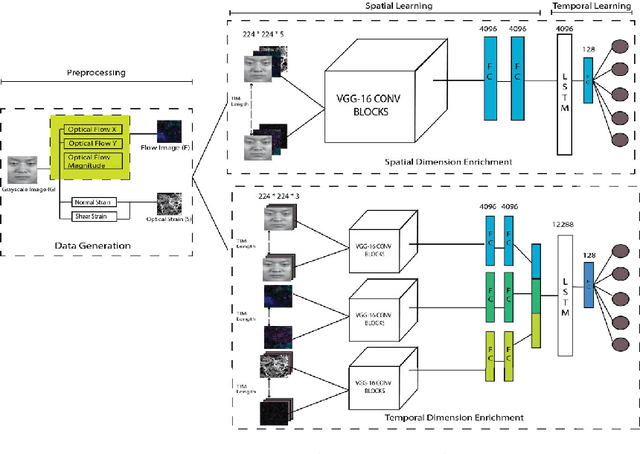
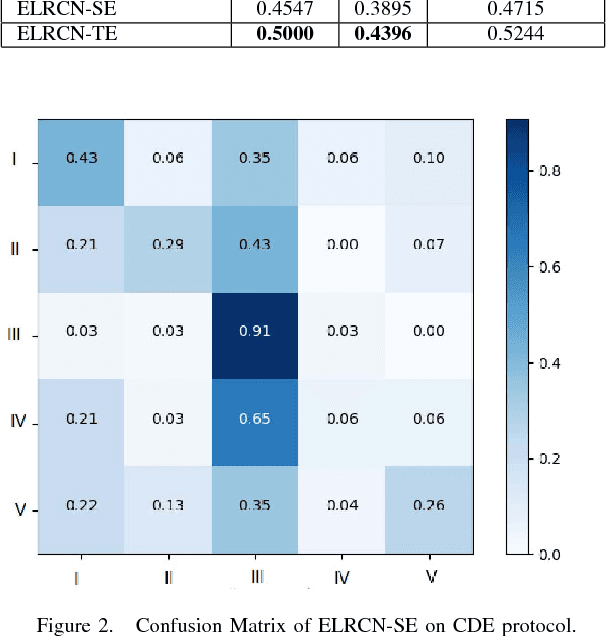
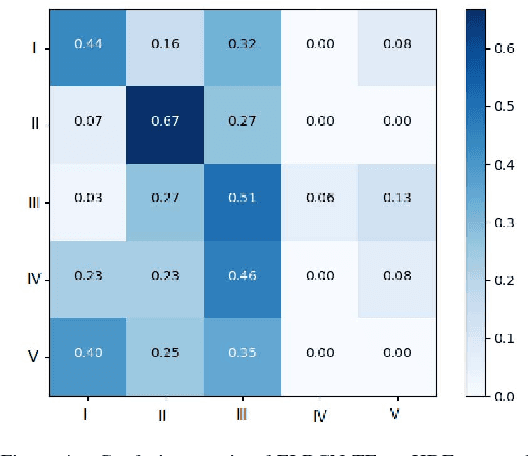
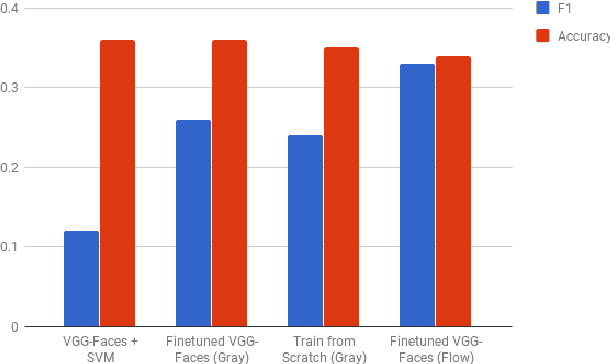
Facial micro-expression (ME) recognition has posed a huge challenge to researchers for its subtlety in motion and limited databases. Recently, handcrafted techniques have achieved superior performance in micro-expression recognition but at the cost of domain specificity and cumbersome parametric tunings. In this paper, we propose an Enriched Long-term Recurrent Convolutional Network (ELRCN) that first encodes each micro-expression frame into a feature vector through CNN module(s), then predicts the micro-expression by passing the feature vector through a Long Short-term Memory (LSTM) module. The framework contains two different network variants: (1) Channel-wise stacking of input data for spatial enrichment, (2) Feature-wise stacking of features for temporal enrichment. We demonstrate that the proposed approach is able to achieve reasonably good performance, without data augmentation. In addition, we also present ablation studies conducted on the framework and visualizations of what CNN "sees" when predicting the micro-expression classes.