 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarSLIP: Discovering Effective CLIP Adaptation for Fine-Grained Remote Sensing Understanding
Nov 18, 2025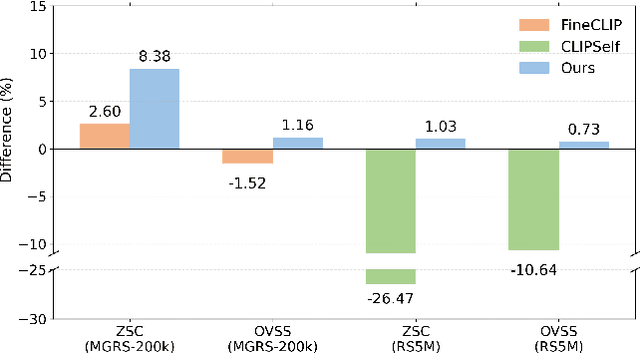
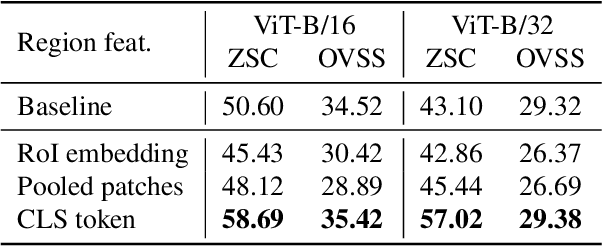
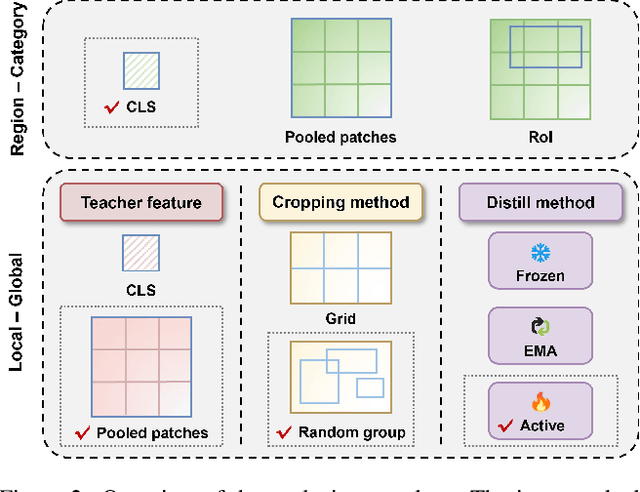
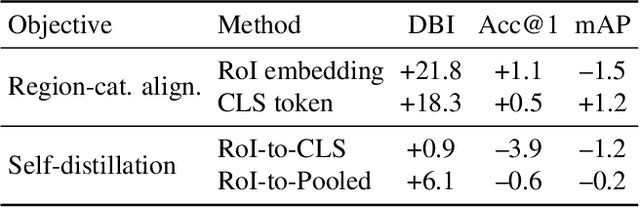
As CLIP's global alignment limits its ability to capture fine-grained details, recent efforts have focused on enhancing its region-text alignment. However, current remote sensing (RS)-specific CLIP variants still inherit this limited spatial awareness. We identify two key limitations behind this: (1) current RS image-text datasets generate global captions from object-level labels, leaving the original object-level supervision underutilized; (2) despite the success of region-text alignment methods in general domain, their direct application to RS data often leads to performance degradation. To address these, we construct the first multi-granularity RS image-text dataset, MGRS-200k, featuring rich object-level textual supervision for RS region-category alignment. We further investigate existing fine-grained CLIP tuning strategies and find that current explicit region-text alignment methods, whether in a direct or indirect way, underperform due to severe degradation of CLIP's semantic coherence. Building on these, we propose FarSLIP, a Fine-grained Aligned RS Language-Image Pretraining framework. Rather than the commonly used patch-to-CLS self-distillation, FarSLIP employs patch-to-patch distillation to align local and global visual cues, which improves feature discriminability while preserving semantic coherence. Additionally, to effectively utilize region-text supervision, it employs simple CLS token-based region-category alignment rather than explicit patch-level alignment, further enhancing spatial awareness. FarSLIP features improved fine-grained vision-language alignment in RS domain and sets a new state of the art not only on RS open-vocabulary semantic segmentation, but also on image-level tasks such as zero-shot classification and image-text retrieval. Our dataset, code, and models are available at https://github.com/NJU-LHRS/FarSLIP.
Geospatial Foundation Models to Enable Progress on Sustainable Development Goals
May 30, 2025Foundation Models (FMs) are large-scale, pre-trained AI systems that have revolutionized natural language processing and computer vision, and are now advancing geospatial analysis and Earth Observation (EO). They promise improved generalization across tasks, scalability, and efficient adaptation with minimal labeled data. However, despite the rapid proliferation of geospatial FMs, their real-world utility and alignment with global sustainability goals remain underexplored. We introduce SustainFM, a comprehensive benchmarking framework grounded in the 17 Sustainable Development Goals with extremely diverse tasks ranging from asset wealth prediction to environmental hazard detection. This study provides a rigorous, interdisciplinary assessment of geospatial FMs and offers critical insights into their role in attaining sustainability goals. Our findings show: (1) While not universally superior, FMs often outperform traditional approaches across diverse tasks and datasets. (2) Evaluating FMs should go beyond accuracy to include transferability, generalization, and energy efficiency as key criteria for their responsible use. (3) FMs enable scalable, SDG-grounded solutions, offering broad utility for tackling complex sustainability challenges. Critically, we advocate for a paradigm shift from model-centric development to impact-driven deployment, and emphasize metrics such as energy efficiency, robustness to domain shifts, and ethical considerations.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
GeoLangBind: Unifying Earth Observation with Agglomerative Vision-Language Foundation Models
Mar 08, 2025Earth observation (EO) data, collected from diverse sensors with varying imaging principles, present significant challenges in creating unified analytical frameworks. We present GeoLangBind, a novel agglomerative vision--language foundation model that bridges the gap between heterogeneous EO data modalities using language as a unifying medium. Our approach aligns different EO data types into a shared language embedding space, enabling seamless integration and complementary feature learning from diverse sensor data. To achieve this, we construct a large-scale multimodal image--text dataset, GeoLangBind-2M, encompassing six data modalities. GeoLangBind leverages this dataset to develop a zero-shot foundation model capable of processing arbitrary numbers of EO data channels as input. Through our designed Modality-aware Knowledge Agglomeration (MaKA) module and progressive multimodal weight merging strategy, we create a powerful agglomerative foundation model that excels in both zero-shot vision--language comprehension and fine-grained visual understanding. Extensive evaluation across 23 datasets covering multiple tasks demonstrates GeoLangBind's superior performance and versatility in EO applications, offering a robust framework for various environmental monitoring and analysis tasks. The dataset and pretrained models will be publicly available.
Change Captioning in Remote Sensing: Evolution to SAT-Cap -- A Single-Stage Transformer Approach
Jan 14, 2025

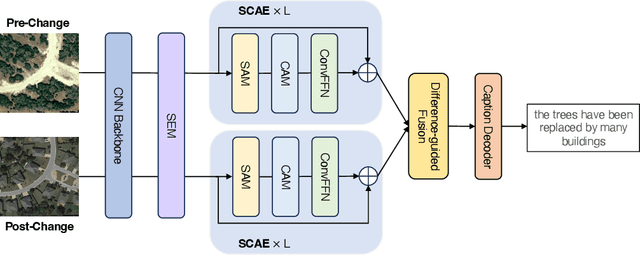

Change captioning has become essential for accurately describing changes in multi-temporal remote sensing data, providing an intuitive way to monitor Earth's dynamics through natural language. However, existing change captioning methods face two key challenges: high computational demands due to multistage fusion strategy, and insufficient detail in object descriptions due to limited semantic extraction from individual images. To solve these challenges, we propose SAT-Cap based on the transformers model with a single-stage feature fusion for remote sensing change captioning. In particular, SAT-Cap integrates a Spatial-Channel Attention Encoder, a Difference-Guided Fusion module, and a Caption Decoder. Compared to typical models that require multi-stage fusion in transformer encoder and fusion module, SAT-Cap uses only a simple cosine similarity-based fusion module for information integration, reducing the complexity of the model architecture. By jointly modeling spatial and channel information in Spatial-Channel Attention Encoder, our approach significantly enhances the model's ability to extract semantic information from objects in multi-temporal remote sensing images. Extensive experiments validate the effectiveness of SAT-Cap, achieving CIDEr scores of 140.23% on the LEVIR-CC dataset and 97.74% on the DUBAI-CC dataset, surpassing current state-of-the-art methods. The code and pre-trained models will be available online.
ChangeMinds: Multi-task Framework for Detecting and Describing Changes in Remote Sensing
Oct 15, 2024



Recent advancements in Remote Sensing (RS) for Change Detection (CD) and Change Captioning (CC) have seen substantial success by adopting deep learning techniques. Despite these advances, existing methods often handle CD and CC tasks independently, leading to inefficiencies from the absence of synergistic processing. In this paper, we present ChangeMinds, a novel unified multi-task framework that concurrently optimizes CD and CC processes within a single, end-to-end model. We propose the change-aware long short-term memory module (ChangeLSTM) to effectively capture complex spatiotemporal dynamics from extracted bi-temporal deep features, enabling the generation of universal change-aware representations that effectively serve both CC and CD tasks. Furthermore, we introduce a multi-task predictor with a cross-attention mechanism that enhances the interaction between image and text features, promoting efficient simultaneous learning and processing for both tasks. Extensive evaluations on the LEVIR-MCI dataset, alongside other standard benchmarks, show that ChangeMinds surpasses existing methods in multi-task learning settings and markedly improves performance in individual CD and CC tasks. Codes and pre-trained models will be available online.
MineNetCD: A Benchmark for Global Mining Change Detection on Remote Sensing Imagery
Jul 04, 2024



Monitoring changes triggered by mining activities is crucial for industrial controlling, environmental management and regulatory compliance, yet it poses significant challenges due to the vast and often remote locations of mining sites. Remote sensing technologies have increasingly become indispensable to detect and analyze these changes over time. We thus introduce MineNetCD, a comprehensive benchmark designed for global mining change detection using remote sensing imagery. The benchmark comprises three key contributions. First, we establish a global mining change detection dataset featuring more than 70k paired patches of bi-temporal high-resolution remote sensing images and pixel-level annotations from 100 mining sites worldwide. Second, we develop a novel baseline model based on a change-aware Fast Fourier Transform (ChangeFFT) module, which enhances various backbones by leveraging essential spectrum components within features in the frequency domain and capturing the channel-wise correlation of bi-temporal feature differences to learn change-aware representations. Third, we construct a unified change detection (UCD) framework that integrates over 13 advanced change detection models. This framework is designed for streamlined and efficient processing, utilizing the cloud platform hosted by HuggingFace. Extensive experiments have been conducted to demonstrate the superiority of the proposed baseline model compared with 12 state-of-the-art change detection approaches. Empirical studies on modularized backbones comprehensively confirm the efficacy of different representation learners on change detection. This contribution represents significant advancements in the field of remote sensing and change detection, providing a robust resource for future research and applications in global mining monitoring. Dataset and Codes are available via the link.
Responsible AI for Earth Observation
May 31, 2024The convergence of artificial intelligence (AI) and Earth observation (EO) technologies has brought geoscience and remote sensing into an era of unparalleled capabilities. AI's transformative impact on data analysis, particularly derived from EO platforms, holds great promise in addressing global challenges such as environmental monitoring, disaster response and climate change analysis. However, the rapid integration of AI necessitates a careful examination of the responsible dimensions inherent in its application within these domains. In this paper, we represent a pioneering effort to systematically define the intersection of AI and EO, with a central focus on responsible AI practices. Specifically, we identify several critical components guiding this exploration from both academia and industry perspectives within the EO field: AI and EO for social good, mitigating unfair biases, AI security in EO, geo-privacy and privacy-preserving measures, as well as maintaining scientific excellence, open data, and guiding AI usage based on ethical principles. Furthermore, the paper explores potential opportunities and emerging trends, providing valuable insights for future research endeavors.
MaskCD: A Remote Sensing Change Detection Network Based on Mask Classification
Apr 18, 2024



Change detection (CD) from remote sensing (RS) images using deep learning has been widely investigated in the literature. It is typically regarded as a pixel-wise labeling task that aims to classify each pixel as changed or unchanged. Although per-pixel classification networks in encoder-decoder structures have shown dominance, they still suffer from imprecise boundaries and incomplete object delineation at various scenes. For high-resolution RS images, partly or totally changed objects are more worthy of attention rather than a single pixel. Therefore, we revisit the CD task from the mask prediction and classification perspective and propose MaskCD to detect changed areas by adaptively generating categorized masks from input image pairs. Specifically, it utilizes a cross-level change representation perceiver (CLCRP) to learn multiscale change-aware representations and capture spatiotemporal relations from encoded features by exploiting deformable multihead self-attention (DeformMHSA). Subsequently, a masked-attention-based detection transformers (MA-DETR) decoder is developed to accurately locate and identify changed objects based on masked attention and self-attention mechanisms. It reconstructs the desired changed objects by decoding the pixel-wise representations into learnable mask proposals and making final predictions from these candidates. Experimental results on five benchmark datasets demonstrate the proposed approach outperforms other state-of-the-art models. Codes and pretrained models are available online (https://github.com/EricYu97/MaskCD).
Universal Adversarial Defense in Remote Sensing Based on Pre-trained Denoising Diffusion Models
Aug 02, 2023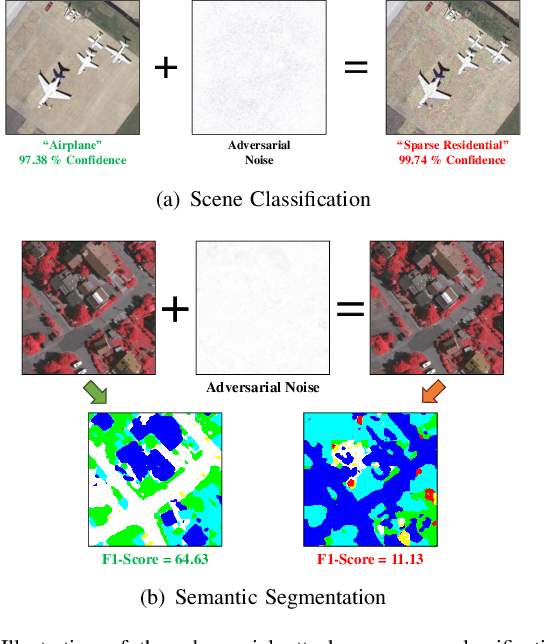
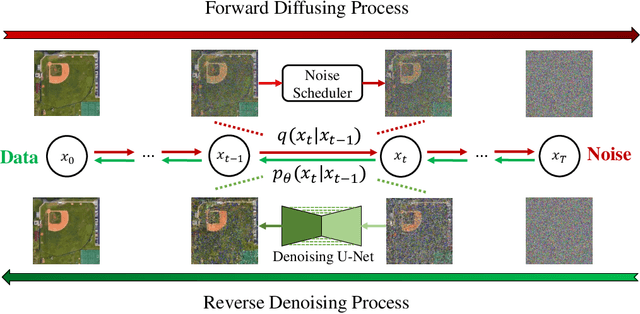
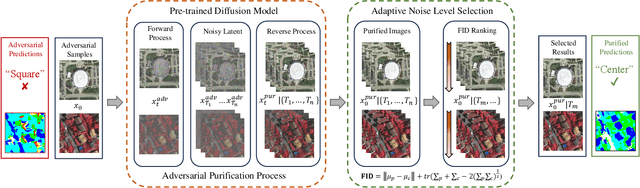

Deep neural networks (DNNs) have achieved tremendous success in many remote sensing (RS) applications, in which DNNs are vulnerable to adversarial perturbations. Unfortunately, current adversarial defense approaches in RS studies usually suffer from performance fluctuation and unnecessary re-training costs due to the need for prior knowledge of the adversarial perturbations among RS data. To circumvent these challenges, we propose a universal adversarial defense approach in RS imagery (UAD-RS) using pre-trained diffusion models to defend the common DNNs against multiple unknown adversarial attacks. Specifically, the generative diffusion models are first pre-trained on different RS datasets to learn generalized representations in various data domains. After that, a universal adversarial purification framework is developed using the forward and reverse process of the pre-trained diffusion models to purify the perturbations from adversarial samples. Furthermore, an adaptive noise level selection (ANLS) mechanism is built to capture the optimal noise level of the diffusion model that can achieve the best purification results closest to the clean samples according to their Frechet Inception Distance (FID) in deep feature space. As a result, only a single pre-trained diffusion model is needed for the universal purification of adversarial samples on each dataset, which significantly alleviates the re-training efforts and maintains high performance without prior knowledge of the adversarial perturbations. Experiments on four heterogeneous RS datasets regarding scene classification and semantic segmentation verify that UAD-RS outperforms state-of-the-art adversarial purification approaches with a universal defense against seven commonly existing adversarial perturbations. Codes and the pre-trained models are available online (https://github.com/EricYu97/UAD-RS).