 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D LULC classification using multispectral LiDAR and deep learning: current and prospective schemes
May 21, 2026Land Use Land Cover (LULC) classification is essential for national 3D mapping, geospatial analysis, and sustainable planning. Multispectral (MS) LiDAR provides synchronized spatial-spectral information, and deep learning (DL) enables 3D point cloud semantic segmentation; however, adoption is limited by the lack of publicly available urban and suburban MS LiDAR datasets aligned with National Mapping and Cadastral Agencies (NMCAs) classification schemes. This study addresses these gaps by introducing L1 and L2 NMCA-aligned LULC classification schemes and a new benchmark MS LiDAR dataset. We evaluate seven state-of-the-art DL models and perform spectral ablation studies at both levels of detail. Results show that Point Transformer V3 achieves the best performance, with mIoU of 79.4% (L1, 8 classes) and 58.9% (L2, 20 classes) using a dual-wavelength LiDAR system (532 nm and 1064 nm). Ablation results show that multispectral information improves performance over geometry-only inputs, with gains of 1.1 percentage points at L1 and 7.8 points at L2. These results highlight the value of LiDAR reflectance for fine-grained material discrimination and support the evolution of NMCA LULC schemes toward higher semantic detail. The Loosdorf-MSL dataset contributes a new benchmark for consistent national and international LULC mapping.
Label-Efficient 3D Forest Mapping: Self-Supervised and Transfer Learning for Individual, Structural, and Species Analysis
Nov 09, 2025



Detailed structural and species information on individual tree level is increasingly important to support precision forestry, biodiversity conservation, and provide reference data for biomass and carbon mapping. Point clouds from airborne and ground-based laser scanning are currently the most suitable data source to rapidly derive such information at scale. Recent advancements in deep learning improved segmenting and classifying individual trees and identifying semantic tree components. However, deep learning models typically require large amounts of annotated training data which limits further improvement. Producing dense, high-quality annotations for 3D point clouds, especially in complex forests, is labor-intensive and challenging to scale. We explore strategies to reduce dependence on large annotated datasets using self-supervised and transfer learning architectures. Our objective is to improve performance across three tasks: instance segmentation, semantic segmentation, and tree classification using realistic and operational training sets. Our findings indicate that combining self-supervised learning with domain adaptation significantly enhances instance segmentation compared to training from scratch (AP50 +16.98%), self-supervised learning suffices for semantic segmentation (mIoU +1.79%), and hierarchical transfer learning enables accurate classification of unseen species (Jaccard +6.07%). To simplify use and encourage uptake, we integrated the tasks into a unified framework, streamlining the process from raw point clouds to tree delineation, structural analysis, and species classification. Pretrained models reduce energy consumption and carbon emissions by ~21%. This open-source contribution aims to accelerate operational extraction of individual tree information from laser scanning point clouds to support forestry, biodiversity, and carbon mapping.
Geospatial Foundation Models to Enable Progress on Sustainable Development Goals
May 30, 2025Foundation Models (FMs) are large-scale, pre-trained AI systems that have revolutionized natural language processing and computer vision, and are now advancing geospatial analysis and Earth Observation (EO). They promise improved generalization across tasks, scalability, and efficient adaptation with minimal labeled data. However, despite the rapid proliferation of geospatial FMs, their real-world utility and alignment with global sustainability goals remain underexplored. We introduce SustainFM, a comprehensive benchmarking framework grounded in the 17 Sustainable Development Goals with extremely diverse tasks ranging from asset wealth prediction to environmental hazard detection. This study provides a rigorous, interdisciplinary assessment of geospatial FMs and offers critical insights into their role in attaining sustainability goals. Our findings show: (1) While not universally superior, FMs often outperform traditional approaches across diverse tasks and datasets. (2) Evaluating FMs should go beyond accuracy to include transferability, generalization, and energy efficiency as key criteria for their responsible use. (3) FMs enable scalable, SDG-grounded solutions, offering broad utility for tackling complex sustainability challenges. Critically, we advocate for a paradigm shift from model-centric development to impact-driven deployment, and emphasize metrics such as energy efficiency, robustness to domain shifts, and ethical considerations.
HyperPointFormer: Multimodal Fusion in 3D Space with Dual-Branch Cross-Attention Transformers
May 29, 2025
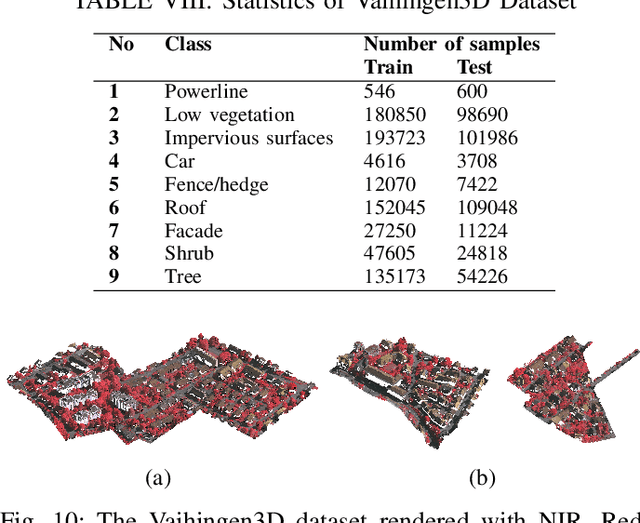
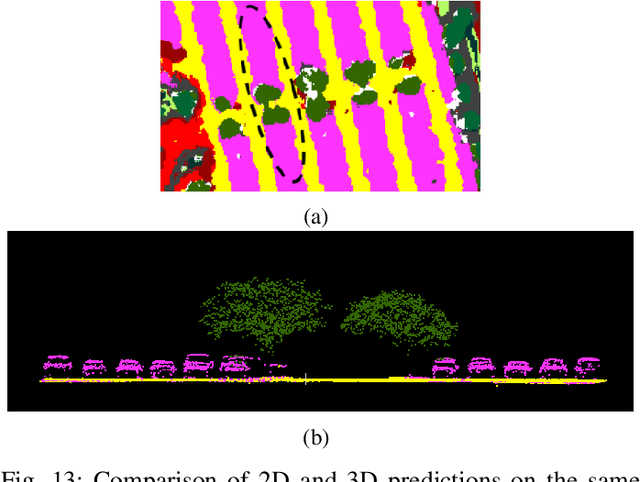
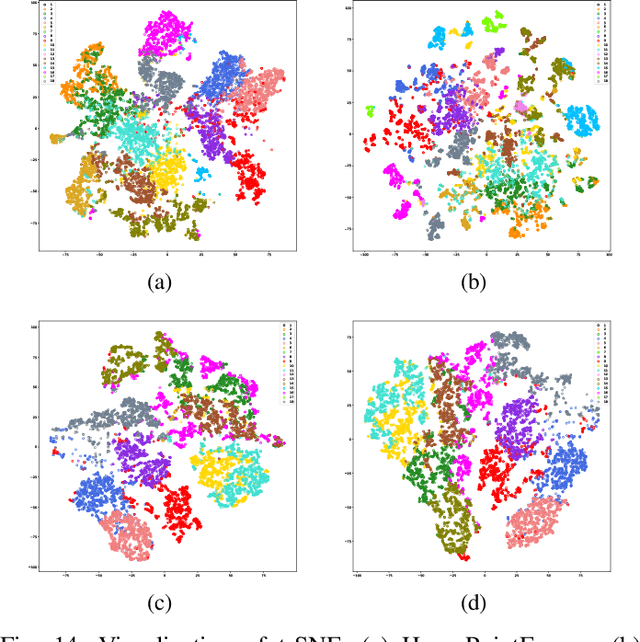
Multimodal remote sensing data, including spectral and lidar or photogrammetry, is crucial for achieving satisfactory land-use / land-cover classification results in urban scenes. So far, most studies have been conducted in a 2D context. When 3D information is available in the dataset, it is typically integrated with the 2D data by rasterizing the 3D data into 2D formats. Although this method yields satisfactory classification results, it falls short in fully exploiting the potential of 3D data by restricting the model's ability to learn 3D spatial features directly from raw point clouds. Additionally, it limits the generation of 3D predictions, as the dimensionality of the input data has been reduced. In this study, we propose a fully 3D-based method that fuses all modalities within the 3D point cloud and employs a dedicated dual-branch Transformer model to simultaneously learn geometric and spectral features. To enhance the fusion process, we introduce a cross-attention-based mechanism that fully operates on 3D points, effectively integrating features from various modalities across multiple scales. The purpose of cross-attention is to allow one modality to assess the importance of another by weighing the relevant features. We evaluated our method by comparing it against both 3D and 2D methods using the 2018 IEEE GRSS Data Fusion Contest (DFC2018) dataset. Our findings indicate that 3D fusion delivers competitive results compared to 2D methods and offers more flexibility by providing 3D predictions. These predictions can be projected onto 2D maps, a capability that is not feasible in reverse. Additionally, we evaluated our method on different datasets, specifically the ISPRS Vaihingen 3D and the IEEE 2019 Data Fusion Contest. Our code will be published here: https://github.com/aldinorizaldy/hyperpointformer.