 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarVerseLOD: High-Fidelity 3D Garment Reconstruction from a Single In-the-Wild Image using a Dataset with Levels of Details
Nov 05, 2024



Neural implicit functions have brought impressive advances to the state-of-the-art of clothed human digitization from multiple or even single images. However, despite the progress, current arts still have difficulty generalizing to unseen images with complex cloth deformation and body poses. In this work, we present GarVerseLOD, a new dataset and framework that paves the way to achieving unprecedented robustness in high-fidelity 3D garment reconstruction from a single unconstrained image. Inspired by the recent success of large generative models, we believe that one key to addressing the generalization challenge lies in the quantity and quality of 3D garment data. Towards this end, GarVerseLOD collects 6,000 high-quality cloth models with fine-grained geometry details manually created by professional artists. In addition to the scale of training data, we observe that having disentangled granularities of geometry can play an important role in boosting the generalization capability and inference accuracy of the learned model. We hence craft GarVerseLOD as a hierarchical dataset with levels of details (LOD), spanning from detail-free stylized shape to pose-blended garment with pixel-aligned details. This allows us to make this highly under-constrained problem tractable by factorizing the inference into easier tasks, each narrowed down with smaller searching space. To ensure GarVerseLOD can generalize well to in-the-wild images, we propose a novel labeling paradigm based on conditional diffusion models to generate extensive paired images for each garment model with high photorealism. We evaluate our method on a massive amount of in-the-wild images. Experimental results demonstrate that GarVerseLOD can generate standalone garment pieces with significantly better quality than prior approaches. Project page: https://garverselod.github.io/
MarvelOVD: Marrying Object Recognition and Vision-Language Models for Robust Open-Vocabulary Object Detection
Jul 31, 2024



Learning from pseudo-labels that generated with VLMs~(Vision Language Models) has been shown as a promising solution to assist open vocabulary detection (OVD) in recent studies. However, due to the domain gap between VLM and vision-detection tasks, pseudo-labels produced by the VLMs are prone to be noisy, while the training design of the detector further amplifies the bias. In this work, we investigate the root cause of VLMs' biased prediction under the OVD context. Our observations lead to a simple yet effective paradigm, coded MarvelOVD, that generates significantly better training targets and optimizes the learning procedure in an online manner by marrying the capability of the detector with the vision-language model. Our key insight is that the detector itself can act as a strong auxiliary guidance to accommodate VLM's inability of understanding both the ``background'' and the context of a proposal within the image. Based on it, we greatly purify the noisy pseudo-labels via Online Mining and propose Adaptive Reweighting to effectively suppress the biased training boxes that are not well aligned with the target object. In addition, we also identify a neglected ``base-novel-conflict'' problem and introduce stratified label assignments to prevent it. Extensive experiments on COCO and LVIS datasets demonstrate that our method outperforms the other state-of-the-arts by significant margins. Codes are available at https://github.com/wkfdb/MarvelOVD
OVER-NAV: Elevating Iterative Vision-and-Language Navigation with Open-Vocabulary Detection and StructurEd Representation
Mar 26, 2024Recent advances in Iterative Vision-and-Language Navigation (IVLN) introduce a more meaningful and practical paradigm of VLN by maintaining the agent's memory across tours of scenes. Although the long-term memory aligns better with the persistent nature of the VLN task, it poses more challenges on how to utilize the highly unstructured navigation memory with extremely sparse supervision. Towards this end, we propose OVER-NAV, which aims to go over and beyond the current arts of IVLN techniques. In particular, we propose to incorporate LLMs and open-vocabulary detectors to distill key information and establish correspondence between multi-modal signals. Such a mechanism introduces reliable cross-modal supervision and enables on-the-fly generalization to unseen scenes without the need of extra annotation and re-training. To fully exploit the interpreted navigation data, we further introduce a structured representation, coded Omnigraph, to effectively integrate multi-modal information along the tour. Accompanied with a novel omnigraph fusion mechanism, OVER-NAV is able to extract the most relevant knowledge from omnigraph for a more accurate navigating action. In addition, OVER-NAV seamlessly supports both discrete and continuous environments under a unified framework. We demonstrate the superiority of OVER-NAV in extensive experiments.
Divide and Adapt: Active Domain Adaptation via Customized Learning
Jul 21, 2023



Active domain adaptation (ADA) aims to improve the model adaptation performance by incorporating active learning (AL) techniques to label a maximally-informative subset of target samples. Conventional AL methods do not consider the existence of domain shift, and hence, fail to identify the truly valuable samples in the context of domain adaptation. To accommodate active learning and domain adaption, the two naturally different tasks, in a collaborative framework, we advocate that a customized learning strategy for the target data is the key to the success of ADA solutions. We present Divide-and-Adapt (DiaNA), a new ADA framework that partitions the target instances into four categories with stratified transferable properties. With a novel data subdivision protocol based on uncertainty and domainness, DiaNA can accurately recognize the most gainful samples. While sending the informative instances for annotation, DiaNA employs tailored learning strategies for the remaining categories. Furthermore, we propose an informativeness score that unifies the data partitioning criteria. This enables the use of a Gaussian mixture model (GMM) to automatically sample unlabeled data into the proposed four categories. Thanks to the "divideand-adapt" spirit, DiaNA can handle data with large variations of domain gap. In addition, we show that DiaNA can generalize to different domain adaptation settings, such as unsupervised domain adaptation (UDA), semi-supervised domain adaptation (SSDA), source-free domain adaptation (SFDA), etc.
NeUDF: Leaning Neural Unsigned Distance Fields with Volume Rendering
Apr 20, 2023Multi-view shape reconstruction has achieved impressive progresses thanks to the latest advances in neural implicit surface rendering. However, existing methods based on signed distance function (SDF) are limited to closed surfaces, failing to reconstruct a wide range of real-world objects that contain open-surface structures. In this work, we introduce a new neural rendering framework, coded NeUDF, that can reconstruct surfaces with arbitrary topologies solely from multi-view supervision. To gain the flexibility of representing arbitrary surfaces, NeUDF leverages the unsigned distance function (UDF) as surface representation. While a naive extension of an SDF-based neural renderer cannot scale to UDF, we propose two new formulations of weight function specially tailored for UDF-based volume rendering. Furthermore, to cope with open surface rendering, where the in/out test is no longer valid, we present a dedicated normal regularization strategy to resolve the surface orientation ambiguity. We extensively evaluate our method over a number of challenging datasets, including DTU}, MGN, and Deep Fashion 3D. Experimental results demonstrate that nEudf can significantly outperform the state-of-the-art method in the task of multi-view surface reconstruction, especially for complex shapes with open boundaries.
NerVE: Neural Volumetric Edges for Parametric Curve Extraction from Point Cloud
Mar 29, 2023



Extracting parametric edge curves from point clouds is a fundamental problem in 3D vision and geometry processing. Existing approaches mainly rely on keypoint detection, a challenging procedure that tends to generate noisy output, making the subsequent edge extraction error-prone. To address this issue, we propose to directly detect structured edges to circumvent the limitations of the previous point-wise methods. We achieve this goal by presenting NerVE, a novel neural volumetric edge representation that can be easily learned through a volumetric learning framework. NerVE can be seamlessly converted to a versatile piece-wise linear (PWL) curve representation, enabling a unified strategy for learning all types of free-form curves. Furthermore, as NerVE encodes rich structural information, we show that edge extraction based on NerVE can be reduced to a simple graph search problem. After converting NerVE to the PWL representation, parametric curves can be obtained via off-the-shelf spline fitting algorithms. We evaluate our method on the challenging ABC dataset. We show that a simple network based on NerVE can already outperform the previous state-of-the-art methods by a great margin. Project page: https://dongdu3.github.io/projects/2023/NerVE/.
NeAT: Learning Neural Implicit Surfaces with Arbitrary Topologies from Multi-view Images
Mar 21, 2023



Recent progress in neural implicit functions has set new state-of-the-art in reconstructing high-fidelity 3D shapes from a collection of images. However, these approaches are limited to closed surfaces as they require the surface to be represented by a signed distance field. In this paper, we propose NeAT, a new neural rendering framework that can learn implicit surfaces with arbitrary topologies from multi-view images. In particular, NeAT represents the 3D surface as a level set of a signed distance function (SDF) with a validity branch for estimating the surface existence probability at the query positions. We also develop a novel neural volume rendering method, which uses SDF and validity to calculate the volume opacity and avoids rendering points with low validity. NeAT supports easy field-to-mesh conversion using the classic Marching Cubes algorithm. Extensive experiments on DTU, MGN, and Deep Fashion 3D datasets indicate that our approach is able to faithfully reconstruct both watertight and non-watertight surfaces. In particular, NeAT significantly outperforms the state-of-the-art methods in the task of open surface reconstruction both quantitatively and qualitatively.
Get3DHuman: Lifting StyleGAN-Human into a 3D Generative Model using Pixel-aligned Reconstruction Priors
Feb 11, 2023Fast generation of high-quality 3D digital humans is important to a vast number of applications ranging from entertainment to professional concerns. Recent advances in differentiable rendering have enabled the training of 3D generative models without requiring 3D ground truths. However, the quality of the generated 3D humans still has much room to improve in terms of both fidelity and diversity. In this paper, we present Get3DHuman, a novel 3D human framework that can significantly boost the realism and diversity of the generated outcomes by only using a limited budget of 3D ground-truth data. Our key observation is that the 3D generator can profit from human-related priors learned through 2D human generators and 3D reconstructors. Specifically, we bridge the latent space of Get3DHuman with that of StyleGAN-Human via a specially-designed prior network, where the input latent code is mapped to the shape and texture feature volumes spanned by the pixel-aligned 3D reconstructor. The outcomes of the prior network are then leveraged as the supervisory signals for the main generator network. To ensure effective training, we further propose three tailored losses applied to the generated feature volumes and the intermediate feature maps. Extensive experiments demonstrate that Get3DHuman greatly outperforms the other state-of-the-art approaches and can support a wide range of applications including shape interpolation, shape re-texturing, and single-view reconstruction through latent inversion.
Divide and Contrast: Source-free Domain Adaptation via Adaptive Contrastive Learning
Nov 12, 2022



We investigate a practical domain adaptation task, called source-free domain adaptation (SFUDA), where the source-pretrained model is adapted to the target domain without access to the source data. Existing techniques mainly leverage self-supervised pseudo labeling to achieve class-wise global alignment [1] or rely on local structure extraction that encourages feature consistency among neighborhoods [2]. While impressive progress has been made, both lines of methods have their own drawbacks - the "global" approach is sensitive to noisy labels while the "local" counterpart suffers from source bias. In this paper, we present Divide and Contrast (DaC), a new paradigm for SFUDA that strives to connect the good ends of both worlds while bypassing their limitations. Based on the prediction confidence of the source model, DaC divides the target data into source-like and target-specific samples, where either group of samples is treated with tailored goals under an adaptive contrastive learning framework. Specifically, the source-like samples are utilized for learning global class clustering thanks to their relatively clean labels. The more noisy target-specific data are harnessed at the instance level for learning the intrinsic local structures. We further align the source-like domain with the target-specific samples using a memory bank-based Maximum Mean Discrepancy (MMD) loss to reduce the distribution mismatch. Extensive experiments on VisDA, Office-Home, and the more challenging DomainNet have verified the superior performance of DaC over current state-of-the-art approaches. The code is available at https://github.com/ZyeZhang/DaC.git.
3PSDF: Three-Pole Signed Distance Function for Learning Surfaces with Arbitrary Topologies
May 31, 2022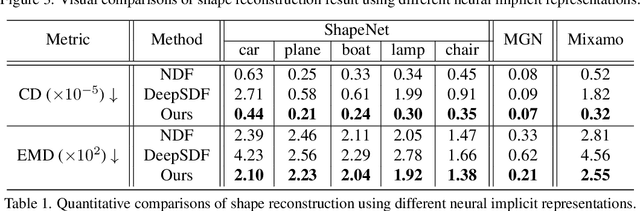
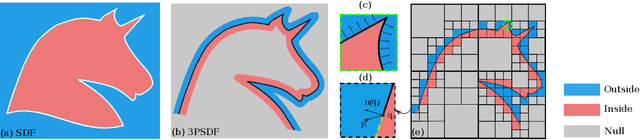
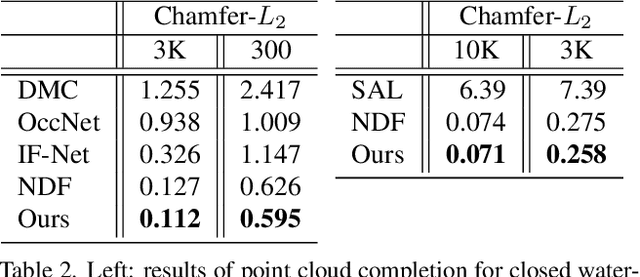
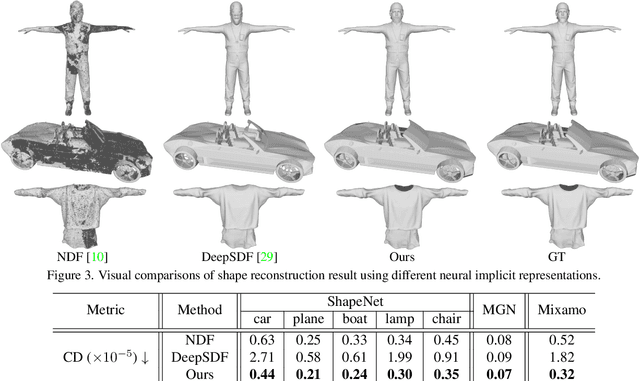
Recent advances in learning 3D shapes using neural implicit functions have achieved impressive results by breaking the previous barrier of resolution and diversity for varying topologies. However, most of such approaches are limited to closed surfaces as they require the space to be divided into inside and outside. More recent works based on unsigned distance function have been proposed to handle complex geometry containing both the open and closed surfaces. Nonetheless, as their direct outputs are point clouds, robustly obtaining high-quality meshing results from discrete points remains an open question. We present a novel learnable implicit representation, called the three-pole signed distance function (3PSDF), that can represent non-watertight 3D shapes with arbitrary topologies while supporting easy field-to-mesh conversion using the classic Marching Cubes algorithm. The key to our method is the introduction of a new sign, the NULL sign, in addition to the conventional in and out labels. The existence of the null sign could stop the formation of a closed isosurface derived from the bisector of the in/out regions. Further, we propose a dedicated learning framework to effectively learn 3PSDF without worrying about the vanishing gradient due to the null labels. Experimental results show that our approach outperforms the previous state-of-the-art methods in a wide range of benchmarks both quantitatively and qualitatively.