 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversational Recommender System and Large Language Model Are Made for Each Other in E-commerce Pre-sales Dialogue
Oct 23, 2023



E-commerce pre-sales dialogue aims to understand and elicit user needs and preferences for the items they are seeking so as to provide appropriate recommendations. Conversational recommender systems (CRSs) learn user representation and provide accurate recommendations based on dialogue context, but rely on external knowledge. Large language models (LLMs) generate responses that mimic pre-sales dialogues after fine-tuning, but lack domain-specific knowledge for accurate recommendations. Intuitively, the strengths of LLM and CRS in E-commerce pre-sales dialogues are complementary, yet no previous work has explored this. This paper investigates the effectiveness of combining LLM and CRS in E-commerce pre-sales dialogues, proposing two collaboration methods: CRS assisting LLM and LLM assisting CRS. We conduct extensive experiments on a real-world dataset of Ecommerce pre-sales dialogues. We analyze the impact of two collaborative approaches with two CRSs and two LLMs on four tasks of Ecommerce pre-sales dialogue. We find that collaborations between CRS and LLM can be very effective in some cases.
U-NEED: A Fine-grained Dataset for User Needs-Centric E-commerce Conversational Recommendation
May 05, 2023



Conversational recommender systems (CRSs) aim to understand the information needs and preferences expressed in a dialogue to recommend suitable items to the user. Most of the existing conversational recommendation datasets are synthesized or simulated with crowdsourcing, which has a large gap with real-world scenarios. To bridge the gap, previous work contributes a dataset E-ConvRec, based on pre-sales dialogues between users and customer service staff in E-commerce scenarios. However, E-ConvRec only supplies coarse-grained annotations and general tasks for making recommendations in pre-sales dialogues. Different from that, we use real user needs as a clue to explore the E-commerce conversational recommendation in complex pre-sales dialogues, namely user needs-centric E-commerce conversational recommendation (UNECR). In this paper, we construct a user needs-centric E-commerce conversational recommendation dataset (U-NEED) from real-world E-commerce scenarios. U-NEED consists of 3 types of resources: (i) 7,698 fine-grained annotated pre-sales dialogues in 5 top categories (ii) 333,879 user behaviors and (iii) 332,148 product knowledge tuples. To facilitate the research of UNECR, we propose 5 critical tasks: (i) pre-sales dialogue understanding (ii) user needs elicitation (iii) user needs-based recommendation (iv) pre-sales dialogue generation and (v) pre-sales dialogue evaluation. We establish baseline methods and evaluation metrics for each task. We report experimental results of 5 tasks on U-NEED. We also report results in 3 typical categories. Experimental results indicate that the challenges of UNECR in various categories are different.
A General Framework for Debiasing in CTR Prediction
Dec 06, 2021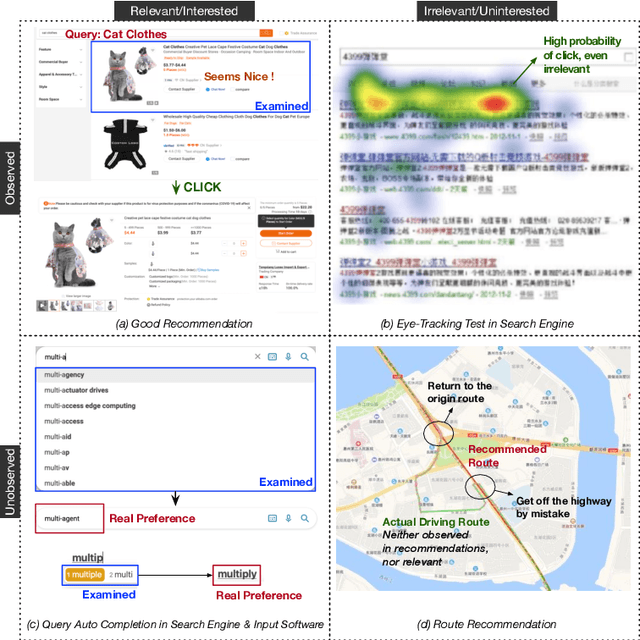
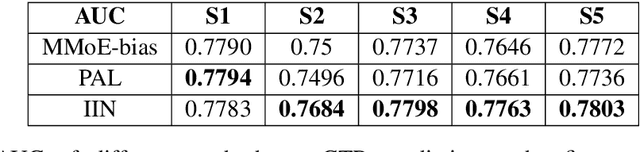
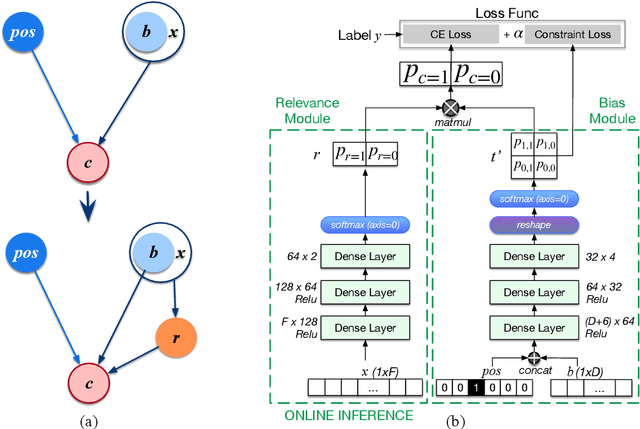
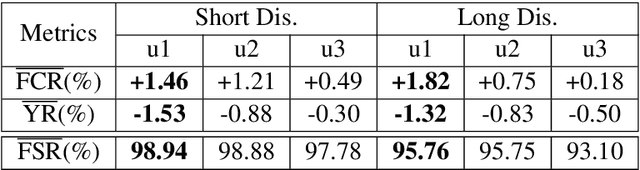
Most of the existing methods for debaising in click-through rate (CTR) prediction depend on an oversimplified assumption, i.e., the click probability is the product of observation probability and relevance probability. However, since there is a complicated interplay between these two probabilities, these methods cannot be applied to other scenarios, e.g. query auto completion (QAC) and route recommendation. We propose a general debiasing framework without simplifying the relationships between variables, which can handle all scenarios in CTR prediction. Simulation experiments show that: under the simplest scenario, our method maintains a similar AUC with the state-of-the-art methods; in other scenarios, our method achieves considerable improvements compared with existing methods. Meanwhile, in online experiments, the framework also gains significant improvements consistently.
R4: A Framework for Route Representation and Route Recommendation
Oct 25, 2021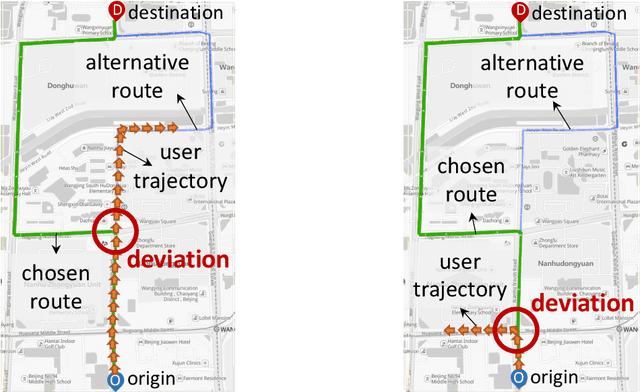
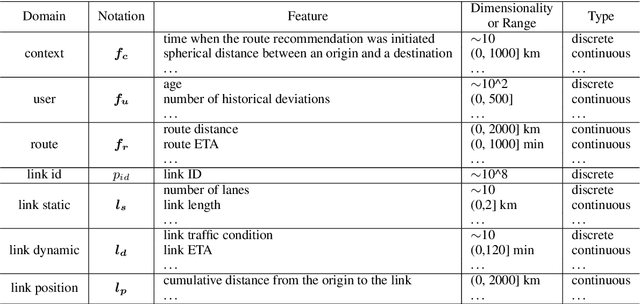
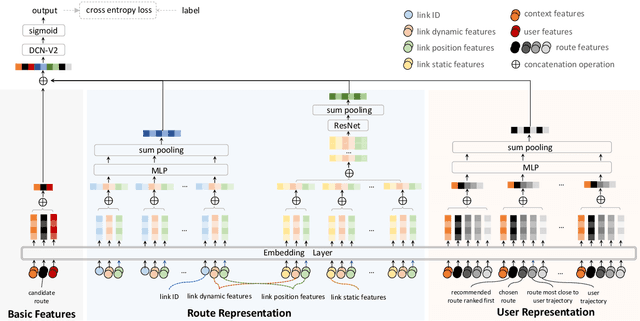

Route recommendation is significant in navigation service. Two major challenges for route recommendation are route representation and user representation. Different from items that can be identified by unique IDs in traditional recommendation, routes are combinations of links (i.e., a road segment and its following action like turning left) and the number of combinations could be close to infinite. Besides, the representation of a route changes under different scenarios. These facts result in severe sparsity of routes, which increases the difficulty of route representation. Moreover, link attribute deficiencies and errors affect preciseness of route representation. Because of the sparsity of routes, the interaction data between users and routes are also sparse. This makes it not easy to acquire user representation from historical user-item interactions as traditional recommendations do. To address these issues, we propose a novel learning framework R4. In R4, we design a sparse & dense network to obtain representations of routes. The sparse unit learns link ID embeddings and aggregates them to represent a route, which captures implicit route characteristics and subsequently alleviates problems caused by link attribute deficiencies and errors. The dense unit extracts implicit local features of routes from link attributes. For user representation, we utilize a series of historical navigation to extract user preference. R4 achieves remarkable performance in both offline and online experiments.
Local Contextual Attention with Hierarchical Structure for Dialogue Act Recognition
Mar 12, 2020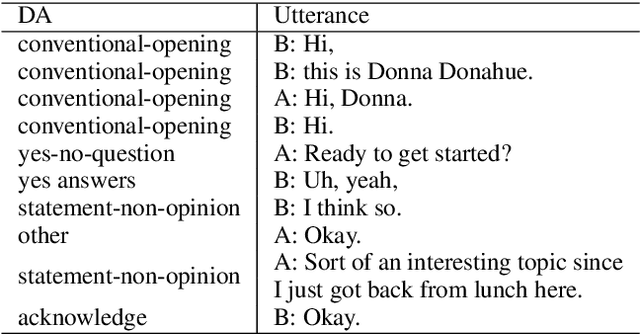
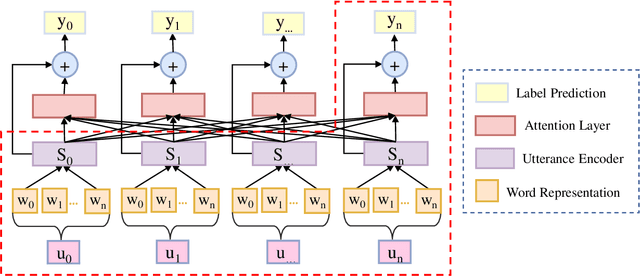
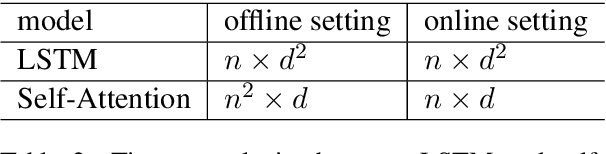
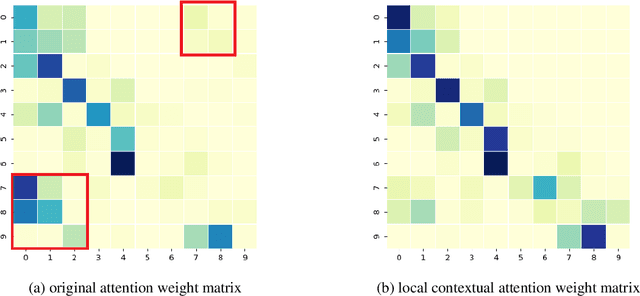
Dialogue act recognition is a fundamental task for an intelligent dialogue system. Previous work models the whole dialog to predict dialog acts, which may bring the noise from unrelated sentences. In this work, we design a hierarchical model based on self-attention to capture intra-sentence and inter-sentence information. We revise the attention distribution to focus on the local and contextual semantic information by incorporating the relative position information between utterances. Based on the found that the length of dialog affects the performance, we introduce a new dialog segmentation mechanism to analyze the effect of dialog length and context padding length under online and offline settings. The experiment shows that our method achieves promising performance on two datasets: Switchboard Dialogue Act and DailyDialog with the accuracy of 80.34\% and 85.81\% respectively. Visualization of the attention weights shows that our method can learn the context dependency between utterances explicitly.