 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Sound Change Over Time: A Review of Computational and Human Perception
Jul 06, 2024Computational and human perception are often considered separate approaches for studying sound changes over time; few works have touched on the intersection of both. To fill this research gap, we provide a pioneering review contrasting computational with human perception from the perspectives of methods and tasks. Overall, computational approaches rely on computer-driven models to perceive historical sound changes on etymological datasets, while human approaches use listener-driven models to perceive ongoing sound changes on recording corpora. Despite their differences, both approaches complement each other on phonetic and acoustic levels, showing the potential to achieve a more comprehensive perception of sound change. Moreover, we call for a comparative study on the datasets used by both approaches to investigate the influence of historical sound changes on ongoing changes. Lastly, we discuss the applications of sound change in computational linguistics, and point out that perceiving sound change alone is insufficient, as many processes of language change are complex, with entangled changes at syntactic, semantic, and phonetic levels.
Exploring Diachronic and Diatopic Changes in Dialect Continua: Tasks, Datasets and Challenges
Jul 04, 2024Everlasting contact between language communities leads to constant changes in languages over time, and gives rise to language varieties and dialects. However, the communities speaking non-standard language are often overlooked by non-inclusive NLP technologies. Recently, there has been a surge of interest in studying diatopic and diachronic changes in dialect NLP, but there is currently no research exploring the intersection of both. Our work aims to fill this gap by systematically reviewing diachronic and diatopic papers from a unified perspective. In this work, we critically assess nine tasks and datasets across five dialects from three language families (Slavic, Romance, and Germanic) in both spoken and written modalities. The tasks covered are diverse, including corpus construction, dialect distance estimation, and dialect geolocation prediction, among others. Moreover, we outline five open challenges regarding changes in dialect use over time, the reliability of dialect datasets, the importance of speaker characteristics, limited coverage of dialects, and ethical considerations in data collection. We hope that our work sheds light on future research towards inclusive computational methods and datasets for language varieties and dialects.
Lost in UNet: Improving Infrared Small Target Detection by Underappreciated Local Features
Jun 19, 2024



Many targets are often very small in infrared images due to the long-distance imaging meachnism. UNet and its variants, as popular detection backbone networks, downsample the local features early and cause the irreversible loss of these local features, leading to both the missed and false detection of small targets in infrared images. We propose HintU, a novel network to recover the local features lost by various UNet-based methods for effective infrared small target detection. HintU has two key contributions. First, it introduces the "Hint" mechanism for the first time, i.e., leveraging the prior knowledge of target locations to highlight critical local features. Second, it improves the mainstream UNet-based architecture to preserve target pixels even after downsampling. HintU can shift the focus of various networks (e.g., vanilla UNet, UNet++, UIUNet, MiM+, and HCFNet) from the irrelevant background pixels to a more restricted area from the beginning. Experimental results on three datasets NUDT-SIRST, SIRSTv2 and IRSTD1K demonstrate that HintU enhances the performance of existing methods with only an additional 1.88 ms cost (on RTX Titan). Additionally, the explicit constraints of HintU enhance the generalization ability of UNet-based methods. Code is available at https://github.com/Wuzhou-Quan/HintU.
Enhancing Criminal Case Matching through Diverse Legal Factors
Jun 17, 2024



Criminal case matching endeavors to determine the relevance between different criminal cases. Conventional methods predict the relevance solely based on instance-level semantic features and neglect the diverse legal factors (LFs), which are associated with diverse court judgments. Consequently, comprehensively representing a criminal case remains a challenge for these approaches. Moreover, extracting and utilizing these LFs for criminal case matching face two challenges: (1) the manual annotations of LFs rely heavily on specialized legal knowledge; (2) overlaps among LFs may potentially harm the model's performance. In this paper, we propose a two-stage framework named Diverse Legal Factor-enhanced Criminal Case Matching (DLF-CCM). Firstly, DLF-CCM employs a multi-task learning framework to pre-train an LF extraction network on a large-scale legal judgment prediction dataset. In stage two, DLF-CCM introduces an LF de-redundancy module to learn shared LF and exclusive LFs. Moreover, an entropy-weighted fusion strategy is introduced to dynamically fuse the multiple relevance generated by all LFs. Experimental results validate the effectiveness of DLF-CCM and show its significant improvements over competitive baselines. Code: https://github.com/jiezhao6/DLF-CCM.
Towards Efficient Target-Level Machine Unlearning Based on Essential Graph
Jun 16, 2024



Machine unlearning is an emerging technology that has come to attract widespread attention. A number of factors, including regulations and laws, privacy, and usability concerns, have resulted in this need to allow a trained model to forget some of its training data. Existing studies of machine unlearning mainly focus on unlearning requests that forget a cluster of instances or all instances from one class. While these approaches are effective in removing instances, they do not scale to scenarios where partial targets within an instance need to be forgotten. For example, one would like to only unlearn a person from all instances that simultaneously contain the person and other targets. Directly migrating instance-level unlearning to target-level unlearning will reduce the performance of the model after the unlearning process, or fail to erase information completely. To address these concerns, we have proposed a more effective and efficient unlearning scheme that focuses on removing partial targets from the model, which we name "target unlearning". Specifically, we first construct an essential graph data structure to describe the relationships between all important parameters that are selected based on the model explanation method. After that, we simultaneously filter parameters that are also important for the remaining targets and use the pruning-based unlearning method, which is a simple but effective solution to remove information about the target that needs to be forgotten. Experiments with different training models on various datasets demonstrate the effectiveness of the proposed approach.
Stepwise Regression and Pre-trained Edge for Robust Stereo Matching
Jun 11, 2024
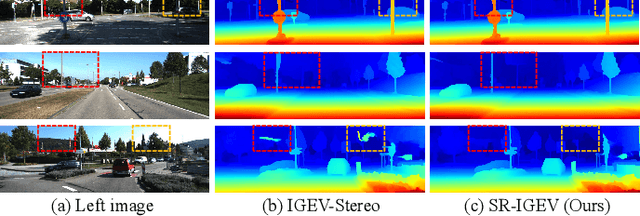
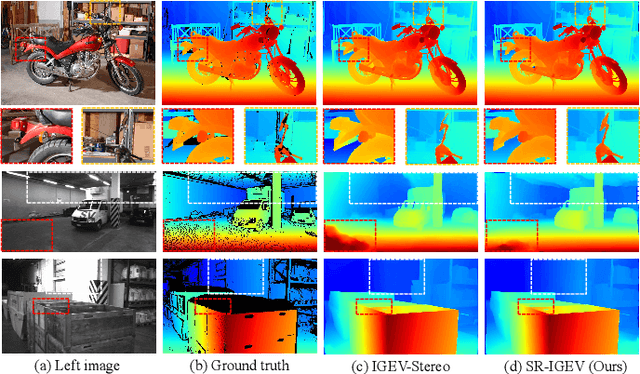
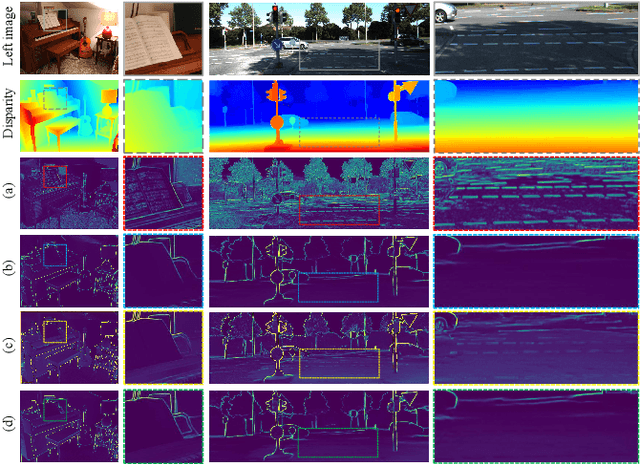
Due to the difficulty in obtaining real samples and ground truth, the generalization performance and the fine-tuned performance are critical for the feasibility of stereo matching methods in real-world applications. However, the presence of substantial disparity distributions and density variations across different datasets presents significant challenges for the generalization and fine-tuning of the model. In this paper, we propose a novel stereo matching method, called SR-Stereo, which mitigates the distributional differences across different datasets by predicting the disparity clips and uses a loss weight related to the regression target scale to improve the accuracy of the disparity clips. Moreover, this stepwise regression architecture can be easily extended to existing iteration-based methods to improve the performance without changing the structure. In addition, to mitigate the edge blurring of the fine-tuned model on sparse ground truth, we propose Domain Adaptation Based on Pre-trained Edges (DAPE). Specifically, we use the predicted disparity and RGB image to estimate the edge map of the target domain image. The edge map is filtered to generate edge map background pseudo-labels, which together with the sparse ground truth disparity on the target domain are used as a supervision to jointly fine-tune the pre-trained stereo matching model. These proposed methods are extensively evaluated on SceneFlow, KITTI, Middbury 2014 and ETH3D. The SR-Stereo achieves competitive disparity estimation performance and state-of-the-art cross-domain generalisation performance. Meanwhile, the proposed DAPE significantly improves the disparity estimation performance of fine-tuned models, especially in the textureless and detail regions.
SC2: Towards Enhancing Content Preservation and Style Consistency in Long Text Style Transfer
Jun 07, 2024Text style transfer (TST) aims to vary the style polarity of text while preserving the semantic content. Although recent advancements have demonstrated remarkable progress in short TST, it remains a relatively straightforward task with limited practical applications. The more comprehensive long TST task presents two challenges: (1) existing methods encounter difficulties in accurately evaluating content attributes in multiple words, leading to content degradation; (2) the conventional vanilla style classifier loss encounters obstacles in maintaining consistent style across multiple generated sentences. In this paper, we propose a novel method SC2, where a multilayer Joint Style-Content Weighed (JSCW) module and a Style Consistency loss are designed to address the two issues. The JSCW simultaneously assesses the amounts of style and content attributes within a token, aiming to acquire a lossless content representation and thereby enhancing content preservation. The multiple JSCW layers further progressively refine content representations. We design a style consistency loss to ensure the generated multiple sentences consistently reflect the target style polarity. Moreover, we incorporate a denoising non-autoregressive decoder to accelerate the training. We conduct plentiful experiments and the results show significant improvements of SC2 over competitive baselines. Our code: https://github.com/jiezhao6/SC2.
C^2RV: Cross-Regional and Cross-View Learning for Sparse-View CBCT Reconstruction
Jun 06, 2024Cone beam computed tomography (CBCT) is an important imaging technology widely used in medical scenarios, such as diagnosis and preoperative planning. Using fewer projection views to reconstruct CT, also known as sparse-view reconstruction, can reduce ionizing radiation and further benefit interventional radiology. Compared with sparse-view reconstruction for traditional parallel/fan-beam CT, CBCT reconstruction is more challenging due to the increased dimensionality caused by the measurement process based on cone-shaped X-ray beams. As a 2D-to-3D reconstruction problem, although implicit neural representations have been introduced to enable efficient training, only local features are considered and different views are processed equally in previous works, resulting in spatial inconsistency and poor performance on complicated anatomies. To this end, we propose C^2RV by leveraging explicit multi-scale volumetric representations to enable cross-regional learning in the 3D space. Additionally, the scale-view cross-attention module is introduced to adaptively aggregate multi-scale and multi-view features. Extensive experiments demonstrate that our C^2RV achieves consistent and significant improvement over previous state-of-the-art methods on datasets with diverse anatomy.
Presence or Absence: Are Unknown Word Usages in Dictionaries?
Jun 02, 2024



In this work, we outline the components and results of our system submitted to the AXOLOTL-24 shared task for Finnish, Russian and German languages. Our system is fully unsupervised. It leverages a graph-based clustering approach to predict mappings between unknown word usages and dictionary entries for Subtask 1, and generates dictionary-like definitions for those novel word usages through the state-of-the-art Large Language Models such as GPT-4 and LLaMA-3 for Subtask 2. In Subtask 1, our system outperforms the baseline system by a large margin, and it offers interpretability for the mapping results by distinguishing between matched and unmatched (novel) word usages through our graph-based clustering approach. Our system ranks first in Finnish and German, and ranks second in Russian on the Subtask 2 test-phase leaderboard. These results show the potential of our system in managing dictionary entries, particularly for updating dictionaries to include novel sense entries. Our code and data are made publicly available\footnote{\url{https://github.com/xiaohemaikoo/axolotl24-ABDN-NLP}}.
AdaGMLP: AdaBoosting GNN-to-MLP Knowledge Distillation
May 23, 2024



Graph Neural Networks (GNNs) have revolutionized graph-based machine learning, but their heavy computational demands pose challenges for latency-sensitive edge devices in practical industrial applications. In response, a new wave of methods, collectively known as GNN-to-MLP Knowledge Distillation, has emerged. They aim to transfer GNN-learned knowledge to a more efficient MLP student, which offers faster, resource-efficient inference while maintaining competitive performance compared to GNNs. However, these methods face significant challenges in situations with insufficient training data and incomplete test data, limiting their applicability in real-world applications. To address these challenges, we propose AdaGMLP, an AdaBoosting GNN-to-MLP Knowledge Distillation framework. It leverages an ensemble of diverse MLP students trained on different subsets of labeled nodes, addressing the issue of insufficient training data. Additionally, it incorporates a Node Alignment technique for robust predictions on test data with missing or incomplete features. Our experiments on seven benchmark datasets with different settings demonstrate that AdaGMLP outperforms existing G2M methods, making it suitable for a wide range of latency-sensitive real-world applications. We have submitted our code to the GitHub repository (https://github.com/WeigangLu/AdaGMLP-KDD24).
* Accepted by KDD 2024