 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Enhancement with Intelligent Neural Homomorphic Synthesis
Oct 28, 2022



Most neural network speech enhancement models ignore speech production mathematical models by directly mapping Fourier transform spectrums or waveforms. In this work, we propose a neural source filter network for speech enhancement. Specifically, we use homomorphic signal processing and cepstral analysis to obtain noisy speech's excitation and vocal tract. Unlike traditional signal processing, we use an attentive recurrent network (ARN) model predicted ratio mask to replace the liftering separation function. Then two convolutional attentive recurrent network (CARN) networks are used to predict the excitation and vocal tract of clean speech, respectively. The system's output is synthesized from the estimated excitation and vocal. Experiments prove that our proposed method performs better, with SI-SNR improving by 1.363dB compared to FullSubNet.
Local-global speaker representation for target speaker extraction
Oct 28, 2022



Target speaker extraction is to extract the target speaker's voice from a mixture of signals according to the given enrollment utterance. The target speaker's enrollment utterance is also called as anchor speech. The effective utilization of anchor speech is crucial for speaker extraction. In this study, we propose a new system to exploit speaker information from anchor speech fully. Unlike models that use only local or global features of the anchor, the proposed method extracts speaker information on global and local levels and feeds the features into a speech separation network. Our approach benefits from the complementary advantages of both global and local features, and the performance of speaker extraction is improved. We verified the feasibility of this local-global representation (LGR) method using multiple speaker extraction models. Systematic experiments were conducted on the open-source dataset Libri-2talker, and the results showed that the proposed method significantly outperformed the baseline models.
spatial-dccrn: dccrn equipped with frame-level angle feature and hybrid filtering for multi-channel speech enhancement
Oct 17, 2022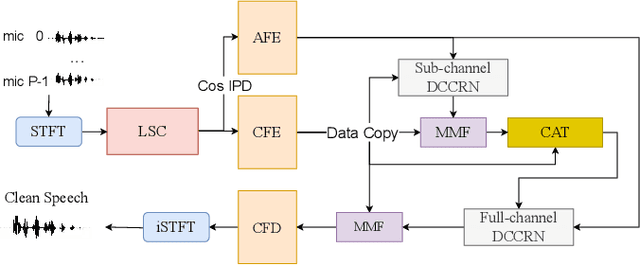
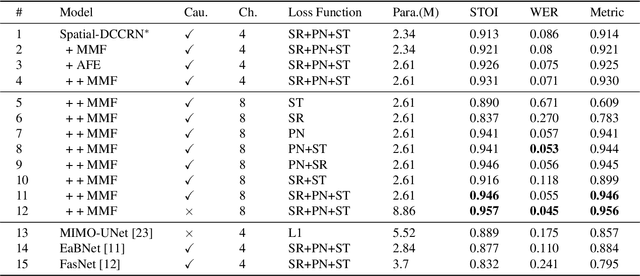
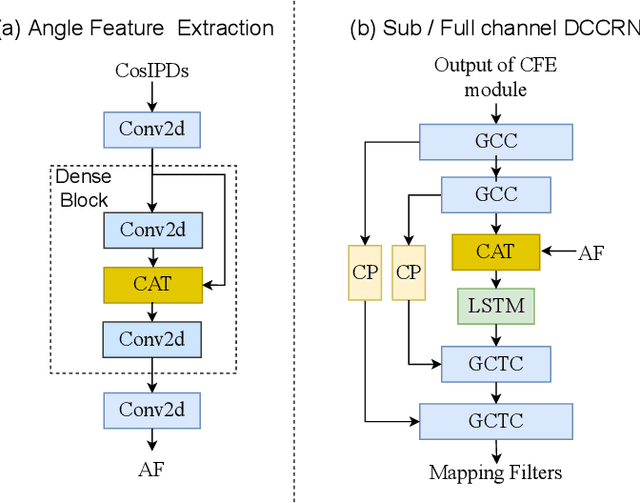
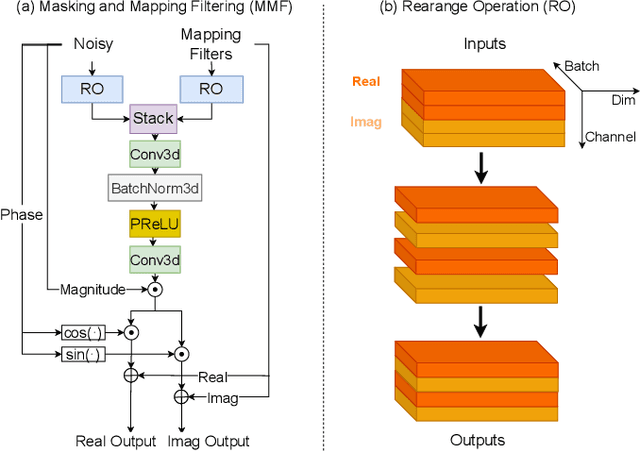
Recently, multi-channel speech enhancement has drawn much interest due to the use of spatial information to distinguish target speech from interfering signal. To make full use of spatial information and neural network based masking estimation, we propose a multi-channel denoising neural network -- Spatial DCCRN. Firstly, we extend S-DCCRN to multi-channel scenario, aiming at performing cascaded sub-channel and full-channel processing strategy, which can model different channels separately. Moreover, instead of only adopting multi-channel spectrum or concatenating first-channel's magnitude and IPD as the model's inputs, we apply an angle feature extraction module (AFE) to extract frame-level angle feature embeddings, which can help the model to apparently perceive spatial information. Finally, since the phenomenon of residual noise will be more serious when the noise and speech exist in the same time frequency (TF) bin, we particularly design a masking and mapping filtering method to substitute the traditional filter-and-sum operation, with the purpose of cascading coarsely denoising, dereverberation and residual noise suppression. The proposed model, Spatial-DCCRN, has surpassed EaBNet, FasNet as well as several competitive models on the L3DAS22 Challenge dataset. Not only the 3D scenario, Spatial-DCCRN outperforms state-of-the-art (SOTA) model MIMO-UNet by a large margin in multiple evaluation metrics on the multi-channel ConferencingSpeech2021 Challenge dataset. Ablation studies also demonstrate the effectiveness of different contributions.
Improving Channel Decorrelation for Multi-Channel Target Speech Extraction
Jun 06, 2021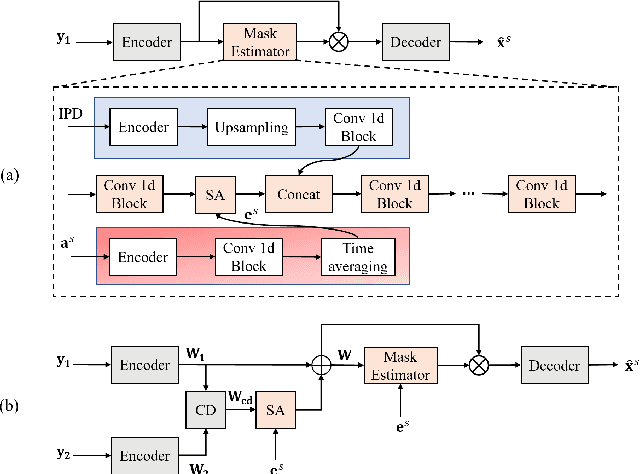
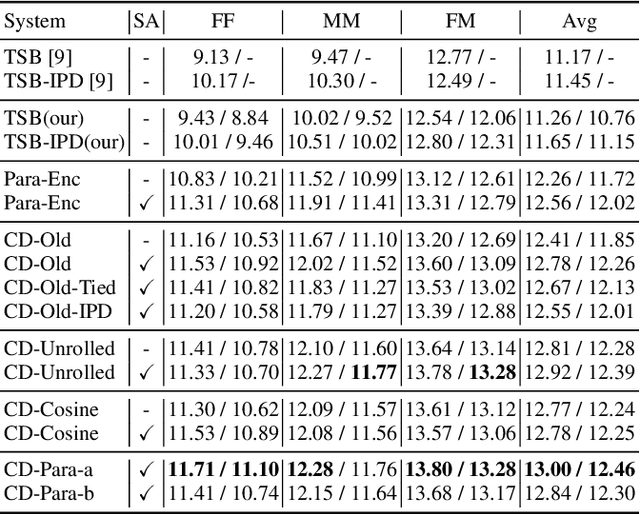
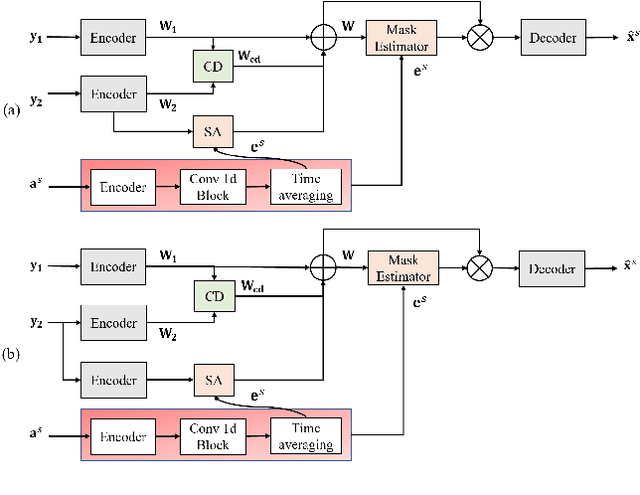
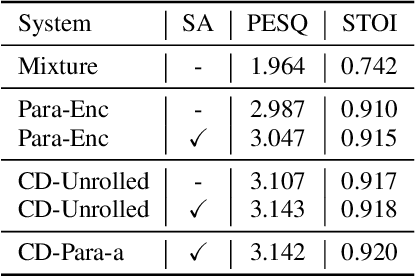
Target speech extraction has attracted widespread attention. When microphone arrays are available, the additional spatial information can be helpful in extracting the target speech. We have recently proposed a channel decorrelation (CD) mechanism to extract the inter-channel differential information to enhance the reference channel encoder representation. Although the proposed mechanism has shown promising results for extracting the target speech from mixtures, the extraction performance is still limited by the nature of the original decorrelation theory. In this paper, we propose two methods to broaden the horizon of the original channel decorrelation, by replacing the original softmax-based inter-channel similarity between encoder representations, using an unrolled probability and a normalized cosine-based similarity at the dimensional-level. Moreover, new combination strategies of the CD-based spatial information and target speaker adaptation of parallel encoder outputs are also investigated. Experiments on the reverberant WSJ0 2-mix show that the improved CD can result in more discriminative differential information and the new adaptation strategy is also very effective to improve the target speech extraction.
INTERSPEECH 2021 ConferencingSpeech Challenge: Towards Far-field Multi-Channel Speech Enhancement for Video Conferencing
Apr 02, 2021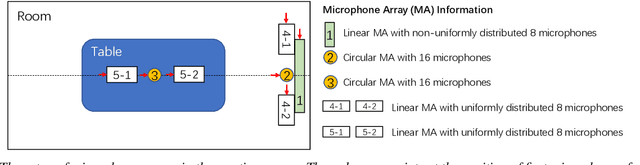
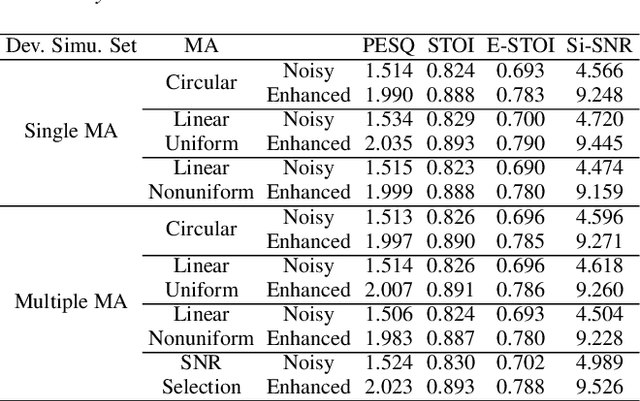

The ConferencingSpeech 2021 challenge is proposed to stimulate research on far-field multi-channel speech enhancement for video conferencing. The challenge consists of two separate tasks: 1) Task 1 is multi-channel speech enhancement with single microphone array and focusing on practical application with real-time requirement and 2) Task 2 is multi-channel speech enhancement with multiple distributed microphone arrays, which is a non-real-time track and does not have any constraints so that participants could explore any algorithms to obtain high speech quality. Targeting the real video conferencing room application, the challenge database was recorded from real speakers and all recording facilities were located by following the real setup of conferencing room. In this challenge, we open-sourced the list of open source clean speech and noise datasets, simulation scripts, and a baseline system for participants to develop their own system. The final ranking of the challenge will be decided by the subjective evaluation which is performed using Absolute Category Ratings (ACR) to estimate Mean Opinion Score (MOS), speech MOS (S-MOS), and noise MOS (N-MOS). This paper describes the challenge, tasks, datasets, and subjective evaluation. The baseline system which is a complex ratio mask based neural network and its experimental results are also presented.
Target Speaker Verification with Selective Auditory Attention for Single and Multi-talker Speech
Apr 02, 2021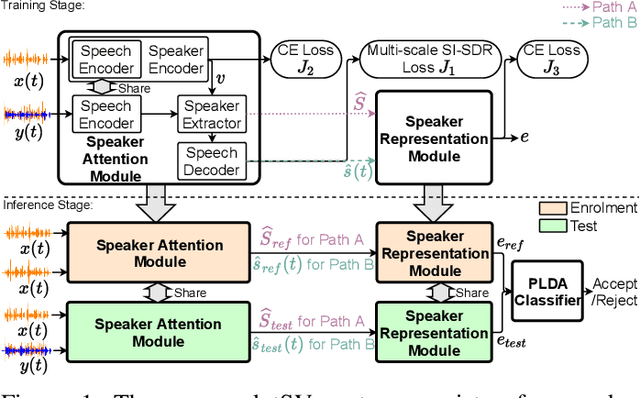
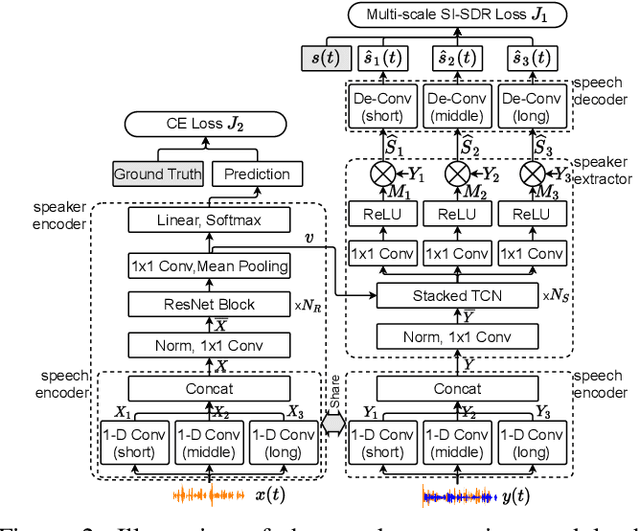
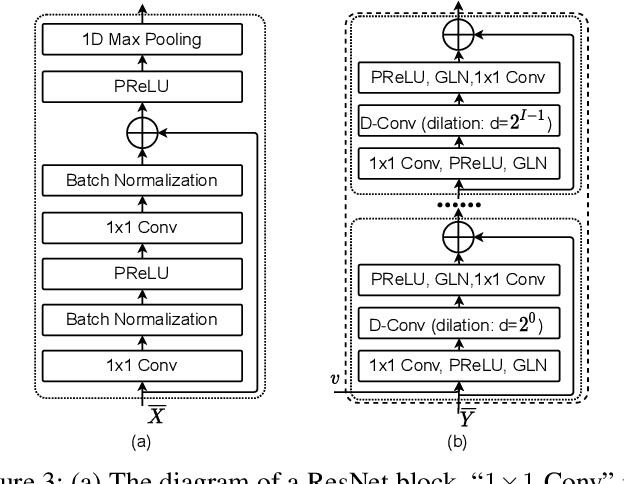
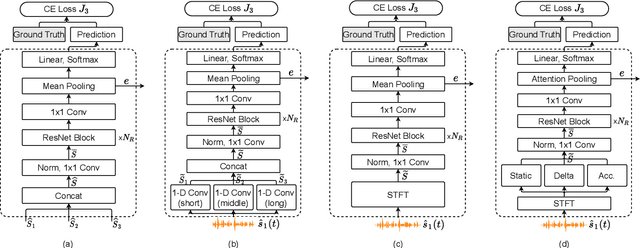
Speaker verification has been studied mostly under the single-talker condition. It is adversely affected in the presence of interference speakers. Inspired by the study on target speaker extraction, e.g., SpEx, we propose a unified speaker verification framework for both single- and multi-talker speech, that is able to pay selective auditory attention to the target speaker. This target speaker verification (tSV) framework jointly optimizes a speaker attention module and a speaker representation module via multi-task learning. We study four different target speaker embedding schemes under the tSV framework. The experimental results show that all four target speaker embedding schemes significantly outperform other competitive solutions for multi-talker speech. Notably, the best tSV speaker embedding scheme achieves 76.0% and 55.3% relative improvements over the baseline system on the WSJ0-2mix-extr and Libri2Mix corpora in terms of equal-error-rate for 2-talker speech, while the performance of tSV for single-talker speech is on par with that of traditional speaker verification system, that is trained and evaluated under the same single-talker condition.
SpEx: Multi-Scale Time Domain Speaker Extraction Network
Apr 17, 2020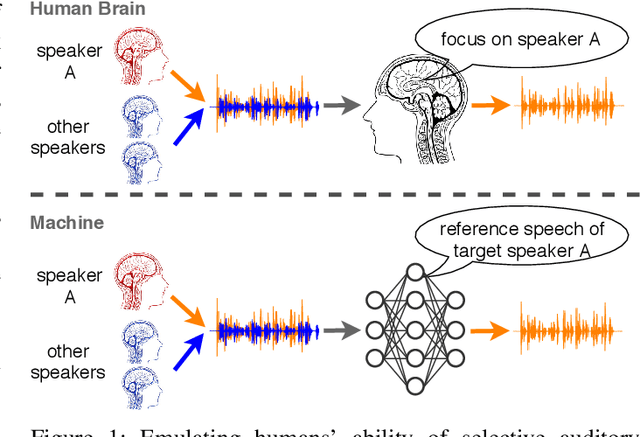
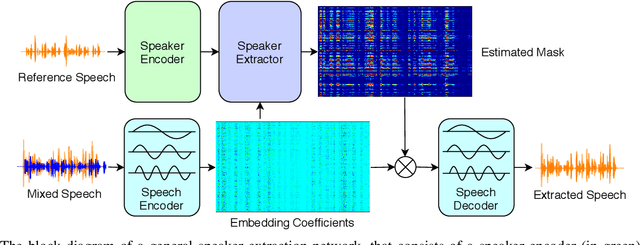
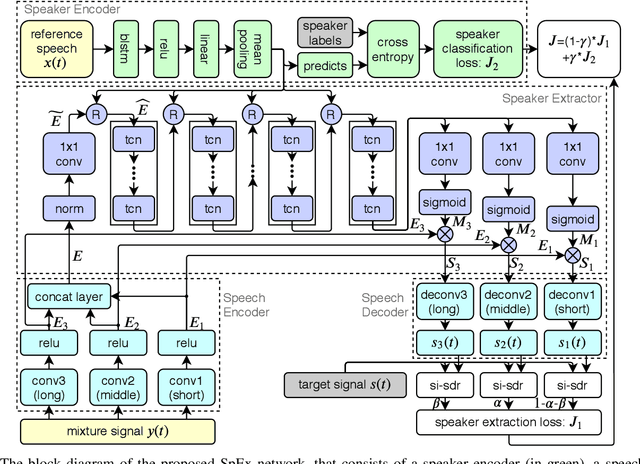
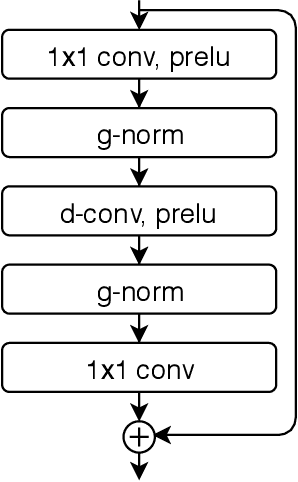
Speaker extraction aims to mimic humans' selective auditory attention by extracting a target speaker's voice from a multi-talker environment. It is common to perform the extraction in frequency-domain, and reconstruct the time-domain signal from the extracted magnitude and estimated phase spectra. However, such an approach is adversely affected by the inherent difficulty of phase estimation. Inspired by Conv-TasNet, we propose a time-domain speaker extraction network (SpEx) that converts the mixture speech into multi-scale embedding coefficients instead of decomposing the speech signal into magnitude and phase spectra. In this way, we avoid phase estimation. The SpEx network consists of four network components, namely speaker encoder, speech encoder, speaker extractor, and speech decoder. Specifically, the speech encoder converts the mixture speech into multi-scale embedding coefficients, the speaker encoder learns to represent the target speaker with a speaker embedding. The speaker extractor takes the multi-scale embedding coefficients and target speaker embedding as input and estimates a receptive mask. Finally, the speech decoder reconstructs the target speaker's speech from the masked embedding coefficients. We also propose a multi-task learning framework and a multi-scale embedding implementation. Experimental results show that the proposed SpEx achieves 37.3%, 37.7% and 15.0% relative improvements over the best baseline in terms of signal-to-distortion ratio (SDR), scale-invariant SDR (SI-SDR), and perceptual evaluation of speech quality (PESQ) under an open evaluation condition.
* ACCEPTED in IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP)
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019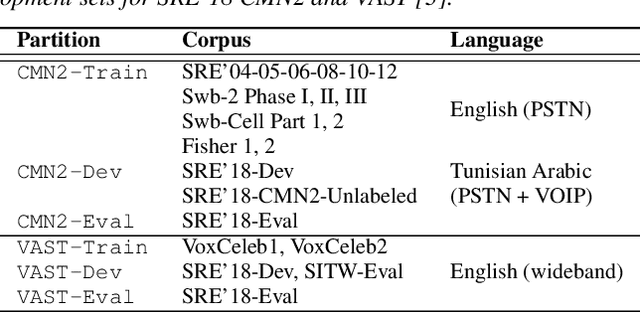
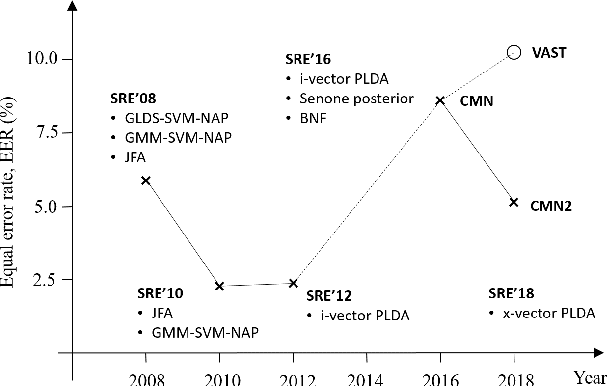
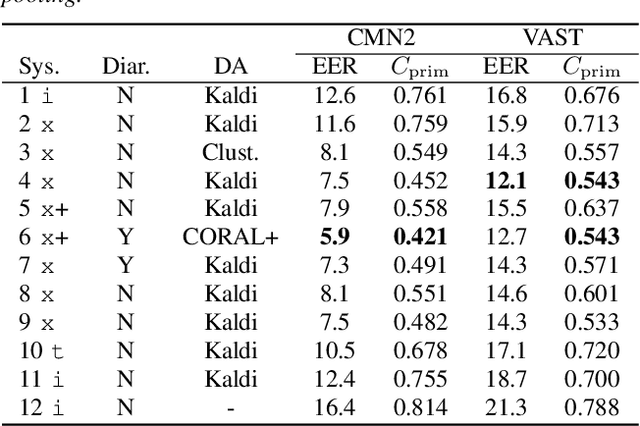
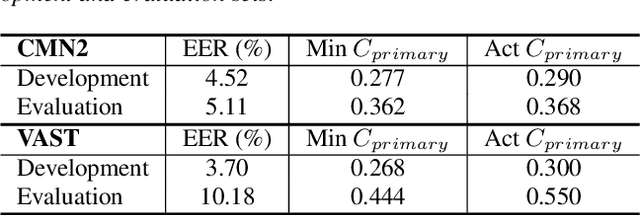
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
Optimization of Speaker Extraction Neural Network with Magnitude and Temporal Spectrum Approximation Loss
Mar 24, 2019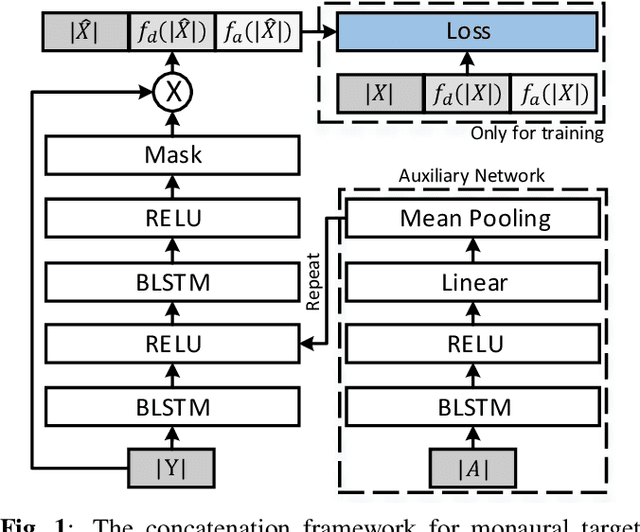
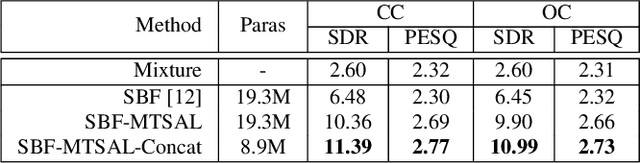
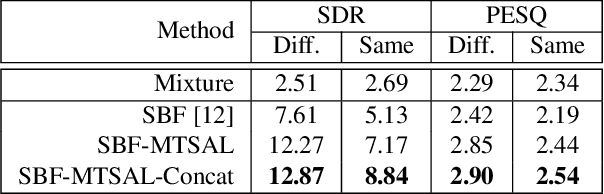
The SpeakerBeam-FE (SBF) method is proposed for speaker extraction. It attempts to overcome the problem of unknown number of speakers in an audio recording during source separation. The mask approximation loss of SBF is sub-optimal, which doesn't calculate direct signal reconstruction error and consider the speech context. To address these problems, this paper proposes a magnitude and temporal spectrum approximation loss to estimate a phase sensitive mask for the target speaker with the speaker characteristics. Moreover, this paper explores a concatenation framework instead of the context adaptive deep neural network in the SBF method to encode a speaker embedding into the mask estimation network. Experimental results under open evaluation condition show that the proposed method achieves 70.4% and 17.7% relative improvement over the SBF baseline on signal-to-distortion ratio (SDR) and perceptual evaluation of speech quality (PESQ), respectively. A further analysis demonstrates 69.1% and 72.3% relative SDR improvements obtained by the proposed method for different and same gender mixtures.
Fantastic 4 system for NIST 2015 Language Recognition Evaluation
Feb 05, 2016
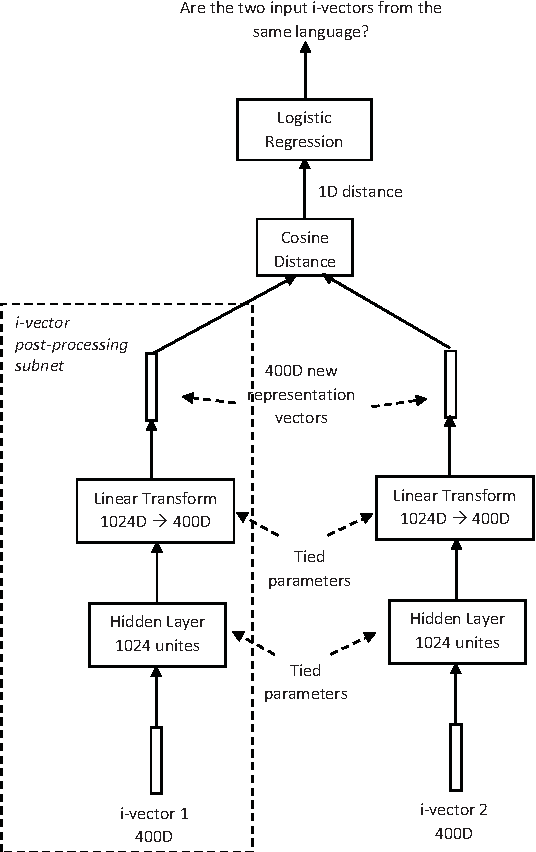
This article describes the systems jointly submitted by Institute for Infocomm (I$^2$R), the Laboratoire d'Informatique de l'Universit\'e du Maine (LIUM), Nanyang Technology University (NTU) and the University of Eastern Finland (UEF) for 2015 NIST Language Recognition Evaluation (LRE). The submitted system is a fusion of nine sub-systems based on i-vectors extracted from different types of features. Given the i-vectors, several classifiers are adopted for the language detection task including support vector machines (SVM), multi-class logistic regression (MCLR), Probabilistic Linear Discriminant Analysis (PLDA) and Deep Neural Networks (DNN).