 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Video Localization: A Revisit in Span-based Question Answering Framework
Mar 02, 2021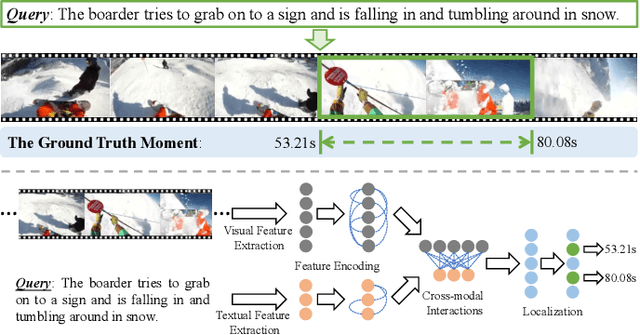

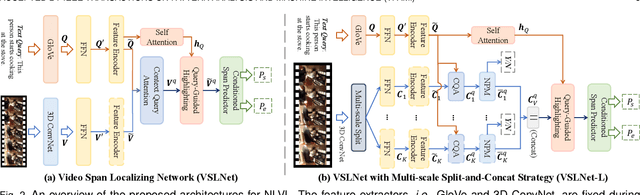
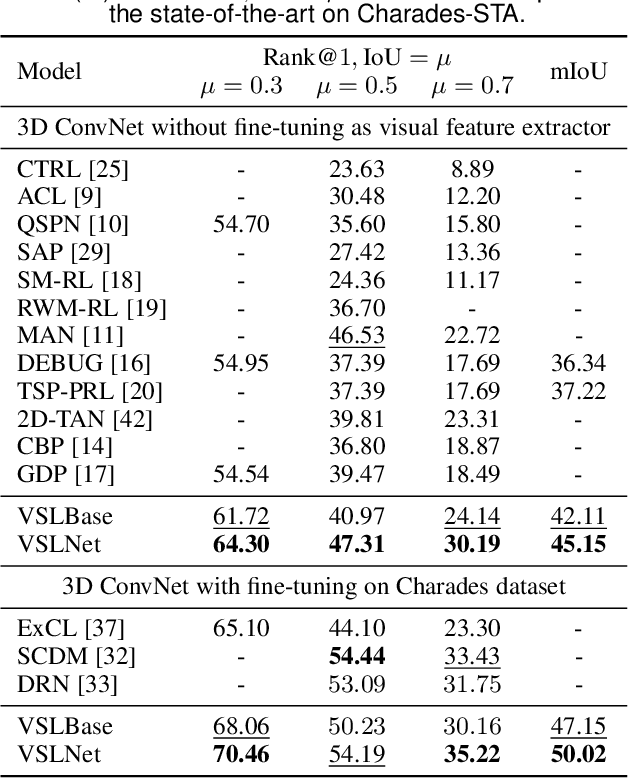
Natural Language Video Localization (NLVL) aims to locate a target moment from an untrimmed video that semantically corresponds to a text query. Existing approaches mainly solve the NLVL problem from the perspective of computer vision by formulating it as ranking, anchor, or regression tasks. These methods suffer from large performance degradation when localizing on long videos. In this work, we address the NLVL from a new perspective, i.e., span-based question answering (QA), by treating the input video as a text passage. We propose a video span localizing network (VSLNet), on top of the standard span-based QA framework (named VSLBase), to address NLVL. VSLNet tackles the differences between NLVL and span-based QA through a simple yet effective query-guided highlighting (QGH) strategy. QGH guides VSLNet to search for the matching video span within a highlighted region. To address the performance degradation on long videos, we further extend VSLNet to VSLNet-L by applying a multi-scale split-and-concatenation strategy. VSLNet-L first splits the untrimmed video into short clip segments; then, it predicts which clip segment contains the target moment and suppresses the importance of other segments. Finally, the clip segments are concatenated, with different confidences, to locate the target moment accurately. Extensive experiments on three benchmark datasets show that the proposed VSLNet and VSLNet-L outperform the state-of-the-art methods; VSLNet-L addresses the issue of performance degradation on long videos. Our study suggests that the span-based QA framework is an effective strategy to solve the NLVL problem.
* 15 pages, 18 figures, and 10 tables. Accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). arXiv admin note: substantial text overlap with arXiv:2004.13931
Context Modeling with Evidence Filter for Multiple Choice Question Answering
Oct 06, 2020
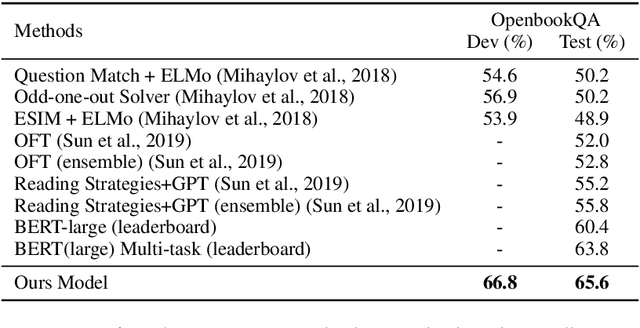
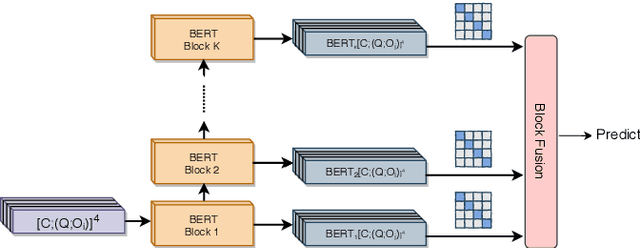

Multiple-Choice Question Answering (MCQA) is a challenging task in machine reading comprehension. The main challenge in MCQA is to extract "evidence" from the given context that supports the correct answer. In the OpenbookQA dataset, the requirement of extracting "evidence" is particularly important due to the mutual independence of sentences in the context. Existing work tackles this problem by annotated evidence or distant supervision with rules which overly rely on human efforts. To address the challenge, we propose a simple yet effective approach termed evidence filtering to model the relationships between the encoded contexts with respect to different options collectively and to potentially highlight the evidence sentences and filter out unrelated sentences. In addition to the effective reduction of human efforts of our approach compared, through extensive experiments on OpenbookQA, we show that the proposed approach outperforms the models that use the same backbone and more training data; and our parameter analysis also demonstrates the interpretability of our approach.
KOVIS: Keypoint-based Visual Servoing with Zero-Shot Sim-to-Real Transfer for Robotics Manipulation
Jul 28, 2020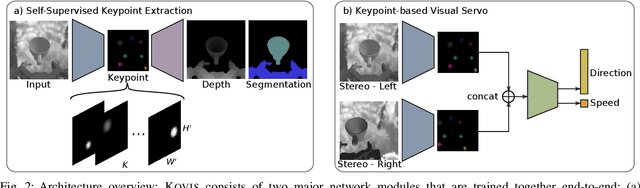
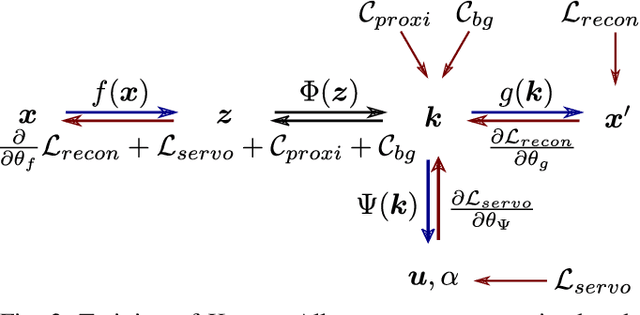
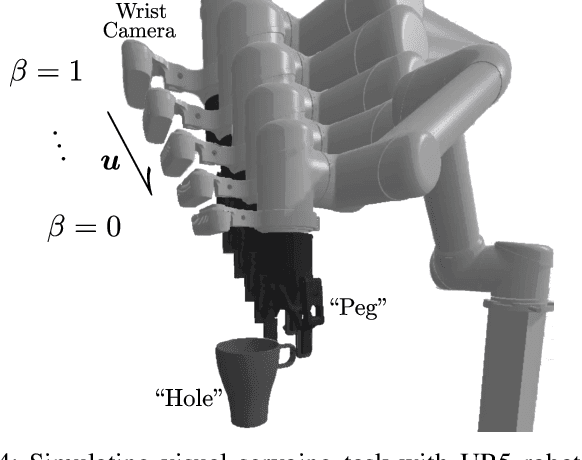
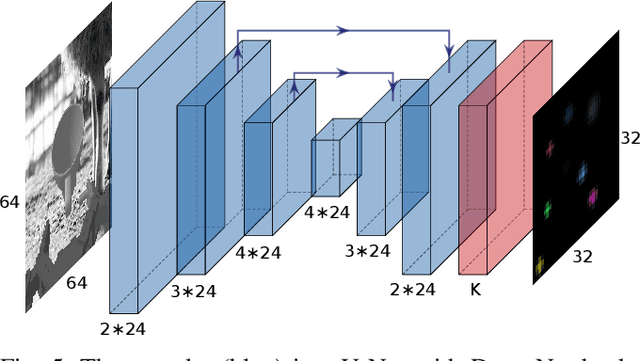
We present KOVIS, a novel learning-based, calibration-free visual servoing method for fine robotic manipulation tasks with eye-in-hand stereo camera system. We train the deep neural network only in the simulated environment; and the trained model could be directly used for real-world visual servoing tasks. KOVIS consists of two networks. The first keypoint network learns the keypoint representation from the image using with an autoencoder. Then the visual servoing network learns the motion based on keypoints extracted from the camera image. The two networks are trained end-to-end in the simulated environment by self-supervised learning without manual data labeling. After training with data augmentation, domain randomization, and adversarial examples, we are able to achieve zero-shot sim-to-real transfer to real-world robotic manipulation tasks. We demonstrate the effectiveness of the proposed method in both simulated environment and real-world experiment with different robotic manipulation tasks, including grasping, peg-in-hole insertion with 4mm clearance, and M13 screw insertion. The demo video is available at http://youtu.be/gfBJBR2tDzA
Multi-UAV Coverage Path Planning for the Inspection of Large and Complex Structures
Jul 26, 2020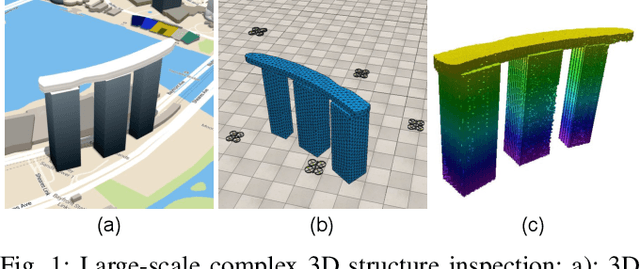
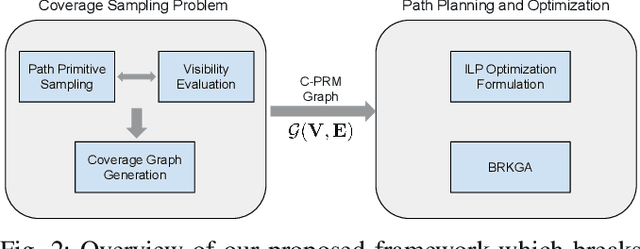
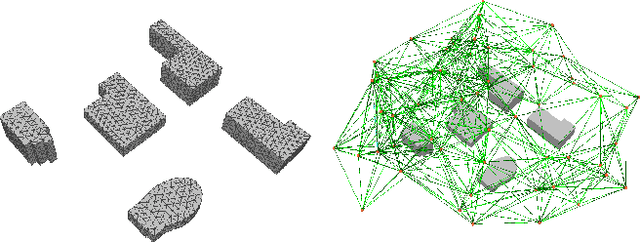
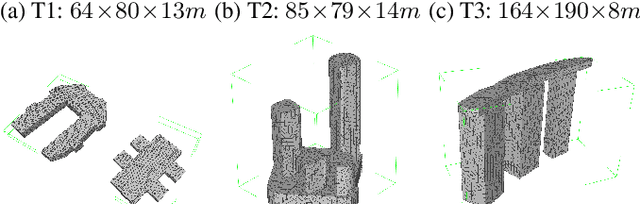
We present a multi-UAV Coverage Path Planning (CPP) framework for the inspection of large-scale, complex 3D structures. In the proposed sampling-based coverage path planning method, we formulate the multi-UAV inspection applications as a multi-agent coverage path planning problem. By combining two NP-hard problems: Set Covering Problem (SCP) and Vehicle Routing Problem (VRP), a Set-Covering Vehicle Routing Problem (SC-VRP) is formulated and subsequently solved by a modified Biased Random Key Genetic Algorithm (BRKGA) with novel, efficient encoding strategies and local improvement heuristics. We test our proposed method for several complex 3D structures with the 3D model extracted from OpenStreetMap. The proposed method outperforms previous methods, by reducing the length of the planned inspection path by up to 48%
Span-based Localizing Network for Natural Language Video Localization
Apr 29, 2020

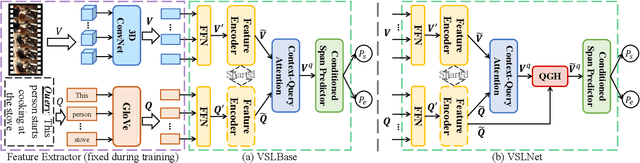
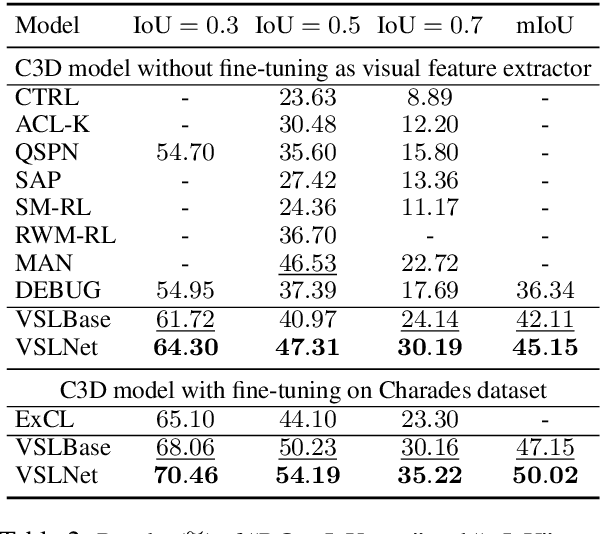
Given an untrimmed video and a text query, natural language video localization (NLVL) is to locate a matching span from the video that semantically corresponds to the query. Existing solutions formulate NLVL either as a ranking task and apply multimodal matching architecture, or as a regression task to directly regress the target video span. In this work, we address NLVL task with a span-based QA approach by treating the input video as text passage. We propose a video span localizing network (VSLNet), on top of the standard span-based QA framework, to address NLVL. The proposed VSLNet tackles the differences between NLVL and span-based QA through a simple and yet effective query-guided highlighting (QGH) strategy. The QGH guides VSLNet to search for matching video span within a highlighted region. Through extensive experiments on three benchmark datasets, we show that the proposed VSLNet outperforms the state-of-the-art methods; and adopting span-based QA framework is a promising direction to solve NLVL.
Feature Super-Resolution Based Facial Expression Recognition for Multi-scale Low-Resolution Faces
Apr 05, 2020
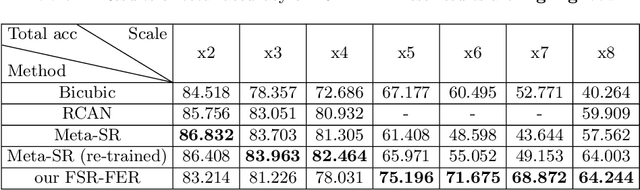
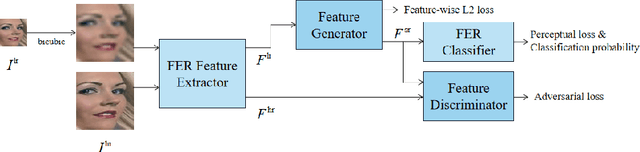
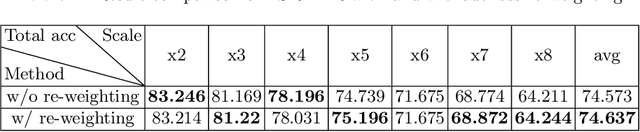
Facial Expressions Recognition(FER) on low-resolution images is necessary for applications like group expression recognition in crowd scenarios(station, classroom etc.). Classifying a small size facial image into the right expression category is still a challenging task. The main cause of this problem is the loss of discriminative feature due to reduced resolution. Super-resolution method is often used to enhance low-resolution images, but the performance on FER task is limited when on images of very low resolution. In this work, inspired by feature super-resolution methods for object detection, we proposed a novel generative adversary network-based feature level super-resolution method for robust facial expression recognition(FSR-FER). In particular, a pre-trained FER model was employed as feature extractor, and a generator network G and a discriminator network D are trained with features extracted from images of low resolution and original high resolution. Generator network G tries to transform features of low-resolution images to more discriminative ones by making them closer to the ones of corresponding high-resolution images. For better classification performance, we also proposed an effective classification-aware loss re-weighting strategy based on the classification probability calculated by a fixed FER model to make our model focus more on samples that are easily misclassified. Experiment results on Real-World Affective Faces (RAF) Database demonstrate that our method achieves satisfying results on various down-sample factors with a single model and has better performance on low-resolution images compared with methods using image super-resolution and expression recognition separately.
Efficient Robotic Task Generalization Using Deep Model Fusion Reinforcement Learning
Dec 11, 2019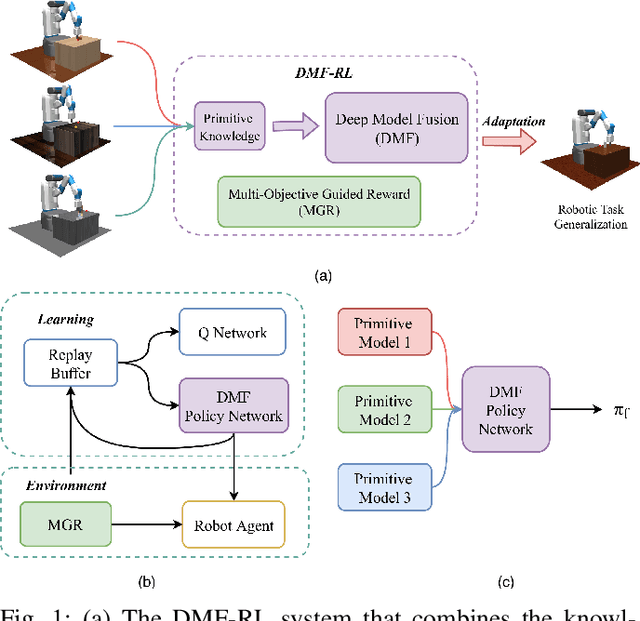
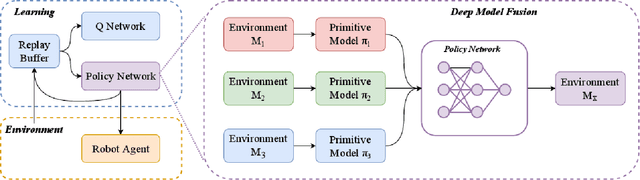
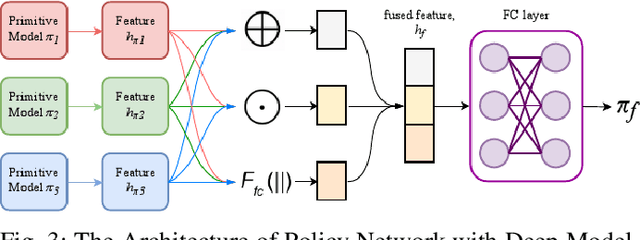
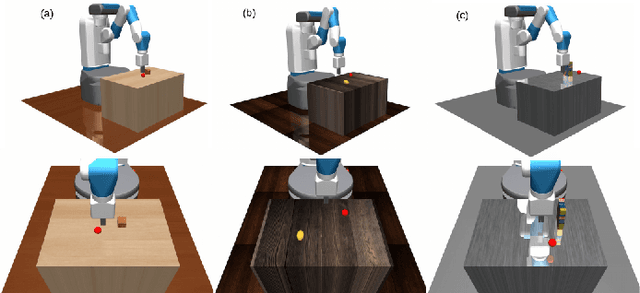
Learning-based methods have been used to pro-gram robotic tasks in recent years. However, extensive training is usually required not only for the initial task learning but also for generalizing the learned model to the same task but in different environments. In this paper, we propose a novel Deep Reinforcement Learning algorithm for efficient task generalization and environment adaptation in the robotic task learning problem. The proposed method is able to efficiently generalize the previously learned task by model fusion to solve the environment adaptation problem. The proposed Deep Model Fusion (DMF) method reuses and combines the previously trained model to improve the learning efficiency and results.Besides, we also introduce a Multi-objective Guided Reward(MGR) shaping technique to further improve training efficiency.The proposed method was benchmarked with previous methods in various environments to validate its effectiveness.
RoboCoDraw: Robotic Avatar Drawing with GAN-based Style Transfer and Time-efficient Path Optimization
Dec 11, 2019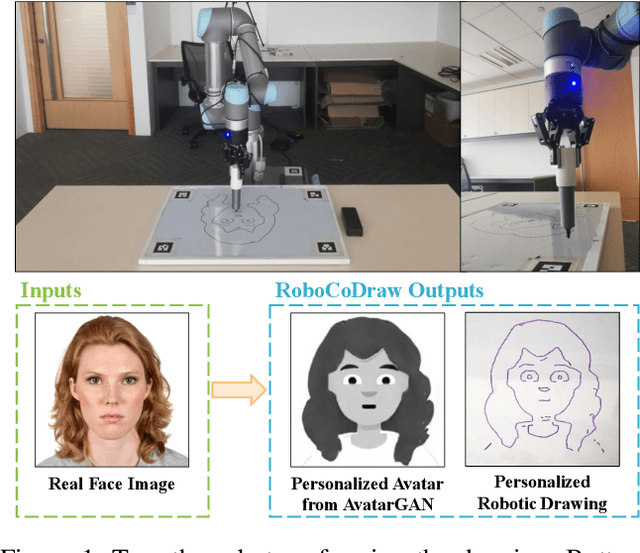
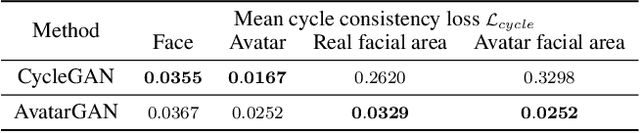

Robotic drawing has become increasingly popular as an entertainment and interactive tool. In this paper we present RoboCoDraw, a real-time collaborative robot-based drawing system that draws stylized human face sketches interactively in front of human users, by using the Generative Adversarial Network (GAN)-based style transfer and a Random-Key Genetic Algorithm (RKGA)-based path optimization. The proposed RoboCoDraw system takes a real human face image as input, converts it to a stylized avatar, then draws it with a robotic arm. A core component in this system is the Avatar-GAN proposed by us, which generates a cartoon avatar face image from a real human face. AvatarGAN is trained with unpaired face and avatar images only and can generate avatar images of much better likeness with human face images in comparison with the vanilla CycleGAN. After the avatar image is generated, it is fed to a line extraction algorithm and converted to sketches. An RKGA-based path optimization algorithm is applied to find a time-efficient robotic drawing path to be executed by the robotic arm. We demonstrate the capability of RoboCoDraw on various face images using a lightweight, safe collaborative robot UR5.
Constrained Heterogeneous Vehicle Path Planning for Large-area Coverage
Nov 22, 2019

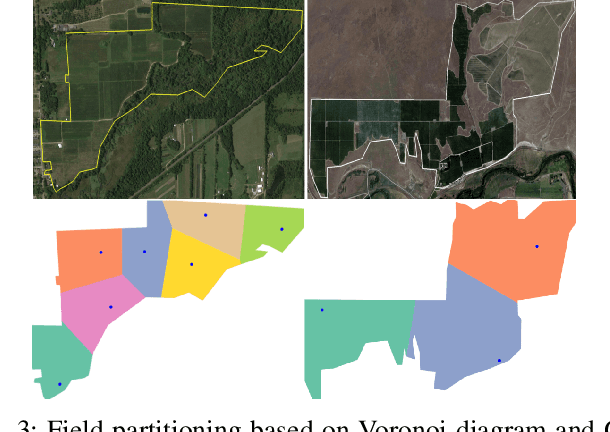
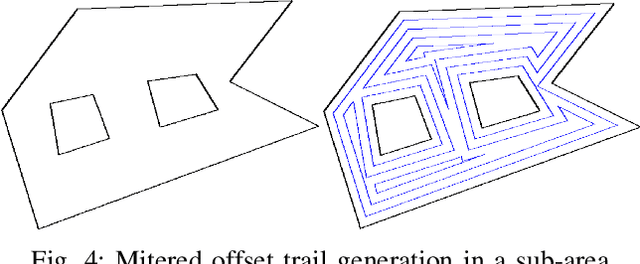
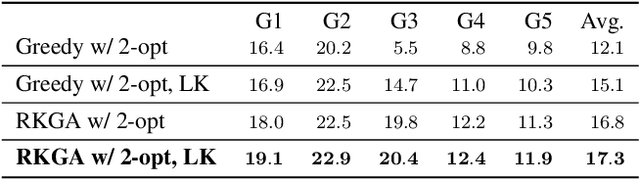
There is a strong demand for covering a large area autonomously by multiple UAVs (Unmanned Aerial Vehicles) supported by a ground vehicle. Limited by UAVs' battery life and communication distance, complete coverage of large areas typically involves multiple take-offs and landings to recharge batteries, and the transportation of UAVs between operation areas by a ground vehicle. In this paper, we introduce a novel large-area-coverage planning framework which collectively optimizes the paths for aerial and ground vehicles. Our method first partitions a large area into sub-areas, each of which a given fleet of UAVs can cover without recharging batteries. UAV operation routes, or trails, are then generated for each sub-area. Next, the assignment of trials to different UAVs and the order in which UAVs visit their assigned trails are simultaneously optimized to minimize the total UAV flight distance. Finally, a ground vehicle transportation path which visits all sub-areas is found by solving an asymmetric traveling salesman problem (ATSP). Although finding the globally optimal trail assignment and transition paths can be formulated as a Mixed Integer Quadratic Program (MIQP), the MIQP is intractable even for small problems. We show that the solution time can be reduced to close-to-real-time levels by first finding a feasible solution using a Random Key Genetic Algorithm (RKGA), which is then locally optimized by solving a much smaller MIQP.
6D Pose Estimation with Correlation Fusion
Sep 24, 2019
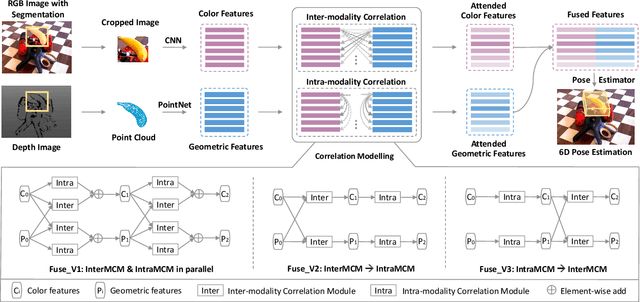
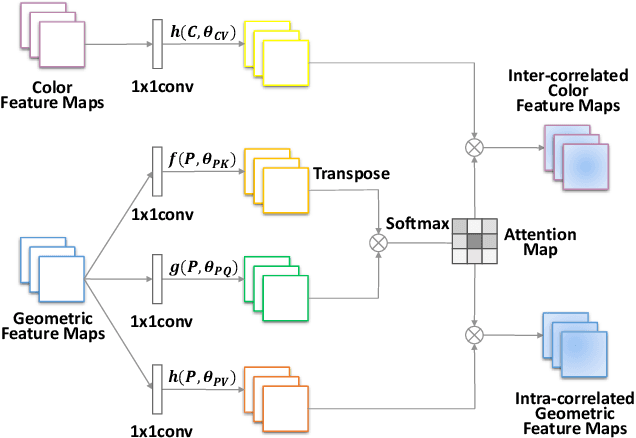

6D object pose estimation is widely applied in robotic tasks such as grasping and manipulation. Prior methods using RGB-only images are vulnerable to heavy occlusion and poor illumination, so it is important to complement them with depth information. However, existing methods using RGB-D data don't adequately exploit consistent and complementary information between two modalities. In this paper, we present a novel method to effectively consider the correlation within and across RGB and depth modalities with attention mechanism to learn discriminative multi-modal features. Then, effective fusion strategies for intra- and inter-correlation modules are explored to ensure efficient information flow between RGB and depth. To the best of our knowledge, this is the first work to explore effective intra- and inter-modality fusion in 6D pose estimation and experimental results show that our method can help achieve the state-of-the-art performance on LineMOD and YCB-Video datasets as well as benefit robot grasping task.