 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuseformer: Transformer with Fine- and Coarse-Grained Attention for Music Generation
Oct 19, 2022
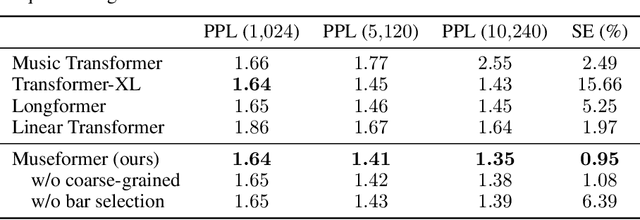
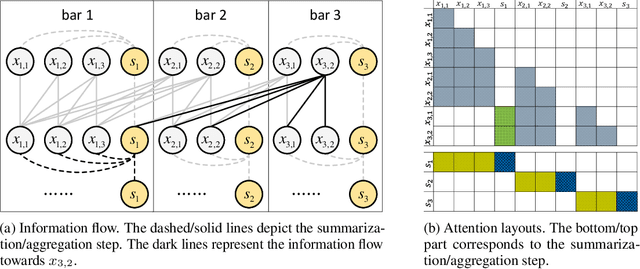
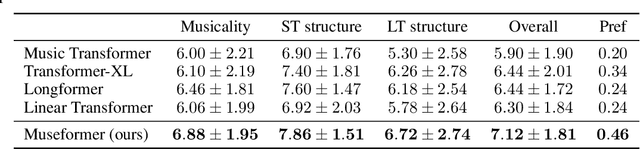
Symbolic music generation aims to generate music scores automatically. A recent trend is to use Transformer or its variants in music generation, which is, however, suboptimal, because the full attention cannot efficiently model the typically long music sequences (e.g., over 10,000 tokens), and the existing models have shortcomings in generating musical repetition structures. In this paper, we propose Museformer, a Transformer with a novel fine- and coarse-grained attention for music generation. Specifically, with the fine-grained attention, a token of a specific bar directly attends to all the tokens of the bars that are most relevant to music structures (e.g., the previous 1st, 2nd, 4th and 8th bars, selected via similarity statistics); with the coarse-grained attention, a token only attends to the summarization of the other bars rather than each token of them so as to reduce the computational cost. The advantages are two-fold. First, it can capture both music structure-related correlations via the fine-grained attention, and other contextual information via the coarse-grained attention. Second, it is efficient and can model over 3X longer music sequences compared to its full-attention counterpart. Both objective and subjective experimental results demonstrate its ability to generate long music sequences with high quality and better structures.
Implicit Bias in Leaky ReLU Networks Trained on High-Dimensional Data
Oct 13, 2022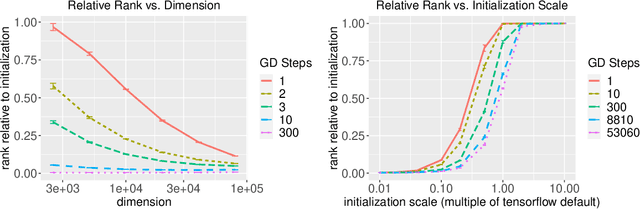
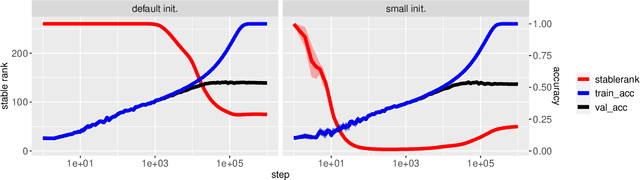
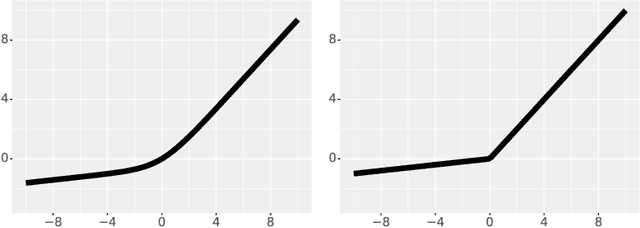
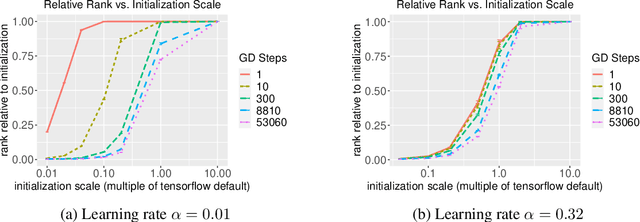
The implicit biases of gradient-based optimization algorithms are conjectured to be a major factor in the success of modern deep learning. In this work, we investigate the implicit bias of gradient flow and gradient descent in two-layer fully-connected neural networks with leaky ReLU activations when the training data are nearly-orthogonal, a common property of high-dimensional data. For gradient flow, we leverage recent work on the implicit bias for homogeneous neural networks to show that asymptotically, gradient flow produces a neural network with rank at most two. Moreover, this network is an $\ell_2$-max-margin solution (in parameter space), and has a linear decision boundary that corresponds to an approximate-max-margin linear predictor. For gradient descent, provided the random initialization variance is small enough, we show that a single step of gradient descent suffices to drastically reduce the rank of the network, and that the rank remains small throughout training. We provide experiments which suggest that a small initialization scale is important for finding low-rank neural networks with gradient descent.
I Know What You Do Not Know: Knowledge Graph Embedding via Co-distillation Learning
Aug 28, 2022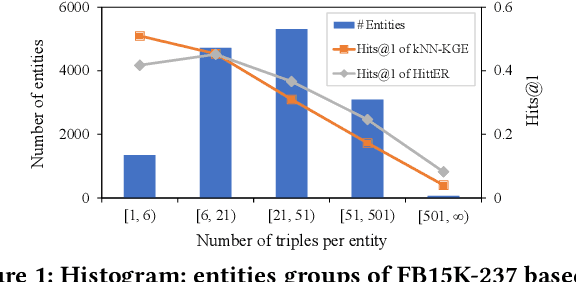

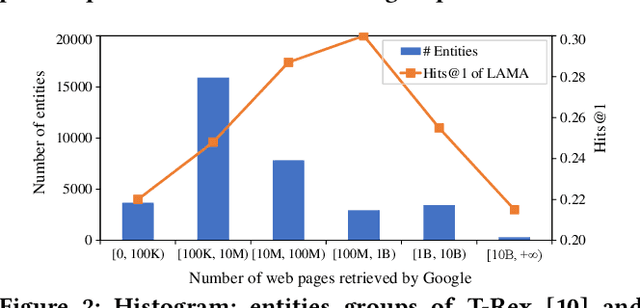

Knowledge graph (KG) embedding seeks to learn vector representations for entities and relations. Conventional models reason over graph structures, but they suffer from the issues of graph incompleteness and long-tail entities. Recent studies have used pre-trained language models to learn embeddings based on the textual information of entities and relations, but they cannot take advantage of graph structures. In the paper, we show empirically that these two kinds of features are complementary for KG embedding. To this end, we propose CoLE, a Co-distillation Learning method for KG Embedding that exploits the complementarity of graph structures and text information. Its graph embedding model employs Transformer to reconstruct the representation of an entity from its neighborhood subgraph. Its text embedding model uses a pre-trained language model to generate entity representations from the soft prompts of their names, descriptions, and relational neighbors. To let the two model promote each other, we propose co-distillation learning that allows them to distill selective knowledge from each other's prediction logits. In our co-distillation learning, each model serves as both a teacher and a student. Experiments on benchmark datasets demonstrate that the two models outperform their related baselines, and the ensemble method CoLE with co-distillation learning advances the state-of-the-art of KG embedding.
Large-scale Entity Alignment via Knowledge Graph Merging, Partitioning and Embedding
Aug 23, 2022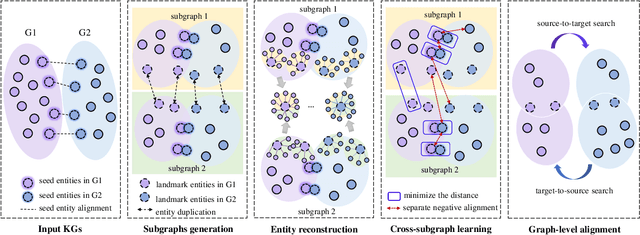
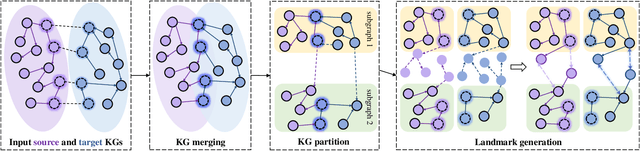
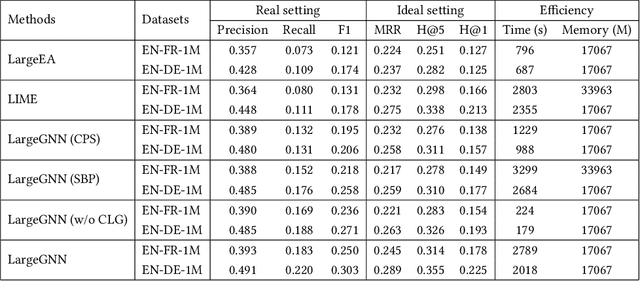
Entity alignment is a crucial task in knowledge graph fusion. However, most entity alignment approaches have the scalability problem. Recent methods address this issue by dividing large KGs into small blocks for embedding and alignment learning in each. However, such a partitioning and learning process results in an excessive loss of structure and alignment. Therefore, in this work, we propose a scalable GNN-based entity alignment approach to reduce the structure and alignment loss from three perspectives. First, we propose a centrality-based subgraph generation algorithm to recall some landmark entities serving as the bridges between different subgraphs. Second, we introduce self-supervised entity reconstruction to recover entity representations from incomplete neighborhood subgraphs, and design cross-subgraph negative sampling to incorporate entities from other subgraphs in alignment learning. Third, during the inference process, we merge the embeddings of subgraphs to make a single space for alignment search. Experimental results on the benchmark OpenEA dataset and the proposed large DBpedia1M dataset verify the effectiveness of our approach.
Inductive Knowledge Graph Reasoning for Multi-batch Emerging Entities
Aug 22, 2022
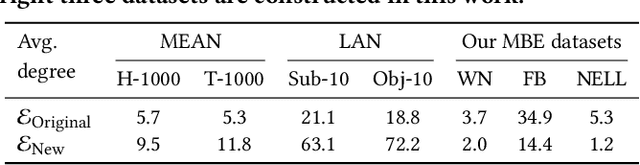
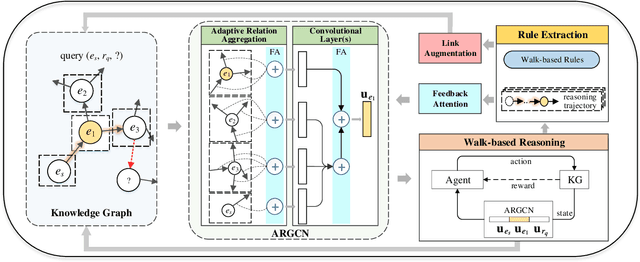

Over the years, reasoning over knowledge graphs (KGs), which aims to infer new conclusions from known facts, has mostly focused on static KGs. The unceasing growth of knowledge in real life raises the necessity to enable the inductive reasoning ability on expanding KGs. Existing inductive work assumes that new entities all emerge once in a batch, which oversimplifies the real scenario that new entities continually appear. This study dives into a more realistic and challenging setting where new entities emerge in multiple batches. We propose a walk-based inductive reasoning model to tackle the new setting. Specifically, a graph convolutional network with adaptive relation aggregation is designed to encode and update entities using their neighboring relations. To capture the varying neighbor importance, we employ a query-aware feedback attention mechanism during the aggregation. Furthermore, to alleviate the sparse link problem of new entities, we propose a link augmentation strategy to add trustworthy facts into KGs. We construct three new datasets for simulating this multi-batch emergence scenario. The experimental results show that our proposed model outperforms state-of-the-art embedding-based, walk-based and rule-based models on inductive KG reasoning.
Neural Capture of Animatable 3D Human from Monocular Video
Aug 18, 2022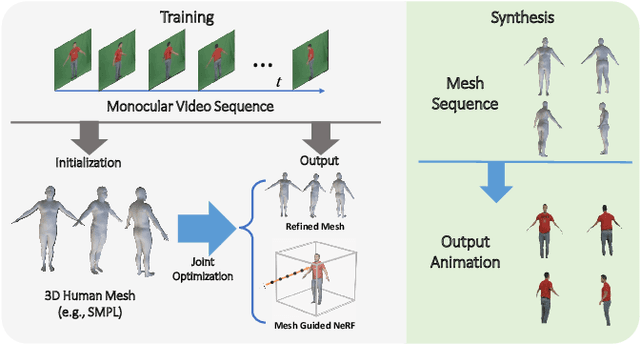
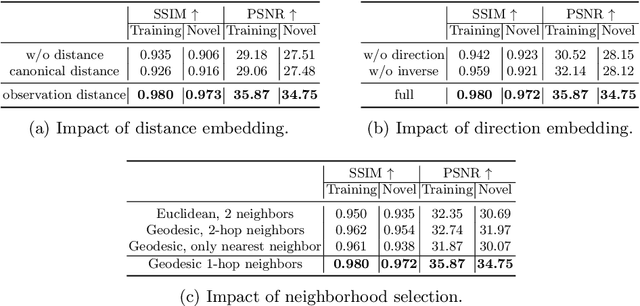
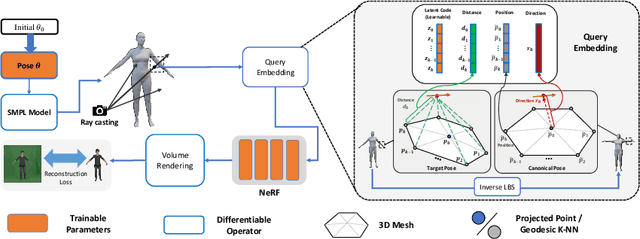
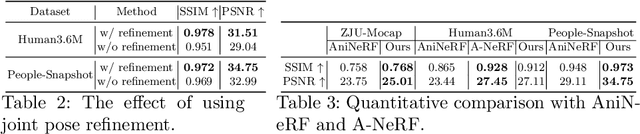
We present a novel paradigm of building an animatable 3D human representation from a monocular video input, such that it can be rendered in any unseen poses and views. Our method is based on a dynamic Neural Radiance Field (NeRF) rigged by a mesh-based parametric 3D human model serving as a geometry proxy. Previous methods usually rely on multi-view videos or accurate 3D geometry information as additional inputs; besides, most methods suffer from degraded quality when generalized to unseen poses. We identify that the key to generalization is a good input embedding for querying dynamic NeRF: A good input embedding should define an injective mapping in the full volumetric space, guided by surface mesh deformation under pose variation. Based on this observation, we propose to embed the input query with its relationship to local surface regions spanned by a set of geodesic nearest neighbors on mesh vertices. By including both position and relative distance information, our embedding defines a distance-preserved deformation mapping and generalizes well to unseen poses. To reduce the dependency on additional inputs, we first initialize per-frame 3D meshes using off-the-shelf tools and then propose a pipeline to jointly optimize NeRF and refine the initial mesh. Extensive experiments show our method can synthesize plausible human rendering results under unseen poses and views.
$μ\text{KG}$: A Library for Multi-source Knowledge Graph Embeddings and Applications
Jul 28, 2022
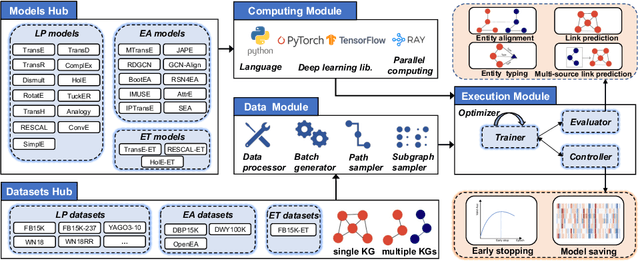
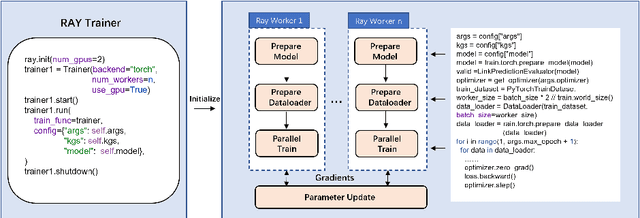
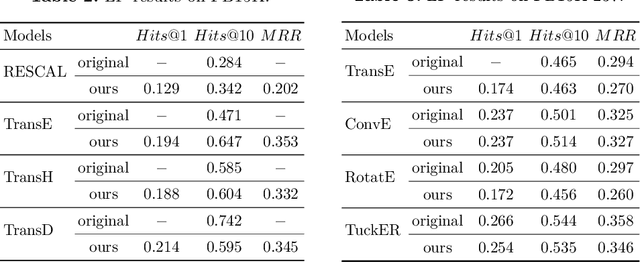
This paper presents $\mu\text{KG}$, an open-source Python library for representation learning over knowledge graphs. $\mu\text{KG}$ supports joint representation learning over multi-source knowledge graphs (and also a single knowledge graph), multiple deep learning libraries (PyTorch and TensorFlow2), multiple embedding tasks (link prediction, entity alignment, entity typing, and multi-source link prediction), and multiple parallel computing modes (multi-process and multi-GPU computing). It currently implements 26 popular knowledge graph embedding models and supports 16 benchmark datasets. $\mu\text{KG}$ provides advanced implementations of embedding techniques with simplified pipelines of different tasks. It also comes with high-quality documentation for ease of use. $\mu\text{KG}$ is more comprehensive than existing knowledge graph embedding libraries. It is useful for a thorough comparison and analysis of various embedding models and tasks. We show that the jointly learned embeddings can greatly help knowledge-powered downstream tasks, such as multi-hop knowledge graph question answering. We will stay abreast of the latest developments in the related fields and incorporate them into $\mu\text{KG}$.
Reducing the Vision and Language Bias for Temporal Sentence Grounding
Jul 27, 2022
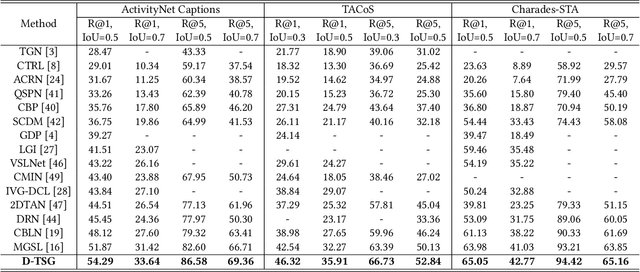
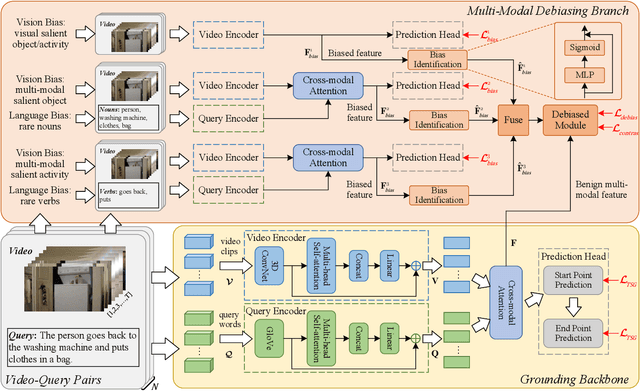
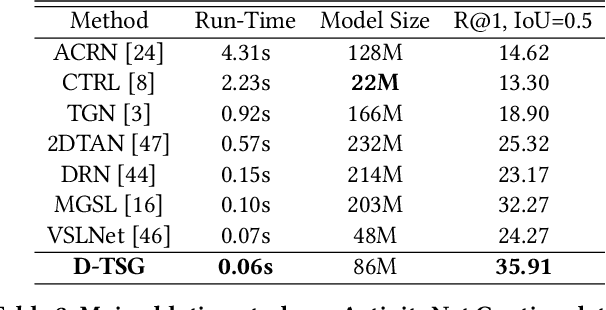
Temporal sentence grounding (TSG) is an important yet challenging task in multimedia information retrieval. Although previous TSG methods have achieved decent performance, they tend to capture the selection biases of frequently appeared video-query pairs in the dataset rather than present robust multimodal reasoning abilities, especially for the rarely appeared pairs. In this paper, we study the above issue of selection biases and accordingly propose a Debiasing-TSG (D-TSG) model to filter and remove the negative biases in both vision and language modalities for enhancing the model generalization ability. Specifically, we propose to alleviate the issue from two perspectives: 1) Feature distillation. We built a multi-modal debiasing branch to firstly capture the vision and language biases, and then apply a bias identification module to explicitly recognize the true negative biases and remove them from the benign multi-modal representations. 2) Contrastive sample generation. We construct two types of negative samples to enforce the model to accurately learn the aligned multi-modal semantics and make complete semantic reasoning. We apply the proposed model to both commonly and rarely appeared TSG cases, and demonstrate its effectiveness by achieving the state-of-the-art performance on three benchmark datasets (ActivityNet Caption, TACoS, and Charades-STA).
Skimming, Locating, then Perusing: A Human-Like Framework for Natural Language Video Localization
Jul 27, 2022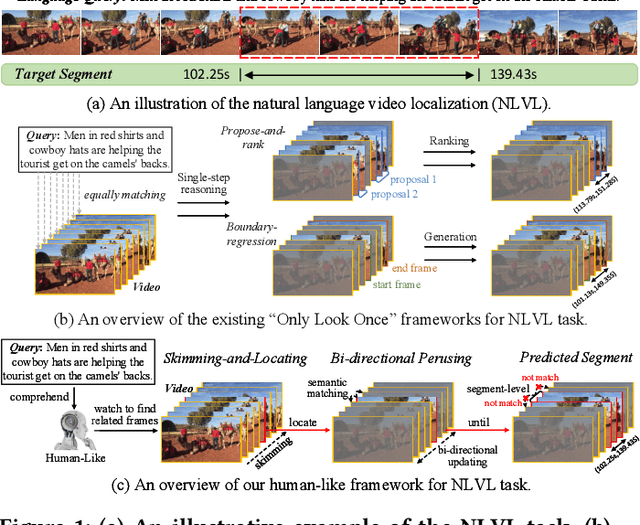
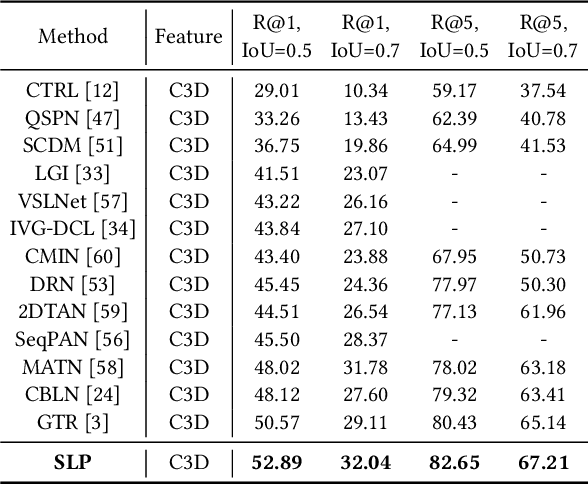
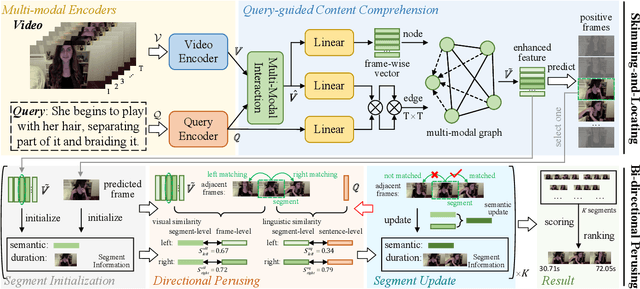
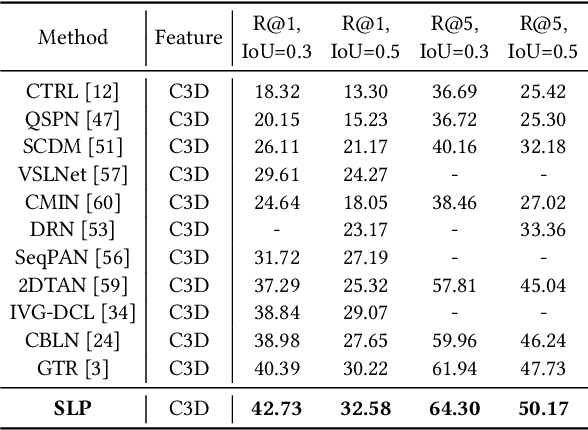
This paper addresses the problem of natural language video localization (NLVL). Almost all existing works follow the "only look once" framework that exploits a single model to directly capture the complex cross- and self-modal relations among video-query pairs and retrieve the relevant segment. However, we argue that these methods have overlooked two indispensable characteristics of an ideal localization method: 1) Frame-differentiable: considering the imbalance of positive/negative video frames, it is effective to highlight positive frames and weaken negative ones during the localization. 2) Boundary-precise: to predict the exact segment boundary, the model should capture more fine-grained differences between consecutive frames since their variations are often smooth. To this end, inspired by how humans perceive and localize a segment, we propose a two-step human-like framework called Skimming-Locating-Perusing (SLP). SLP consists of a Skimming-and-Locating (SL) module and a Bi-directional Perusing (BP) module. The SL module first refers to the query semantic and selects the best matched frame from the video while filtering out irrelevant frames. Then, the BP module constructs an initial segment based on this frame, and dynamically updates it by exploring its adjacent frames until no frame shares the same activity semantic. Experimental results on three challenging benchmarks show that our SLP is superior to the state-of-the-art methods and localizes more precise segment boundaries.
Point Cloud Attacks in Graph Spectral Domain: When 3D Geometry Meets Graph Signal Processing
Jul 27, 2022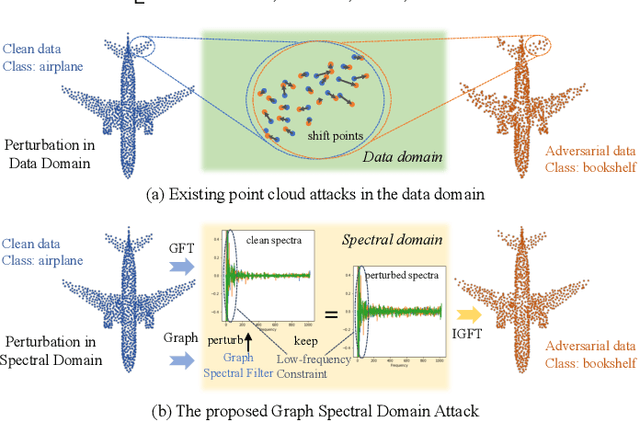
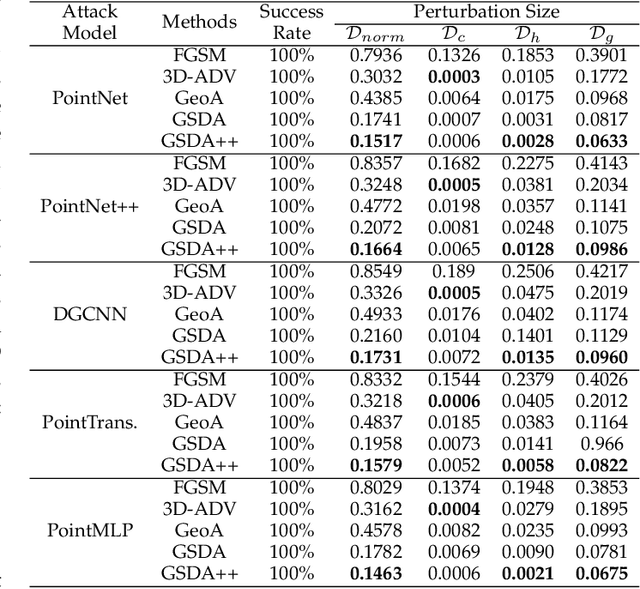
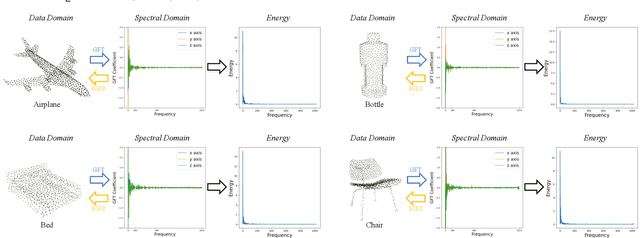
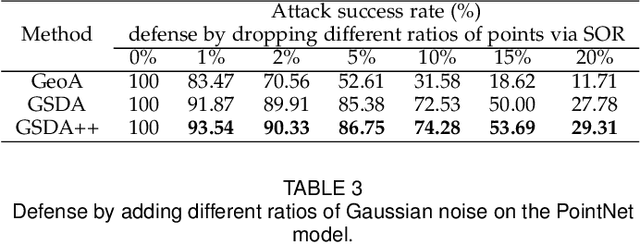
With the increasing attention in various 3D safety-critical applications, point cloud learning models have been shown to be vulnerable to adversarial attacks. Although existing 3D attack methods achieve high success rates, they delve into the data space with point-wise perturbation, which may neglect the geometric characteristics. Instead, we propose point cloud attacks from a new perspective -- the graph spectral domain attack, aiming to perturb graph transform coefficients in the spectral domain that corresponds to varying certain geometric structure. Specifically, leveraging on graph signal processing, we first adaptively transform the coordinates of points onto the spectral domain via graph Fourier transform (GFT) for compact representation. Then, we analyze the influence of different spectral bands on the geometric structure, based on which we propose to perturb the GFT coefficients via a learnable graph spectral filter. Considering the low-frequency components mainly contribute to the rough shape of the 3D object, we further introduce a low-frequency constraint to limit perturbations within imperceptible high-frequency components. Finally, the adversarial point cloud is generated by transforming the perturbed spectral representation back to the data domain via the inverse GFT. Experimental results demonstrate the effectiveness of the proposed attack in terms of both the imperceptibility and attack success rates.