 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Chen
Mixed-Variable Global Sensitivity Analysis For Knowledge Discovery And Efficient Combinatorial Materials Design
Oct 23, 2023
Global Sensitivity Analysis (GSA) is the study of the influence of any given inputs on the outputs of a model. In the context of engineering design, GSA has been widely used to understand both individual and collective contributions of design variables on the design objectives. So far, global sensitivity studies have often been limited to design spaces with only quantitative (numerical) design variables. However, many engineering systems also contain, if not only, qualitative (categorical) design variables in addition to quantitative design variables. In this paper, we integrate Latent Variable Gaussian Process (LVGP) with Sobol' analysis to develop the first metamodel-based mixed-variable GSA method. Through numerical case studies, we validate and demonstrate the effectiveness of our proposed method for mixed-variable problems. Furthermore, while the proposed GSA method is general enough to benefit various engineering design applications, we integrate it with multi-objective Bayesian optimization (BO) to create a sensitivity-aware design framework in accelerating the Pareto front design exploration for metal-organic framework (MOF) materials with many-level combinatorial design spaces. Although MOFs are constructed only from qualitative variables that are notoriously difficult to design, our method can utilize sensitivity analysis to navigate the optimization in the many-level large combinatorial design space, greatly expediting the exploration of novel MOF candidates.
When Urban Region Profiling Meets Large Language Models
Oct 22, 2023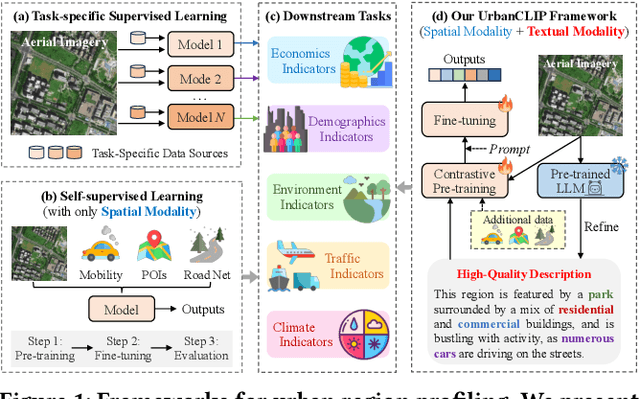
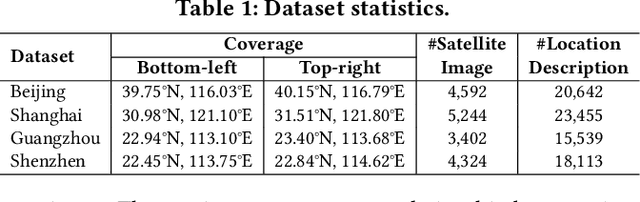
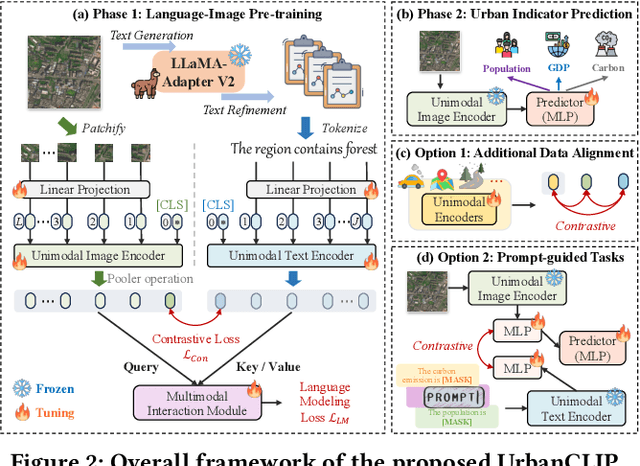
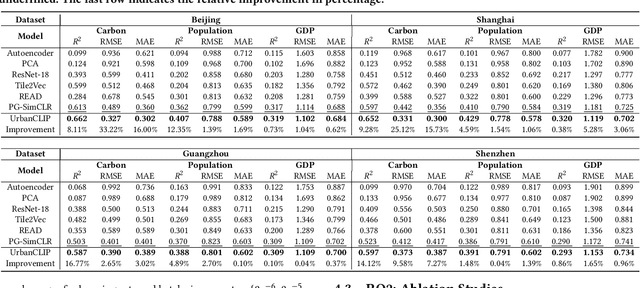
Urban region profiling from web-sourced data is of utmost importance for urban planning and sustainable development. We are witnessing a rising trend of LLMs for various fields, especially dealing with multi-modal data research such as vision-language learning, where the text modality serves as a supplement information for the image. Since textual modality has never been introduced into modality combinations in urban region profiling, we aim to answer two fundamental questions in this paper: i) Can textual modality enhance urban region profiling? ii) and if so, in what ways and with regard to which aspects? To answer the questions, we leverage the power of Large Language Models (LLMs) and introduce the first-ever LLM-enhanced framework that integrates the knowledge of textual modality into urban imagery profiling, named LLM-enhanced Urban Region Profiling with Contrastive Language-Image Pretraining (UrbanCLIP). Specifically, it first generates a detailed textual description for each satellite image by an open-source Image-to-Text LLM. Then, the model is trained on the image-text pairs, seamlessly unifying natural language supervision for urban visual representation learning, jointly with contrastive loss and language modeling loss. Results on predicting three urban indicators in four major Chinese metropolises demonstrate its superior performance, with an average improvement of 6.1% on R^2 compared to the state-of-the-art methods. Our code and the image-language dataset will be released upon paper notification.
Towards Enhancing Relational Rules for Knowledge Graph Link Prediction
Oct 20, 2023Graph neural networks (GNNs) have shown promising performance for knowledge graph reasoning. A recent variant of GNN called progressive relational graph neural network (PRGNN), utilizes relational rules to infer missing knowledge in relational digraphs and achieves notable results. However, during reasoning with PRGNN, two important properties are often overlooked: (1) the sequentiality of relation composition, where the order of combining different relations affects the semantics of the relational rules, and (2) the lagged entity information propagation, where the transmission speed of required information lags behind the appearance speed of new entities. Ignoring these properties leads to incorrect relational rule learning and decreased reasoning accuracy. To address these issues, we propose a novel knowledge graph reasoning approach, the Relational rUle eNhanced Graph Neural Network (RUN-GNN). Specifically, RUN-GNN employs a query related fusion gate unit to model the sequentiality of relation composition and utilizes a buffering update mechanism to alleviate the negative effect of lagged entity information propagation, resulting in higher-quality relational rule learning. Experimental results on multiple datasets demonstrate the superiority of RUN-GNN is superior on both transductive and inductive link prediction tasks.
Over-the-Air Federated Learning and Optimization
Oct 16, 2023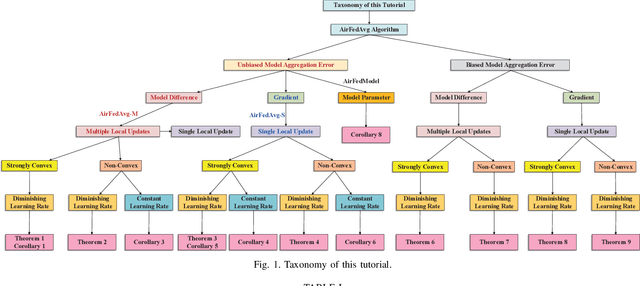

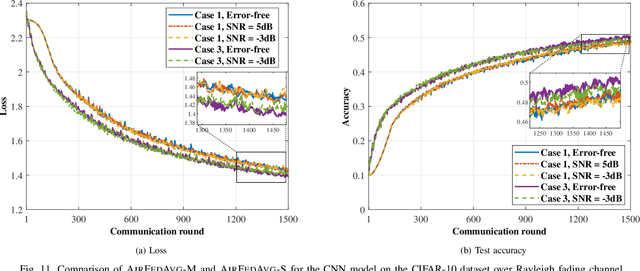
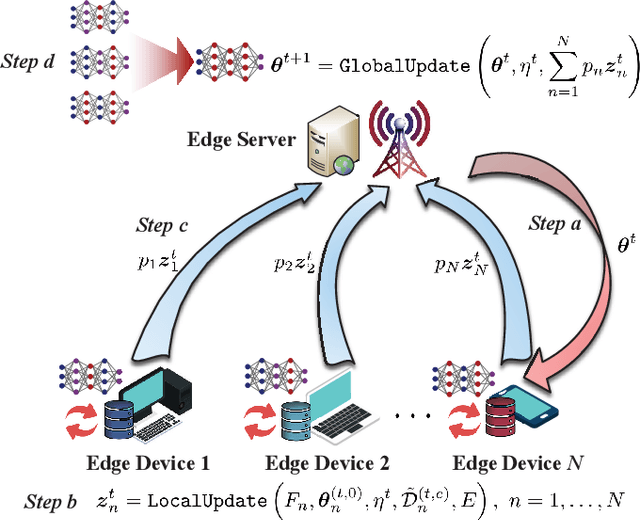
Federated learning (FL), as an emerging distributed machine learning paradigm, allows a mass of edge devices to collaboratively train a global model while preserving privacy. In this tutorial, we focus on FL via over-the-air computation (AirComp), which is proposed to reduce the communication overhead for FL over wireless networks at the cost of compromising in the learning performance due to model aggregation error arising from channel fading and noise. We first provide a comprehensive study on the convergence of AirComp-based FedAvg (AirFedAvg) algorithms under both strongly convex and non-convex settings with constant and diminishing learning rates in the presence of data heterogeneity. Through convergence and asymptotic analysis, we characterize the impact of aggregation error on the convergence bound and provide insights for system design with convergence guarantees. Then we derive convergence rates for AirFedAvg algorithms for strongly convex and non-convex objectives. For different types of local updates that can be transmitted by edge devices (i.e., local model, gradient, and model difference), we reveal that transmitting local model in AirFedAvg may cause divergence in the training procedure. In addition, we consider more practical signal processing schemes to improve the communication efficiency and further extend the convergence analysis to different forms of model aggregation error caused by these signal processing schemes. Extensive simulation results under different settings of objective functions, transmitted local information, and communication schemes verify the theoretical conclusions.
Rate Compatible LDPC Neural Decoding Network: A Multi-Task Learning Approach
Oct 10, 2023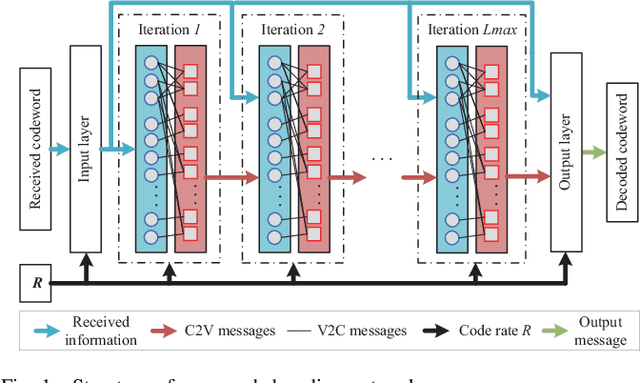
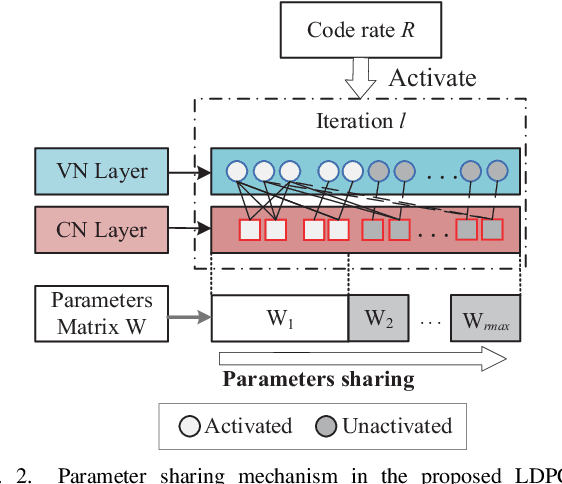
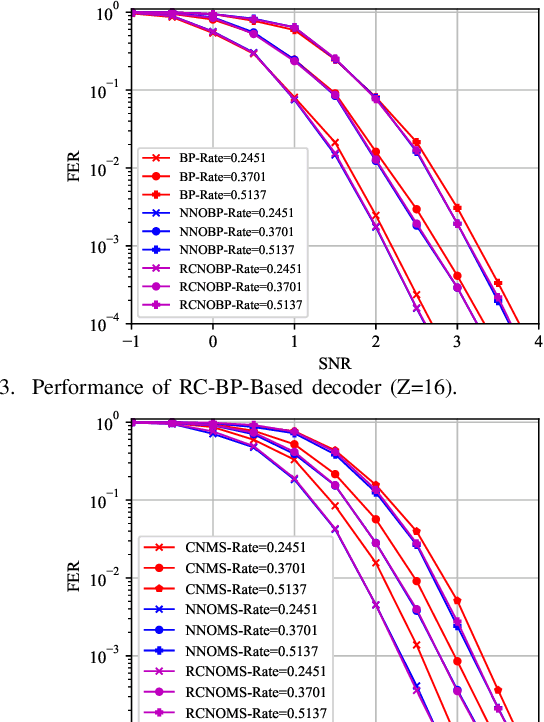
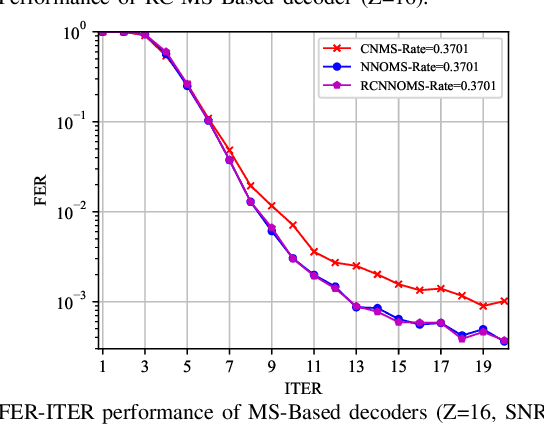
Deep learning based decoding networks have shown significant improvement in decoding LDPC codes, but the neural decoders are limited by rate-matching operations such as puncturing or extending, thus needing to train multiple decoders with different code rates for a variety of channel conditions. In this correspondence, we propose a Multi-Task Learning based rate-compatible LDPC ecoding network, which utilizes the structure of raptor-like LDPC codes and can deal with multiple code rates. In the proposed network, different portions of parameters are activated to deal with distinct code rates, which leads to parameter sharing among tasks. Numerical experiments demonstrate the effectiveness of the proposed method. Training the specially designed network under multiple code rates makes the decoder compatible with multiple code rates without sacrificing frame error rate performance.
A Latent Variable Approach for Non-Hierarchical Multi-Fidelity Adaptive Sampling
Oct 05, 2023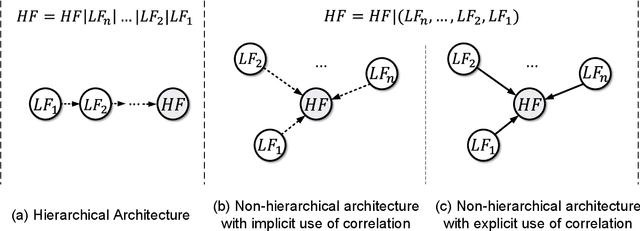
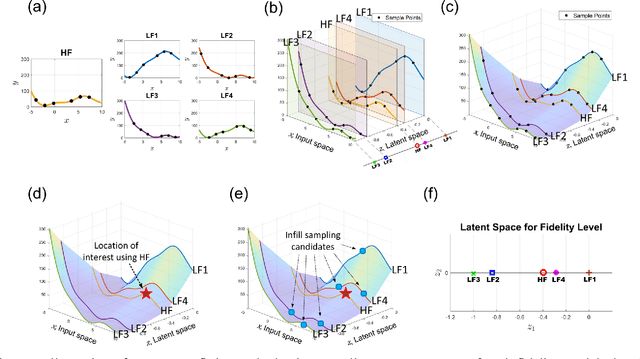

Multi-fidelity (MF) methods are gaining popularity for enhancing surrogate modeling and design optimization by incorporating data from various low-fidelity (LF) models. While most existing MF methods assume a fixed dataset, adaptive sampling methods that dynamically allocate resources among fidelity models can achieve higher efficiency in the exploring and exploiting the design space. However, most existing MF methods rely on the hierarchical assumption of fidelity levels or fail to capture the intercorrelation between multiple fidelity levels and utilize it to quantify the value of the future samples and navigate the adaptive sampling. To address this hurdle, we propose a framework hinged on a latent embedding for different fidelity models and the associated pre-posterior analysis to explicitly utilize their correlation for adaptive sampling. In this framework, each infill sampling iteration includes two steps: We first identify the location of interest with the greatest potential improvement using the high-fidelity (HF) model, then we search for the next sample across all fidelity levels that maximize the improvement per unit cost at the location identified in the first step. This is made possible by a single Latent Variable Gaussian Process (LVGP) model that maps different fidelity models into an interpretable latent space to capture their correlations without assuming hierarchical fidelity levels. The LVGP enables us to assess how LF sampling candidates will affect HF response with pre-posterior analysis and determine the next sample with the best benefit-to-cost ratio. Through test cases, we demonstrate that the proposed method outperforms the benchmark methods in both MF global fitting (GF) and Bayesian Optimization (BO) problems in convergence rate and robustness. Moreover, the method offers the flexibility to switch between GF and BO by simply changing the acquisition function.
DISC-LawLLM: Fine-tuning Large Language Models for Intelligent Legal Services
Sep 23, 2023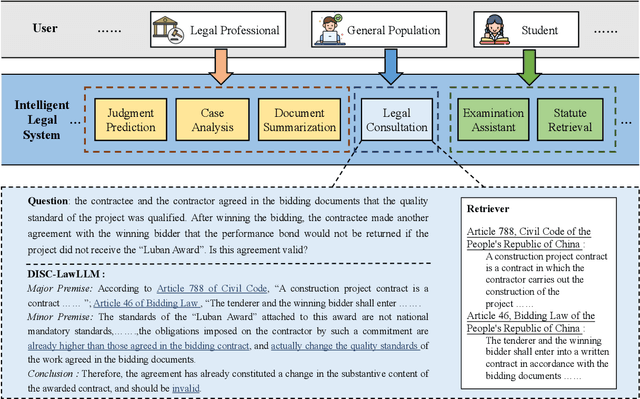
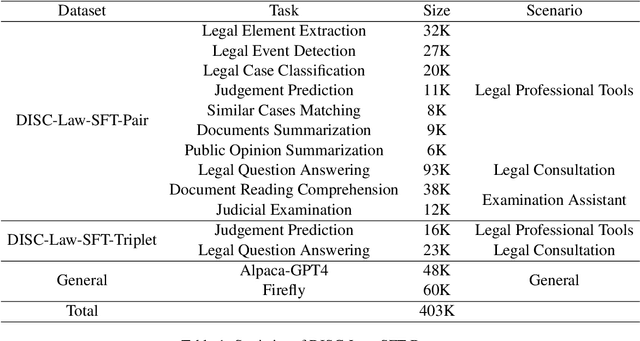
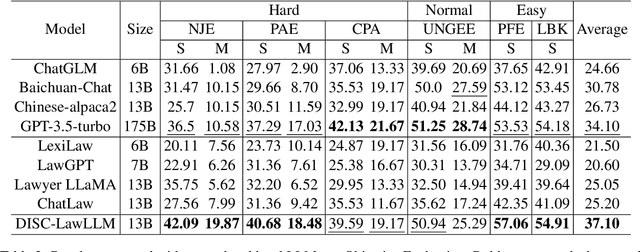
We propose DISC-LawLLM, an intelligent legal system utilizing large language models (LLMs) to provide a wide range of legal services. We adopt legal syllogism prompting strategies to construct supervised fine-tuning datasets in the Chinese Judicial domain and fine-tune LLMs with legal reasoning capability. We augment LLMs with a retrieval module to enhance models' ability to access and utilize external legal knowledge. A comprehensive legal benchmark, DISC-Law-Eval, is presented to evaluate intelligent legal systems from both objective and subjective dimensions. Quantitative and qualitative results on DISC-Law-Eval demonstrate the effectiveness of our system in serving various users across diverse legal scenarios. The detailed resources are available at https://github.com/FudanDISC/DISC-LawLLM.
A Comprehensive Study of PAPR Reduction Techniques for Deep Joint Source Channel Coding in OFDM Systems
Sep 21, 2023
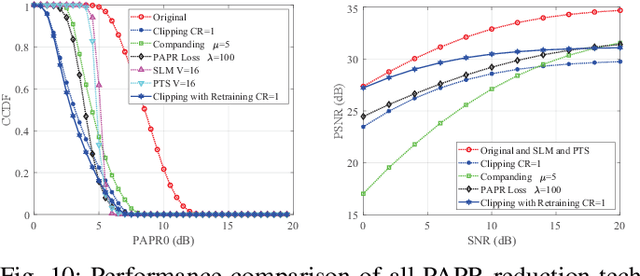
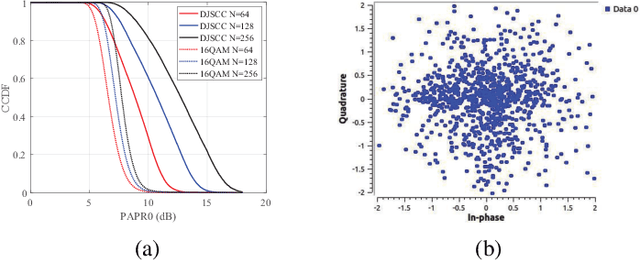
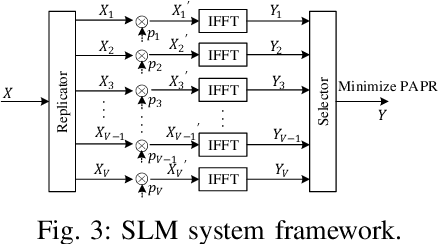
Recently, deep joint source channel coding (DJSCC) techniques have been extensively studied and have shown significant performance with limited bandwidth and low signal to noise ratio. Most DJSCC work considers discrete-time analog transmission, while combining it with orthogonal frequency division multiplexing (OFDM) creates serious high peak-to-average power ratio (PAPR) problem. This paper conducts a comprehensive analysis on the use of various OFDM PAPR reduction techniques in the DJSCC system, including both conventional techniques such as clipping, companding, SLM and PTS, and deep learning-based PAPR reduction techniques such as PAPR loss and clipping with retraining. Our investigation shows that although conventional PAPR reduction techniques can be applied to DJSCC, their performance in DJSCC is different from the conventional split source channel coding. Moreover, we observe that for signal distortion PAPR reduction techniques, clipping with retraining achieves the best performance in terms of both PAPR reduction and recovery accuracy. It is also noticed that signal non-distortion PAPR reduction techniques can successfully reduce the PAPR in DJSCC without compromise to signal reconstruction.
Reliability-Latency-Rate Tradeoff in Low-Latency Communications with Finite-Blocklength Coding
Sep 13, 2023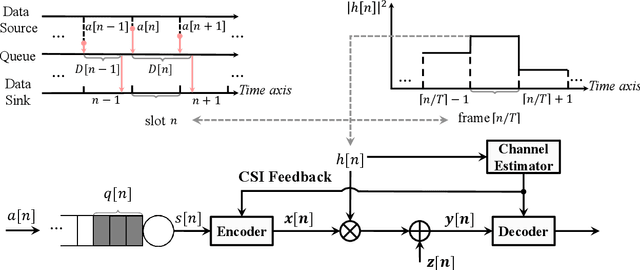
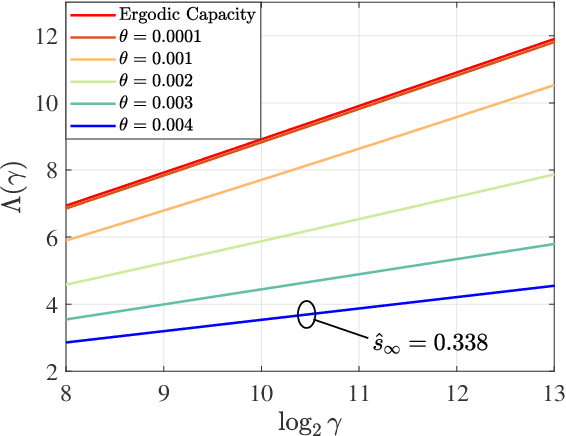
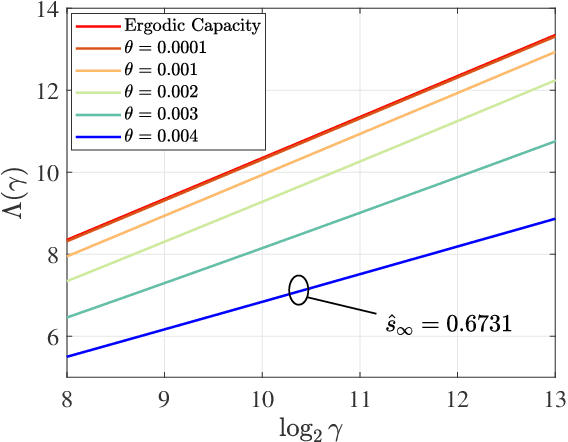
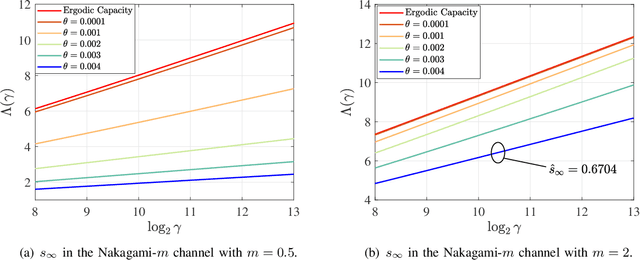
Low-latency communication plays an increasingly important role in delay-sensitive applications by ensuring the real-time exchange of information. However, due to the constraints on the maximum instantaneous power, bounded latency is hard to be guaranteed. In this paper, we investigate the reliability-latency-rate tradeoff in low-latency communications with finite-blocklength coding (FBC). More specifically, we are interested in the fundamental tradeoff between error probability, delay-violation probability (DVP), and service rate. Based on the effective capacity (EC) and normal approximation, we present several gain-conservation inequalities to bound the reliability-latency-rate tradeoffs. In particular, we investigate the low-latency transmissions over an additive white Gaussian noise (AWGN) channel, over a Rayleigh fading channel, with frequency or spatial diversity, and over a Nakagami-$m$ fading channel. To analytically evaluate the quality-of-service-constrained low-latency communications with FBC, an EC-approximation method is further conceived to derive the closed-form expression of quality-of-service-constrained throughput. For delay-sensitive transmissions in which the latency threshold is greater than the channel coherence time, we find an asymptotic form of the tradeoff between the error probability and DVP over the AWGN and Rayleigh fading channels. Our results may provide some insights into the efficient scheduling of low-latency wireless communications in which statistical latency and reliability metrics are adopted.