 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWarpformer: A Multi-scale Modeling Approach for Irregular Clinical Time Series
Jun 14, 2023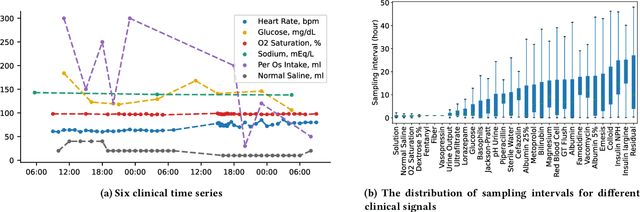
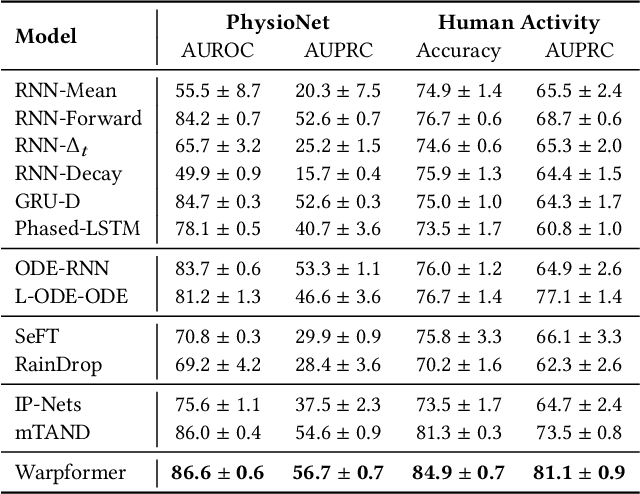
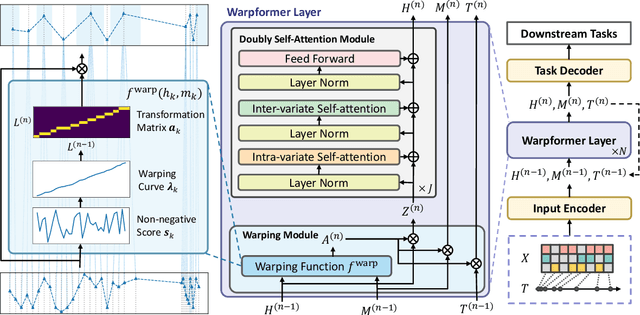
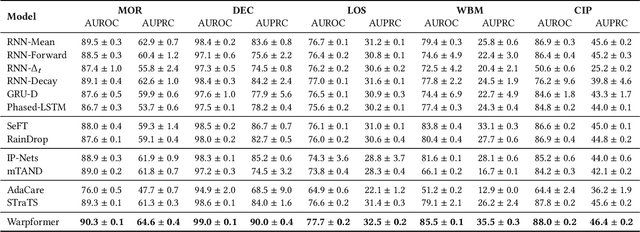
Irregularly sampled multivariate time series are ubiquitous in various fields, particularly in healthcare, and exhibit two key characteristics: intra-series irregularity and inter-series discrepancy. Intra-series irregularity refers to the fact that time-series signals are often recorded at irregular intervals, while inter-series discrepancy refers to the significant variability in sampling rates among diverse series. However, recent advances in irregular time series have primarily focused on addressing intra-series irregularity, overlooking the issue of inter-series discrepancy. To bridge this gap, we present Warpformer, a novel approach that fully considers these two characteristics. In a nutshell, Warpformer has several crucial designs, including a specific input representation that explicitly characterizes both intra-series irregularity and inter-series discrepancy, a warping module that adaptively unifies irregular time series in a given scale, and a customized attention module for representation learning. Additionally, we stack multiple warping and attention modules to learn at different scales, producing multi-scale representations that balance coarse-grained and fine-grained signals for downstream tasks. We conduct extensive experiments on widely used datasets and a new large-scale benchmark built from clinical databases. The results demonstrate the superiority of Warpformer over existing state-of-the-art approaches.
UADB: Unsupervised Anomaly Detection Booster
Jun 03, 2023



Unsupervised Anomaly Detection (UAD) is a key data mining problem owing to its wide real-world applications. Due to the complete absence of supervision signals, UAD methods rely on implicit assumptions about anomalous patterns (e.g., scattered/sparsely/densely clustered) to detect anomalies. However, real-world data are complex and vary significantly across different domains. No single assumption can describe such complexity and be valid in all scenarios. This is also confirmed by recent research that shows no UAD method is omnipotent. Based on above observations, instead of searching for a magic universal winner assumption, we seek to design a general UAD Booster (UADB) that empowers any UAD models with adaptability to different data. This is a challenging task given the heterogeneous model structures and assumptions adopted by existing UAD methods. To achieve this, we dive deep into the UAD problem and find that compared to normal data, anomalies (i) lack clear structure/pattern in feature space, thus (ii) harder to learn by model without a suitable assumption, and finally, leads to (iii) high variance between different learners. In light of these findings, we propose to (i) distill the knowledge of the source UAD model to an imitation learner (booster) that holds no data assumption, then (ii) exploit the variance between them to perform automatic correction, and thus (iii) improve the booster over the original UAD model. We use a neural network as the booster for its strong expressive power as a universal approximator and ability to perform flexible post-hoc tuning. Note that UADB is a model-agnostic framework that can enhance heterogeneous UAD models in a unified way. Extensive experiments on over 80 tabular datasets demonstrate the effectiveness of UADB.
Autonomous Driving Simulator based on Neurorobotics Platform
Dec 31, 2022



There are many artificial intelligence algorithms for autonomous driving, but directly installing these algorithms on vehicles is unrealistic and expensive. At the same time, many of these algorithms need an environment to train and optimize. Simulation is a valuable and meaningful solution with training and testing functions, and it can say that simulation is a critical link in the autonomous driving world. There are also many different applications or systems of simulation from companies or academies such as SVL and Carla. These simulators flaunt that they have the closest real-world simulation, but their environment objects, such as pedestrians and other vehicles around the agent-vehicle, are already fixed programmed. They can only move along the pre-setting trajectory, or random numbers determine their movements. What is the situation when all environmental objects are also installed by Artificial Intelligence, or their behaviors are like real people or natural reactions of other drivers? This problem is a blind spot for most of the simulation applications, or these applications cannot be easy to solve this problem. The Neurorobotics Platform from the TUM team of Prof. Alois Knoll has the idea about "Engines" and "Transceiver Functions" to solve the multi-agents problem. This report will start with a little research on the Neurorobotics Platform and analyze the potential and possibility of developing a new simulator to achieve the true real-world simulation goal. Then based on the NRP-Core Platform, this initial development aims to construct an initial demo experiment. The consist of this report starts with the basic knowledge of NRP-Core and its installation, then focus on the explanation of the necessary components for a simulation experiment, at last, about the details of constructions for the autonomous driving system, which is integrated object detection and autonomous control.
OpenFE: Automated Feature Generation beyond Expert-level Performance
Nov 22, 2022



The goal of automated feature generation is to liberate machine learning experts from the laborious task of manual feature generation, which is crucial for improving the learning performance of tabular data. The major challenge in automated feature generation is to efficiently and accurately identify useful features from a vast pool of candidate features. In this paper, we present OpenFE, an automated feature generation tool that provides competitive results against machine learning experts. OpenFE achieves efficiency and accuracy with two components: 1) a novel feature boosting method for accurately estimating the incremental performance of candidate features. 2) a feature-scoring framework for retrieving effective features from a large number of candidates through successive featurewise halving and feature importance attribution. Extensive experiments on seven benchmark datasets show that OpenFE outperforms existing baseline methods. We further evaluate OpenFE in two famous Kaggle competitions with thousands of data science teams participating. In one of the competitions, features generated by OpenFE with a simple baseline model can beat 99.3\% data science teams. In addition to the empirical results, we provide a theoretical perspective to show that feature generation is beneficial in a simple yet representative setting. The code is available at https://github.com/ZhangTP1996/OpenFE.
Less Is More: Fast Multivariate Time Series Forecasting with Light Sampling-oriented MLP Structures
Jul 04, 2022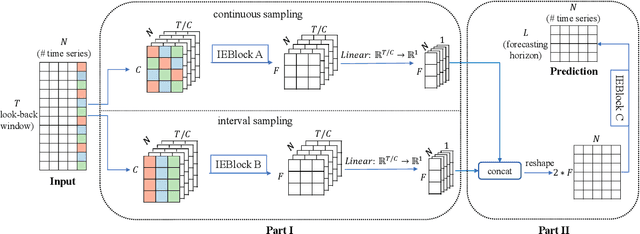
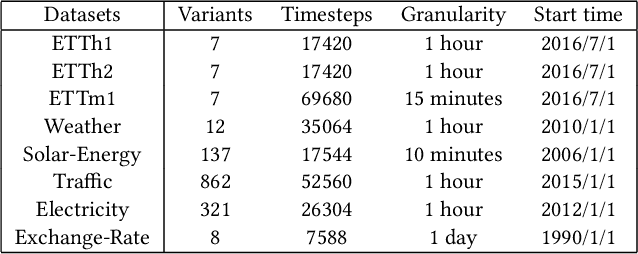
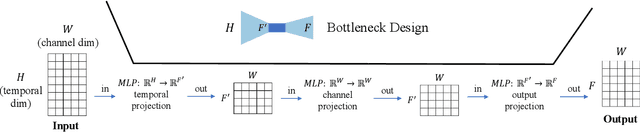
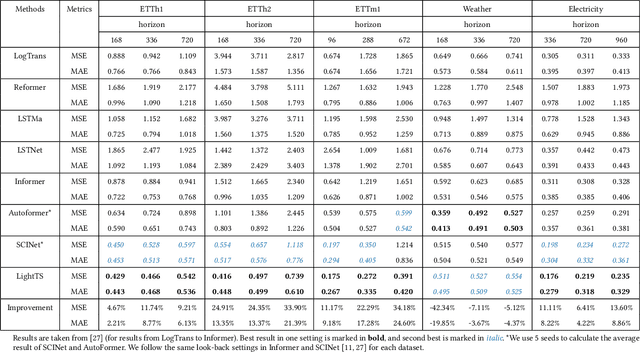
Multivariate time series forecasting has seen widely ranging applications in various domains, including finance, traffic, energy, and healthcare. To capture the sophisticated temporal patterns, plenty of research studies designed complex neural network architectures based on many variants of RNNs, GNNs, and Transformers. However, complex models are often computationally expensive and thus face a severe challenge in training and inference efficiency when applied to large-scale real-world datasets. In this paper, we introduce LightTS, a light deep learning architecture merely based on simple MLP-based structures. The key idea of LightTS is to apply an MLP-based structure on top of two delicate down-sampling strategies, including interval sampling and continuous sampling, inspired by a crucial fact that down-sampling time series often preserves the majority of its information. We conduct extensive experiments on eight widely used benchmark datasets. Compared with the existing state-of-the-art methods, LightTS demonstrates better performance on five of them and comparable performance on the rest. Moreover, LightTS is highly efficient. It uses less than 5% FLOPS compared with previous SOTA methods on the largest benchmark dataset. In addition, LightTS is robust and has a much smaller variance in forecasting accuracy than previous SOTA methods in long sequence forecasting tasks.
Family of Two Dimensional Transition Metal Dichlorides Fundamental Properties, Structural Defects, and Environmental Stability
Apr 29, 2022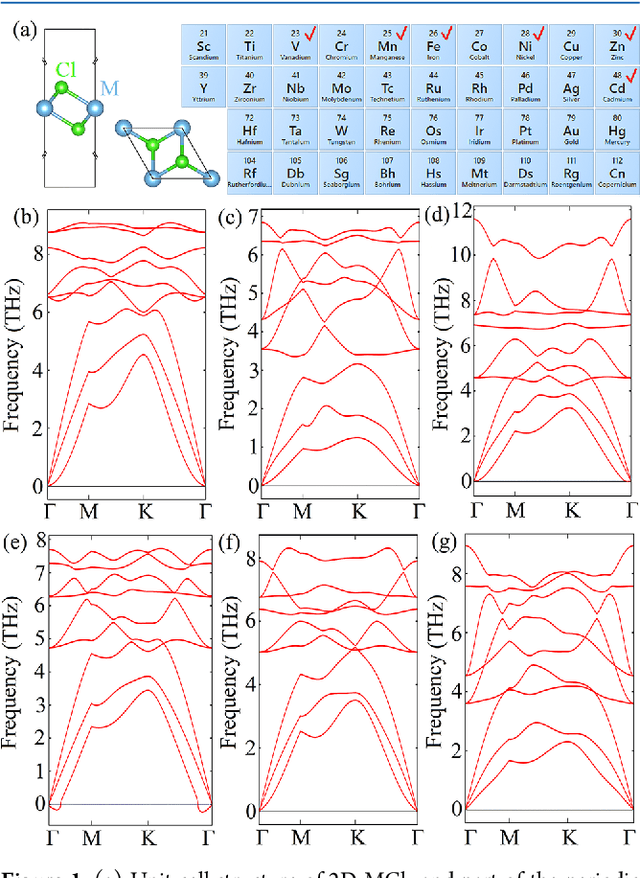
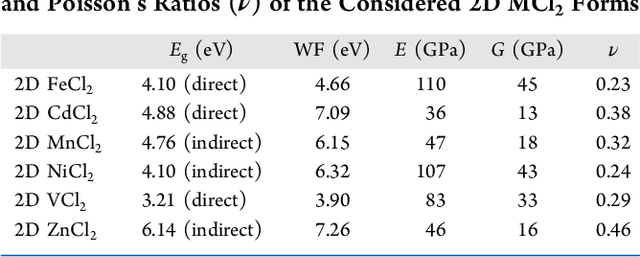
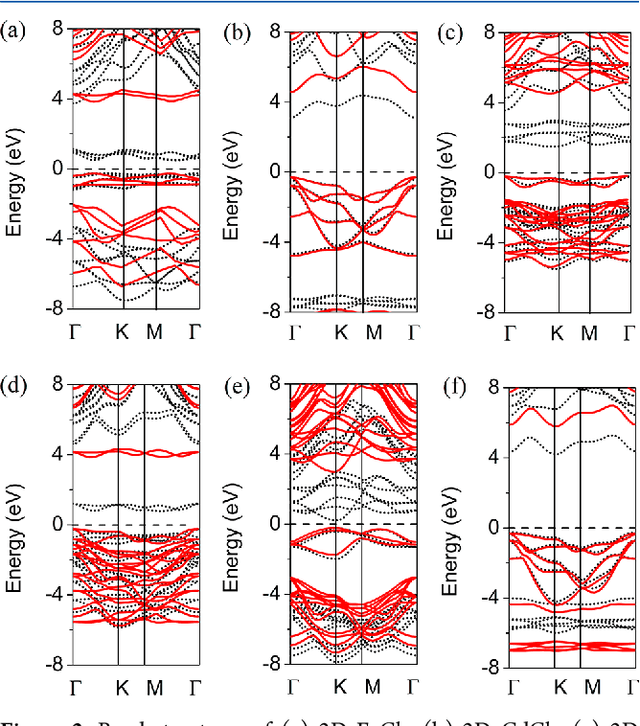
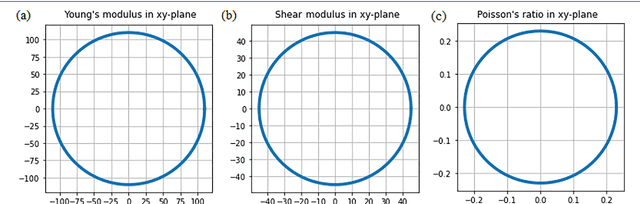
A large number of novel two-dimensional (2D) materials are constantly discovered and deposed into the databases. Consolidate implementation of machine learning algorithms and density functional theory (DFT) based predictions have allowed creating several databases containing an unimaginable amount of 2D samples. The next step in this chain, the investigation leads to a comprehensive study of the functionality of the invented materials. In this work, a family of transition metal dichlorides has been screened out for systematical investigation of their structural stability, fundamental properties, structural defects, and environmental stability via DFT based calculations. The work highlights the importance of using the potential of the invented materials and proposes a comprehensive characterization of a new family of 2D materials.
DEPTS: Deep Expansion Learning for Periodic Time Series Forecasting
Mar 15, 2022
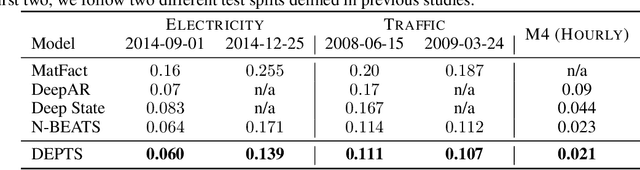
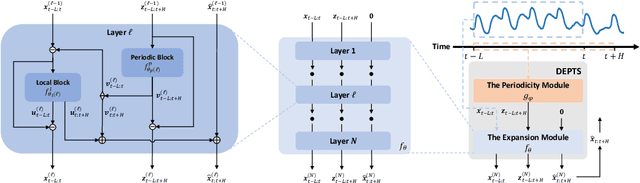
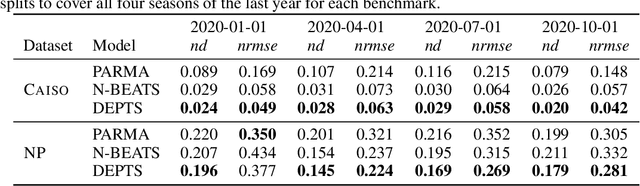
Periodic time series (PTS) forecasting plays a crucial role in a variety of industries to foster critical tasks, such as early warning, pre-planning, resource scheduling, etc. However, the complicated dependencies of the PTS signal on its inherent periodicity as well as the sophisticated composition of various periods hinder the performance of PTS forecasting. In this paper, we introduce a deep expansion learning framework, DEPTS, for PTS forecasting. DEPTS starts with a decoupled formulation by introducing the periodic state as a hidden variable, which stimulates us to make two dedicated modules to tackle the aforementioned two challenges. First, we develop an expansion module on top of residual learning to perform a layer-by-layer expansion of those complicated dependencies. Second, we introduce a periodicity module with a parameterized periodic function that holds sufficient capacity to capture diversified periods. Moreover, our two customized modules also have certain interpretable capabilities, such as attributing the forecasts to either local momenta or global periodicity and characterizing certain core periodic properties, e.g., amplitudes and frequencies. Extensive experiments on both synthetic data and real-world data demonstrate the effectiveness of DEPTS on handling PTS. In most cases, DEPTS achieves significant improvements over the best baseline. Specifically, the error reduction can even reach up to 20% for a few cases. Finally, all codes are publicly available.
Towards Inter-class and Intra-class Imbalance in Class-imbalanced Learning
Nov 24, 2021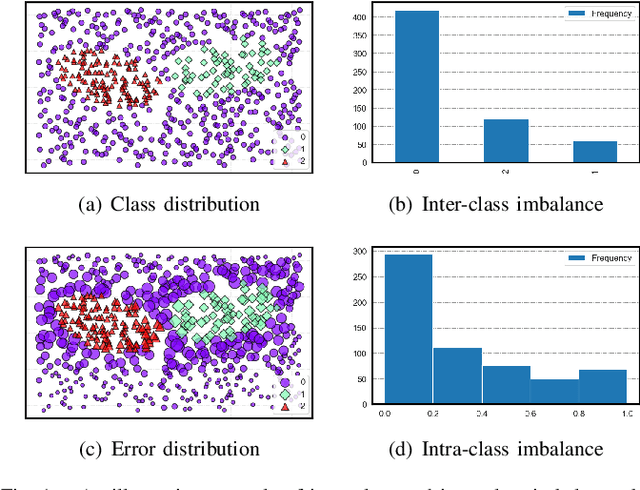
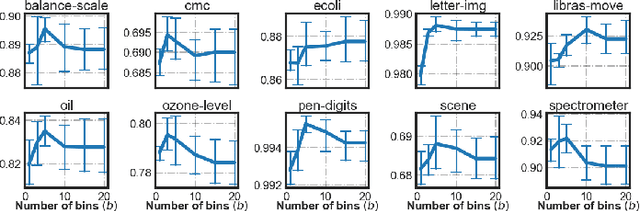
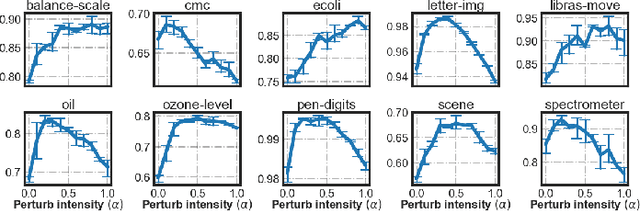
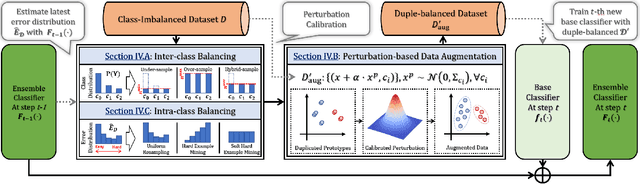
Imbalanced Learning (IL) is an important problem that widely exists in data mining applications. Typical IL methods utilize intuitive class-wise resampling or reweighting to directly balance the training set. However, some recent research efforts in specific domains show that class-imbalanced learning can be achieved without class-wise manipulation. This prompts us to think about the relationship between the two different IL strategies and the nature of the class imbalance. Fundamentally, they correspond to two essential imbalances that exist in IL: the difference in quantity between examples from different classes as well as between easy and hard examples within a single class, i.e., inter-class and intra-class imbalance. Existing works fail to explicitly take both imbalances into account and thus suffer from suboptimal performance. In light of this, we present Duple-Balanced Ensemble, namely DUBE , a versatile ensemble learning framework. Unlike prevailing methods, DUBE directly performs inter-class and intra-class balancing without relying on heavy distance-based computation, which allows it to achieve competitive performance while being computationally efficient. We also present a detailed discussion and analysis about the pros and cons of different inter/intra-class balancing strategies based on DUBE . Extensive experiments validate the effectiveness of the proposed method. Code and examples are available at https://github.com/ICDE2022Sub/duplebalance.
IMBENS: Ensemble Class-imbalanced Learning in Python
Nov 24, 2021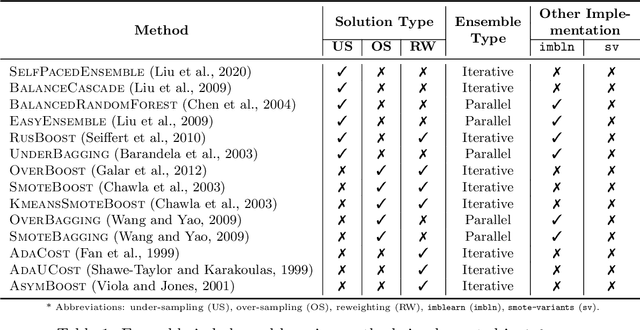
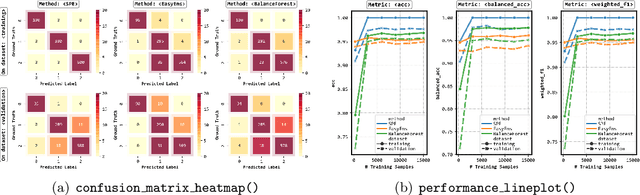
imbalanced-ensemble, abbreviated as imbens, is an open-source Python toolbox for quick implementing and deploying ensemble learning algorithms on class-imbalanced data. It provides access to multiple state-of-art ensemble imbalanced learning (EIL) methods, visualizer, and utility functions for dealing with the class imbalance problem. These ensemble methods include resampling-based, e.g., under/over-sampling, and reweighting-based ones, e.g., cost-sensitive learning. Beyond the implementation, we also extend conventional binary EIL algorithms with new functionalities like multi-class support and resampling scheduler, thereby enabling them to handle more complex tasks. The package was developed under a simple, well-documented API design follows that of scikit-learn for increased ease of use. imbens is released under the MIT open-source license and can be installed from Python Package Index (PyPI). Source code, binaries, detailed documentation, and usage examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.
Pinpointing the Memory Behaviors of DNN Training
Apr 01, 2021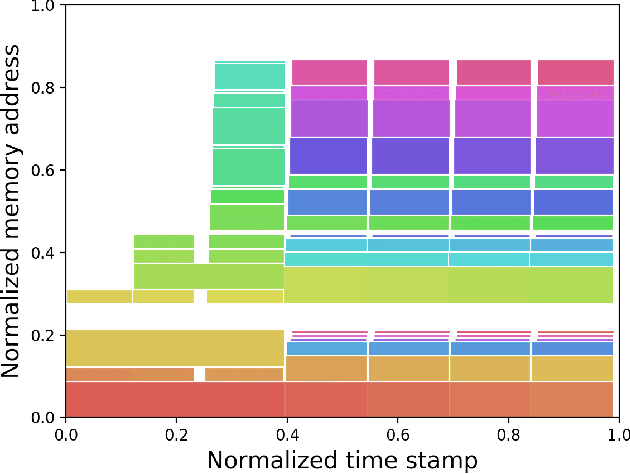
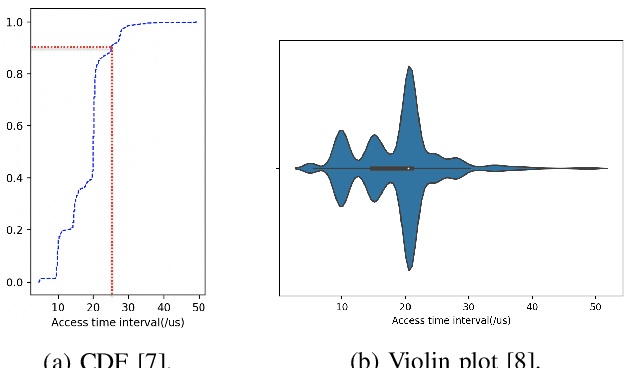
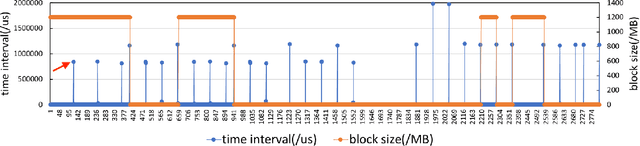
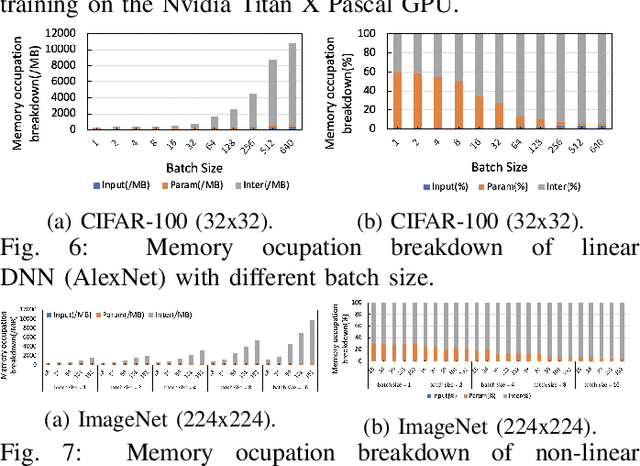
The training of deep neural networks (DNNs) is usually memory-hungry due to the limited device memory capacity of DNN accelerators. Characterizing the memory behaviors of DNN training is critical to optimize the device memory pressures. In this work, we pinpoint the memory behaviors of each device memory block of GPU during training by instrumenting the memory allocators of the runtime system. Our results show that the memory access patterns of device memory blocks are stable and follow an iterative fashion. These observations are useful for the future optimization of memory-efficient training from the perspective of raw memory access patterns.