 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACIFIC: Towards Proactive Conversational Question Answering over Tabular and Textual Data in Finance
Oct 17, 2022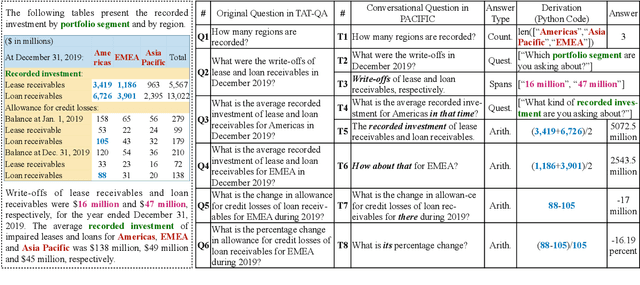
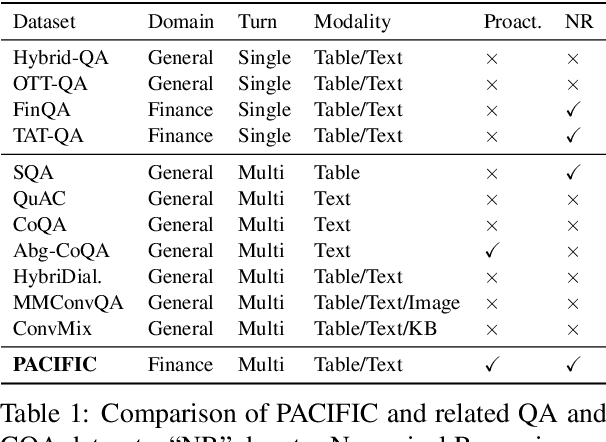
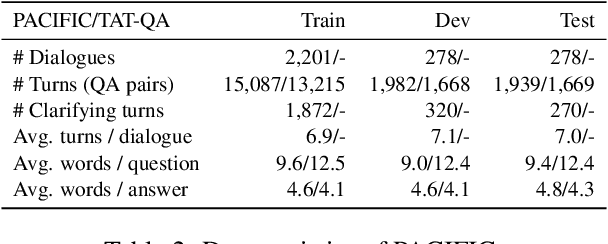

To facilitate conversational question answering (CQA) over hybrid contexts in finance, we present a new dataset, named PACIFIC. Compared with existing CQA datasets, PACIFIC exhibits three key features: (i) proactivity, (ii) numerical reasoning, and (iii) hybrid context of tables and text. A new task is defined accordingly to study Proactive Conversational Question Answering (PCQA), which combines clarification question generation and CQA. In addition, we propose a novel method, namely UniPCQA, to adapt a hybrid format of input and output content in PCQA into the Seq2Seq problem, including the reformulation of the numerical reasoning process as code generation. UniPCQA performs multi-task learning over all sub-tasks in PCQA and incorporates a simple ensemble strategy to alleviate the error propagation issue in the multi-task learning by cross-validating top-$k$ sampled Seq2Seq outputs. We benchmark the PACIFIC dataset with extensive baselines and provide comprehensive evaluations on each sub-task of PCQA.
Multilingual Transitivity and Bidirectional Multilingual Agreement for Multilingual Document-level Machine Translation
Oct 05, 2022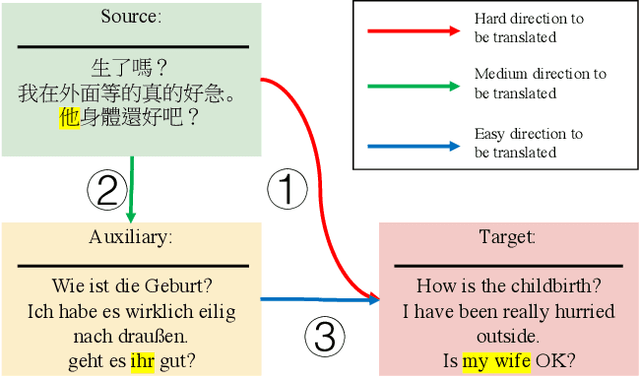
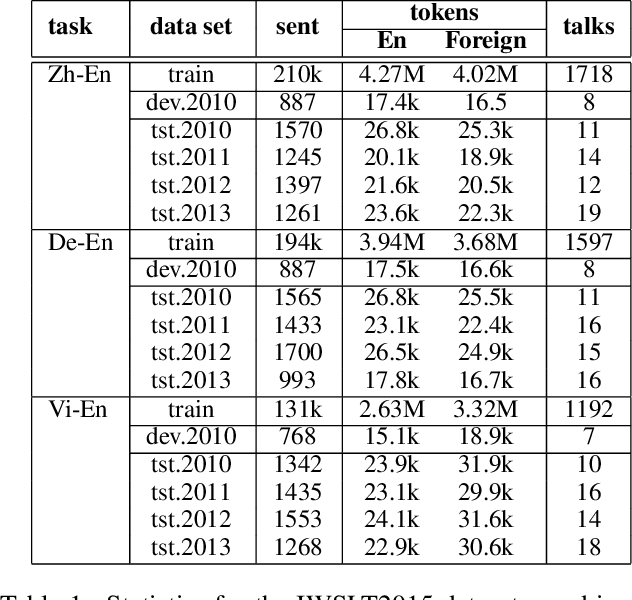
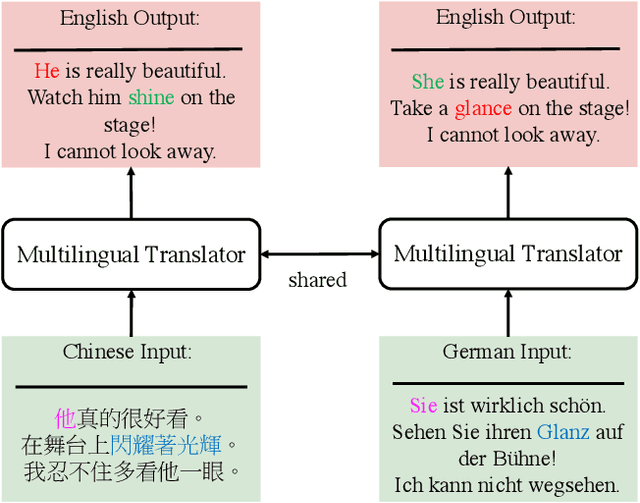

Multilingual machine translation has been proven an effective strategy to support translation between multiple languages with a single model. However, most studies focus on multilingual sentence translation without considering generating long documents across different languages, which requires an understanding of multilingual context dependency and is typically harder. In this paper, we first spot that naively incorporating auxiliary multilingual data either auxiliary-target or source-auxiliary brings no improvement to the source-target language pair in our interest. Motivated by this observation, we propose a novel framework called Multilingual Transitivity (MTrans) to find an implicit optimal route via source-auxiliary-target within the multilingual model. To encourage MTrans, we propose a novel method called Triplet Parallel Data (TPD), which uses parallel triplets that contain (source-auxiliary, auxiliary-target, and source-target) for training. The auxiliary language then serves as a pivot and automatically facilitates the implicit information transition flow which is easier to translate. We further propose a novel framework called Bidirectional Multilingual Agreement (Bi-MAgree) that encourages the bidirectional agreement between different languages. To encourage Bi-MAgree, we propose a novel method called Multilingual Kullback-Leibler Divergence (MKL) that forces the output distribution of the inputs with the same meaning but in different languages to be consistent with each other. The experimental results indicate that our methods bring consistent improvements over strong baselines on three document translation tasks: IWSLT2015 Zh-En, De-En, and Vi-En. Our analysis validates the usefulness and existence of MTrans and Bi-MAgree, and our frameworks and methods are effective on synthetic auxiliary data.
Informative Text Generation from Knowledge Triples
Sep 26, 2022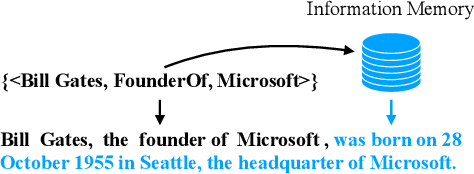
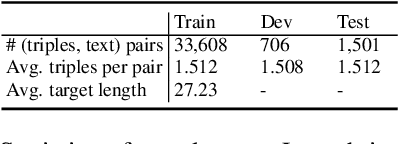
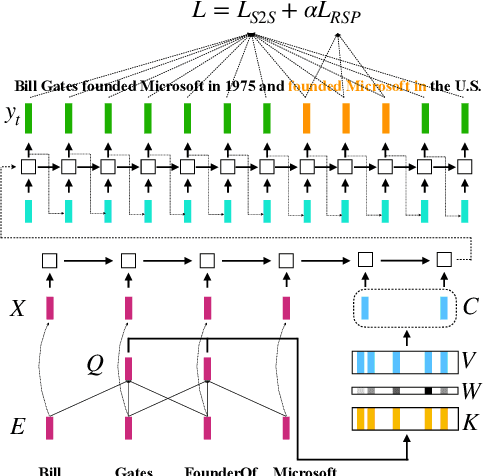
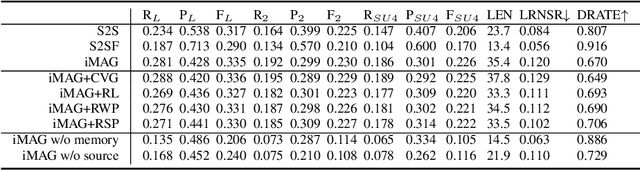
As the development of the encoder-decoder architecture, researchers are able to study the text generation tasks with broader types of data. Among them, KB-to-text aims at converting a set of knowledge triples into human readable sentences. In the original setting, the task assumes that the input triples and the text are exactly aligned in the perspective of the embodied knowledge/information. In this paper, we extend this setting and explore how to facilitate the trained model to generate more informative text, namely, containing more information about the triple entities but not conveyed by the input triples. To solve this problem, we propose a novel memory augmented generator that employs a memory network to memorize the useful knowledge learned during the training and utilizes such information together with the input triples to generate text in the operational or testing phase. We derive a dataset from WebNLG for our new setting and conduct extensive experiments to investigate the effectiveness of our model as well as uncover the intrinsic characteristics of the setting.
PCC: Paraphrasing with Bottom-k Sampling and Cyclic Learning for Curriculum Data Augmentation
Aug 17, 2022
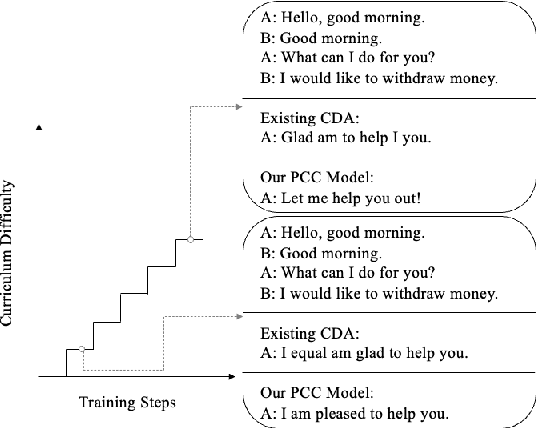
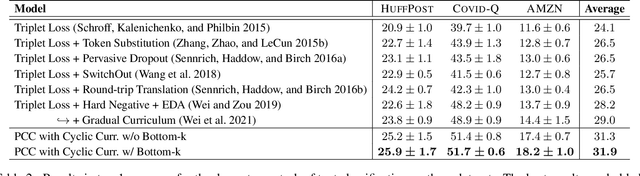
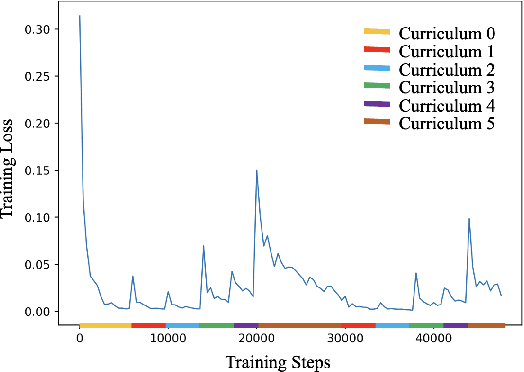
Curriculum Data Augmentation (CDA) improves neural models by presenting synthetic data with increasing difficulties from easy to hard. However, traditional CDA simply treats the ratio of word perturbation as the difficulty measure and goes through the curriculums only once. This paper presents \textbf{PCC}: \textbf{P}araphrasing with Bottom-k Sampling and \textbf{C}yclic Learning for \textbf{C}urriculum Data Augmentation, a novel CDA framework via paraphrasing, which exploits the textual paraphrase similarity as the curriculum difficulty measure. We propose a curriculum-aware paraphrase generation module composed of three units: a paraphrase candidate generator with bottom-k sampling, a filtering mechanism and a difficulty measure. We also propose a cyclic learning strategy that passes through the curriculums multiple times. The bottom-k sampling is proposed to generate super-hard instances for the later curriculums. Experimental results on few-shot text classification as well as dialogue generation indicate that PCC surpasses competitive baselines. Human evaluation and extensive case studies indicate that bottom-k sampling effectively generates super-hard instances, and PCC significantly improves the baseline dialogue agent.
UniGDD: A Unified Generative Framework for Goal-Oriented Document-Grounded Dialogue
Apr 16, 2022



The goal-oriented document-grounded dialogue aims at responding to the user query based on the dialogue context and supporting document. Existing studies tackle this problem by decomposing it into two sub-tasks: knowledge identification and response generation. However, such pipeline methods would unavoidably suffer from the error propagation issue. This paper proposes to unify these two sub-tasks via sequentially generating the grounding knowledge and the response. We further develop a prompt-connected multi-task learning strategy to model the characteristics and connections of different tasks and introduce linear temperature scheduling to reduce the negative effect of irrelevant document information. Experimental results demonstrate the effectiveness of our framework.
A Unified Multi-task Learning Framework for Multi-goal Conversational Recommender Systems
Apr 14, 2022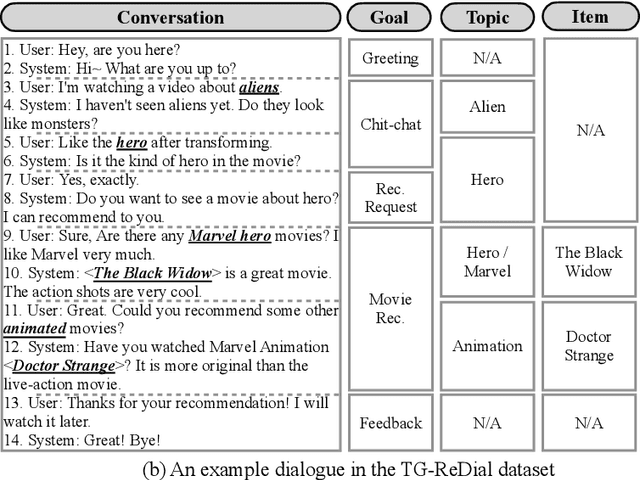
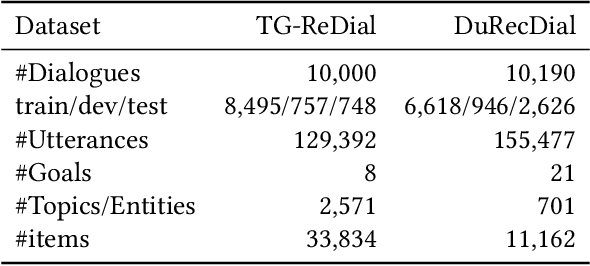
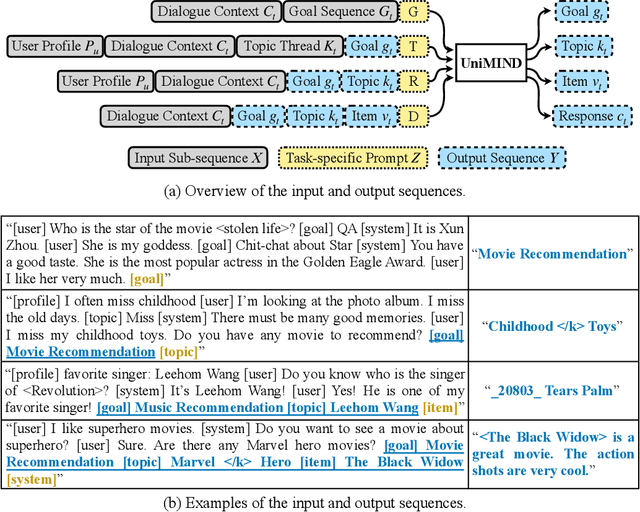
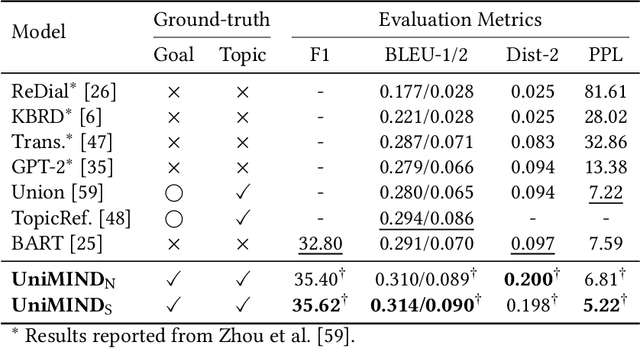
Recent years witnessed several advances in developing multi-goal conversational recommender systems (MG-CRS) that can proactively attract users' interests and naturally lead user-engaged dialogues with multiple conversational goals and diverse topics. Four tasks are often involved in MG-CRS, including Goal Planning, Topic Prediction, Item Recommendation, and Response Generation. Most existing studies address only some of these tasks. To handle the whole problem of MG-CRS, modularized frameworks are adopted where each task is tackled independently without considering their interdependencies. In this work, we propose a novel Unified MultI-goal conversational recommeNDer system, namely UniMIND. In specific, we unify these four tasks with different formulations into the same sequence-to-sequence (Seq2Seq) paradigm. Prompt-based learning strategies are investigated to endow the unified model with the capability of multi-task learning. Finally, the overall learning and inference procedure consists of three stages, including multi-task learning, prompt-based tuning, and inference. Experimental results on two MG-CRS benchmarks (DuRecDial and TG-ReDial) show that UniMIND achieves state-of-the-art performance on all tasks with a unified model. Extensive analyses and discussions are provided for shedding some new perspectives for MG-CRS.
Parameter-Efficient Tuning by Manipulating Hidden States of Pretrained Language Models For Classification Tasks
Apr 13, 2022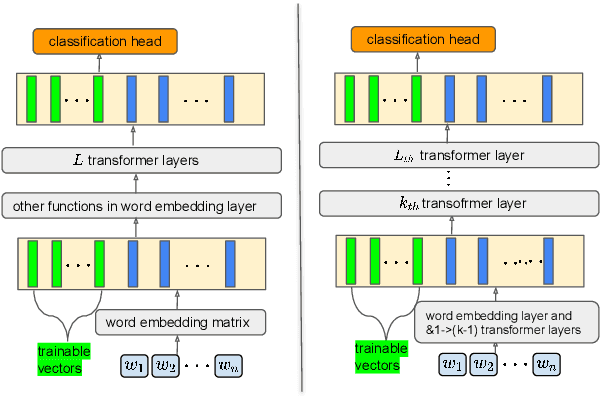
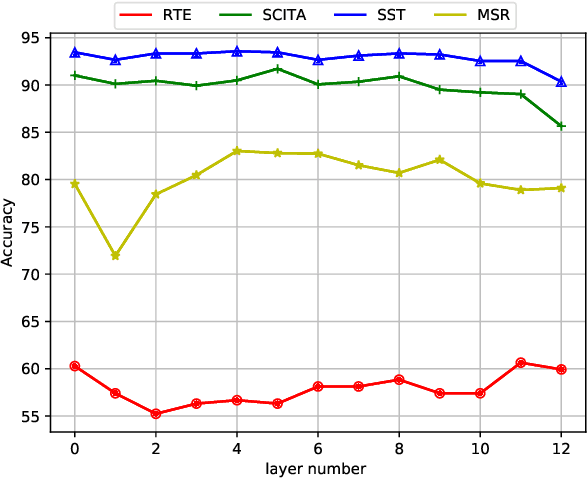
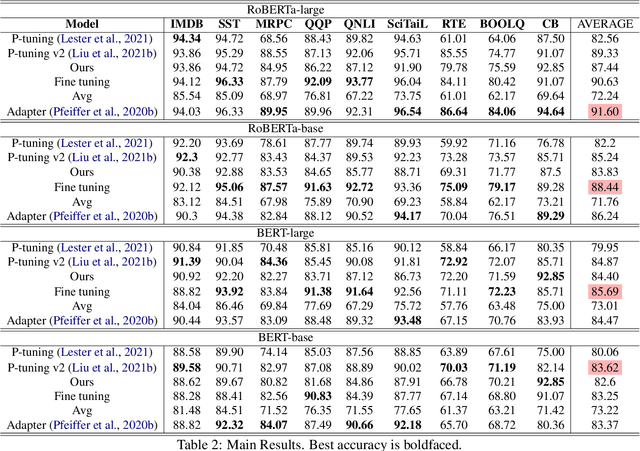
Parameter-efficient tuning aims to distill knowledge for downstream tasks by optimizing a few introduced parameters while freezing the pretrained language models (PLMs). Continuous prompt tuning which prepends a few trainable vectors to the embeddings of input is one of these methods and has drawn much attention due to its effectiveness and efficiency. This family of methods can be illustrated as exerting nonlinear transformations of hidden states inside PLMs. However, a natural question is ignored: can the hidden states be directly used for classification without changing them? In this paper, we aim to answer this question by proposing a simple tuning method which only introduces three trainable vectors. Firstly, we integrate all layers hidden states using the introduced vectors. And then, we input the integrated hidden state(s) to a task-specific linear classifier to predict categories. This scheme is similar to the way ELMo utilises hidden states except that they feed the hidden states to LSTM-based models. Although our proposed tuning scheme is simple, it achieves comparable performance with prompt tuning methods like P-tuning and P-tuning v2, verifying that original hidden states do contain useful information for classification tasks. Moreover, our method has an advantage over prompt tuning in terms of time and the number of parameters.
A Survey on Aspect-Based Sentiment Analysis: Tasks, Methods, and Challenges
Mar 02, 2022
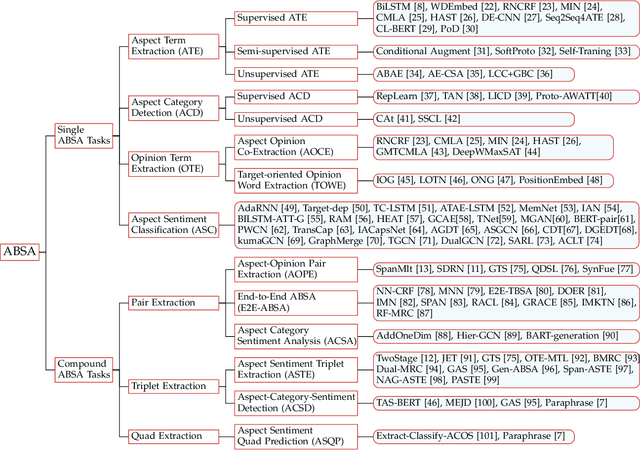
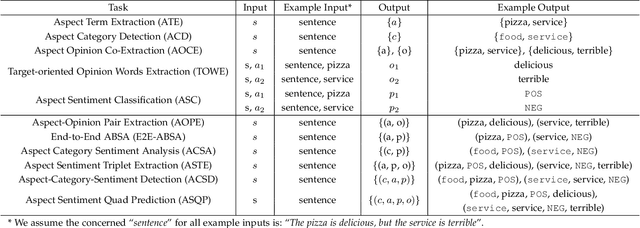
As an important fine-grained sentiment analysis problem, aspect-based sentiment analysis (ABSA), aiming to analyze and understand people's opinions at the aspect level, has been attracting considerable interest in the last decade. To handle ABSA in different scenarios, various tasks have been introduced for analyzing different sentiment elements and their relations, including the aspect term, aspect category, opinion term, and sentiment polarity. Unlike early ABSA works focusing on a single sentiment element, many compound ABSA tasks involving multiple elements have been studied in recent years for capturing more complete aspect-level sentiment information. However, a systematic review of various ABSA tasks and their corresponding solutions is still lacking, which we aim to fill in this survey. More specifically, we provide a new taxonomy for ABSA which organizes existing studies from the axes of concerned sentiment elements, with an emphasis on recent advances of compound ABSA tasks. From the perspective of solutions, we summarize the utilization of pre-trained language models for ABSA, which improved the performance of ABSA to a new stage. Besides, techniques for building more practical ABSA systems in cross-domain/lingual scenarios are discussed. Finally, we review some emerging topics and discuss some open challenges to outlook potential future directions of ABSA.
Improving Lexical Embeddings for Robust Question Answering
Feb 28, 2022
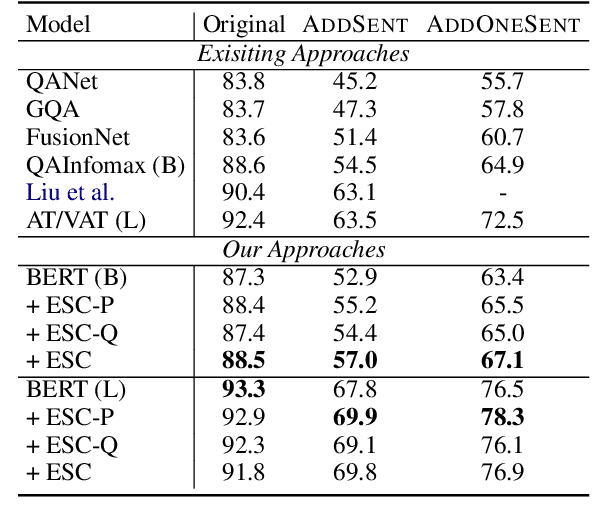
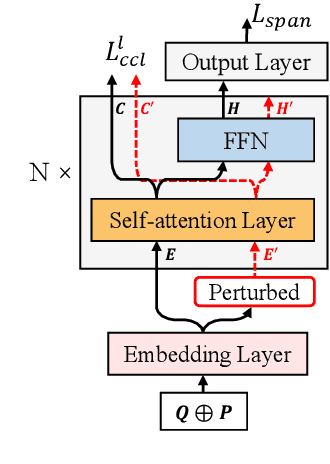
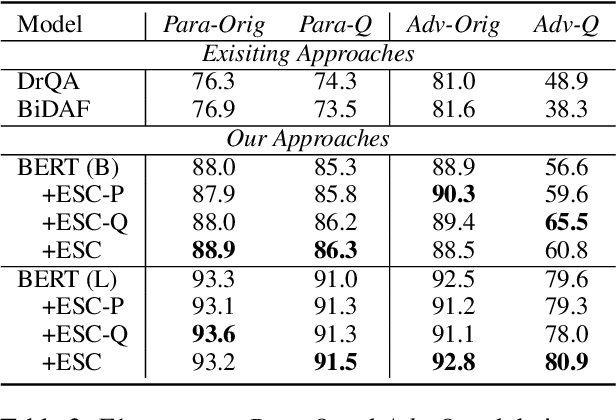
Recent techniques in Question Answering (QA) have gained remarkable performance improvement with some QA models even surpassed human performance. However, the ability of these models in truly understanding the language still remains dubious and the models are revealing limitations when facing adversarial examples. To strengthen the robustness of QA models and their generalization ability, we propose a representation Enhancement via Semantic and Context constraints (ESC) approach to improve the robustness of lexical embeddings. Specifically, we insert perturbations with semantic constraints and train enhanced contextual representations via a context-constraint loss to better distinguish the context clues for the correct answer. Experimental results show that our approach gains significant robustness improvement on four adversarial test sets.
User Satisfaction Estimation with Sequential Dialogue Act Modeling in Goal-oriented Conversational Systems
Feb 07, 2022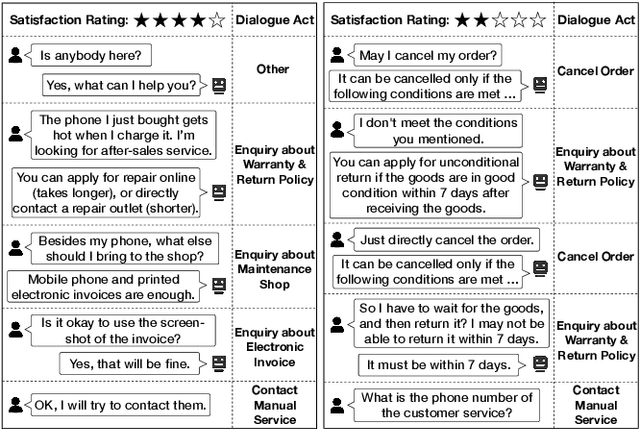
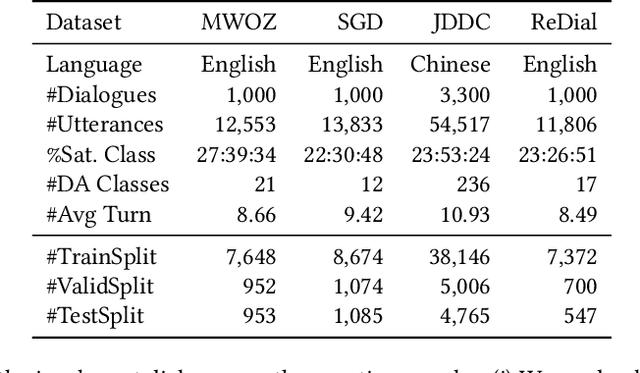
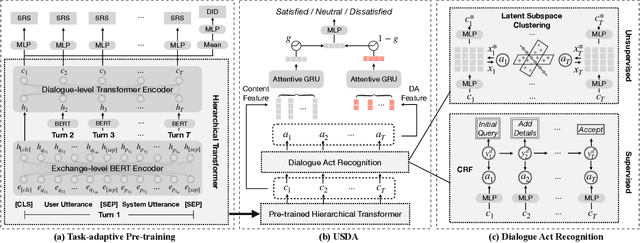
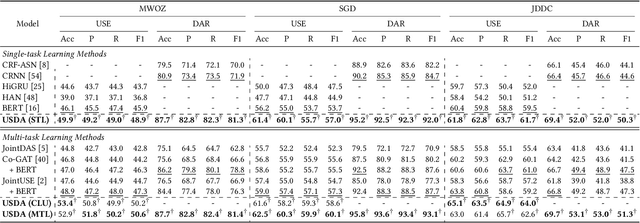
User Satisfaction Estimation (USE) is an important yet challenging task in goal-oriented conversational systems. Whether the user is satisfied with the system largely depends on the fulfillment of the user's needs, which can be implicitly reflected by users' dialogue acts. However, existing studies often neglect the sequential transitions of dialogue act or rely heavily on annotated dialogue act labels when utilizing dialogue acts to facilitate USE. In this paper, we propose a novel framework, namely USDA, to incorporate the sequential dynamics of dialogue acts for predicting user satisfaction, by jointly learning User Satisfaction Estimation and Dialogue Act Recognition tasks. In specific, we first employ a Hierarchical Transformer to encode the whole dialogue context, with two task-adaptive pre-training strategies to be a second-phase in-domain pre-training for enhancing the dialogue modeling ability. In terms of the availability of dialogue act labels, we further develop two variants of USDA to capture the dialogue act information in either supervised or unsupervised manners. Finally, USDA leverages the sequential transitions of both content and act features in the dialogue to predict the user satisfaction. Experimental results on four benchmark goal-oriented dialogue datasets across different applications show that the proposed method substantially and consistently outperforms existing methods on USE, and validate the important role of dialogue act sequences in USE.