 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHabitat 2.0: Training Home Assistants to Rearrange their Habitat
Jun 28, 2021


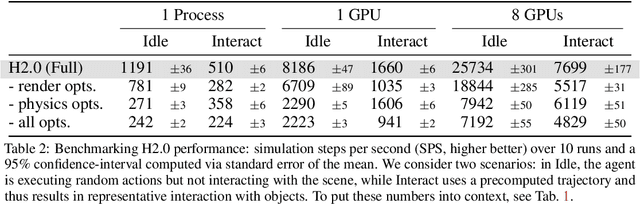
We introduce Habitat 2.0 (H2.0), a simulation platform for training virtual robots in interactive 3D environments and complex physics-enabled scenarios. We make comprehensive contributions to all levels of the embodied AI stack - data, simulation, and benchmark tasks. Specifically, we present: (i) ReplicaCAD: an artist-authored, annotated, reconfigurable 3D dataset of apartments (matching real spaces) with articulated objects (e.g. cabinets and drawers that can open/close); (ii) H2.0: a high-performance physics-enabled 3D simulator with speeds exceeding 25,000 simulation steps per second (850x real-time) on an 8-GPU node, representing 100x speed-ups over prior work; and, (iii) Home Assistant Benchmark (HAB): a suite of common tasks for assistive robots (tidy the house, prepare groceries, set the table) that test a range of mobile manipulation capabilities. These large-scale engineering contributions allow us to systematically compare deep reinforcement learning (RL) at scale and classical sense-plan-act (SPA) pipelines in long-horizon structured tasks, with an emphasis on generalization to new objects, receptacles, and layouts. We find that (1) flat RL policies struggle on HAB compared to hierarchical ones; (2) a hierarchy with independent skills suffers from 'hand-off problems', and (3) SPA pipelines are more brittle than RL policies.
Stabilizing Equilibrium Models by Jacobian Regularization
Jun 28, 2021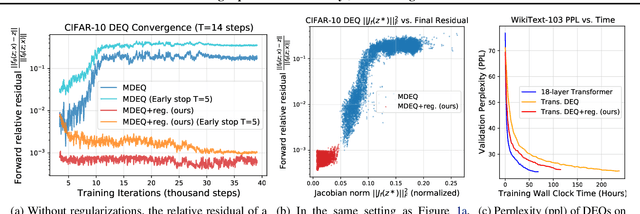
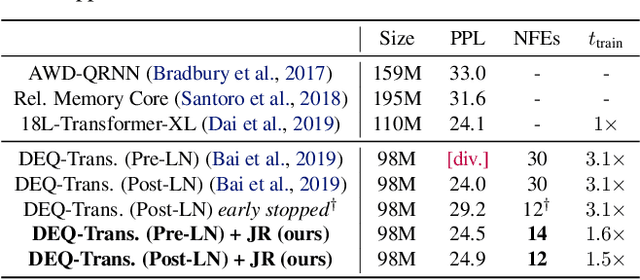
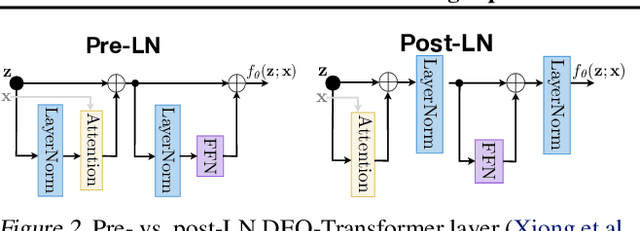
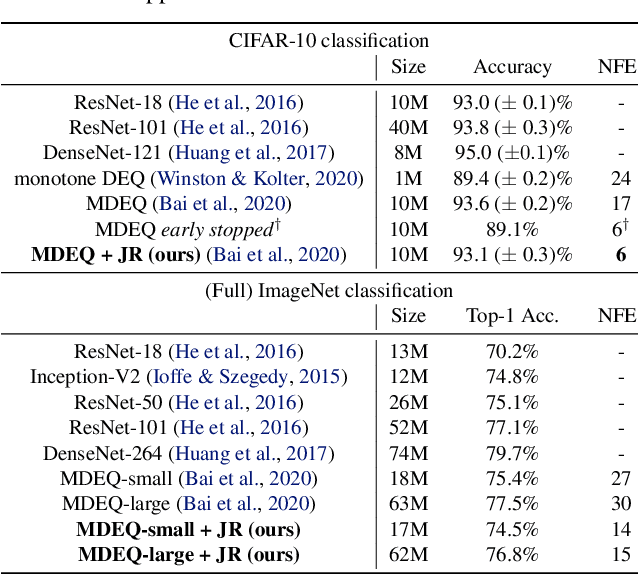
Deep equilibrium networks (DEQs) are a new class of models that eschews traditional depth in favor of finding the fixed point of a single nonlinear layer. These models have been shown to achieve performance competitive with the state-of-the-art deep networks while using significantly less memory. Yet they are also slower, brittle to architectural choices, and introduce potential instability to the model. In this paper, we propose a regularization scheme for DEQ models that explicitly regularizes the Jacobian of the fixed-point update equations to stabilize the learning of equilibrium models. We show that this regularization adds only minimal computational cost, significantly stabilizes the fixed-point convergence in both forward and backward passes, and scales well to high-dimensional, realistic domains (e.g., WikiText-103 language modeling and ImageNet classification). Using this method, we demonstrate, for the first time, an implicit-depth model that runs with approximately the same speed and level of performance as popular conventional deep networks such as ResNet-101, while still maintaining the constant memory footprint and architectural simplicity of DEQs. Code is available at https://github.com/locuslab/deq .
Training Graph Neural Networks with 1000 Layers
Jun 17, 2021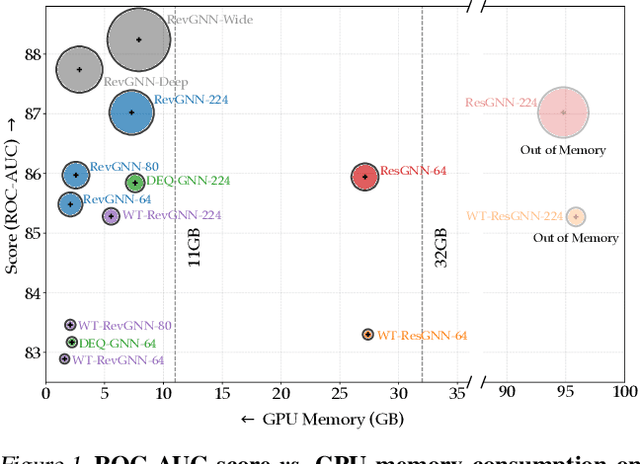
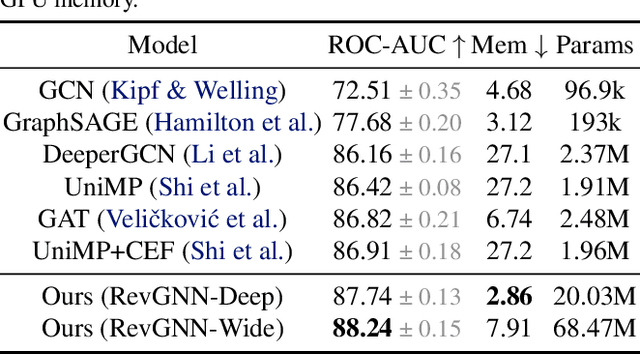
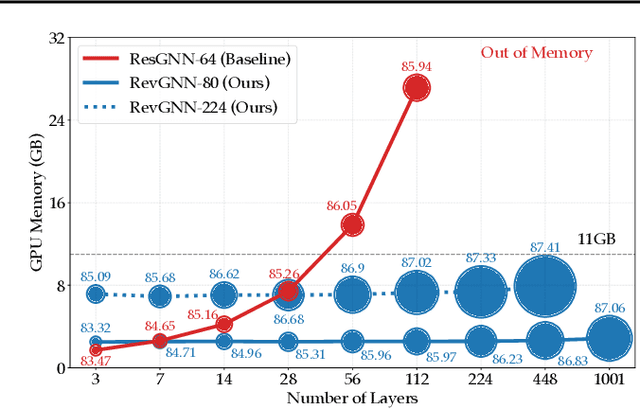
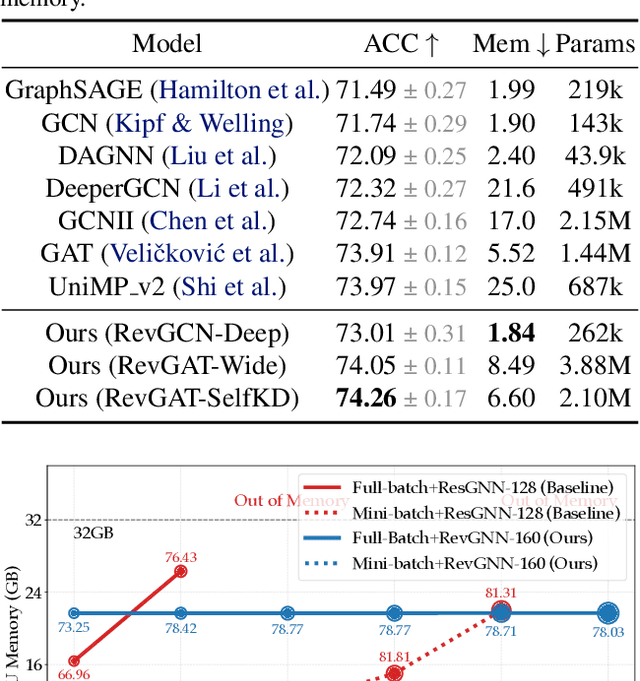
Deep graph neural networks (GNNs) have achieved excellent results on various tasks on increasingly large graph datasets with millions of nodes and edges. However, memory complexity has become a major obstacle when training deep GNNs for practical applications due to the immense number of nodes, edges, and intermediate activations. To improve the scalability of GNNs, prior works propose smart graph sampling or partitioning strategies to train GNNs with a smaller set of nodes or sub-graphs. In this work, we study reversible connections, group convolutions, weight tying, and equilibrium models to advance the memory and parameter efficiency of GNNs. We find that reversible connections in combination with deep network architectures enable the training of overparameterized GNNs that significantly outperform existing methods on multiple datasets. Our models RevGNN-Deep (1001 layers with 80 channels each) and RevGNN-Wide (448 layers with 224 channels each) were both trained on a single commodity GPU and achieve an ROC-AUC of $87.74 \pm 0.13$ and $88.24 \pm 0.15$ on the ogbn-proteins dataset. To the best of our knowledge, RevGNN-Deep is the deepest GNN in the literature by one order of magnitude. Please visit our project website https://www.deepgcns.org/arch/gnn1000 for more information.
A Measure of Research Taste
May 17, 2021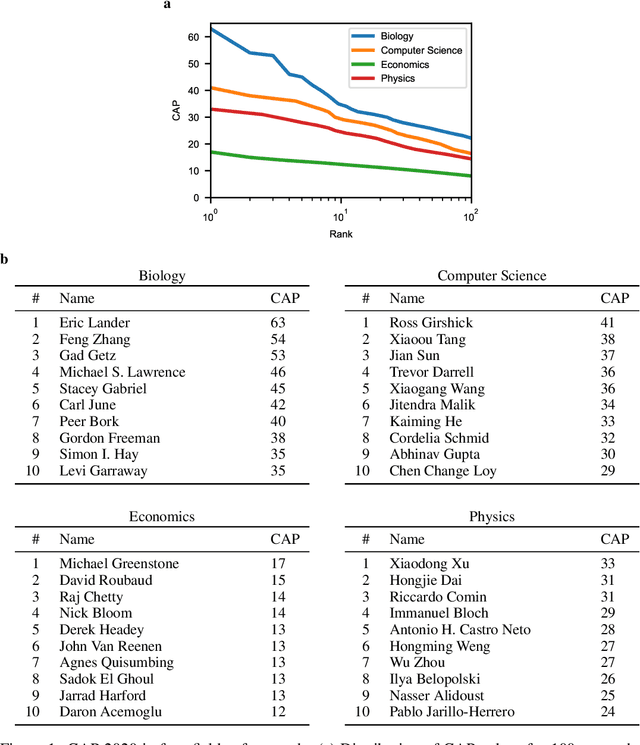
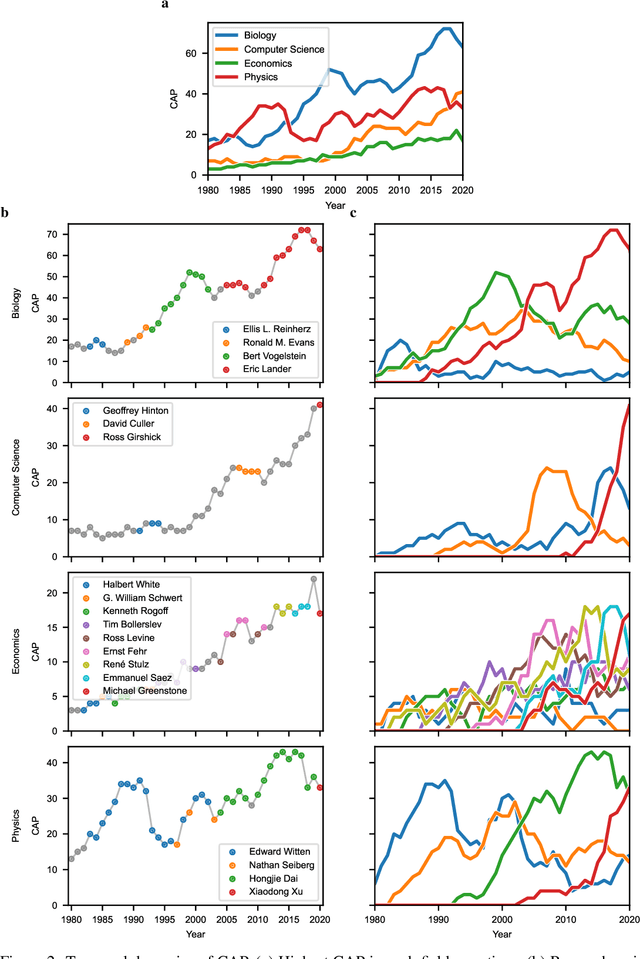
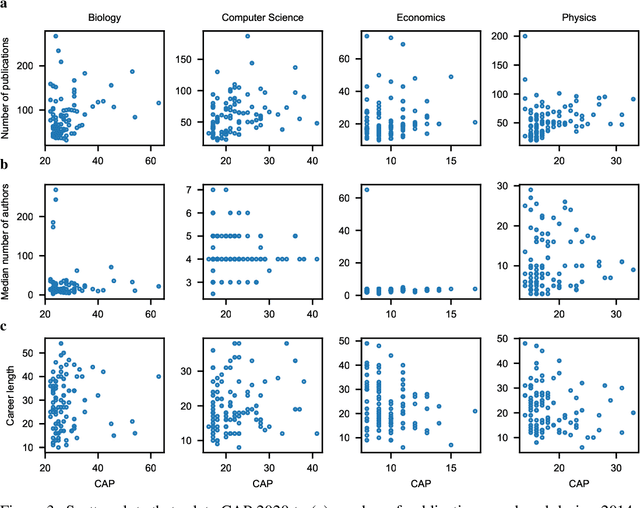
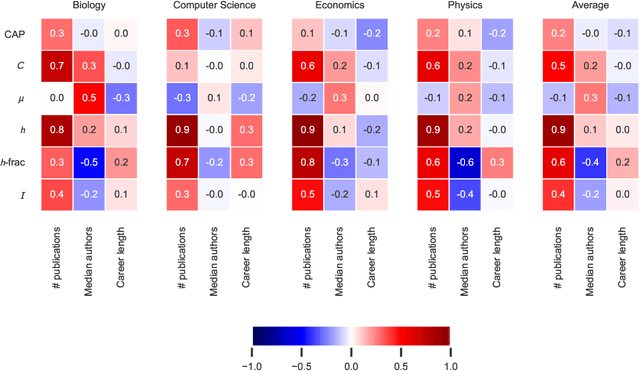
Researchers are often evaluated by citation-based metrics. Such metrics can inform hiring, promotion, and funding decisions. Concerns have been expressed that popular citation-based metrics incentivize researchers to maximize the production of publications. Such incentives may not be optimal for scientific progress. Here we present a citation-based measure that rewards both productivity and taste: the researcher's ability to focus on impactful contributions. The presented measure, CAP, balances the impact of publications and their quantity, thus incentivizing researchers to consider whether a publication is a useful addition to the literature. CAP is simple, interpretable, and parameter-free. We analyze the characteristics of CAP for highly-cited researchers in biology, computer science, economics, and physics, using a corpus of millions of publications and hundreds of millions of citations with yearly temporal granularity. CAP produces qualitatively plausible outcomes and has a number of advantages over prior metrics. Results can be explored at https://cap-measure.org/
Enhancing Photorealism Enhancement
May 10, 2021
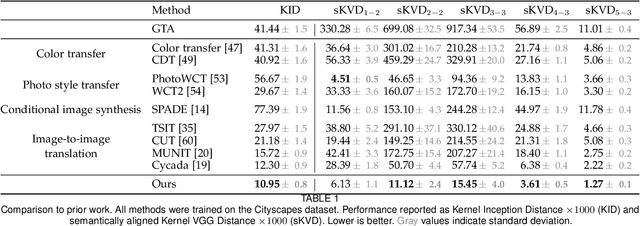

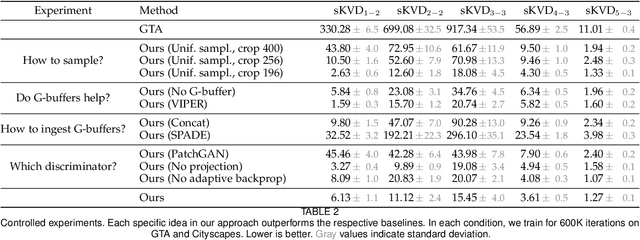
We present an approach to enhancing the realism of synthetic images. The images are enhanced by a convolutional network that leverages intermediate representations produced by conventional rendering pipelines. The network is trained via a novel adversarial objective, which provides strong supervision at multiple perceptual levels. We analyze scene layout distributions in commonly used datasets and find that they differ in important ways. We hypothesize that this is one of the causes of strong artifacts that can be observed in the results of many prior methods. To address this we propose a new strategy for sampling image patches during training. We also introduce multiple architectural improvements in the deep network modules used for photorealism enhancement. We confirm the benefits of our contributions in controlled experiments and report substantial gains in stability and realism in comparison to recent image-to-image translation methods and a variety of other baselines.
Learning to drive from a world on rails
May 03, 2021
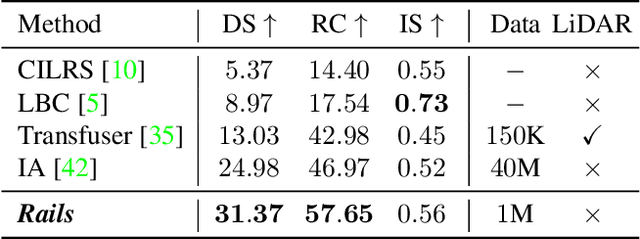

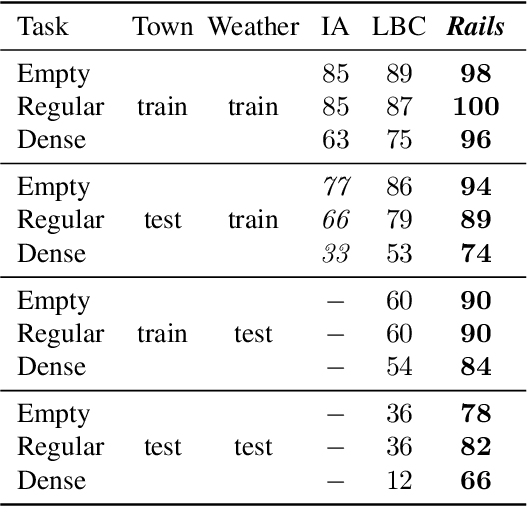
We learn an interactive vision-based driving policy from pre-recorded driving logs via a model-based approach. A forward model of the world supervises a driving policy that predicts the outcome of any potential driving trajectory. To support learning from pre-recorded logs, we assume that the world is on rails, meaning neither the agent nor its actions influence the environment. This assumption greatly simplifies the learning problem, factorizing the dynamics into a nonreactive world model and a low-dimensional and compact forward model of the ego-vehicle. Our approach computes action-values for each training trajectory using a tabular dynamic-programming evaluation of the Bellman equations; these action-values in turn supervise the final vision-based driving policy. Despite the world-on-rails assumption, the final driving policy acts well in a dynamic and reactive world. Our method ranks first on the CARLA leaderboard, attaining a 25% higher driving score while using 40 times less data. Our method is also an order of magnitude more sample-efficient than state-of-the-art model-free reinforcement learning techniques on navigational tasks in the ProcGen benchmark.
Vision Transformers for Dense Prediction
Mar 24, 2021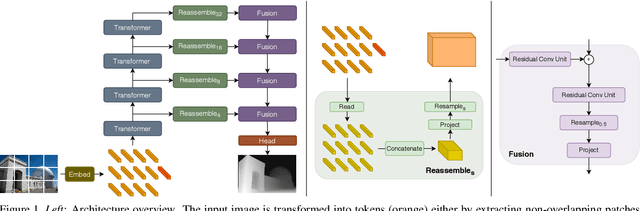
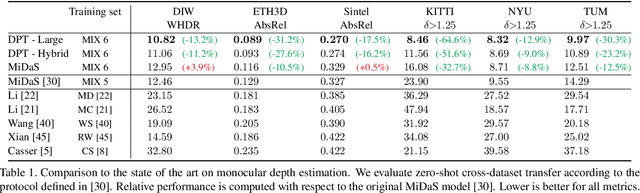
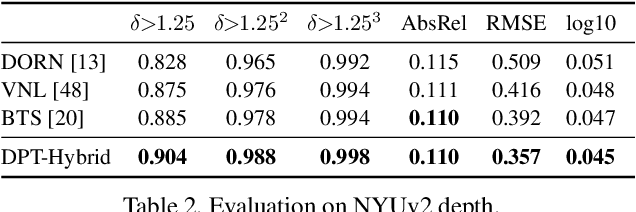

We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art. Our models are available at https://github.com/intel-isl/DPT.
Probabilistic two-stage detection
Mar 12, 2021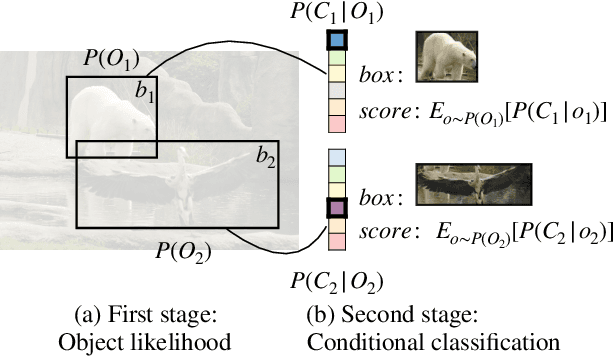
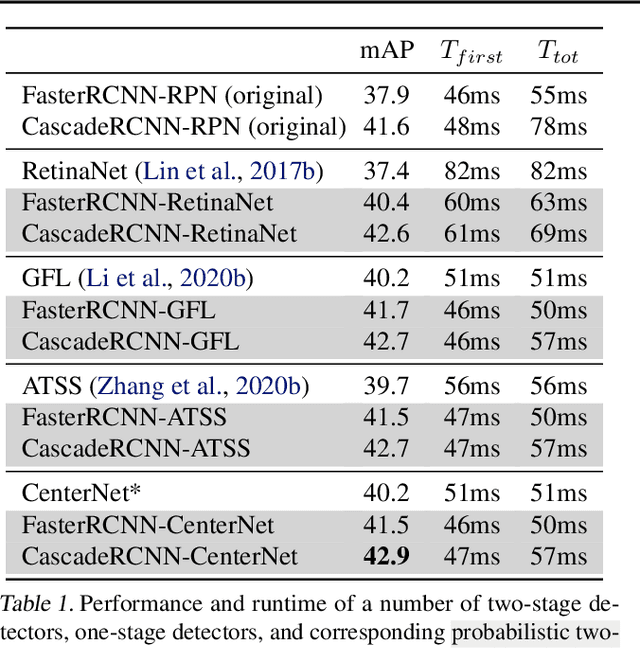
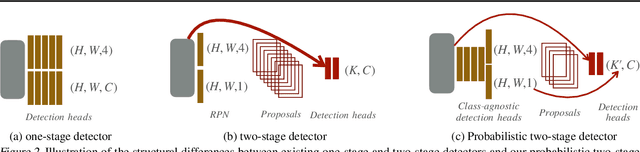
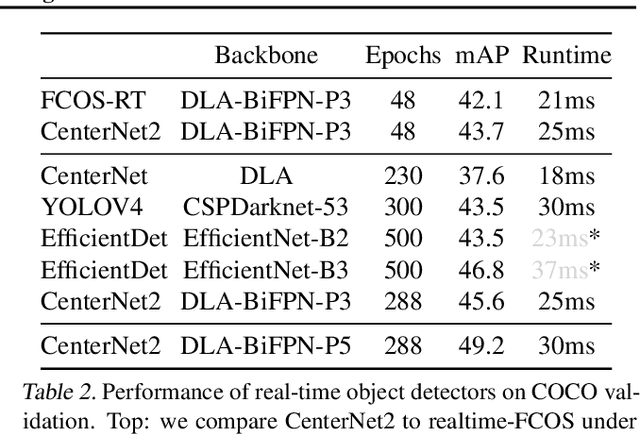
We develop a probabilistic interpretation of two-stage object detection. We show that this probabilistic interpretation motivates a number of common empirical training practices. It also suggests changes to two-stage detection pipelines. Specifically, the first stage should infer proper object-vs-background likelihoods, which should then inform the overall score of the detector. A standard region proposal network (RPN) cannot infer this likelihood sufficiently well, but many one-stage detectors can. We show how to build a probabilistic two-stage detector from any state-of-the-art one-stage detector. The resulting detectors are faster and more accurate than both their one- and two-stage precursors. Our detector achieves 56.4 mAP on COCO test-dev with single-scale testing, outperforming all published results. Using a lightweight backbone, our detector achieves 49.2 mAP on COCO at 33 fps on a Titan Xp, outperforming the popular YOLOv4 model.
Large Batch Simulation for Deep Reinforcement Learning
Mar 12, 2021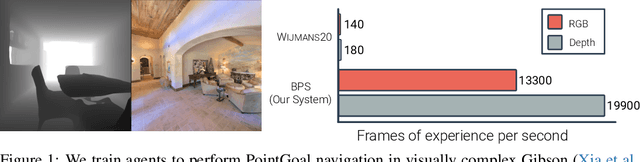
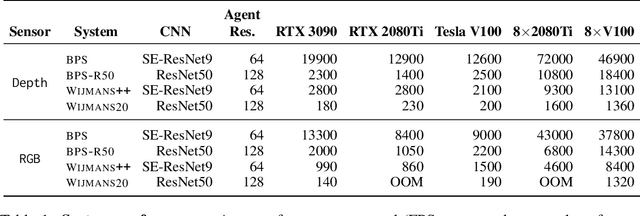
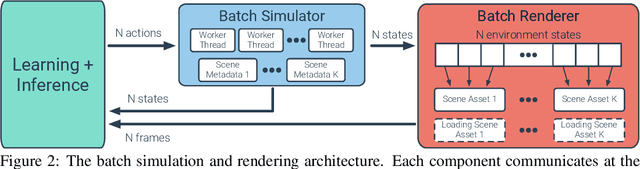
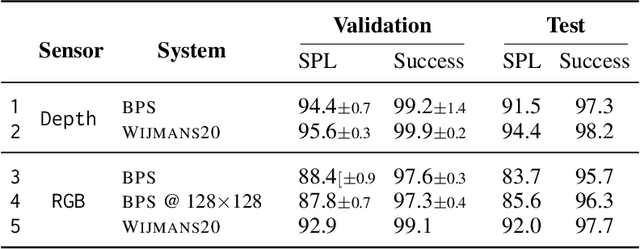
We accelerate deep reinforcement learning-based training in visually complex 3D environments by two orders of magnitude over prior work, realizing end-to-end training speeds of over 19,000 frames of experience per second on a single GPU and up to 72,000 frames per second on a single eight-GPU machine. The key idea of our approach is to design a 3D renderer and embodied navigation simulator around the principle of "batch simulation": accepting and executing large batches of requests simultaneously. Beyond exposing large amounts of work at once, batch simulation allows implementations to amortize in-memory storage of scene assets, rendering work, data loading, and synchronization costs across many simulation requests, dramatically improving the number of simulated agents per GPU and overall simulation throughput. To balance DNN inference and training costs with faster simulation, we also build a computationally efficient policy DNN that maintains high task performance, and modify training algorithms to maintain sample efficiency when training with large mini-batches. By combining batch simulation and DNN performance optimizations, we demonstrate that PointGoal navigation agents can be trained in complex 3D environments on a single GPU in 1.5 days to 97% of the accuracy of agents trained on a prior state-of-the-art system using a 64-GPU cluster over three days. We provide open-source reference implementations of our batch 3D renderer and simulator to facilitate incorporation of these ideas into RL systems.
Self-supervised Geometric Perception
Mar 04, 2021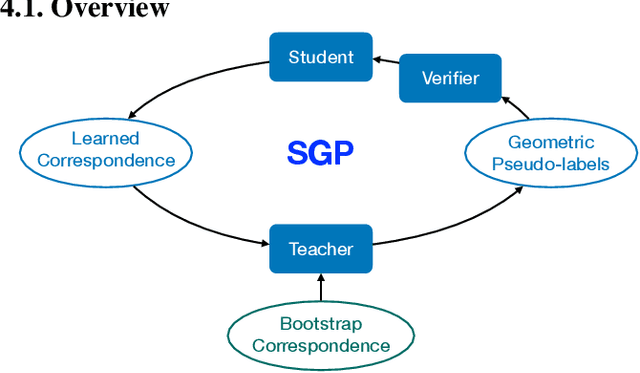
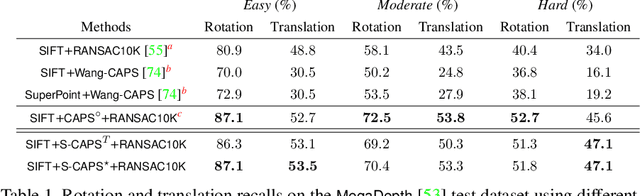

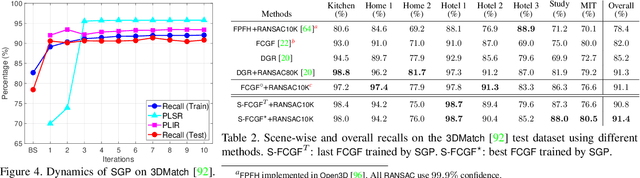
We present self-supervised geometric perception (SGP), the first general framework to learn a feature descriptor for correspondence matching without any ground-truth geometric model labels (e.g., camera poses, rigid transformations). Our first contribution is to formulate geometric perception as an optimization problem that jointly optimizes the feature descriptor and the geometric models given a large corpus of visual measurements (e.g., images, point clouds). Under this optimization formulation, we show that two important streams of research in vision, namely robust model fitting and deep feature learning, correspond to optimizing one block of the unknown variables while fixing the other block. This analysis naturally leads to our second contribution -- the SGP algorithm that performs alternating minimization to solve the joint optimization. SGP iteratively executes two meta-algorithms: a teacher that performs robust model fitting given learned features to generate geometric pseudo-labels, and a student that performs deep feature learning under noisy supervision of the pseudo-labels. As a third contribution, we apply SGP to two perception problems on large-scale real datasets, namely relative camera pose estimation on MegaDepth and point cloud registration on 3DMatch. We demonstrate that SGP achieves state-of-the-art performance that is on-par or superior to the supervised oracles trained using ground-truth labels.