 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLAIM: Robust Dense Neural SLAM for Online Tracking and Mapping
Apr 17, 2024



We present SLAIM - Simultaneous Localization and Implicit Mapping. We propose a novel coarse-to-fine tracking model tailored for Neural Radiance Field SLAM (NeRF-SLAM) to achieve state-of-the-art tracking performance. Notably, existing NeRF-SLAM systems consistently exhibit inferior tracking performance compared to traditional SLAM algorithms. NeRF-SLAM methods solve camera tracking via image alignment and photometric bundle-adjustment. Such optimization processes are difficult to optimize due to the narrow basin of attraction of the optimization loss in image space (local minima) and the lack of initial correspondences. We mitigate these limitations by implementing a Gaussian pyramid filter on top of NeRF, facilitating a coarse-to-fine tracking optimization strategy. Furthermore, NeRF systems encounter challenges in converging to the right geometry with limited input views. While prior approaches use a Signed-Distance Function (SDF)-based NeRF and directly supervise SDF values by approximating ground truth SDF through depth measurements, this often results in suboptimal geometry. In contrast, our method employs a volume density representation and introduces a novel KL regularizer on the ray termination distribution, constraining scene geometry to consist of empty space and opaque surfaces. Our solution implements both local and global bundle-adjustment to produce a robust (coarse-to-fine) and accurate (KL regularizer) SLAM solution. We conduct experiments on multiple datasets (ScanNet, TUM, Replica) showing state-of-the-art results in tracking and in reconstruction accuracy.
3D Semantic MapNet: Building Maps for Multi-Object Re-Identification in 3D
Mar 19, 2024



We study the task of 3D multi-object re-identification from embodied tours. Specifically, an agent is given two tours of an environment (e.g. an apartment) under two different layouts (e.g. arrangements of furniture). Its task is to detect and re-identify objects in 3D - e.g. a "sofa" moved from location A to B, a new "chair" in the second layout at location C, or a "lamp" from location D in the first layout missing in the second. To support this task, we create an automated infrastructure to generate paired egocentric tours of initial/modified layouts in the Habitat simulator using Matterport3D scenes, YCB and Google-scanned objects. We present 3D Semantic MapNet (3D-SMNet) - a two-stage re-identification model consisting of (1) a 3D object detector that operates on RGB-D videos with known pose, and (2) a differentiable object matching module that solves correspondence estimation between two sets of 3D bounding boxes. Overall, 3D-SMNet builds object-based maps of each layout and then uses a differentiable matcher to re-identify objects across the tours. After training 3D-SMNet on our generated episodes, we demonstrate zero-shot transfer to real-world rearrangement scenarios by instantiating our task in Replica, Active Vision, and RIO environments depicting rearrangements. On all datasets, we find 3D-SMNet outperforms competitive baselines. Further, we show jointly training on real and generated episodes can lead to significant improvements over training on real data alone.
Episodic Memory Question Answering
May 03, 2022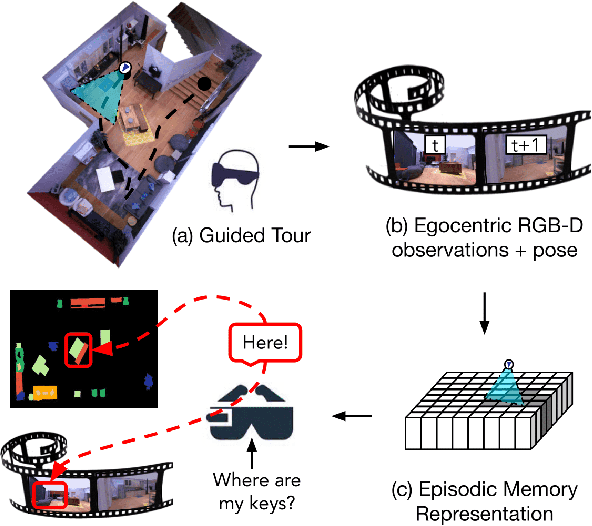
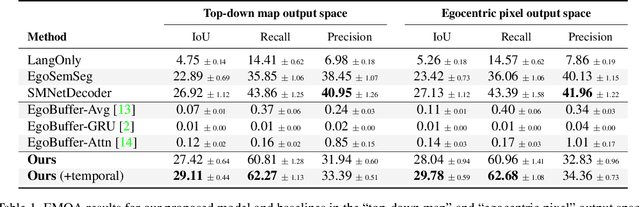
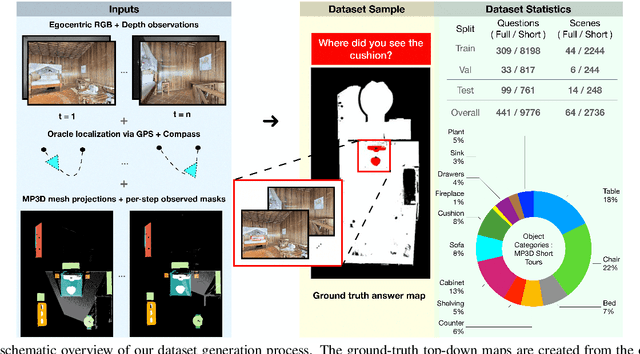
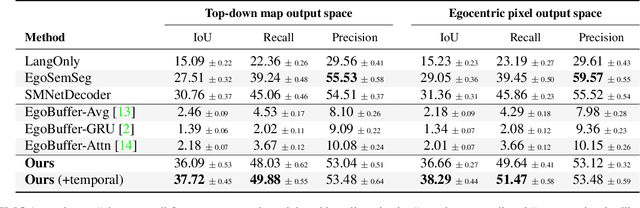
Egocentric augmented reality devices such as wearable glasses passively capture visual data as a human wearer tours a home environment. We envision a scenario wherein the human communicates with an AI agent powering such a device by asking questions (e.g., where did you last see my keys?). In order to succeed at this task, the egocentric AI assistant must (1) construct semantically rich and efficient scene memories that encode spatio-temporal information about objects seen during the tour and (2) possess the ability to understand the question and ground its answer into the semantic memory representation. Towards that end, we introduce (1) a new task - Episodic Memory Question Answering (EMQA) wherein an egocentric AI assistant is provided with a video sequence (the tour) and a question as an input and is asked to localize its answer to the question within the tour, (2) a dataset of grounded questions designed to probe the agent's spatio-temporal understanding of the tour, and (3) a model for the task that encodes the scene as an allocentric, top-down semantic feature map and grounds the question into the map to localize the answer. We show that our choice of episodic scene memory outperforms naive, off-the-shelf solutions for the task as well as a host of very competitive baselines and is robust to noise in depth, pose as well as camera jitter. The project page can be found at: https://samyak-268.github.io/emqa .
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021



We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
Semantic MapNet: Building Allocentric SemanticMaps and Representations from Egocentric Views
Oct 02, 2020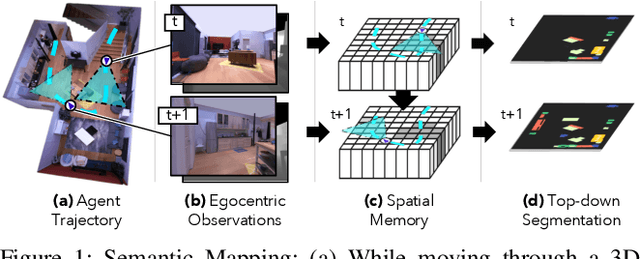

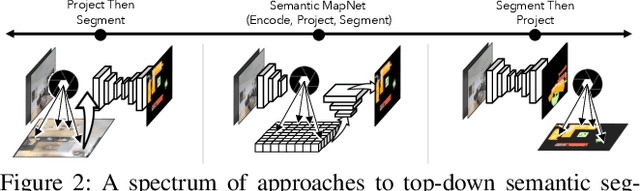

We study the task of semantic mapping - specifically, an embodied agent (a robot or an egocentric AI assistant) is given a tour of a new environment and asked to build an allocentric top-down semantic map ("what is where?") from egocentric observations of an RGB-D camera with known pose (via localization sensors). Towards this goal, we present SemanticMapNet (SMNet), which consists of: (1) an Egocentric Visual Encoder that encodes each egocentric RGB-D frame, (2) a Feature Projector that projects egocentric features to appropriate locations on a floor-plan, (3) a Spatial Memory Tensor of size floor-plan length x width x feature-dims that learns to accumulate projected egocentric features, and (4) a Map Decoder that uses the memory tensor to produce semantic top-down maps. SMNet combines the strengths of (known) projective camera geometry and neural representation learning. On the task of semantic mapping in the Matterport3D dataset, SMNet significantly outperforms competitive baselines by 4.01-16.81% (absolute) on mean-IoU and 3.81-19.69% (absolute) on Boundary-F1 metrics. Moreover, we show how to use the neural episodic memories and spatio-semantic allocentric representations build by SMNet for subsequent tasks in the same space - navigating to objects seen during the tour("Find chair") or answering questions about the space ("How many chairs did you see in the house?").
Audio-Visual Scene-Aware Dialog
Jan 25, 2019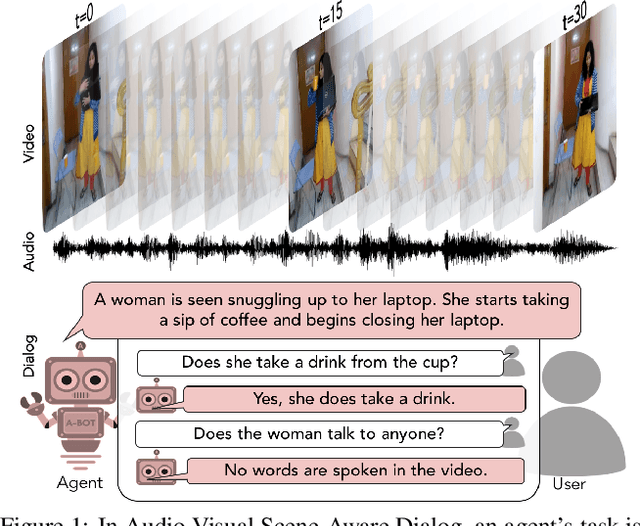


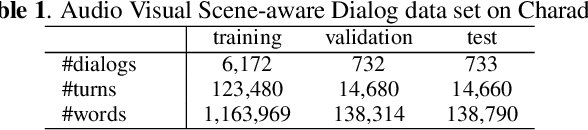
We introduce the task of scene-aware dialog. Given a follow-up question in an ongoing dialog about a video, our goal is to generate a complete and natural response to a question given (a) an input video, and (b) the history of previous turns in the dialog. To succeed, agents must ground the semantics in the video and leverage contextual cues from the history of the dialog to answer the question. To benchmark this task, we introduce the Audio Visual Scene-Aware Dialog (AVSD) dataset. For each of more than 11,000 videos of human actions for the Charades dataset. Our dataset contains a dialog about the video, plus a final summary of the video by one of the dialog participants. We train several baseline systems for this task and evaluate the performance of the trained models using several qualitative and quantitative metrics. Our results indicate that the models must comprehend all the available inputs (video, audio, question and dialog history) to perform well on this dataset.
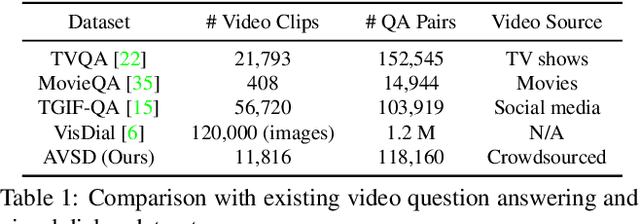
End-to-End Audio Visual Scene-Aware Dialog using Multimodal Attention-Based Video Features
Jun 30, 2018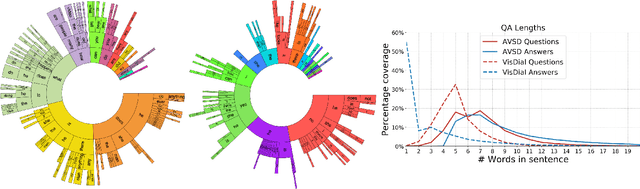
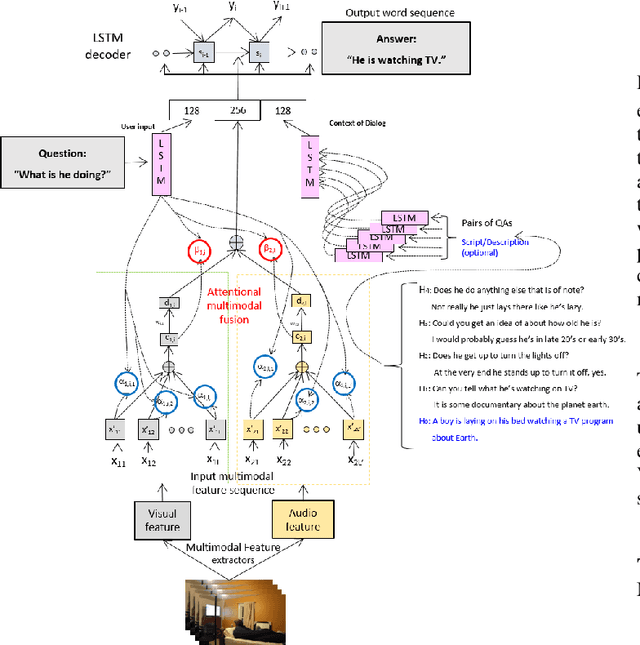
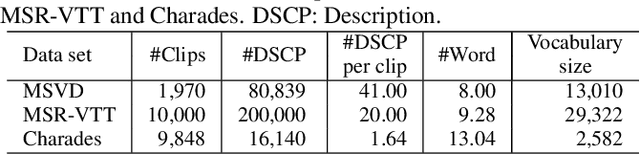
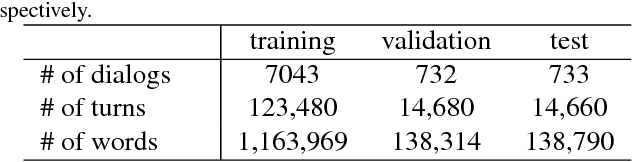
Dialog systems need to understand dynamic visual scenes in order to have conversations with users about the objects and events around them. Scene-aware dialog systems for real-world applications could be developed by integrating state-of-the-art technologies from multiple research areas, including: end-to-end dialog technologies, which generate system responses using models trained from dialog data; visual question answering (VQA) technologies, which answer questions about images using learned image features; and video description technologies, in which descriptions/captions are generated from videos using multimodal information. We introduce a new dataset of dialogs about videos of human behaviors. Each dialog is a typed conversation that consists of a sequence of 10 question-and-answer(QA) pairs between two Amazon Mechanical Turk (AMT) workers. In total, we collected dialogs on roughly 9,000 videos. Using this new dataset for Audio Visual Scene-aware dialog (AVSD), we trained an end-to-end conversation model that generates responses in a dialog about a video. Our experiments demonstrate that using multimodal features that were developed for multimodal attention-based video description enhances the quality of generated dialog about dynamic scenes (videos). Our dataset, model code and pretrained models will be publicly available for a new Video Scene-Aware Dialog challenge.
Audio Visual Scene-Aware Dialog Challenge at DSTC7
Jun 01, 2018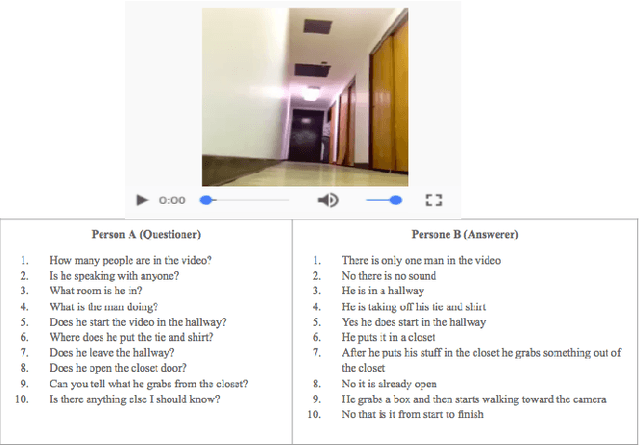
Scene-aware dialog systems will be able to have conversations with users about the objects and events around them. Progress on such systems can be made by integrating state-of-the-art technologies from multiple research areas including end-to-end dialog systems visual dialog, and video description. We introduce the Audio Visual Scene Aware Dialog (AVSD) challenge and dataset. In this challenge, which is one track of the 7th Dialog System Technology Challenges (DSTC7) workshop1, the task is to build a system that generates responses in a dialog about an input video