 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Region Ensemble Convolutional Neural Network for Facial Expression Recognition
Jul 12, 2018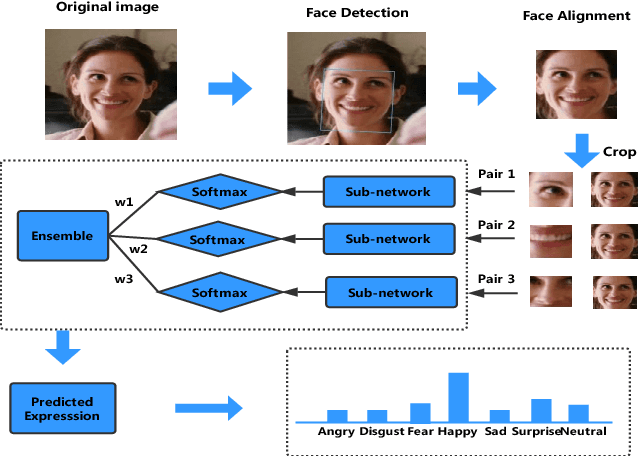
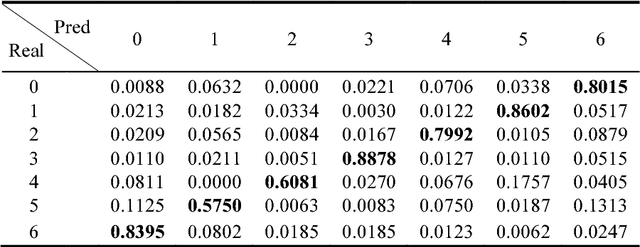

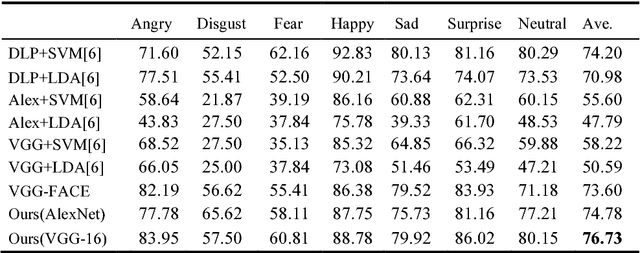
Facial expressions play an important role in conveying the emotional states of human beings. Recently, deep learning approaches have been applied to image recognition field due to the discriminative power of Convolutional Neural Network (CNN). In this paper, we first propose a novel Multi-Region Ensemble CNN (MRE-CNN) framework for facial expression recognition, which aims to enhance the learning power of CNN models by capturing both the global and the local features from multiple human face sub-regions. Second, the weighted prediction scores from each sub-network are aggregated to produce the final prediction of high accuracy. Third, we investigate the effects of different sub-regions of the whole face on facial expression recognition. Our proposed method is evaluated based on two well-known publicly available facial expression databases: AFEW 7.0 and RAF-DB, and has been shown to achieve the state-of-the-art recognition accuracy.
pg-Causality: Identifying Spatiotemporal Causal Pathways for Air Pollutants with Urban Big Data
Apr 18, 2018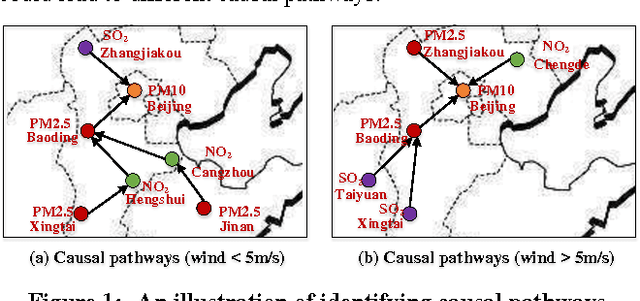

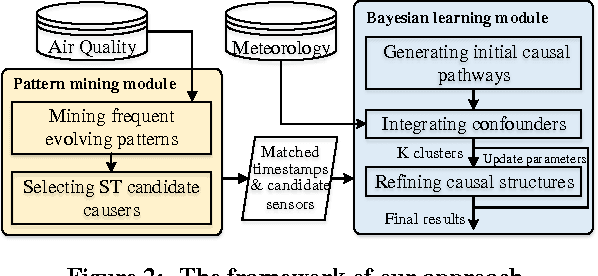
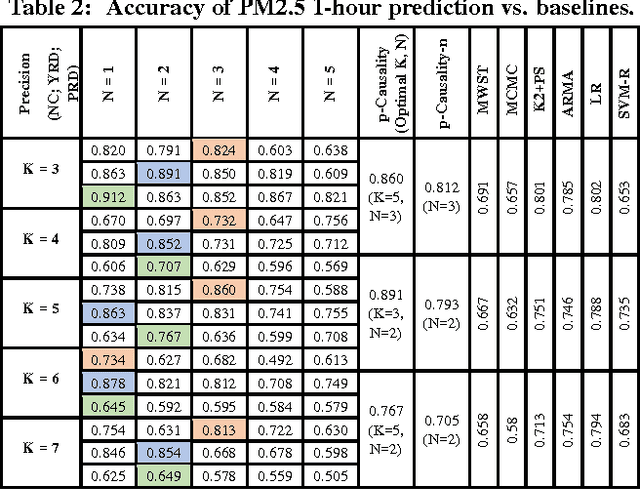
Many countries are suffering from severe air pollution. Understanding how different air pollutants accumulate and propagate is critical to making relevant public policies. In this paper, we use urban big data (air quality data and meteorological data) to identify the \emph{spatiotemporal (ST) causal pathways} for air pollutants. This problem is challenging because: (1) there are numerous noisy and low-pollution periods in the raw air quality data, which may lead to unreliable causality analysis, (2) for large-scale data in the ST space, the computational complexity of constructing a causal structure is very high, and (3) the \emph{ST causal pathways} are complex due to the interactions of multiple pollutants and the influence of environmental factors. Therefore, we present \emph{p-Causality}, a novel pattern-aided causality analysis approach that combines the strengths of \emph{pattern mining} and \emph{Bayesian learning} to efficiently and faithfully identify the \emph{ST causal pathways}. First, \emph{Pattern mining} helps suppress the noise by capturing frequent evolving patterns (FEPs) of each monitoring sensor, and greatly reduce the complexity by selecting the pattern-matched sensors as "causers". Then, \emph{Bayesian learning} carefully encodes the local and ST causal relations with a Gaussian Bayesian network (GBN)-based graphical model, which also integrates environmental influences to minimize biases in the final results. We evaluate our approach with three real-world data sets containing 982 air quality sensors, in three regions of China from 01-Jun-2013 to 19-Dec-2015. Results show that our approach outperforms the traditional causal structure learning methods in time efficiency, inference accuracy and interpretability.
Universal Neural Machine Translation for Extremely Low Resource Languages
Apr 17, 2018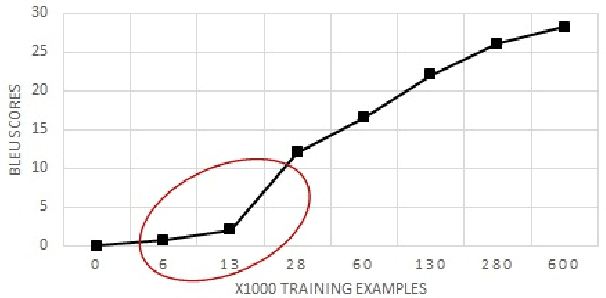

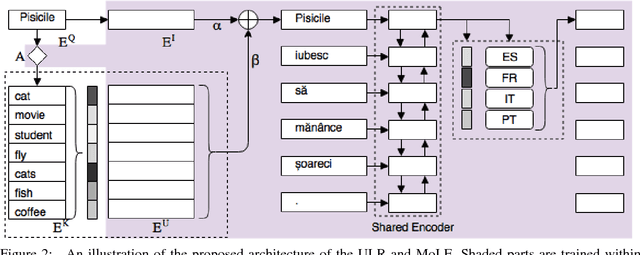

In this paper, we propose a new universal machine translation approach focusing on languages with a limited amount of parallel data. Our proposed approach utilizes a transfer-learning approach to share lexical and sentence level representations across multiple source languages into one target language. The lexical part is shared through a Universal Lexical Representation to support multilingual word-level sharing. The sentence-level sharing is represented by a model of experts from all source languages that share the source encoders with all other languages. This enables the low-resource language to utilize the lexical and sentence representations of the higher resource languages. Our approach is able to achieve 23 BLEU on Romanian-English WMT2016 using a tiny parallel corpus of 6k sentences, compared to the 18 BLEU of strong baseline system which uses multilingual training and back-translation. Furthermore, we show that the proposed approach can achieve almost 20 BLEU on the same dataset through fine-tuning a pre-trained multi-lingual system in a zero-shot setting.
Non-Autoregressive Neural Machine Translation
Mar 09, 2018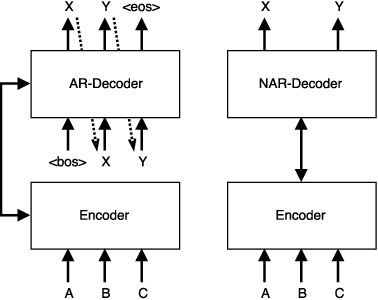
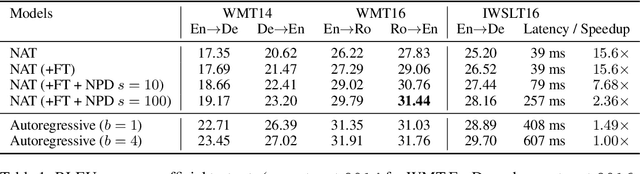
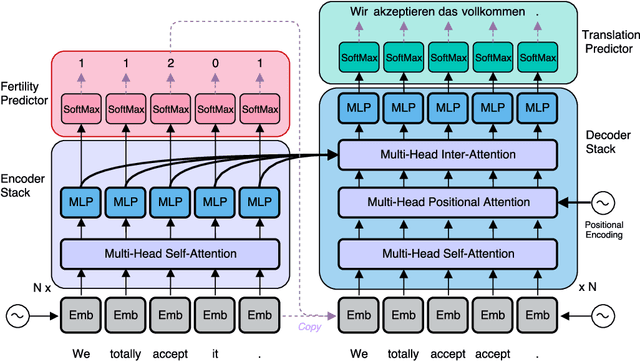
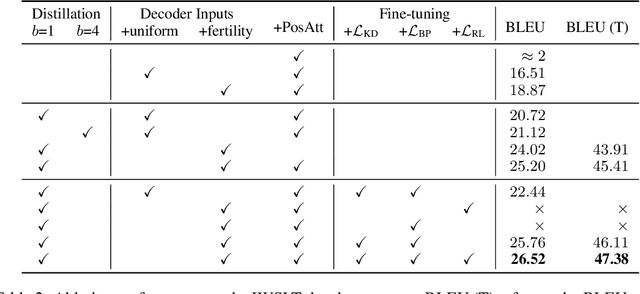
Existing approaches to neural machine translation condition each output word on previously generated outputs. We introduce a model that avoids this autoregressive property and produces its outputs in parallel, allowing an order of magnitude lower latency during inference. Through knowledge distillation, the use of input token fertilities as a latent variable, and policy gradient fine-tuning, we achieve this at a cost of as little as 2.0 BLEU points relative to the autoregressive Transformer network used as a teacher. We demonstrate substantial cumulative improvements associated with each of the three aspects of our training strategy, and validate our approach on IWSLT 2016 English-German and two WMT language pairs. By sampling fertilities in parallel at inference time, our non-autoregressive model achieves near-state-of-the-art performance of 29.8 BLEU on WMT 2016 English-Romanian.
Search Engine Guided Non-Parametric Neural Machine Translation
Mar 08, 2018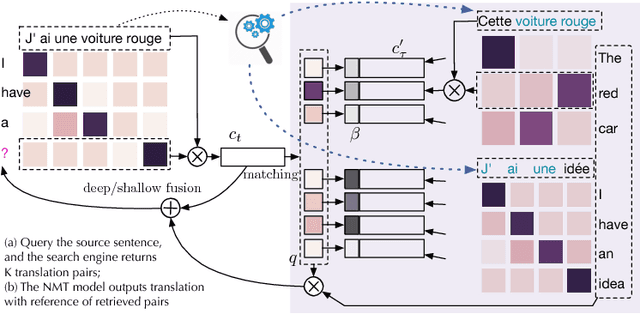
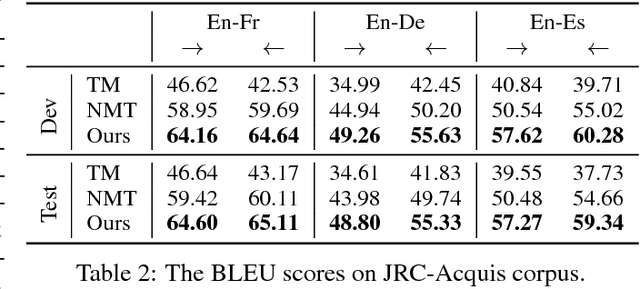
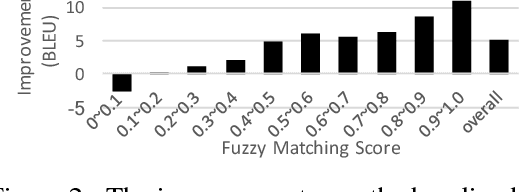
In this paper, we extend an attention-based neural machine translation (NMT) model by allowing it to access an entire training set of parallel sentence pairs even after training. The proposed approach consists of two stages. In the first stage--retrieval stage--, an off-the-shelf, black-box search engine is used to retrieve a small subset of sentence pairs from a training set given a source sentence. These pairs are further filtered based on a fuzzy matching score based on edit distance. In the second stage--translation stage--, a novel translation model, called translation memory enhanced NMT (TM-NMT), seamlessly uses both the source sentence and a set of retrieved sentence pairs to perform the translation. Empirical evaluation on three language pairs (En-Fr, En-De, and En-Es) shows that the proposed approach significantly outperforms the baseline approach and the improvement is more significant when more relevant sentence pairs were retrieved.
Zero-Resource Neural Machine Translation with Multi-Agent Communication Game
Feb 09, 2018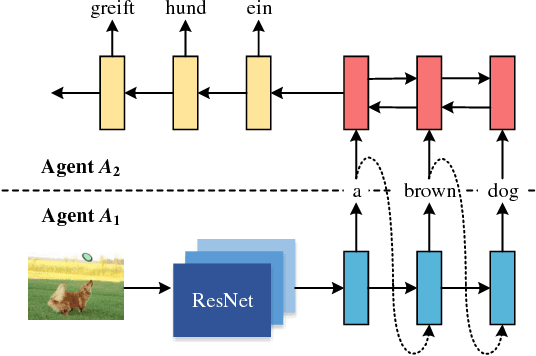
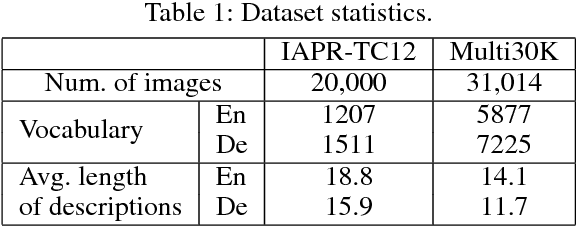
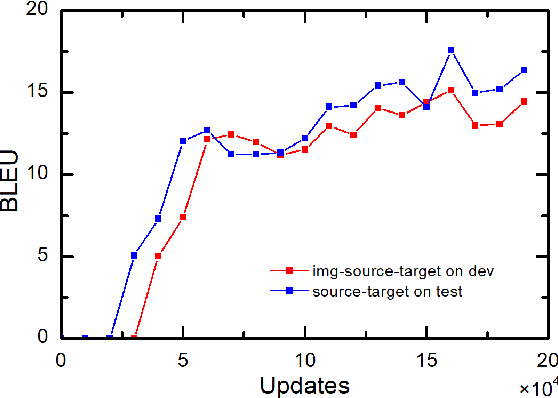
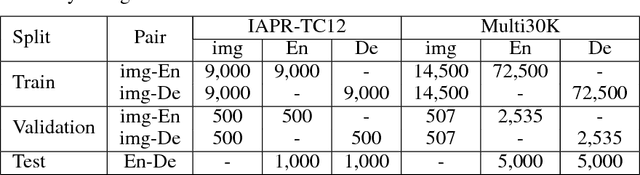
While end-to-end neural machine translation (NMT) has achieved notable success in the past years in translating a handful of resource-rich language pairs, it still suffers from the data scarcity problem for low-resource language pairs and domains. To tackle this problem, we propose an interactive multimodal framework for zero-resource neural machine translation. Instead of being passively exposed to large amounts of parallel corpora, our learners (implemented as encoder-decoder architecture) engage in cooperative image description games, and thus develop their own image captioning or neural machine translation model from the need to communicate in order to succeed at the game. Experimental results on the IAPR-TC12 and Multi30K datasets show that the proposed learning mechanism significantly improves over the state-of-the-art methods.
Neural Machine Translation with Gumbel-Greedy Decoding
Jun 22, 2017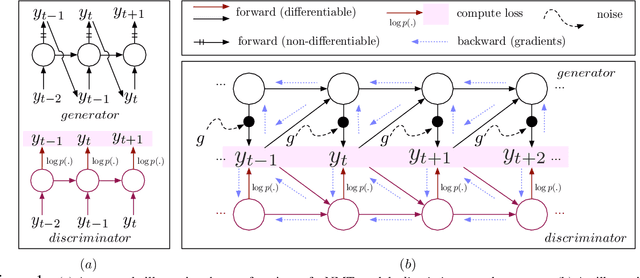
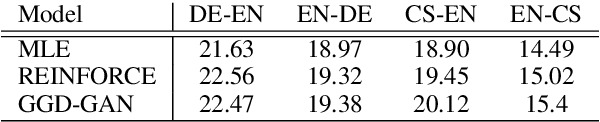
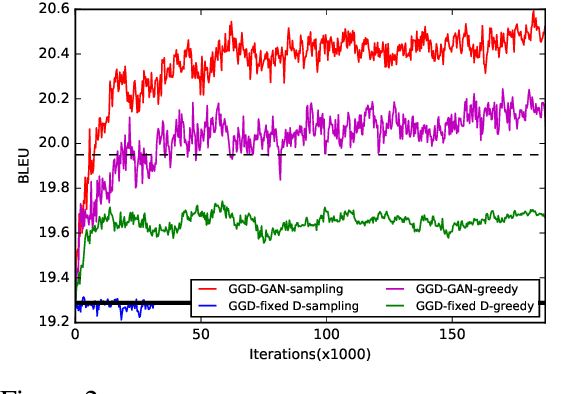

Previous neural machine translation models used some heuristic search algorithms (e.g., beam search) in order to avoid solving the maximum a posteriori problem over translation sentences at test time. In this paper, we propose the Gumbel-Greedy Decoding which trains a generative network to predict translation under a trained model. We solve such a problem using the Gumbel-Softmax reparameterization, which makes our generative network differentiable and trainable through standard stochastic gradient methods. We empirically demonstrate that our proposed model is effective for generating sequences of discrete words.
A Teacher-Student Framework for Zero-Resource Neural Machine Translation
May 02, 2017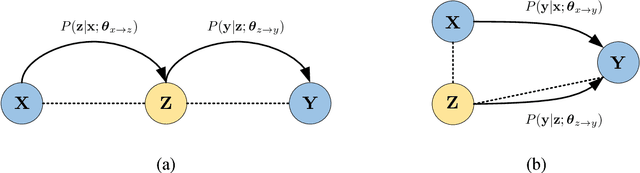
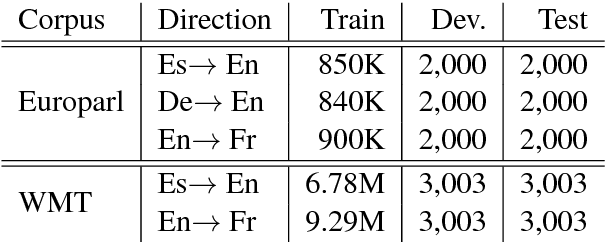
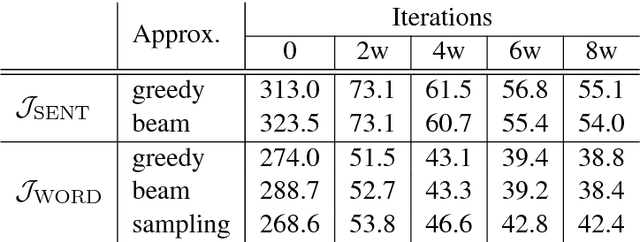
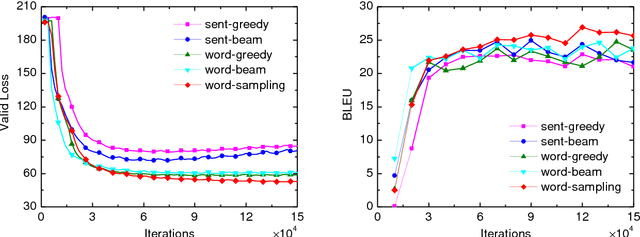
While end-to-end neural machine translation (NMT) has made remarkable progress recently, it still suffers from the data scarcity problem for low-resource language pairs and domains. In this paper, we propose a method for zero-resource NMT by assuming that parallel sentences have close probabilities of generating a sentence in a third language. Based on this assumption, our method is able to train a source-to-target NMT model ("student") without parallel corpora available, guided by an existing pivot-to-target NMT model ("teacher") on a source-pivot parallel corpus. Experimental results show that the proposed method significantly improves over a baseline pivot-based model by +3.0 BLEU points across various language pairs.
Trainable Greedy Decoding for Neural Machine Translation
Feb 08, 2017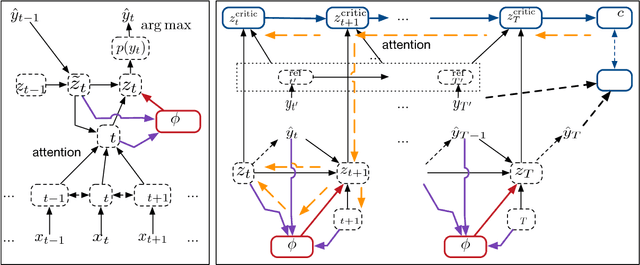
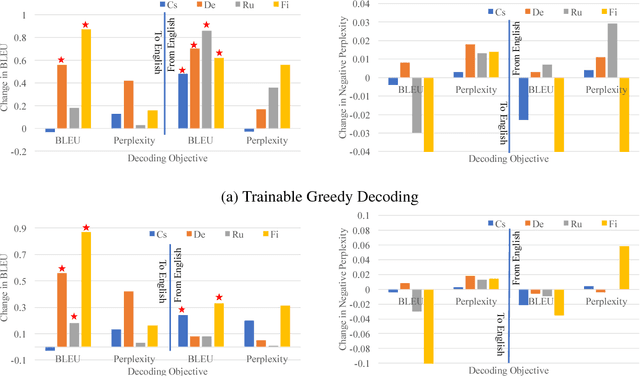
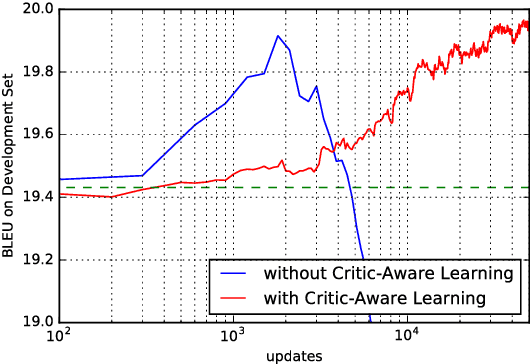

Recent research in neural machine translation has largely focused on two aspects; neural network architectures and end-to-end learning algorithms. The problem of decoding, however, has received relatively little attention from the research community. In this paper, we solely focus on the problem of decoding given a trained neural machine translation model. Instead of trying to build a new decoding algorithm for any specific decoding objective, we propose the idea of trainable decoding algorithm in which we train a decoding algorithm to find a translation that maximizes an arbitrary decoding objective. More specifically, we design an actor that observes and manipulates the hidden state of the neural machine translation decoder and propose to train it using a variant of deterministic policy gradient. We extensively evaluate the proposed algorithm using four language pairs and two decoding objectives and show that we can indeed train a trainable greedy decoder that generates a better translation (in terms of a target decoding objective) with minimal computational overhead.
Learning to Translate in Real-time with Neural Machine Translation
Jan 10, 2017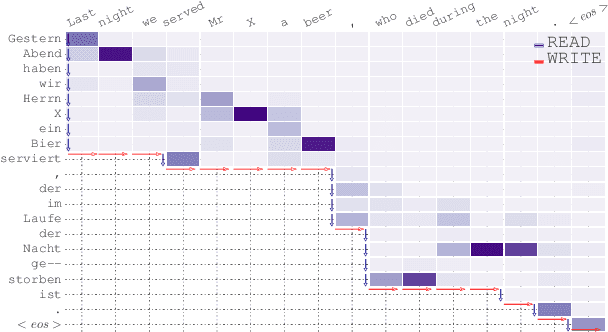

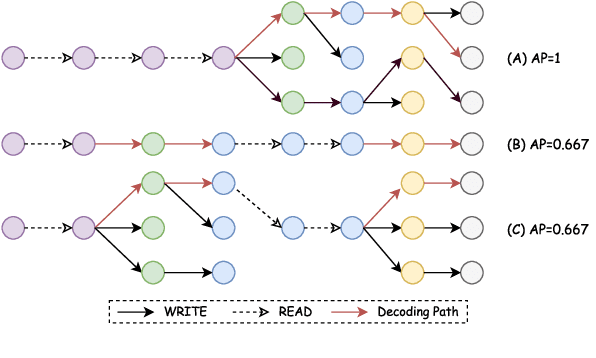
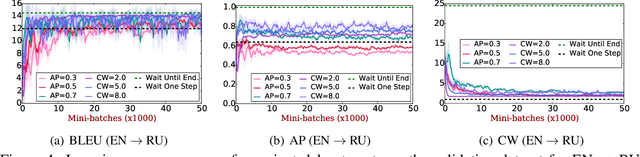
Translating in real-time, a.k.a. simultaneous translation, outputs translation words before the input sentence ends, which is a challenging problem for conventional machine translation methods. We propose a neural machine translation (NMT) framework for simultaneous translation in which an agent learns to make decisions on when to translate from the interaction with a pre-trained NMT environment. To trade off quality and delay, we extensively explore various targets for delay and design a method for beam-search applicable in the simultaneous MT setting. Experiments against state-of-the-art baselines on two language pairs demonstrate the efficacy of the proposed framework both quantitatively and qualitatively.