 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Shared Embodied Intelligence in Humanoid Robots through Optimization Development and Testing of the Human Aware ergoCub Robot
May 26, 2026Collaboration is central to human behavior, enabling tasks beyond individual capability. This ability arises from coordinating actions through internal representations of others, a concept known as shared intelligence. Additionally, humans are characterized by physical bodies and cognitive abilities that are optimized in response to their environment, a phenomenon referred to as embodied cognition. Designing humanoid robots that collaborate safely and effectively with people requires unifying these principles. Here we propose an architecture that integrates shared intelligence and embodied cognition to enable robots to physically collaborate with humans, where robot hardware and control are optimized for human metrics, using representations of the human body and motion intelligence. The ultimate goal is to achieve a form of shared embodied intelligence. Specifically, our architecture optimizes robot hardware and physical intelligence parameters with respect to human ergonomic metrics. This is accomplished by modeling human-robot interaction as a function of hardware configurations and embedding human models into the robot's physical intelligence. As a concrete implementation, we present the humanoid robot ergoCub, whose morphology and control have been optimized for collaborative tasks with humans. Our approach provides a framework for designing humanoid robots that prioritize human ergonomics at both the hardware and physical intelligence levels, with applications in industrial and assistive robotics.
Pickalo: Leveraging 6D Pose Estimation for Low-Cost Industrial Bin Picking
Apr 06, 2026Bin picking in real industrial environments remains challenging due to severe clutter, occlusions, and the high cost of traditional 3D sensing setups. We present Pickalo, a modular 6D pose-based bin-picking pipeline built entirely on low-cost hardware. A wrist-mounted RGB-D camera actively explores the scene from multiple viewpoints, while raw stereo streams are processed with BridgeDepth to obtain refined depth maps suitable for accurate collision reasoning. Object instances are segmented with a Mask-RCNN model trained purely on photorealistic synthetic data and localized using the zero-shot SAM-6D pose estimator. A pose buffer module fuses multi-view observations over time, handling object symmetries and significantly reducing pose noise. Offline, we generate and curate large sets of antipodal grasp candidates per object; online, a utility-based ranking and fast collision checking are queried for the grasp planning. Deployed on a UR5e with a parallel-jaw gripper and an Intel RealSense D435i, Pickalo achieves up to 600 mean picks per hour with 96-99% grasp success and robust performance over 30-minute runs on densely filled euroboxes. Ablation studies demonstrate the benefits of enhanced depth estimation and of the pose buffer for long-term stability and throughput in realistic industrial conditions. Videos are available at https://mesh-iit.github.io/project-jl2-camozzi/
Multifingered force-aware control for humanoid robots
Mar 09, 2026In this paper, we address force-aware control and force distribution in robotic platforms with multi-fingered hands. Given a target goal and force estimates from tactile sensors, we design a controller that adapts the motion of the torso, arm, wrist, and fingers, redistributing forces to maintain stable contact with objects of varying mass distribution or unstable contacts. To estimate forces, we collect a dataset of tactile signals and ground-truth force measurements using five Xela magnetic sensors interacting with indenters, and train force estimators. We then introduce a model-based control scheme that minimizes the distance between the Center of Pressure (CoP) and the centroid of the fingertips contact polygon. Since our method relies on estimated forces rather than raw tactile signals, it has the potential to be applied to any sensor capable of force estimation. We validate our framework on a balancing task with five objects, achieving a $82.7\%$ success rate, and further evaluate it in multi-object scenarios, achieving $80\%$ accuracy. Code and data can be found here https://github.com/hsp-iit/multifingered-force-aware-control.
HARMONIOUS -- Human-like reactive motion control and multimodal perception for humanoid robots
Dec 05, 2023



For safe and effective operation of humanoid robots in human-populated environments, the problem of commanding a large number of Degrees of Freedom (DoF) while simultaneously considering dynamic obstacles and human proximity has still not been solved. We present a new reactive motion controller that commands two arms of a humanoid robot and three torso joints (17 DoF in total). We formulate a quadratic program that seeks joint velocity commands respecting multiple constraints while minimizing the magnitude of the velocities. We introduce a new unified treatment of obstacles that dynamically maps visual and proximity (pre-collision) and tactile (post-collision) obstacles as additional constraints to the motion controller, in a distributed fashion over surface of the upper-body of the iCub robot (with 2000 pressure-sensitive receptors). The bio-inspired controller: (i) produces human-like minimum jerk movement profiles; (ii) gives rise to a robot with whole-body visuo-tactile awareness, resembling peripersonal space representations. The controller was extensively experimentally validated, including a physical human-robot interaction scenario.
iCub3 Avatar System
Mar 14, 2022
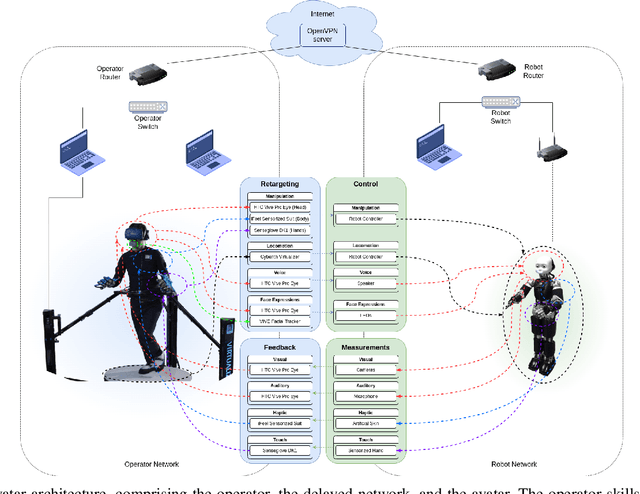
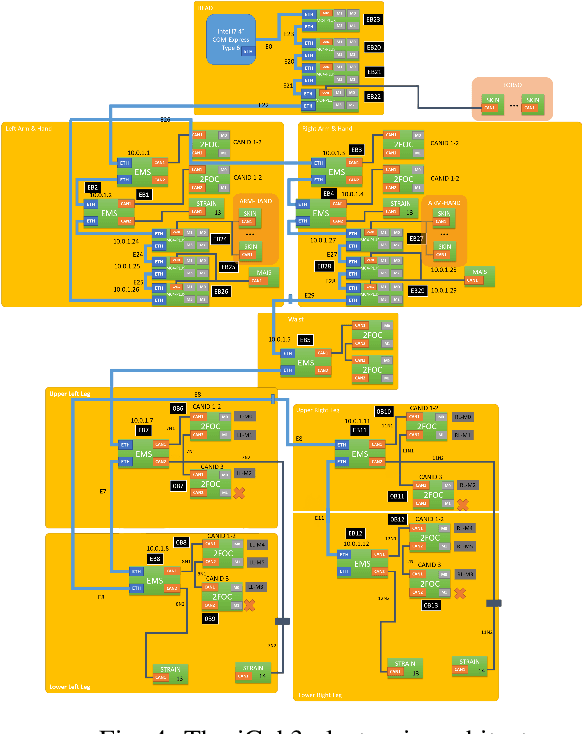
We present an avatar system that enables a human operator to visit a remote location via iCub3, a new humanoid robot developed at the Italian Institute of Technology (IIT) paving the way for the next generation of the iCub platforms. On the one hand, we present the humanoid iCub3 that plays the role of the robotic avatar. Particular attention is paid to the differences between iCub3 and the classical iCub humanoid robot. On the other hand, we present the set of technologies of the avatar system at the operator side. They are mainly composed of iFeel, namely, IIT lightweight non-invasive wearable devices for motion tracking and haptic feedback, and of non-IIT technologies designed for virtual reality ecosystems. Finally, we show the effectiveness of the avatar system by describing a demonstration involving a realtime teleoperation of the iCub3. The robot is located in Venice, Biennale di Venezia, while the human operator is at more than 290km distance and located in Genoa, IIT. Using a standard fiber optic internet connection, the avatar system transports the operator locomotion, manipulation, voice, and face expressions to the iCub3 with visual, auditory, haptic and touch feedback.
ROFT: Real-Time Optical Flow-Aided 6D Object Pose and Velocity Tracking
Nov 06, 2021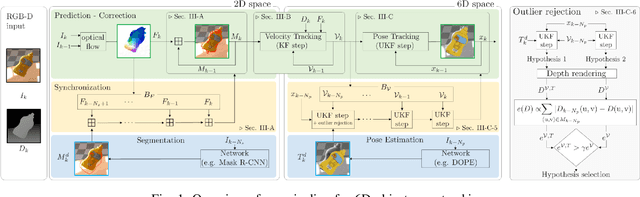

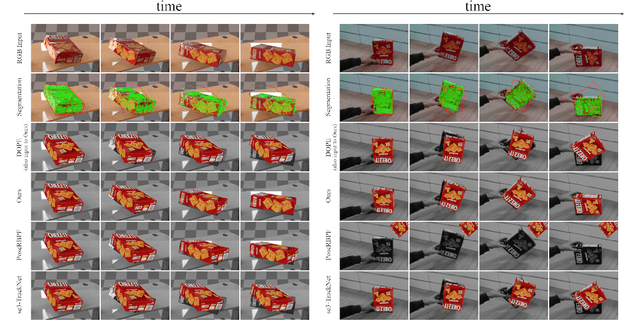

6D object pose tracking has been extensively studied in the robotics and computer vision communities. The most promising solutions, leveraging on deep neural networks and/or filtering and optimization, exhibit notable performance on standard benchmarks. However, to our best knowledge, these have not been tested thoroughly against fast object motions. Tracking performance in this scenario degrades significantly, especially for methods that do not achieve real-time performance and introduce non negligible delays. In this work, we introduce ROFT, a Kalman filtering approach for 6D object pose and velocity tracking from a stream of RGB-D images. By leveraging real-time optical flow, ROFT synchronizes delayed outputs of low frame rate Convolutional Neural Networks for instance segmentation and 6D object pose estimation with the RGB-D input stream to achieve fast and precise 6D object pose and velocity tracking. We test our method on a newly introduced photorealistic dataset, Fast-YCB, which comprises fast moving objects from the YCB model set, and on the dataset for object and hand pose estimation HO-3D. Results demonstrate that our approach outperforms state-of-the-art methods for 6D object pose tracking, while also providing 6D object velocity tracking. A video showing the experiments is provided as supplementary material.
* To cite this work, please refer to the journal reference entry. For more information, code, pictures and video please visit https://github.com/hsp-iit/roft
GRASPA 1.0: GRASPA is a Robot Arm graSping Performance benchmArk
Feb 12, 2020
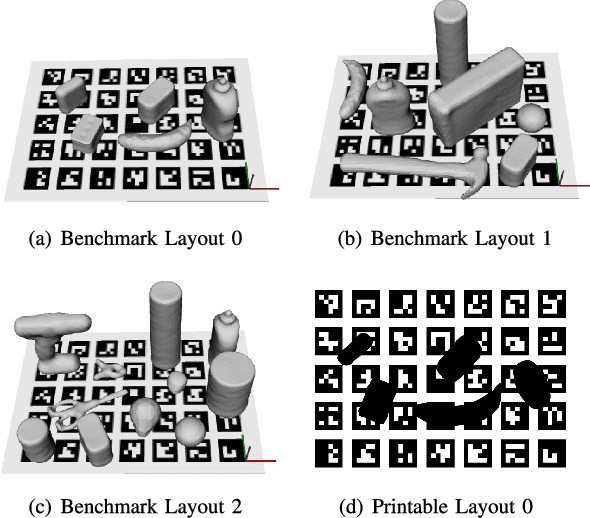

The use of benchmarks is a widespread and scientifically meaningful practice to validate performance of different approaches to the same task. In the context of robot grasping the use of common object sets has emerged in recent years, however no dominant protocols and metrics to test grasping pipelines have taken root yet. In this paper, we present version 1.0 of GRASPA, a benchmark to test effectiveness of grasping pipelines on physical robot setups. This approach tackles the complexity of such pipelines by proposing different metrics that account for the features and limits of the test platform. As an example application, we deploy GRASPA on the iCub humanoid robot and use it to benchmark our grasping pipeline. As closing remarks, we discuss how the GRASPA indicators we obtained as outcome can provide insight into how different steps of the pipeline affect the overall grasping performance.
* To cite this work, please refer to the journal reference entry. For more information, code, pictures and video please visit https://github.com/robotology/GRASPA-benchmark
Sequence-to-Sequence Natural Language to Humanoid Robot Sign Language
Jul 09, 2019
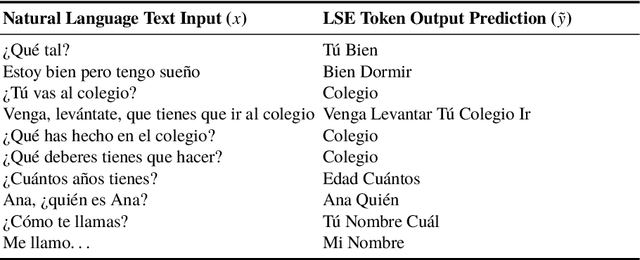
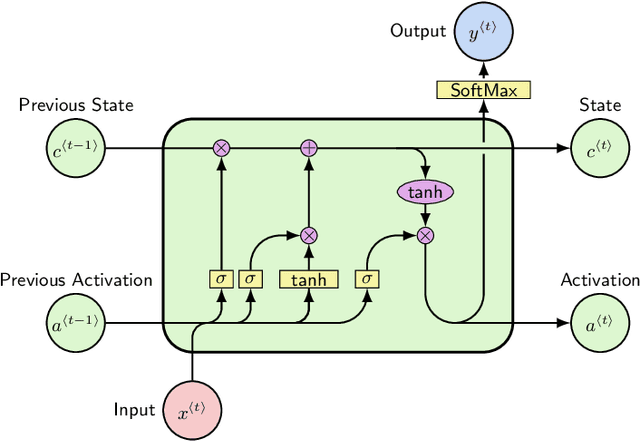
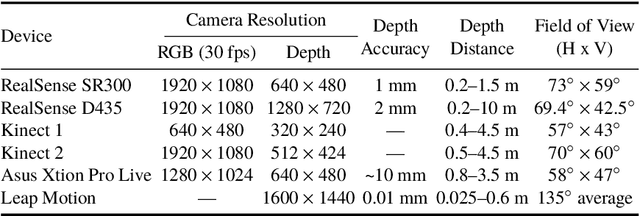
This paper presents a study on natural language to sign language translation with human-robot interaction application purposes. By means of the presented methodology, the humanoid robot TEO is expected to represent Spanish sign language automatically by converting text into movements, thanks to the performance of neural networks. Natural language to sign language translation presents several challenges to developers, such as the discordance between the length of input and output data and the use of non-manual markers. Therefore, neural networks and, consequently, sequence-to-sequence models, are selected as a data-driven system to avoid traditional expert system approaches or temporal dependencies limitations that lead to limited or too complex translation systems. To achieve these objectives, it is necessary to find a way to perform human skeleton acquisition in order to collect the signing input data. OpenPose and skeletonRetriever are proposed for this purpose and a 3D sensor specification study is developed to select the best acquisition hardware.
Compact Real-time avoidance on a Humanoid Robot for Human-robot Interaction
Jan 17, 2018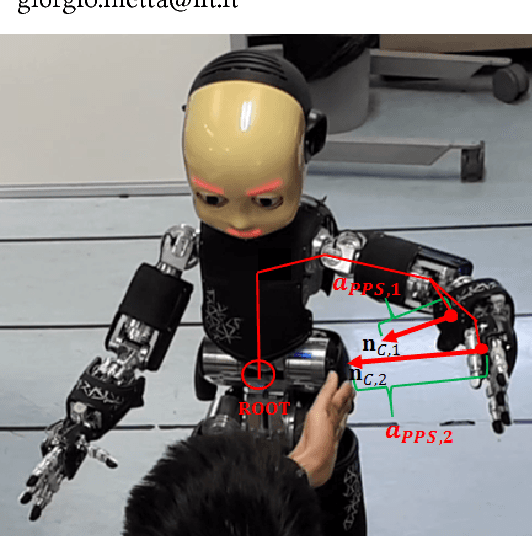
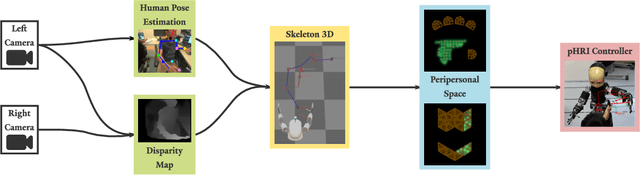

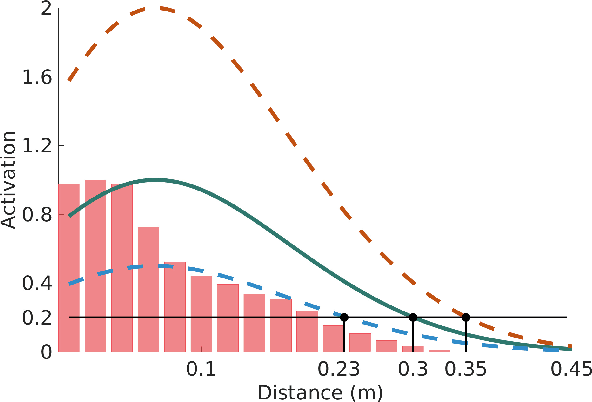
With robots leaving factories and entering less controlled domains, possibly sharing the space with humans, safety is paramount and multimodal awareness of the body surface and the surrounding environment is fundamental. Taking inspiration from peripersonal space representations in humans, we present a framework on a humanoid robot that dynamically maintains such a protective safety zone, composed of the following main components: (i) a human 2D keypoints estimation pipeline employing a deep learning based algorithm, extended here into 3D using disparity; (ii) a distributed peripersonal space representation around the robot's body parts; (iii) a reaching controller that incorporates all obstacles entering the robot's safety zone on the fly into the task. Pilot experiments demonstrate that an effective safety margin between the robot's and the human's body parts is kept. The proposed solution is flexible and versatile since the safety zone around individual robot and human body parts can be selectively modulated---here we demonstrate stronger avoidance of the human head compared to rest of the body. Our system works in real time and is self-contained, with no external sensory equipment and use of onboard cameras only.
Markerless visual servoing on unknown objects for humanoid robot platforms
Oct 12, 2017
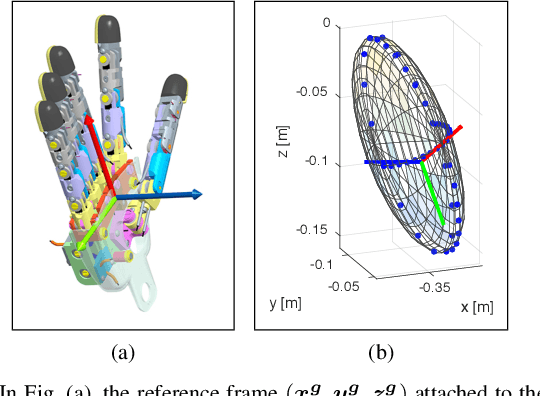
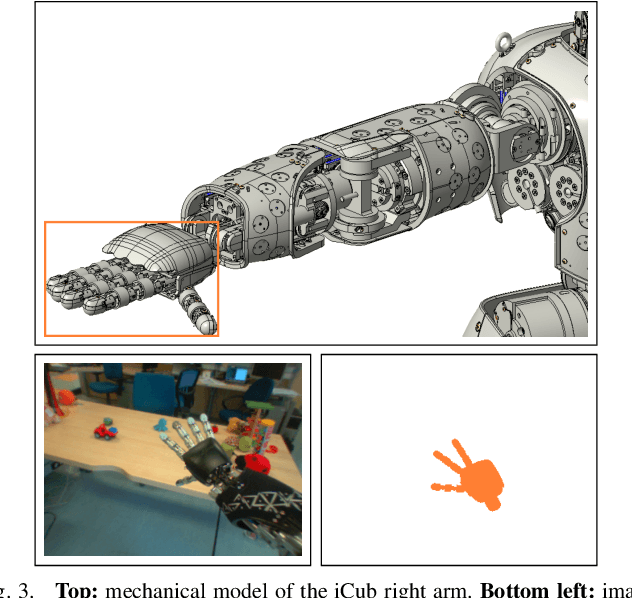
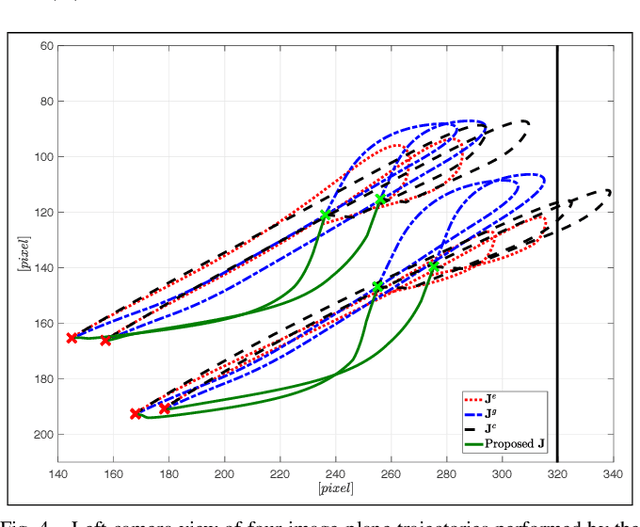
To precisely reach for an object with a humanoid robot, it is of central importance to have good knowledge of both end-effector, object pose and shape. In this work we propose a framework for markerless visual servoing on unknown objects, which is divided in four main parts: I) a least-squares minimization problem is formulated to find the volume of the object graspable by the robot's hand using its stereo vision; II) a recursive Bayesian filtering technique, based on Sequential Monte Carlo (SMC) filtering, estimates the 6D pose (position and orientation) of the robot's end-effector without the use of markers; III) a nonlinear constrained optimization problem is formulated to compute the desired graspable pose about the object; IV) an image-based visual servo control commands the robot's end-effector toward the desired pose. We demonstrate effectiveness and robustness of our approach with extensive experiments on the iCub humanoid robot platform, achieving real-time computation, smooth trajectories and sub-pixel precisions.