 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiCub Being Social: Exploiting Social Cues for Interactive Object Detection Learning
Jul 27, 2022
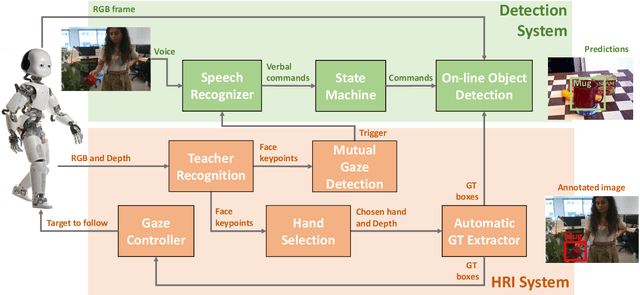
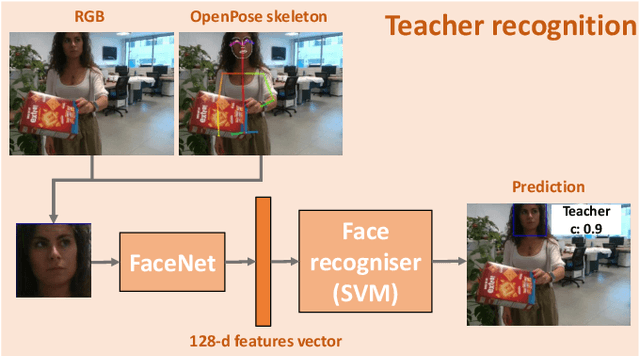

Performing joint interaction requires constant mutual monitoring of own actions and their effects on the other's behaviour. Such an action-effect monitoring is boosted by social cues and might result in an increasing sense of agency. Joint actions and joint attention are strictly correlated and both of them contribute to the formation of a precise temporal coordination. In human-robot interaction, the robot's ability to establish joint attention with a human partner and exploit various social cues to react accordingly is a crucial step in creating communicative robots. Along the social component, an effective human-robot interaction can be seen as a new method to improve and make the robot's learning process more natural and robust for a given task. In this work we use different social skills, such as mutual gaze, gaze following, speech and human face recognition, to develop an effective teacher-learner scenario tailored to visual object learning in dynamic environments. Experiments on the iCub robot demonstrate that the system allows the robot to learn new objects through a natural interaction with a human teacher in presence of distractors.
Weakly-Supervised Object Detection Learning through Human-Robot Interaction
Jul 16, 2021
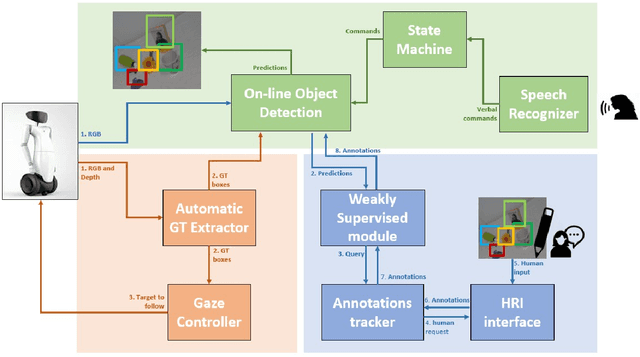

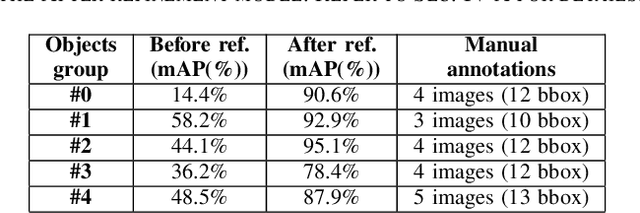
Reliable perception and efficient adaptation to novel conditions are priority skills for humanoids that function in dynamic environments. The vast advancements in latest computer vision research, brought by deep learning methods, are appealing for the robotics community. However, their adoption in applied domains is not straightforward since adapting them to new tasks is strongly demanding in terms of annotated data and optimization time. Nevertheless, robotic platforms, and especially humanoids, present opportunities (such as additional sensors and the chance to explore the environment) that can be exploited to overcome these issues. In this paper, we present a pipeline for efficiently training an object detection system on a humanoid robot. The proposed system allows to iteratively adapt an object detection model to novel scenarios, by exploiting: (i) a teacher-learner pipeline, (ii) weakly supervised learning techniques to reduce the human labeling effort and (iii) an on-line learning approach for fast model re-training. We use the R1 humanoid robot for both testing the proposed pipeline in a real-time application and acquire sequences of images to benchmark the method. We made the code of the application publicly available.
Data-efficient Weakly-supervised Learning for On-line Object Detection under Domain Shift in Robotics
Dec 28, 2020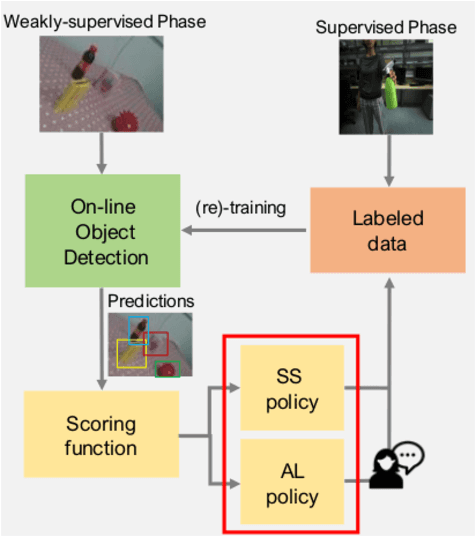
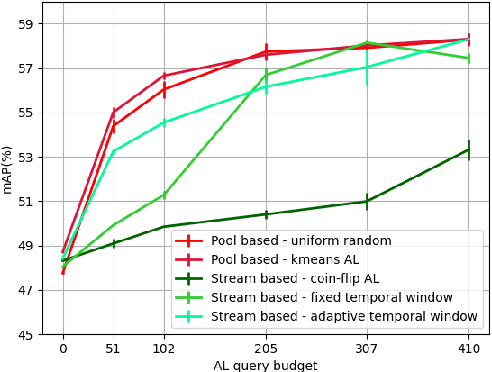

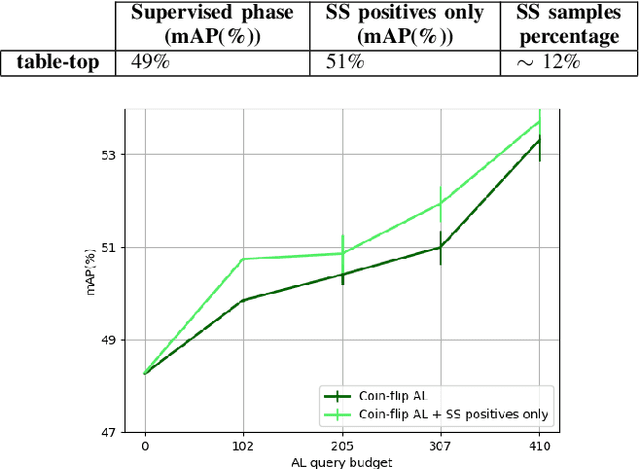
Several object detection methods have recently been proposed in the literature, the vast majority based on Deep Convolutional Neural Networks (DCNNs). Such architectures have been shown to achieve remarkable performance, at the cost of computationally expensive batch training and extensive labeling. These methods have important limitations for robotics: Learning solely on off-line data may introduce biases (the so-called domain shift), and prevents adaptation to novel tasks. In this work, we investigate how weakly-supervised learning can cope with these problems. We compare several techniques for weakly-supervised learning in detection pipelines to reduce model (re)training costs without compromising accuracy. In particular, we show that diversity sampling for constructing active learning queries and strong positives selection for self-supervised learning enable significant annotation savings and improve domain shift adaptation. By integrating our strategies into a hybrid DCNN/FALKON on-line detection pipeline [1], our method is able to be trained and updated efficiently with few labels, overcoming limitations of previous work. We experimentally validate and benchmark our method on challenging robotic object detection tasks under domain shift.
Sequence-to-Sequence Natural Language to Humanoid Robot Sign Language
Jul 09, 2019
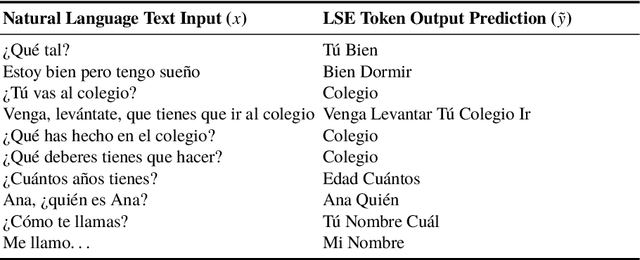
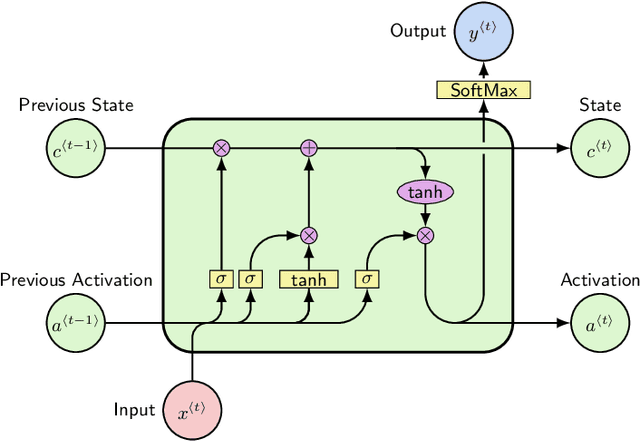
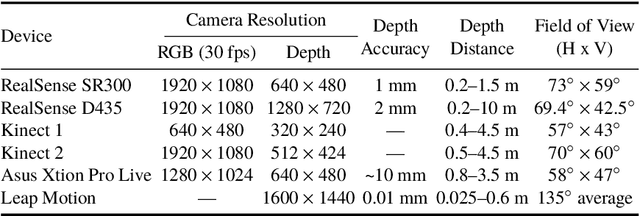
This paper presents a study on natural language to sign language translation with human-robot interaction application purposes. By means of the presented methodology, the humanoid robot TEO is expected to represent Spanish sign language automatically by converting text into movements, thanks to the performance of neural networks. Natural language to sign language translation presents several challenges to developers, such as the discordance between the length of input and output data and the use of non-manual markers. Therefore, neural networks and, consequently, sequence-to-sequence models, are selected as a data-driven system to avoid traditional expert system approaches or temporal dependencies limitations that lead to limited or too complex translation systems. To achieve these objectives, it is necessary to find a way to perform human skeleton acquisition in order to collect the signing input data. OpenPose and skeletonRetriever are proposed for this purpose and a 3D sensor specification study is developed to select the best acquisition hardware.
Face Landmark-based Speaker-Independent Audio-Visual Speech Enhancement in Multi-Talker Environments
Nov 06, 2018
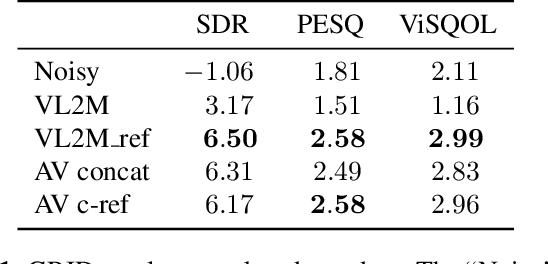
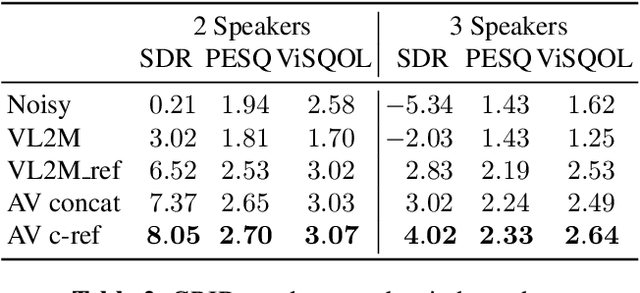
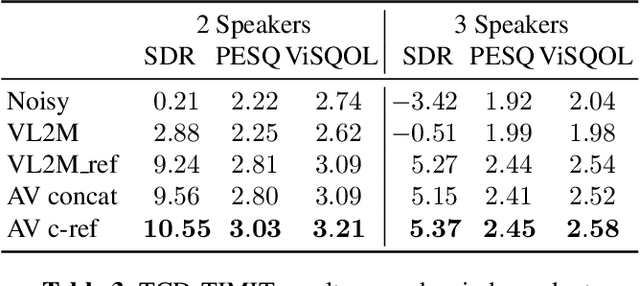
In this paper, we address the problem of enhancing the speech of a speaker of interest in a cocktail party scenario when visual information of the speaker of interest is available. Contrary to most previous studies, we do not learn visual features on the typically small audio-visual datasets, but use an already available face landmark detector (trained on a separate image dataset). The landmarks are used by LSTM-based models to generate time-frequency masks which are applied to the acoustic mixed-speech spectrogram. Results show that: (i) landmark motion features are very effective features for this task, (ii) similarly to previous work, reconstruction of the target speaker's spectrogram mediated by masking is significantly more accurate than direct spectrogram reconstruction, and (iii) the best masks depend on both motion landmark features and the input mixed-speech spectrogram. To the best of our knowledge, our proposed models are the first models trained and evaluated on the limited size GRID and TCD-TIMIT datasets, that achieve speaker-independent speech enhancement in a multi-talker setting.
Markerless visual servoing on unknown objects for humanoid robot platforms
Oct 12, 2017
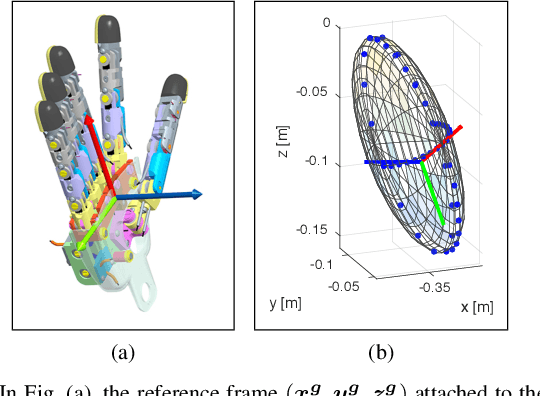
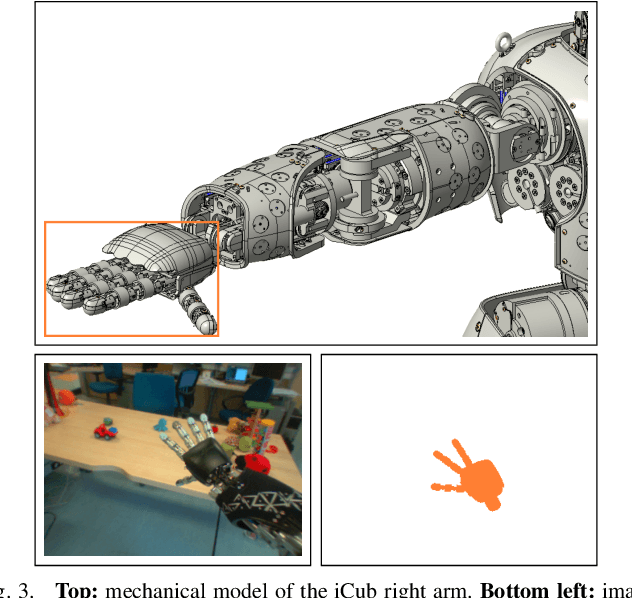
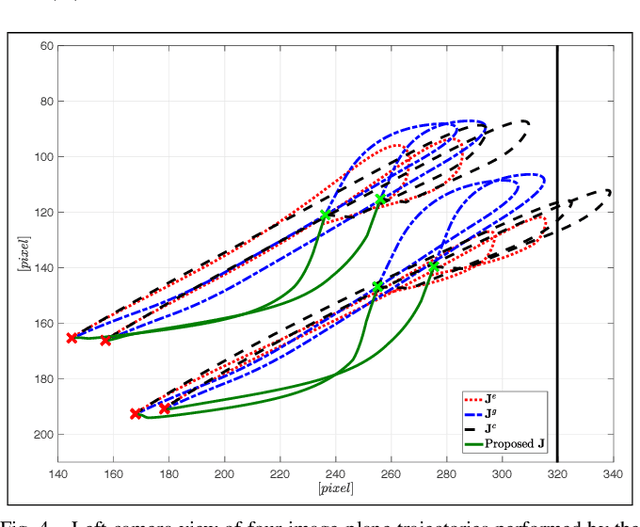
To precisely reach for an object with a humanoid robot, it is of central importance to have good knowledge of both end-effector, object pose and shape. In this work we propose a framework for markerless visual servoing on unknown objects, which is divided in four main parts: I) a least-squares minimization problem is formulated to find the volume of the object graspable by the robot's hand using its stereo vision; II) a recursive Bayesian filtering technique, based on Sequential Monte Carlo (SMC) filtering, estimates the 6D pose (position and orientation) of the robot's end-effector without the use of markers; III) a nonlinear constrained optimization problem is formulated to compute the desired graspable pose about the object; IV) an image-based visual servo control commands the robot's end-effector toward the desired pose. We demonstrate effectiveness and robustness of our approach with extensive experiments on the iCub humanoid robot platform, achieving real-time computation, smooth trajectories and sub-pixel precisions.
Visual end-effector tracking using a 3D model-aided particle filter for humanoid robot platforms
Aug 04, 2017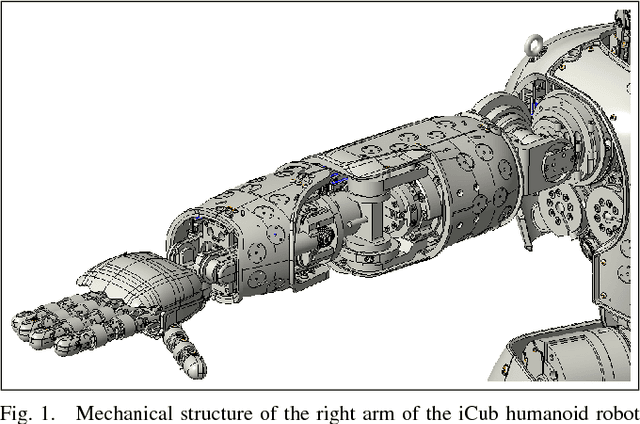


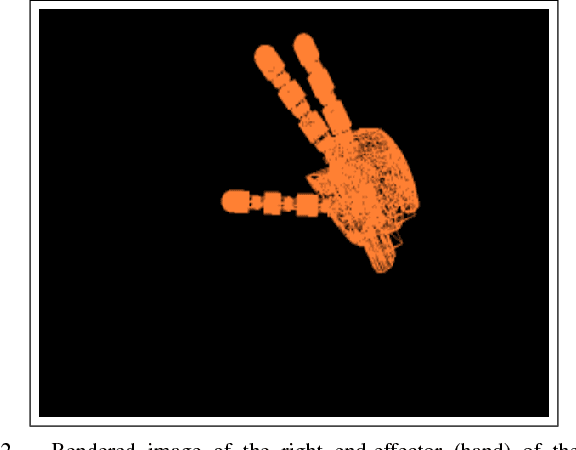
This paper addresses recursive markerless estimation of a robot's end-effector using visual observations from its cameras. The problem is formulated into the Bayesian framework and addressed using Sequential Monte Carlo (SMC) filtering. We use a 3D rendering engine and Computer Aided Design (CAD) schematics of the robot to virtually create images from the robot's camera viewpoints. These images are then used to extract information and estimate the pose of the end-effector. To this aim, we developed a particle filter for estimating the position and orientation of the robot's end-effector using the Histogram of Oriented Gradient (HOG) descriptors to capture robust characteristic features of shapes in both cameras and rendered images. We implemented the algorithm on the iCub humanoid robot and employed it in a closed-loop reaching scenario. We demonstrate that the tracking is robust to clutter, allows compensating for errors in the robot kinematics and servoing the arm in closed loop using vision.
Enhancing software module reusability using port plug-ins: an experiment with the iCub robot
Nov 04, 2014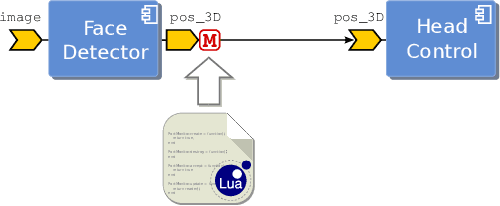
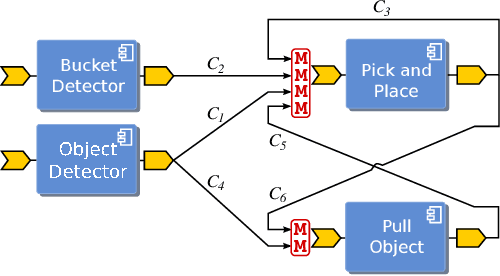

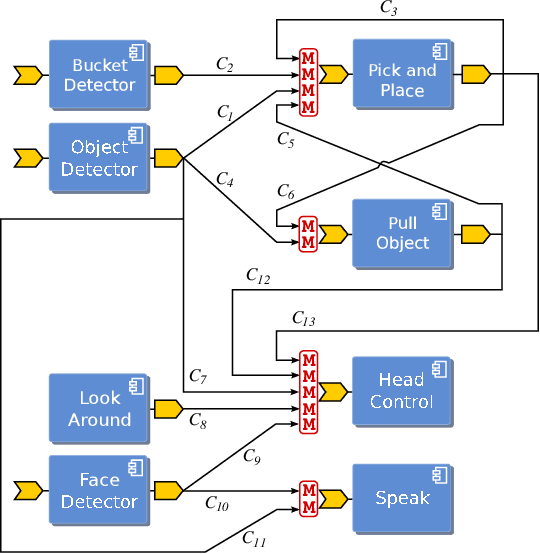
Systematically developing high--quality reusable software components is a difficult task and requires careful design to find a proper balance between potential reuse, functionalities and ease of implementation. Extendibility is an important property for software which helps to reduce cost of development and significantly boosts its reusability. This work introduces an approach to enhance components reusability by extending their functionalities using plug-ins at the level of the connection points (ports). Application--dependent functionalities such as data monitoring and arbitration can be implemented using a conventional scripting language and plugged into the ports of components. The main advantage of our approach is that it avoids to introduce application--dependent modifications to existing components, thus reducing development time and fostering the development of simpler and therefore more reusable components. Another advantage of our approach is that it reduces communication and deployment overheads as extra functionalities can be added without introducing additional modules.