 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Utility of Virtual Staining for Downstream Applications as it relates to Task Network Capacity
Jul 31, 2025Virtual staining, or in-silico-labeling, has been proposed to computationally generate synthetic fluorescence images from label-free images by use of deep learning-based image-to-image translation networks. In most reported studies, virtually stained images have been assessed only using traditional image quality measures such as structural similarity or signal-to-noise ratio. However, in biomedical imaging, images are typically acquired to facilitate an image-based inference, which we refer to as a downstream biological or clinical task. This study systematically investigates the utility of virtual staining for facilitating clinically relevant downstream tasks (like segmentation or classification) with consideration of the capacity of the deep neural networks employed to perform the tasks. Comprehensive empirical evaluations were conducted using biological datasets, assessing task performance by use of label-free, virtually stained, and ground truth fluorescence images. The results demonstrated that the utility of virtual staining is largely dependent on the ability of the segmentation or classification task network to extract meaningful task-relevant information, which is related to the concept of network capacity. Examples are provided in which virtual staining does not improve, or even degrades, segmentation or classification performance when the capacity of the associated task network is sufficiently large. The results demonstrate that task network capacity should be considered when deciding whether to perform virtual staining.
Improving VTE Identification through Language Models from Radiology Reports: A Comparative Study of Mamba, Phi-3 Mini, and BERT
Aug 16, 2024



Venous thromboembolism (VTE) is a critical cardiovascular condition, encompassing deep vein thrombosis (DVT) and pulmonary embolism (PE). Accurate and timely identification of VTE is essential for effective medical care. This study builds upon our previous work, which addressed VTE detection using deep learning methods for DVT and a hybrid approach combining deep learning and rule-based classification for PE. Our earlier approaches, while effective, had two major limitations: they were complex and required expert involvement for feature engineering of the rule set. To overcome these challenges, we utilize the Mamba architecture-based classifier. This model achieves remarkable results, with a 97\% accuracy and F1 score on the DVT dataset and a 98\% accuracy and F1 score on the PE dataset. In contrast to the previous hybrid method on PE identification, the Mamba classifier eliminates the need for hand-engineered rules, significantly reducing model complexity while maintaining comparable performance. Additionally, we evaluated a lightweight Large Language Model (LLM), Phi-3 Mini, in detecting VTE. While this model delivers competitive results, outperforming the baseline BERT models, it proves to be computationally intensive due to its larger parameter set. Our evaluation shows that the Mamba-based model demonstrates superior performance and efficiency in VTE identification, offering an effective solution to the limitations of previous approaches.
Efficient Data-Sketches and Fine-Tuning for Early Detection of Distributional Drift in Medical Imaging
Aug 15, 2024



Distributional drift detection is important in medical applications as it helps ensure the accuracy and reliability of models by identifying changes in the underlying data distribution that could affect diagnostic or treatment decisions. However, current methods have limitations in detecting drift; for example, the inclusion of abnormal datasets can lead to unfair comparisons. This paper presents an accurate and sensitive approach to detect distributional drift in CT-scan medical images by leveraging data-sketching and fine-tuning techniques. We developed a robust baseline library model for real-time anomaly detection, allowing for efficient comparison of incoming images and identification of anomalies. Additionally, we fine-tuned a vision transformer pre-trained model to extract relevant features using breast cancer images as an example, significantly enhancing model accuracy to 99.11\%. Combining with data-sketches and fine-tuning, our feature extraction evaluation demonstrated that cosine similarity scores between similar datasets provide greater improvements, from around 50\% increased to 100\%. Finally, the sensitivity evaluation shows that our solutions are highly sensitive to even 1\% salt-and-pepper and speckle noise, and it is not sensitive to lighting noise (e.g., lighting conditions have no impact on data drift). The proposed methods offer a scalable and reliable solution for maintaining the accuracy of diagnostic models in dynamic clinical environments.
Cross-Data Knowledge Graph Construction for LLM-enabled Educational Question-Answering System: A~Case~Study~at~HCMUT
Apr 14, 2024



In today's rapidly evolving landscape of Artificial Intelligence, large language models (LLMs) have emerged as a vibrant research topic. LLMs find applications in various fields and contribute significantly. Despite their powerful language capabilities, similar to pre-trained language models (PLMs), LLMs still face challenges in remembering events, incorporating new information, and addressing domain-specific issues or hallucinations. To overcome these limitations, researchers have proposed Retrieval-Augmented Generation (RAG) techniques, some others have proposed the integration of LLMs with Knowledge Graphs (KGs) to provide factual context, thereby improving performance and delivering more accurate feedback to user queries. Education plays a crucial role in human development and progress. With the technology transformation, traditional education is being replaced by digital or blended education. Therefore, educational data in the digital environment is increasing day by day. Data in higher education institutions are diverse, comprising various sources such as unstructured/structured text, relational databases, web/app-based API access, etc. Constructing a Knowledge Graph from these cross-data sources is not a simple task. This article proposes a method for automatically constructing a Knowledge Graph from multiple data sources and discusses some initial applications (experimental trials) of KG in conjunction with LLMs for question-answering tasks.
CAPTAIN at COLIEE 2023: Efficient Methods for Legal Information Retrieval and Entailment Tasks
Jan 07, 2024The Competition on Legal Information Extraction/Entailment (COLIEE) is held annually to encourage advancements in the automatic processing of legal texts. Processing legal documents is challenging due to the intricate structure and meaning of legal language. In this paper, we outline our strategies for tackling Task 2, Task 3, and Task 4 in the COLIEE 2023 competition. Our approach involved utilizing appropriate state-of-the-art deep learning methods, designing methods based on domain characteristics observation, and applying meticulous engineering practices and methodologies to the competition. As a result, our performance in these tasks has been outstanding, with first places in Task 2 and Task 3, and promising results in Task 4. Our source code is available at https://github.com/Nguyen2015/CAPTAIN-COLIEE2023/tree/coliee2023.
Improving VTE Identification through Adaptive NLP Model Selection and Clinical Expert Rule-based Classifier from Radiology Reports
Sep 21, 2023



Rapid and accurate identification of Venous thromboembolism (VTE), a severe cardiovascular condition including deep vein thrombosis (DVT) and pulmonary embolism (PE), is important for effective treatment. Leveraging Natural Language Processing (NLP) on radiology reports, automated methods have shown promising advancements in identifying VTE events from retrospective data cohorts or aiding clinical experts in identifying VTE events from radiology reports. However, effectively training Deep Learning (DL) and the NLP models is challenging due to limited labeled medical text data, the complexity and heterogeneity of radiology reports, and data imbalance. This study proposes novel method combinations of DL methods, along with data augmentation, adaptive pre-trained NLP model selection, and a clinical expert NLP rule-based classifier, to improve the accuracy of VTE identification in unstructured (free-text) radiology reports. Our experimental results demonstrate the model's efficacy, achieving an impressive 97\% accuracy and 97\% F1 score in predicting DVT, and an outstanding 98.3\% accuracy and 98.4\% F1 score in predicting PE. These findings emphasize the model's robustness and its potential to significantly contribute to VTE research.
Enabling Quartile-based Estimated-Mean Gradient Aggregation As Baseline for Federated Image Classifications
Sep 21, 2023



Federated Learning (FL) has revolutionized how we train deep neural networks by enabling decentralized collaboration while safeguarding sensitive data and improving model performance. However, FL faces two crucial challenges: the diverse nature of data held by individual clients and the vulnerability of the FL system to security breaches. This paper introduces an innovative solution named Estimated Mean Aggregation (EMA) that not only addresses these challenges but also provides a fundamental reference point as a $\mathsf{baseline}$ for advanced aggregation techniques in FL systems. EMA's significance lies in its dual role: enhancing model security by effectively handling malicious outliers through trimmed means and uncovering data heterogeneity to ensure that trained models are adaptable across various client datasets. Through a wealth of experiments, EMA consistently demonstrates high accuracy and area under the curve (AUC) compared to alternative methods, establishing itself as a robust baseline for evaluating the effectiveness and security of FL aggregation methods. EMA's contributions thus offer a crucial step forward in advancing the efficiency, security, and versatility of decentralized deep learning in the context of FL.
Soft Merging: A Flexible and Robust Soft Model Merging Approach for Enhanced Neural Network Performance
Sep 21, 2023



Stochastic Gradient Descent (SGD), a widely used optimization algorithm in deep learning, is often limited to converging to local optima due to the non-convex nature of the problem. Leveraging these local optima to improve model performance remains a challenging task. Given the inherent complexity of neural networks, the simple arithmetic averaging of the obtained local optima models in undesirable results. This paper proposes a {\em soft merging} method that facilitates rapid merging of multiple models, simplifies the merging of specific parts of neural networks, and enhances robustness against malicious models with extreme values. This is achieved by learning gate parameters through a surrogate of the $l_0$ norm using hard concrete distribution without modifying the model weights of the given local optima models. This merging process not only enhances the model performance by converging to a better local optimum, but also minimizes computational costs, offering an efficient and explicit learning process integrated with stochastic gradient descent. Thorough experiments underscore the effectiveness and superior performance of the merged neural networks.
Resource-Aware Heterogeneous Federated Learning using Neural Architecture Search
Nov 09, 2022



Federated Learning (FL) is extensively used to train AI/ML models in distributed and privacy-preserving settings. Participant edge devices in FL systems typically contain non-independent and identically distributed~(Non-IID) private data and unevenly distributed computational resources. Preserving user data privacy while optimizing AI/ML models in a heterogeneous federated network requires us to address data heterogeneity and system/resource heterogeneity. Hence, we propose \underline{R}esource-\underline{a}ware \underline{F}ederated \underline{L}earning~(RaFL) to address these challenges. RaFL allocates resource-aware models to edge devices using Neural Architecture Search~(NAS) and allows heterogeneous model architecture deployment by knowledge extraction and fusion. Integrating NAS into FL enables on-demand customized model deployment for resource-diverse edge devices. Furthermore, we propose a multi-model architecture fusion scheme allowing the aggregation of the distributed learning results. Results demonstrate RaFL's superior resource efficiency compared to SoTA.
SPATL: Salient Parameter Aggregation and Transfer Learning for Heterogeneous Clients in Federated Learning
Nov 29, 2021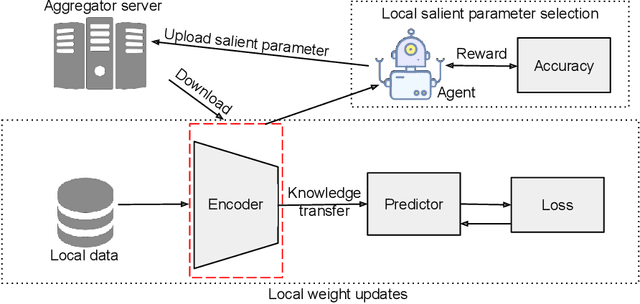
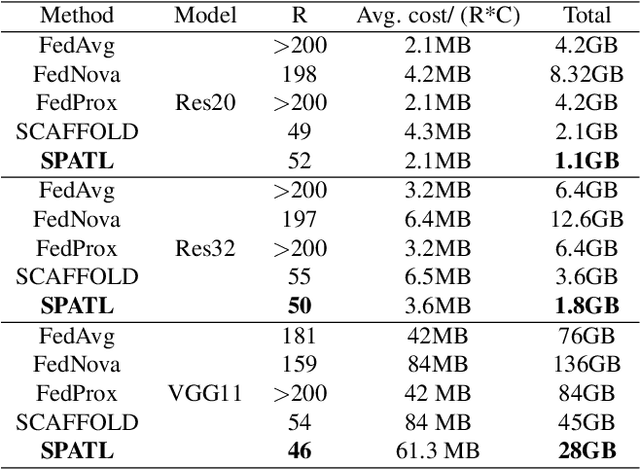
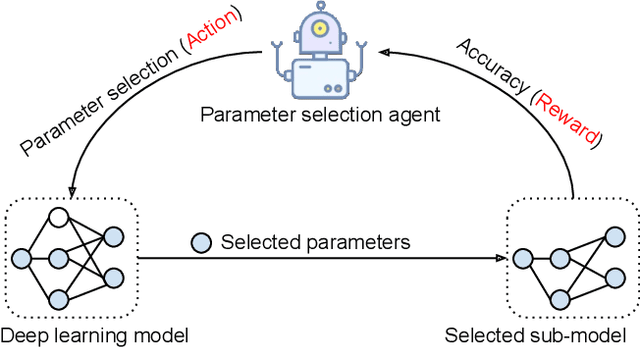
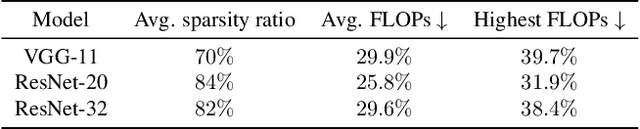
Efficient federated learning is one of the key challenges for training and deploying AI models on edge devices. However, maintaining data privacy in federated learning raises several challenges including data heterogeneity, expensive communication cost, and limited resources. In this paper, we address the above issues by (a) introducing a salient parameter selection agent based on deep reinforcement learning on local clients, and aggregating the selected salient parameters on the central server, and (b) splitting a normal deep learning model~(e.g., CNNs) as a shared encoder and a local predictor, and training the shared encoder through federated learning while transferring its knowledge to Non-IID clients by the local customized predictor. The proposed method (a) significantly reduces the communication overhead of federated learning and accelerates the model inference, while method (b) addresses the data heterogeneity issue in federated learning. Additionally, we leverage the gradient control mechanism to correct the gradient heterogeneity among clients. This makes the training process more stable and converge faster. The experiments show our approach yields a stable training process and achieves notable results compared with the state-of-the-art methods. Our approach significantly reduces the communication cost by up to 108 GB when training VGG-11, and needed $7.6 \times$ less communication overhead when training ResNet-20, while accelerating the local inference by reducing up to $39.7\%$ FLOPs on VGG-11.