 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBesov Function Approximation and Binary Classification on Low-Dimensional Manifolds Using Convolutional Residual Networks
Sep 10, 2021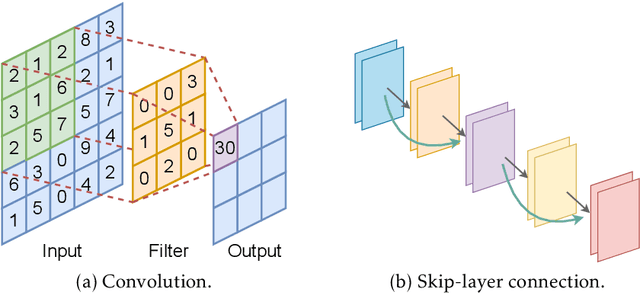

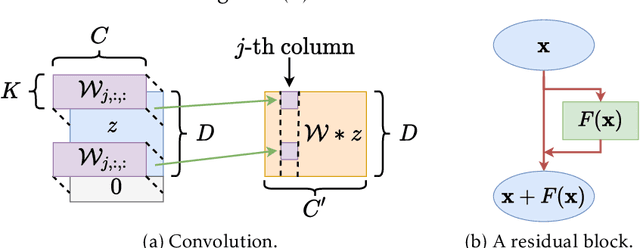
Most of existing statistical theories on deep neural networks have sample complexities cursed by the data dimension and therefore cannot well explain the empirical success of deep learning on high-dimensional data. To bridge this gap, we propose to exploit low-dimensional geometric structures of the real world data sets. We establish theoretical guarantees of convolutional residual networks (ConvResNet) in terms of function approximation and statistical estimation for binary classification. Specifically, given the data lying on a $d$-dimensional manifold isometrically embedded in $\mathbb{R}^D$, we prove that if the network architecture is properly chosen, ConvResNets can (1) approximate Besov functions on manifolds with arbitrary accuracy, and (2) learn a classifier by minimizing the empirical logistic risk, which gives an excess risk in the order of $n^{-\frac{s}{2s+2(s\vee d)}}$, where $s$ is a smoothness parameter. This implies that the sample complexity depends on the intrinsic dimension $d$, instead of the data dimension $D$. Our results demonstrate that ConvResNets are adaptive to low-dimensional structures of data sets.
QUEACO: Borrowing Treasures from Weakly-labeled Behavior Data for Query Attribute Value Extraction
Sep 05, 2021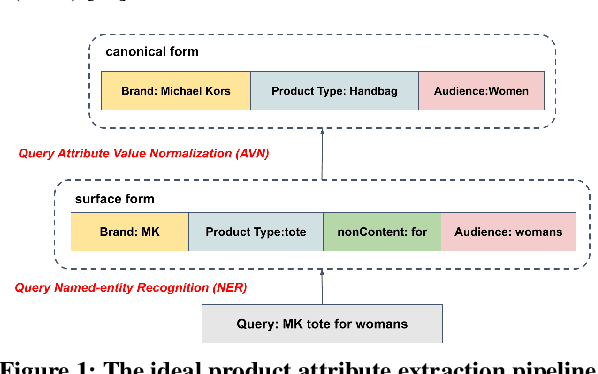

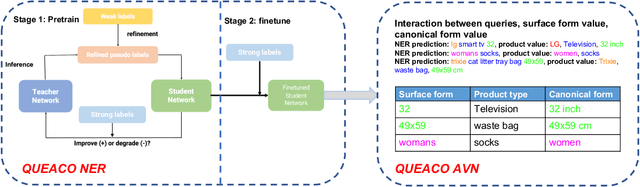
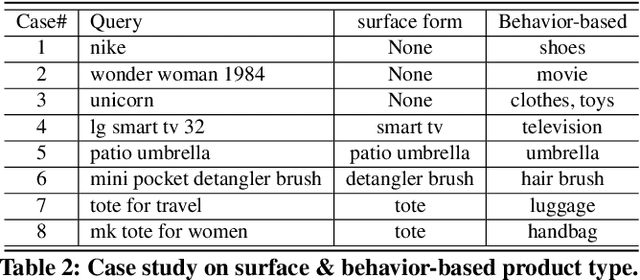
We study the problem of query attribute value extraction, which aims to identify named entities from user queries as diverse surface form attribute values and afterward transform them into formally canonical forms. Such a problem consists of two phases: {named entity recognition (NER)} and {attribute value normalization (AVN)}. However, existing works only focus on the NER phase but neglect equally important AVN. To bridge this gap, this paper proposes a unified query attribute value extraction system in e-commerce search named QUEACO, which involves both two phases. Moreover, by leveraging large-scale weakly-labeled behavior data, we further improve the extraction performance with less supervision cost. Specifically, for the NER phase, QUEACO adopts a novel teacher-student network, where a teacher network that is trained on the strongly-labeled data generates pseudo-labels to refine the weakly-labeled data for training a student network. Meanwhile, the teacher network can be dynamically adapted by the feedback of the student's performance on strongly-labeled data to maximally denoise the noisy supervisions from the weak labels. For the AVN phase, we also leverage the weakly-labeled query-to-attribute behavior data to normalize surface form attribute values from queries into canonical forms from products. Extensive experiments on a real-world large-scale E-commerce dataset demonstrate the effectiveness of QUEACO.
* The 30th ACM International Conference on Information and Knowledge Management (CIKM 2021, Applied Research Track)
Implicit Regularization of Bregman Proximal Point Algorithm and Mirror Descent on Separable Data
Aug 15, 2021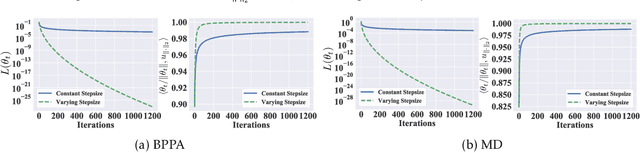
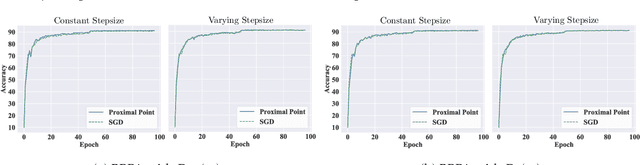
Bregman proximal point algorithm (BPPA), as one of the centerpieces in the optimization toolbox, has been witnessing emerging applications. With simple and easy to implement update rule, the algorithm bears several compelling intuitions for empirical successes, yet rigorous justifications are still largely unexplored. We study the computational properties of BPPA through classification tasks with separable data, and demonstrate provable algorithmic regularization effects associated with BPPA. We show that BPPA attains non-trivial margin, which closely depends on the condition number of the distance generating function inducing the Bregman divergence. We further demonstrate that the dependence on the condition number is tight for a class of problems, thus showing the importance of divergence in affecting the quality of the obtained solutions. In addition, we extend our findings to mirror descent (MD), for which we establish similar connections between the margin and Bregman divergence. We demonstrate through a concrete example, and show BPPA/MD converges in direction to the maximal margin solution with respect to the Mahalanobis distance. Our theoretical findings are among the first to demonstrate the benign learning properties BPPA/MD, and also provide corroborations for a careful choice of divergence in the algorithmic design.
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Jun 16, 2021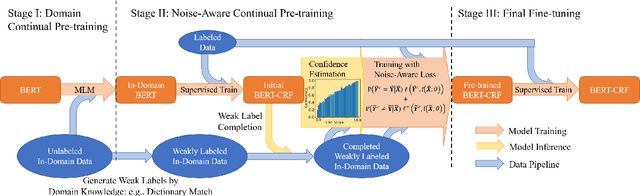
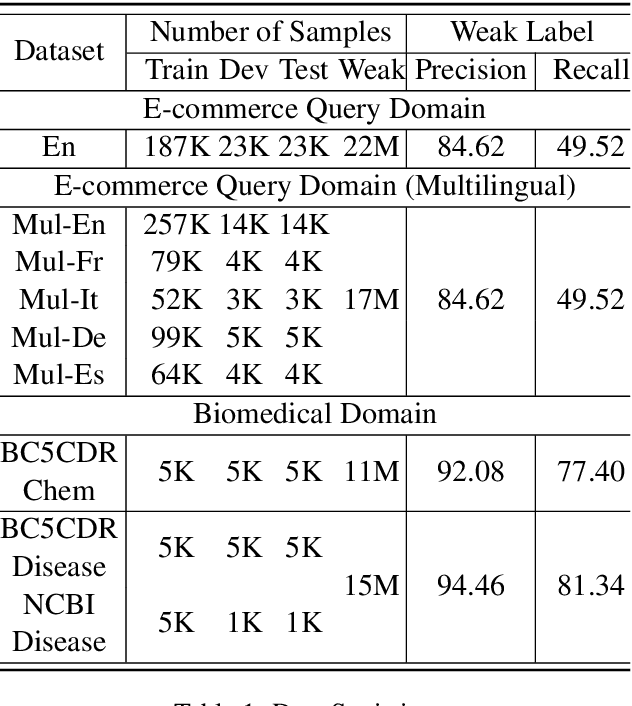
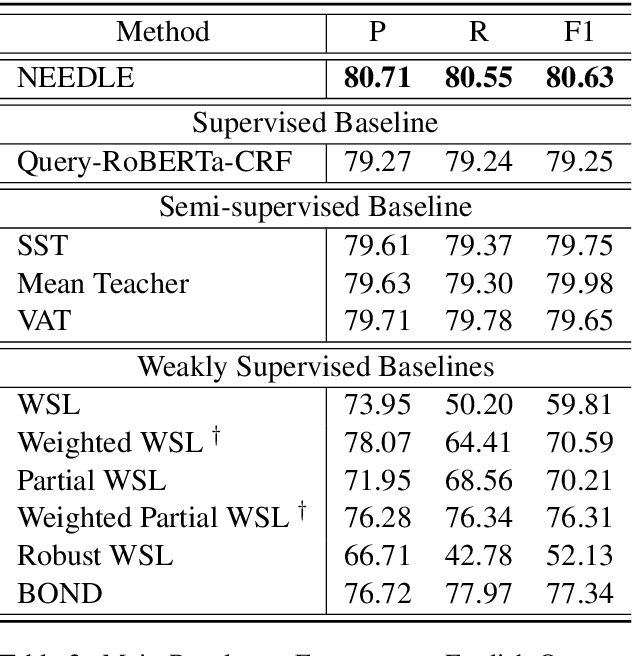
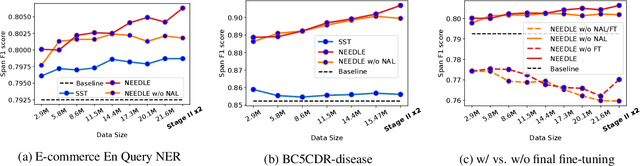
Weak supervision has shown promising results in many natural language processing tasks, such as Named Entity Recognition (NER). Existing work mainly focuses on learning deep NER models only with weak supervision, i.e., without any human annotation, and shows that by merely using weakly labeled data, one can achieve good performance, though still underperforms fully supervised NER with manually/strongly labeled data. In this paper, we consider a more practical scenario, where we have both a small amount of strongly labeled data and a large amount of weakly labeled data. Unfortunately, we observe that weakly labeled data does not necessarily improve, or even deteriorate the model performance (due to the extensive noise in the weak labels) when we train deep NER models over a simple or weighted combination of the strongly labeled and weakly labeled data. To address this issue, we propose a new multi-stage computational framework -- NEEDLE with three essential ingredients: (1) weak label completion, (2) noise-aware loss function, and (3) final fine-tuning over the strongly labeled data. Through experiments on E-commerce query NER and Biomedical NER, we demonstrate that NEEDLE can effectively suppress the noise of the weak labels and outperforms existing methods. In particular, we achieve new SOTA F1-scores on 3 Biomedical NER datasets: BC5CDR-chem 93.74, BC5CDR-disease 90.69, NCBI-disease 92.28.
Super Tickets in Pre-Trained Language Models: From Model Compression to Improving Generalization
Jun 08, 2021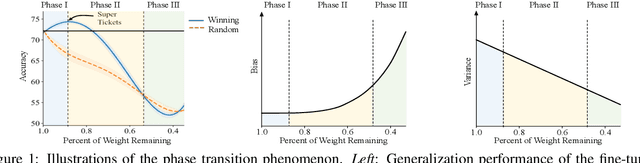

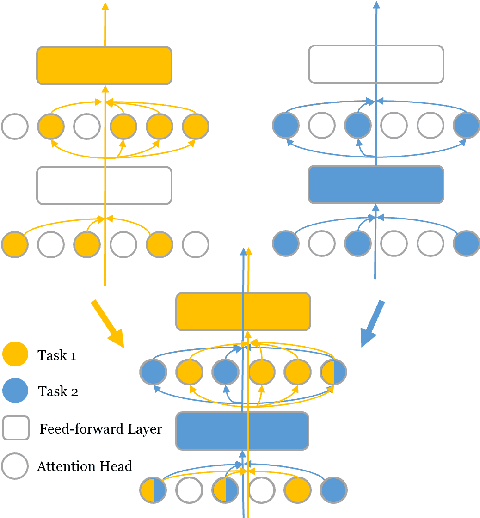

The Lottery Ticket Hypothesis suggests that an over-parametrized network consists of ``lottery tickets'', and training a certain collection of them (i.e., a subnetwork) can match the performance of the full model. In this paper, we study such a collection of tickets, which is referred to as ``winning tickets'', in extremely over-parametrized models, e.g., pre-trained language models. We observe that at certain compression ratios, the generalization performance of the winning tickets can not only match but also exceed that of the full model. In particular, we observe a phase transition phenomenon: As the compression ratio increases, generalization performance of the winning tickets first improves then deteriorates after a certain threshold. We refer to the tickets on the threshold as ``super tickets''. We further show that the phase transition is task and model dependent -- as the model size becomes larger and the training data set becomes smaller, the transition becomes more pronounced. Our experiments on the GLUE benchmark show that the super tickets improve single task fine-tuning by $0.9$ points on BERT-base and $1.0$ points on BERT-large, in terms of task-average score. We also demonstrate that adaptively sharing the super tickets across tasks benefits multi-task learning.
Permutation Invariant Policy Optimization for Mean-Field Multi-Agent Reinforcement Learning: A Principled Approach
May 18, 2021
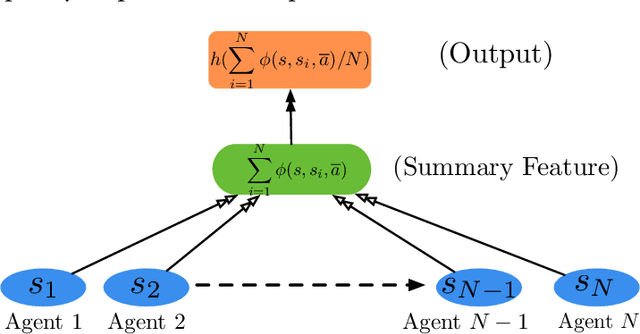
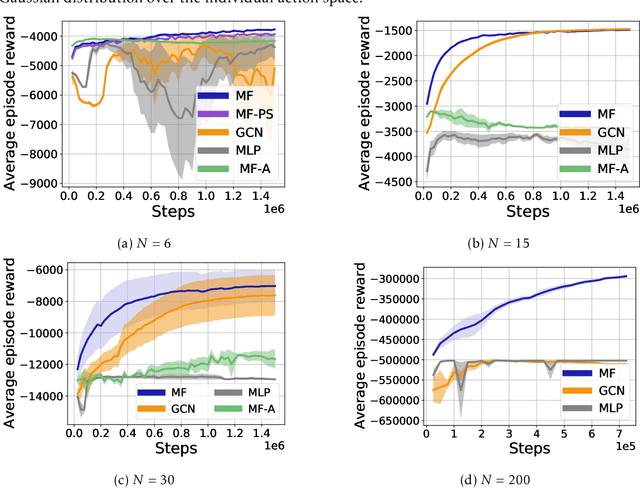
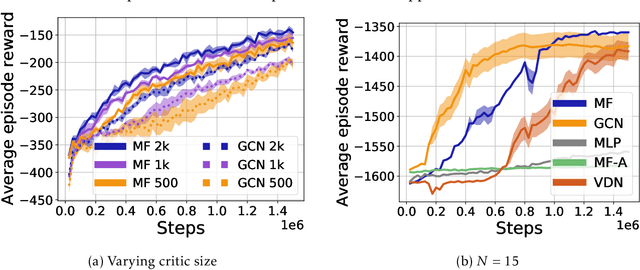
Multi-agent reinforcement learning (MARL) becomes more challenging in the presence of more agents, as the capacity of the joint state and action spaces grows exponentially in the number of agents. To address such a challenge of scale, we identify a class of cooperative MARL problems with permutation invariance, and formulate it as a mean-field Markov decision processes (MDP). To exploit the permutation invariance therein, we propose the mean-field proximal policy optimization (MF-PPO) algorithm, at the core of which is a permutation-invariant actor-critic neural architecture. We prove that MF-PPO attains the globally optimal policy at a sublinear rate of convergence. Moreover, its sample complexity is independent of the number of agents. We validate the theoretical advantages of MF-PPO with numerical experiments in the multi-agent particle environment (MPE). In particular, we show that the inductive bias introduced by the permutation-invariant neural architecture enables MF-PPO to outperform existing competitors with a smaller number of model parameters, which is the key to its generalization performance.
COUnty aggRegation mixup AuGmEntation (COURAGE) COVID-19 Prediction
May 03, 2021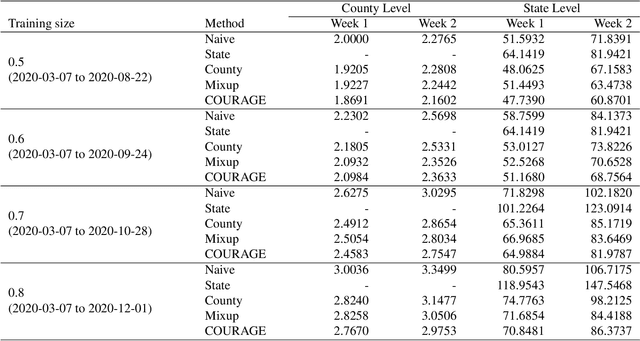
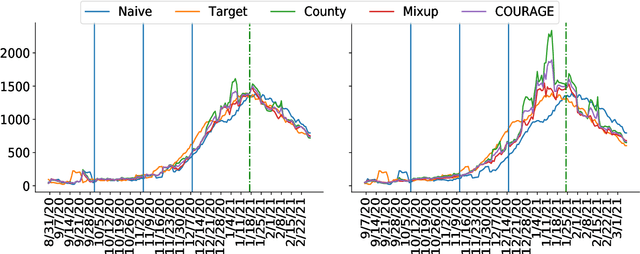
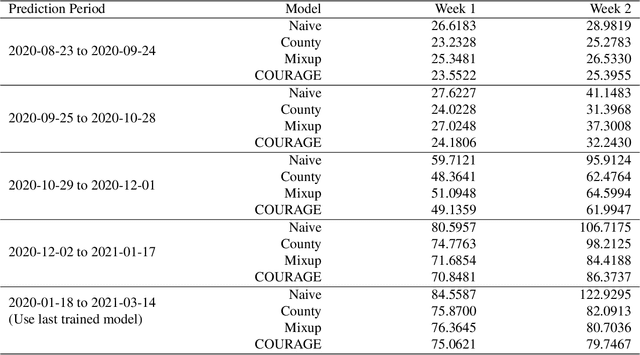
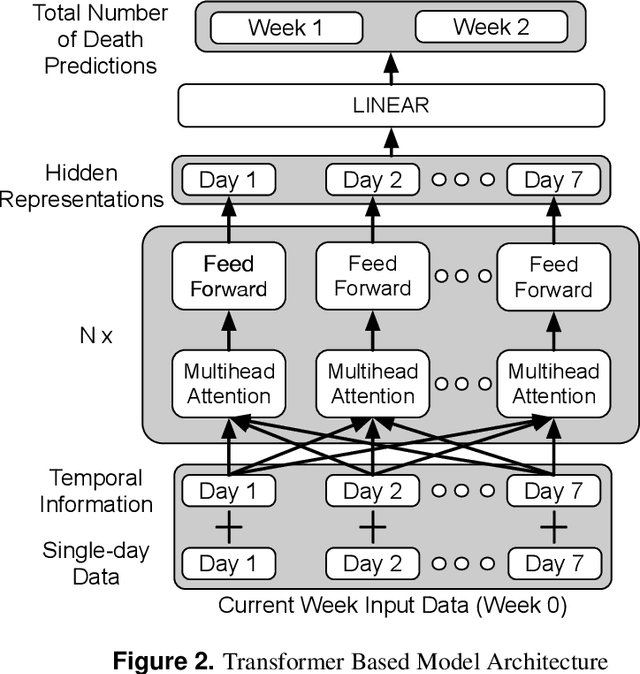
The global spread of COVID-19, the disease caused by the novel coronavirus SARS-CoV-2, has cast a significant threat to mankind. As the COVID-19 situation continues to evolve, predicting localized disease severity is crucial for advanced resource allocation. This paper proposes a method named COURAGE (COUnty aggRegation mixup AuGmEntation) to generate a short-term prediction of 2-week-ahead COVID-19 related deaths for each county in the United States, leveraging modern deep learning techniques. Specifically, our method adopts a self-attention model from Natural Language Processing, known as the transformer model, to capture both short-term and long-term dependencies within the time series while enjoying computational efficiency. Our model fully utilizes publicly available information of COVID-19 related confirmed cases, deaths, community mobility trends and demographic information, and can produce state-level prediction as an aggregation of the corresponding county-level predictions. Our numerical experiments demonstrate that our model achieves the state-of-the-art performance among the publicly available benchmark models.
Adversarial Training as Stackelberg Game: An Unrolled Optimization Approach
Apr 11, 2021
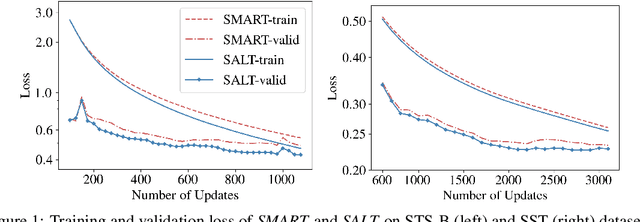
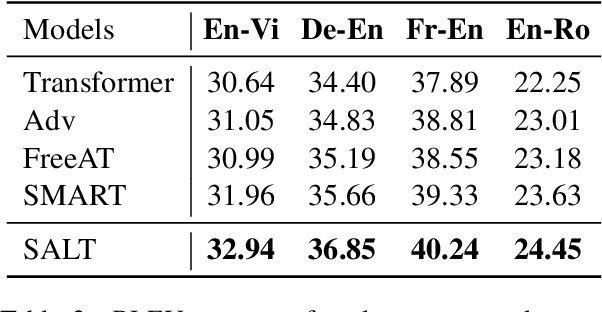
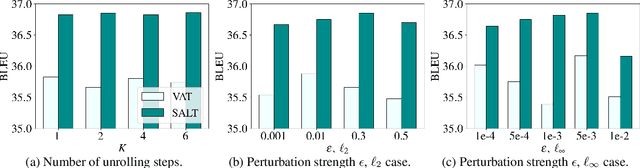
Adversarial training has been shown to improve the generalization performance of deep learning models in various natural language processing tasks. Existing works usually formulate adversarial training as a zero-sum game, which is solved by alternating gradient descent/ascent algorithms. Such a formulation treats the adversarial and the defending players equally, which is undesirable because only the defending player contributes to the generalization performance. To address this issue, we propose Stackelberg Adversarial Training (SALT), which formulates adversarial training as a Stackelberg game. This formulation induces a competition between a leader and a follower, where the follower generates perturbations, and the leader trains the model subject to the perturbations. Different from conventional adversarial training, in SALT, the leader is in an advantageous position. When the leader moves, it recognizes the strategy of the follower and takes the anticipated follower's outcomes into consideration. Such a leader's advantage enables us to improve the model fitting to the unperturbed data. The leader's strategic information is captured by the Stackelberg gradient, which is obtained using an unrolling algorithm. Our experimental results on a set of machine translation and natural language understanding tasks show that SALT outperforms existing adversarial training baselines across all tasks.
Token-wise Curriculum Learning for Neural Machine Translation
Mar 20, 2021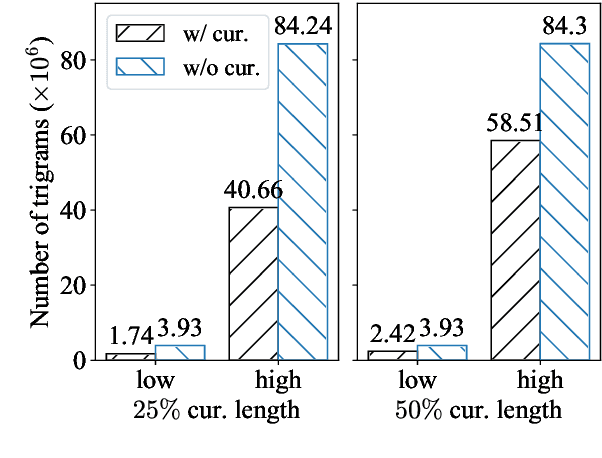
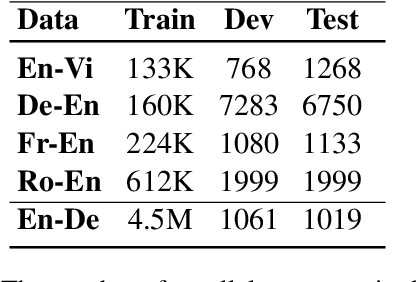
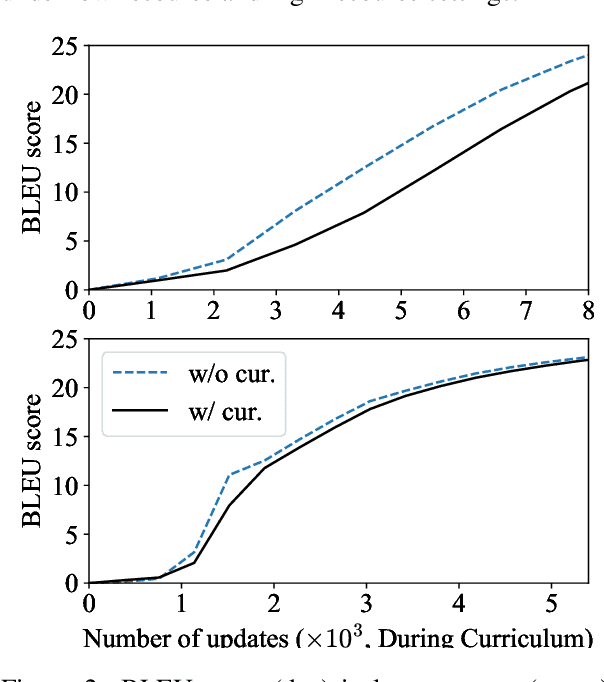
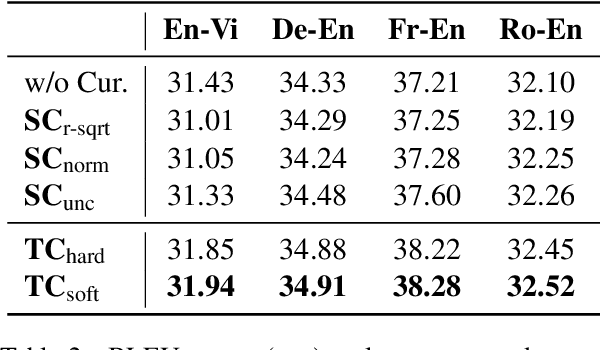
Existing curriculum learning approaches to Neural Machine Translation (NMT) require sampling sufficient amounts of "easy" samples from training data at the early training stage. This is not always achievable for low-resource languages where the amount of training data is limited. To address such limitation, we propose a novel token-wise curriculum learning approach that creates sufficient amounts of easy samples. Specifically, the model learns to predict a short sub-sequence from the beginning part of each target sentence at the early stage of training, and then the sub-sequence is gradually expanded as the training progresses. Such a new curriculum design is inspired by the cumulative effect of translation errors, which makes the latter tokens more difficult to predict than the beginning ones. Extensive experiments show that our approach can consistently outperform baselines on 5 language pairs, especially for low-resource languages. Combining our approach with sentence-level methods further improves the performance on high-resource languages.
Reinforcement Learning for Adaptive Mesh Refinement
Mar 01, 2021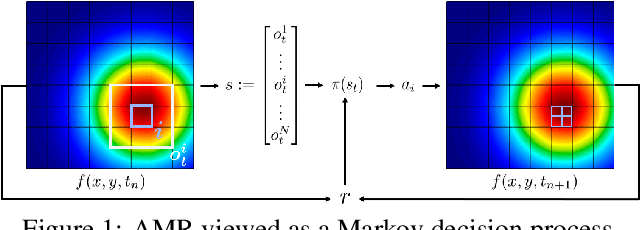
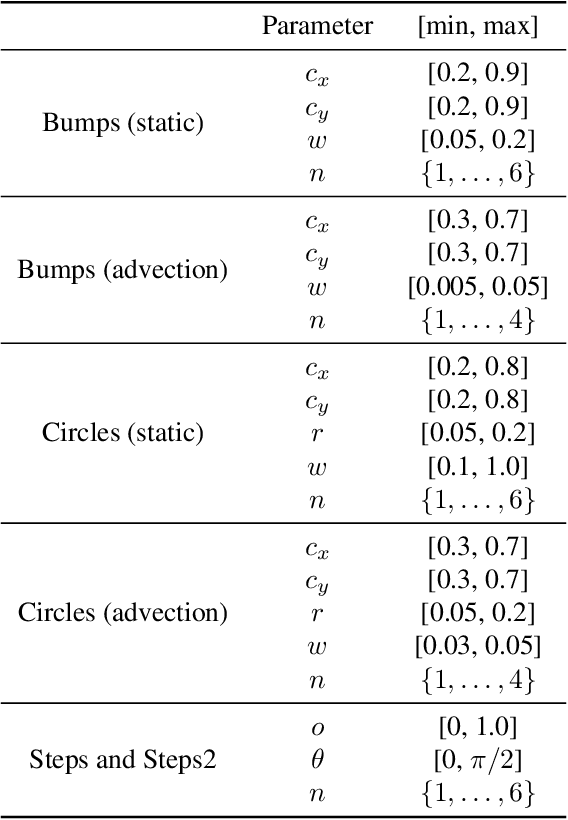
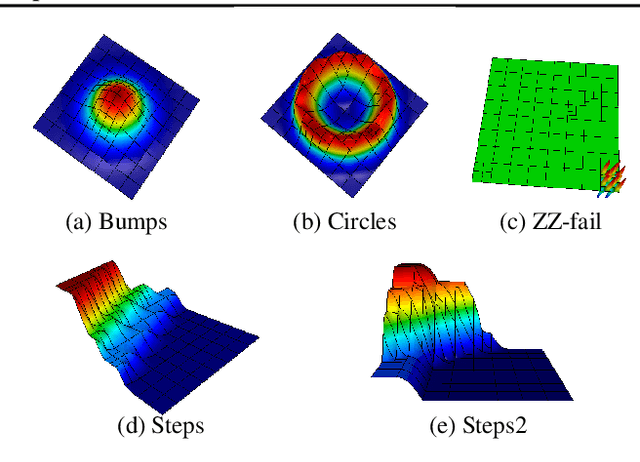

Large-scale finite element simulations of complex physical systems governed by partial differential equations crucially depend on adaptive mesh refinement (AMR) to allocate computational budget to regions where higher resolution is required. Existing scalable AMR methods make heuristic refinement decisions based on instantaneous error estimation and thus do not aim for long-term optimality over an entire simulation. We propose a novel formulation of AMR as a Markov decision process and apply deep reinforcement learning (RL) to train refinement policies directly from simulation. AMR poses a new problem for RL in that both the state dimension and available action set changes at every step, which we solve by proposing new policy architectures with differing generality and inductive bias. The model sizes of these policy architectures are independent of the mesh size and hence scale to arbitrarily large and complex simulations. We demonstrate in comprehensive experiments on static function estimation and the advection of different fields that RL policies can be competitive with a widely-used error estimator and generalize to larger, more complex, and unseen test problems.