 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePicasso: A Sparse Learning Library for High Dimensional Data Analysis in R and Python
Jun 27, 2020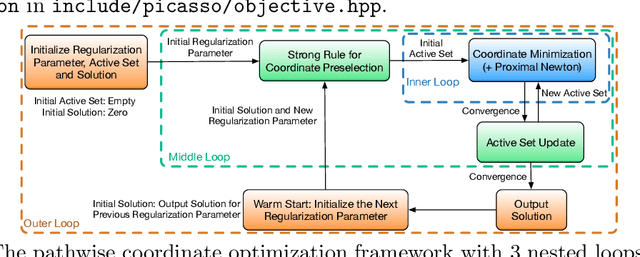
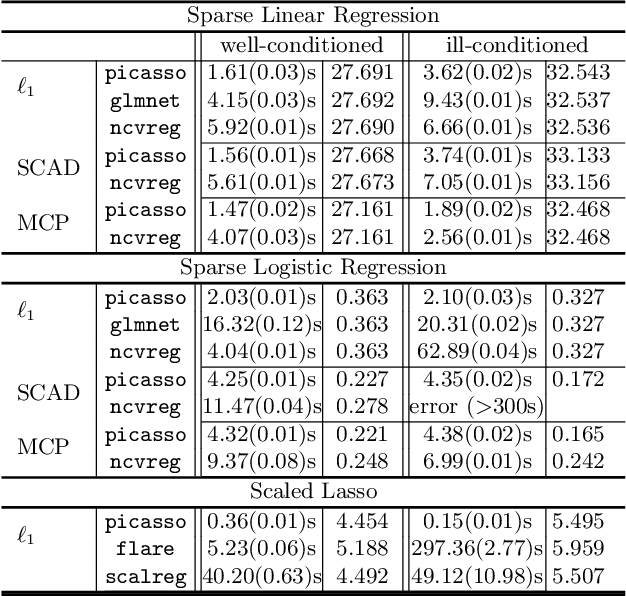
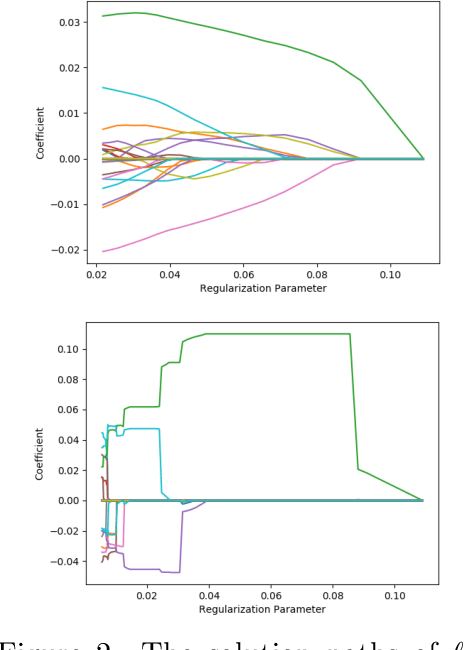
We describe a new library named picasso, which implements a unified framework of pathwise coordinate optimization for a variety of sparse learning problems (e.g., sparse linear regression, sparse logistic regression, sparse Poisson regression and scaled sparse linear regression) combined with efficient active set selection strategies. Besides, the library allows users to choose different sparsity-inducing regularizers, including the convex $\ell_1$, nonconvex MCP and SCAD regularizers. The library is coded in C++ and has user-friendly R and Python wrappers. Numerical experiments demonstrate that picasso can scale up to large problems efficiently.
The huge Package for High-dimensional Undirected Graph Estimation in R
Jun 26, 2020
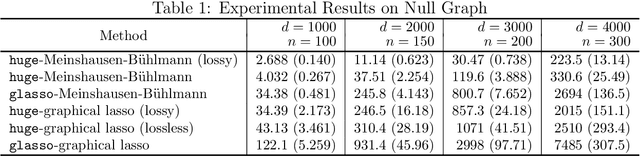

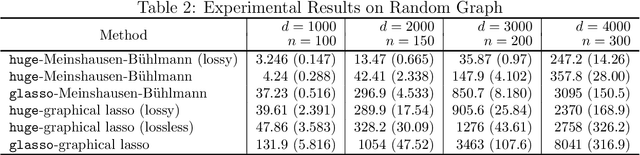
We describe an R package named huge which provides easy-to-use functions for estimating high dimensional undirected graphs from data. This package implements recent results in the literature, including Friedman et al. (2007), Liu et al. (2009, 2012) and Liu et al. (2010). Compared with the existing graph estimation package glasso, the huge package provides extra features: (1) instead of using Fortan, it is written in C, which makes the code more portable and easier to modify; (2) besides fitting Gaussian graphical models, it also provides functions for fitting high dimensional semiparametric Gaussian copula models; (3) more functions like data-dependent model selection, data generation and graph visualization; (4) a minor convergence problem of the graphical lasso algorithm is corrected; (5) the package allows the user to apply both lossless and lossy screening rules to scale up large-scale problems, making a tradeoff between computational and statistical efficiency.
Towards Understanding Hierarchical Learning: Benefits of Neural Representations
Jun 24, 2020Deep neural networks can empirically perform efficient hierarchical learning, in which the layers learn useful representations of the data. However, how they make use of the intermediate representations are not explained by recent theories that relate them to "shallow learners" such as kernels. In this work, we demonstrate that intermediate neural representations add more flexibility to neural networks and can be advantageous over raw inputs. We consider a fixed, randomly initialized neural network as a representation function fed into another trainable network. When the trainable network is the quadratic Taylor model of a wide two-layer network, we show that neural representation can achieve improved sample complexities compared with the raw input: For learning a low-rank degree-$p$ polynomial ($p \geq 4$) in $d$ dimension, neural representation requires only $\tilde{O}(d^{\lceil p/2 \rceil})$ samples, while the best-known sample complexity upper bound for the raw input is $\tilde{O}(d^{p-1})$. We contrast our result with a lower bound showing that neural representations do not improve over the raw input (in the infinite width limit), when the trainable network is instead a neural tangent kernel. Our results characterize when neural representations are beneficial, and may provide a new perspective on why depth is important in deep learning.
Deep Reinforcement Learning with Smooth Policy
Mar 24, 2020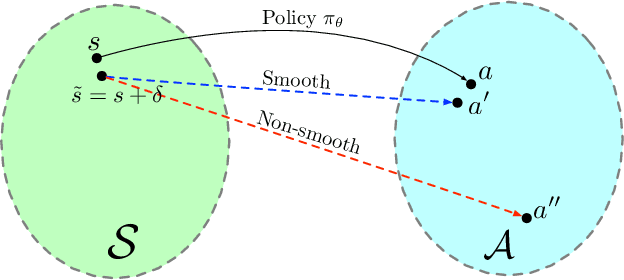

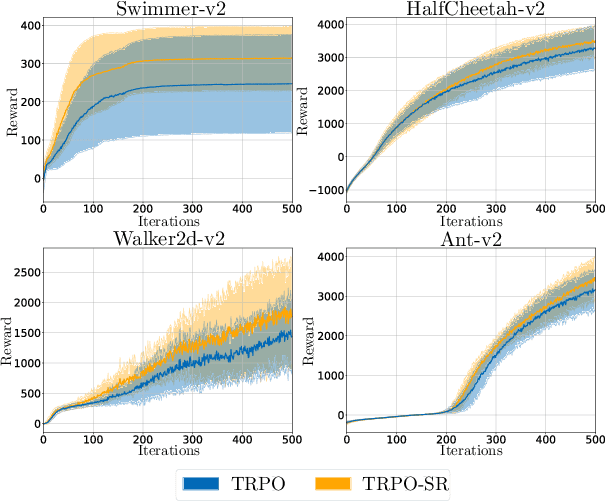
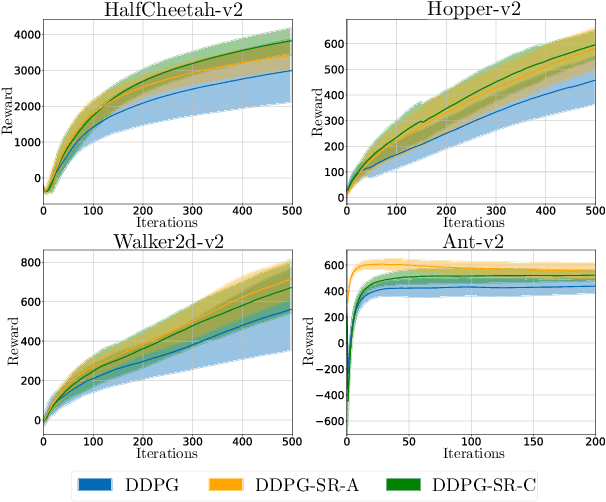
Deep neural networks have been widely adopted in modern reinforcement learning (RL) algorithms with great empirical successes in various domains. However, the large search space of training a neural network requires a significant amount of data, which makes the current RL algorithms not sample efficient. Motivated by the fact that many environments with continuous state space have smooth transitions, we propose to learn a smooth policy that behaves smoothly with respect to states. In contrast to policies parameterized by linear/reproducing kernel functions, where simple regularization techniques suffice to control smoothness, for neural network based reinforcement learning algorithms, there is no readily available solution to learn a smooth policy. In this paper, we develop a new training framework --- $\textbf{S}$mooth $\textbf{R}$egularized $\textbf{R}$einforcement $\textbf{L}$earning ($\textbf{SR}^2\textbf{L}$), where the policy is trained with smoothness-inducing regularization. Such regularization effectively constrains the search space of the learning algorithms and enforces smoothness in the learned policy. We apply the proposed framework to both on-policy (TRPO) and off-policy algorithm (DDPG). Through extensive experiments, we demonstrate that our method achieves improved sample efficiency.
Transformer Hawkes Process
Feb 21, 2020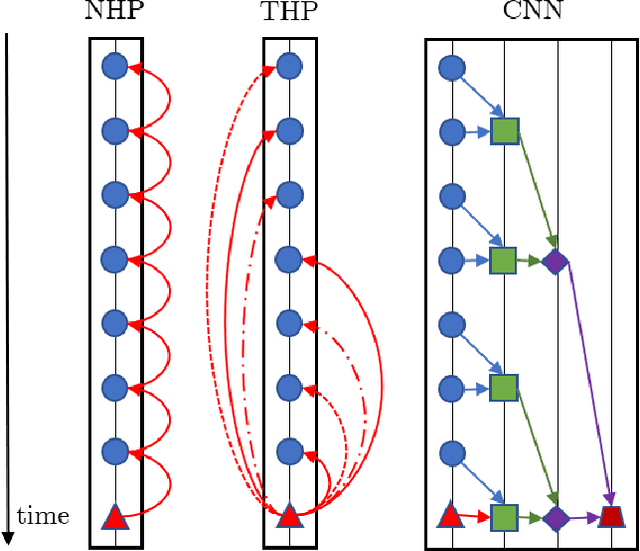
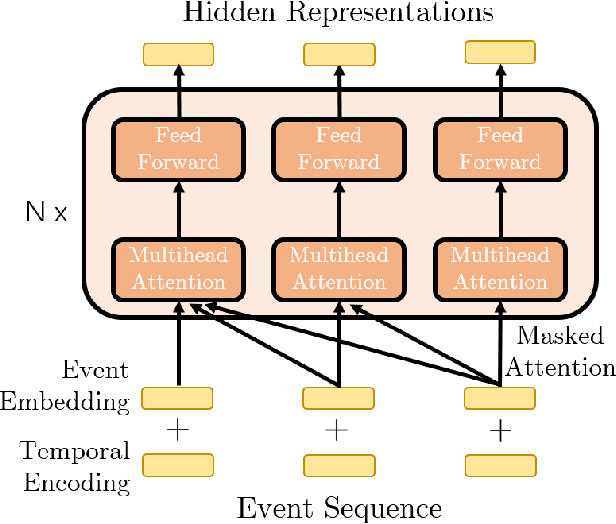
Modern data acquisition routinely produce massive amounts of event sequence data in various domains, such as social media, healthcare, and financial markets. These data often exhibit complicated short-term and long-term temporal dependencies. However, most of the existing recurrent neural network-based point process models fail to capture such dependencies, and yield unreliable prediction performance. To address this issue, we propose a Transformer Hawkes Process (THP) model, which leverages the self-attention mechanism to capture long-term dependencies and meanwhile enjoys computational efficiency. Numerical experiments on various datasets show that THP outperforms existing models in terms of both likelihood and event prediction accuracy by a notable margin. Moreover, THP is quite general and can incorporate additional structural knowledge. We provide a concrete example, where THP achieves improved prediction performance for learning multiple point processes when incorporating their relational information.
Differentiable Top-k Operator with Optimal Transport
Feb 18, 2020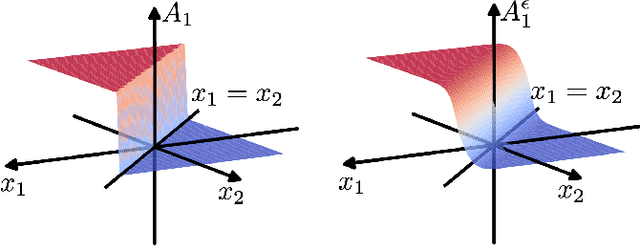
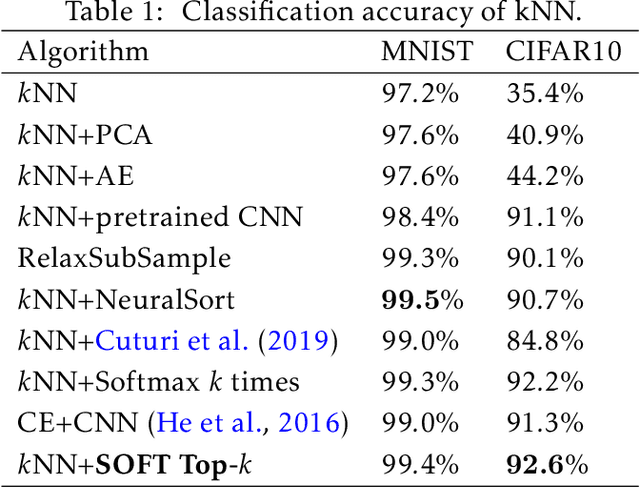

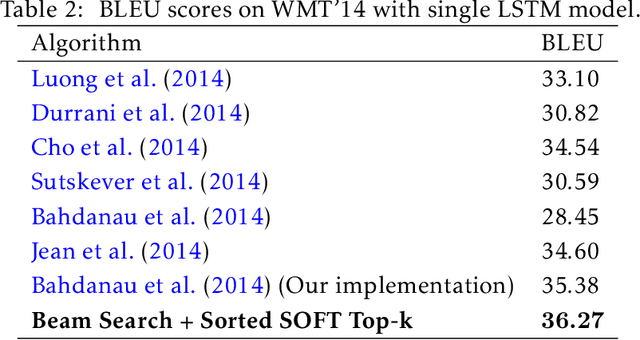
The top-k operation, i.e., finding the k largest or smallest elements from a collection of scores, is an important model component, which is widely used in information retrieval, machine learning, and data mining. However, if the top-k operation is implemented in an algorithmic way, e.g., using bubble algorithm, the resulting model cannot be trained in an end-to-end way using prevalent gradient descent algorithms. This is because these implementations typically involve swapping indices, whose gradient cannot be computed. Moreover, the corresponding mapping from the input scores to the indicator vector of whether this element belongs to the top-k set is essentially discontinuous. To address the issue, we propose a smoothed approximation, namely the SOFT (Scalable Optimal transport-based diFferenTiable) top-k operator. Specifically, our SOFT top-k operator approximates the output of the top-k operation as the solution of an Entropic Optimal Transport (EOT) problem. The gradient of the SOFT operator can then be efficiently approximated based on the optimality conditions of EOT problem. We apply the proposed operator to the k-nearest neighbors and beam search algorithms, and demonstrate improved performance.
Why Do Deep Residual Networks Generalize Better than Deep Feedforward Networks? -- A Neural Tangent Kernel Perspective
Feb 14, 2020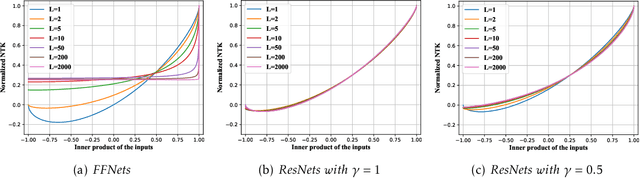
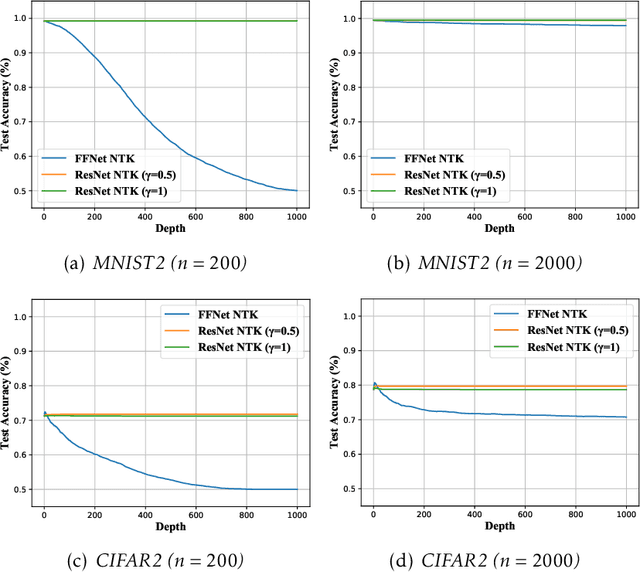
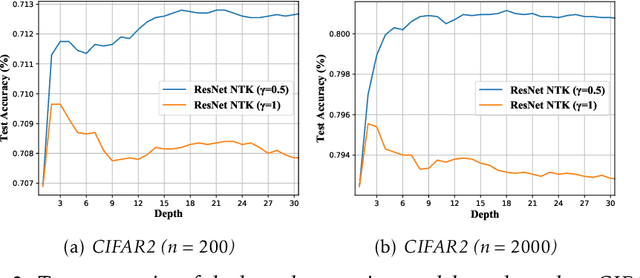
Deep residual networks (ResNets) have demonstrated better generalization performance than deep feedforward networks (FFNets). However, the theory behind such a phenomenon is still largely unknown. This paper studies this fundamental problem in deep learning from a so-called "neural tangent kernel" perspective. Specifically, we first show that under proper conditions, as the width goes to infinity, training deep ResNets can be viewed as learning reproducing kernel functions with some kernel function. We then compare the kernel of deep ResNets with that of deep FFNets and discover that the class of functions induced by the kernel of FFNets is asymptotically not learnable, as the depth goes to infinity. In contrast, the class of functions induced by the kernel of ResNets does not exhibit such degeneracy. Our discovery partially justifies the advantages of deep ResNets over deep FFNets in generalization abilities. Numerical results are provided to support our claim.
Statistical Guarantees of Generative Adversarial Networks for Distribution Estimation
Feb 10, 2020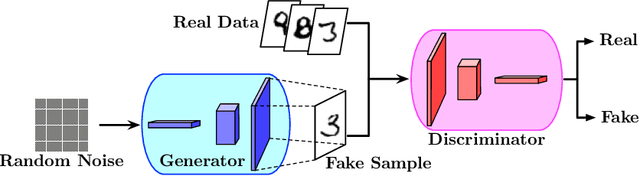
Generative Adversarial Networks (GANs) have achieved great success in unsupervised learning. Despite the remarkable empirical performance, there are limited theoretical understandings on the statistical properties of GANs. This paper provides statistical guarantees of GANs for the estimation of data distributions which have densities in a H\"{o}lder space. Our main result shows that, if the generator and discriminator network architectures are properly chosen (universally for all distributions with H\"{o}lder densities), GANs are consistent estimators of the data distributions under strong discrepancy metrics, such as the Wasserstein distance. To our best knowledge, this is the first statistical theory of GANs for H\"{o}lder densities. In comparison with existing works, our theory requires minimum assumptions on data distributions. Our generator and discriminator networks utilize general weight matrices and the non-invertible ReLU activation function, while many existing works only apply to invertible weight matrices and invertible activation functions. In our analysis, we decompose the error into a statistical error and an approximation error by a new oracle inequality, which may be of independent interest.
On Computation and Generalization of Generative Adversarial Imitation Learning
Jan 12, 2020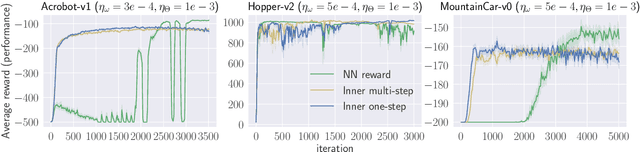
Generative Adversarial Imitation Learning (GAIL) is a powerful and practical approach for learning sequential decision-making policies. Different from Reinforcement Learning (RL), GAIL takes advantage of demonstration data by experts (e.g., human), and learns both the policy and reward function of the unknown environment. Despite the significant empirical progresses, the theory behind GAIL is still largely unknown. The major difficulty comes from the underlying temporal dependency of the demonstration data and the minimax computational formulation of GAIL without convex-concave structure. To bridge such a gap between theory and practice, this paper investigates the theoretical properties of GAIL. Specifically, we show: (1) For GAIL with general reward parameterization, the generalization can be guaranteed as long as the class of the reward functions is properly controlled; (2) For GAIL, where the reward is parameterized as a reproducing kernel function, GAIL can be efficiently solved by stochastic first order optimization algorithms, which attain sublinear convergence to a stationary solution. To the best of our knowledge, these are the first results on statistical and computational guarantees of imitation learning with reward/policy function approximation. Numerical experiments are provided to support our analysis.
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization
Nov 08, 2019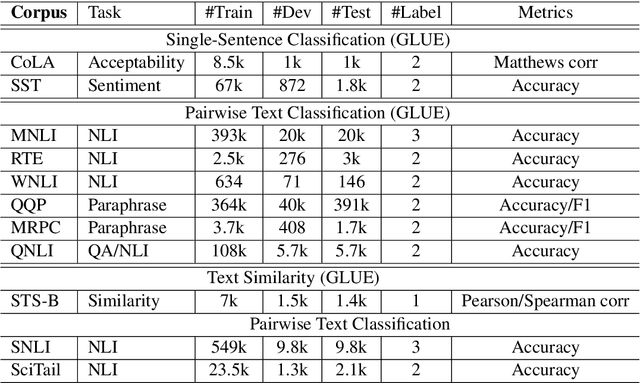
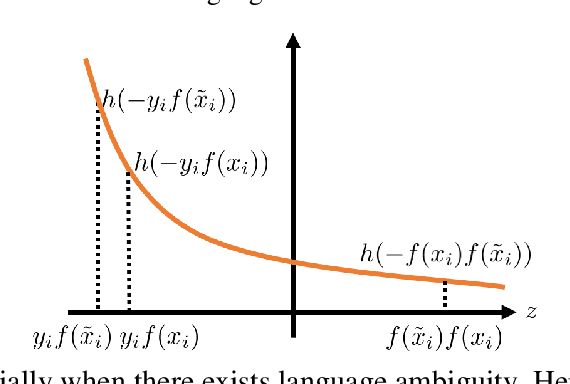
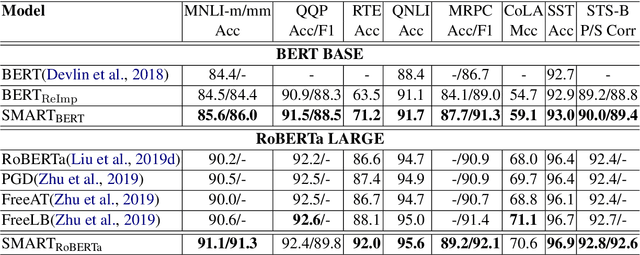
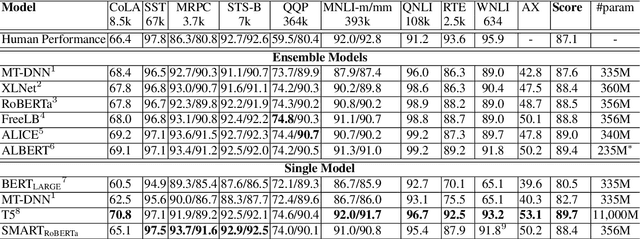
Transfer learning has fundamentally changed the landscape of natural language processing (NLP) research. Many existing state-of-the-art models are first pre-trained on a large text corpus and then fine-tuned on downstream tasks. However, due to limited data resources from downstream tasks and the extremely large capacity of pre-trained models, aggressive fine-tuning often causes the adapted model to overfit the data of downstream tasks and forget the knowledge of the pre-trained model. To address the above issue in a more principled manner, we propose a new computational framework for robust and efficient fine-tuning for pre-trained language models. Specifically, our proposed framework contains two important ingredients: 1. Smoothness-inducing regularization, which effectively manages the capacity of the model; 2. Bregman proximal point optimization, which is a class of trust-region methods and can prevent knowledge forgetting. Our experiments demonstrate that our proposed method achieves the state-of-the-art performance on multiple NLP benchmarks.