 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-guided 3D Human Generation from 2D Collections
May 23, 2023



3D human modeling has been widely used for engaging interaction in gaming, film, and animation. The customization of these characters is crucial for creativity and scalability, which highlights the importance of controllability. In this work, we introduce Text-guided 3D Human Generation (\texttt{T3H}), where a model is to generate a 3D human, guided by the fashion description. There are two goals: 1) the 3D human should render articulately, and 2) its outfit is controlled by the given text. To address this \texttt{T3H} task, we propose Compositional Cross-modal Human (CCH). CCH adopts cross-modal attention to fuse compositional human rendering with the extracted fashion semantics. Each human body part perceives relevant textual guidance as its visual patterns. We incorporate the human prior and semantic discrimination to enhance 3D geometry transformation and fine-grained consistency, enabling it to learn from 2D collections for data efficiency. We conduct evaluations on DeepFashion and SHHQ with diverse fashion attributes covering the shape, fabric, and color of upper and lower clothing. Extensive experiments demonstrate that CCH achieves superior results for \texttt{T3H} with high efficiency.
Collaborative Generative AI: Integrating GPT-k for Efficient Editing in Text-to-Image Generation
May 18, 2023



The field of text-to-image (T2I) generation has garnered significant attention both within the research community and among everyday users. Despite the advancements of T2I models, a common issue encountered by users is the need for repetitive editing of input prompts in order to receive a satisfactory image, which is time-consuming and labor-intensive. Given the demonstrated text generation power of large-scale language models, such as GPT-k, we investigate the potential of utilizing such models to improve the prompt editing process for T2I generation. We conduct a series of experiments to compare the common edits made by humans and GPT-k, evaluate the performance of GPT-k in prompting T2I, and examine factors that may influence this process. We found that GPT-k models focus more on inserting modifiers while humans tend to replace words and phrases, which includes changes to the subject matter. Experimental results show that GPT-k are more effective in adjusting modifiers rather than predicting spontaneous changes in the primary subject matters. Adopting the edit suggested by GPT-k models may reduce the percentage of remaining edits by 20-30%.
Discriminative Diffusion Models as Few-shot Vision and Language Learners
May 18, 2023



Diffusion models, such as Stable Diffusion, have shown incredible performance on text-to-image generation. Since text-to-image generation often requires models to generate visual concepts with fine-grained details and attributes specified in text prompts, can we leverage the powerful representations learned by pre-trained diffusion models for discriminative tasks such as image-text matching? To answer this question, we propose a novel approach, Discriminative Stable Diffusion (DSD), which turns pre-trained text-to-image diffusion models into few-shot discriminative learners. Our approach uses the cross-attention score of a Stable Diffusion model to capture the mutual influence between visual and textual information and fine-tune the model via attention-based prompt learning to perform image-text matching. By comparing DSD with state-of-the-art methods on several benchmark datasets, we demonstrate the potential of using pre-trained diffusion models for discriminative tasks with superior results on few-shot image-text matching.
Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis
Dec 09, 2022



Large-scale diffusion models have achieved state-of-the-art results on text-to-image synthesis (T2I) tasks. Despite their ability to generate high-quality yet creative images, we observe that attribution-binding and compositional capabilities are still considered major challenging issues, especially when involving multiple objects. In this work, we improve the compositional skills of T2I models, specifically more accurate attribute binding and better image compositions. To do this, we incorporate linguistic structures with the diffusion guidance process based on the controllable properties of manipulating cross-attention layers in diffusion-based T2I models. We observe that keys and values in cross-attention layers have strong semantic meanings associated with object layouts and content. Therefore, we can better preserve the compositional semantics in the generated image by manipulating the cross-attention representations based on linguistic insights. Built upon Stable Diffusion, a SOTA T2I model, our structured cross-attention design is efficient that requires no additional training samples. We achieve better compositional skills in qualitative and quantitative results, leading to a 5-8% advantage in head-to-head user comparison studies. Lastly, we conduct an in-depth analysis to reveal potential causes of incorrect image compositions and justify the properties of cross-attention layers in the generation process.
Tell Me What Happened: Unifying Text-guided Video Completion via Multimodal Masked Video Generation
Nov 23, 2022Generating a video given the first several static frames is challenging as it anticipates reasonable future frames with temporal coherence. Besides video prediction, the ability to rewind from the last frame or infilling between the head and tail is also crucial, but they have rarely been explored for video completion. Since there could be different outcomes from the hints of just a few frames, a system that can follow natural language to perform video completion may significantly improve controllability. Inspired by this, we introduce a novel task, text-guided video completion (TVC), which requests the model to generate a video from partial frames guided by an instruction. We then propose Multimodal Masked Video Generation (MMVG) to address this TVC task. During training, MMVG discretizes the video frames into visual tokens and masks most of them to perform video completion from any time point. At inference time, a single MMVG model can address all 3 cases of TVC, including video prediction, rewind, and infilling, by applying corresponding masking conditions. We evaluate MMVG in various video scenarios, including egocentric, animation, and gaming. Extensive experimental results indicate that MMVG is effective in generating high-quality visual appearances with text guidance for TVC.
CPL: Counterfactual Prompt Learning for Vision and Language Models
Oct 19, 2022
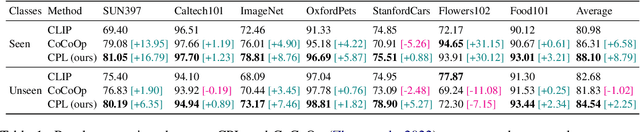
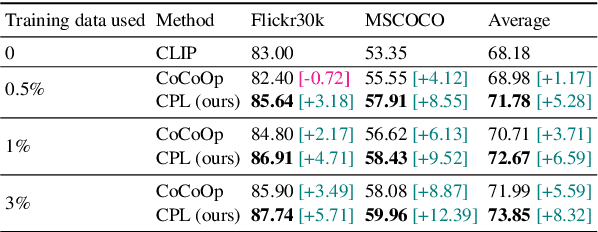
Prompt tuning is a new few-shot transfer learning technique that only tunes the learnable prompt for pre-trained vision and language models such as CLIP. However, existing prompt tuning methods tend to learn spurious or entangled representations, which leads to poor generalization to unseen concepts. Towards non-spurious and efficient prompt learning from limited examples, this paper presents a novel \underline{\textbf{C}}ounterfactual \underline{\textbf{P}}rompt \underline{\textbf{L}}earning (CPL) method for vision and language models, which simultaneously employs counterfactual generation and contrastive learning in a joint optimization framework. Particularly, CPL constructs counterfactual by identifying minimal non-spurious feature change between semantically-similar positive and negative samples that causes concept change, and learns more generalizable prompt representation from both factual and counterfactual examples via contrastive learning. Extensive experiments demonstrate that CPL can obtain superior few-shot performance on different vision and language tasks than previous prompt tuning methods on CLIP. On image classification, we achieve 3.55\% average relative improvement on unseen classes across seven datasets; on image-text retrieval and visual question answering, we gain up to 4.09\% and 25.08\% relative improvements across three few-shot scenarios on unseen test sets respectively.
ULN: Towards Underspecified Vision-and-Language Navigation
Oct 18, 2022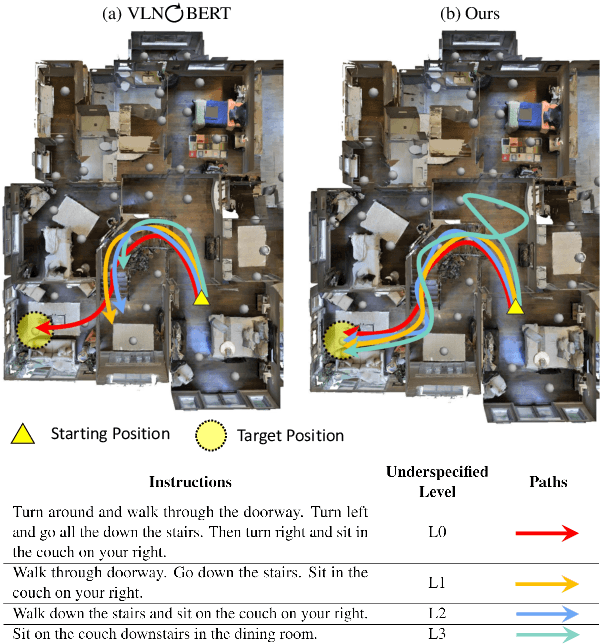

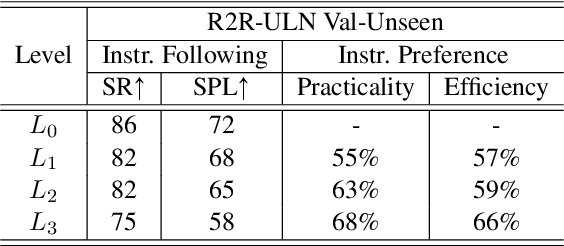
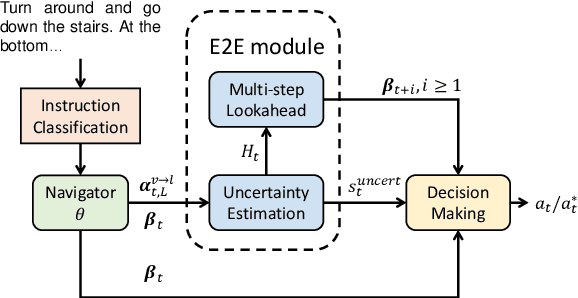
Vision-and-Language Navigation (VLN) is a task to guide an embodied agent moving to a target position using language instructions. Despite the significant performance improvement, the wide use of fine-grained instructions fails to characterize more practical linguistic variations in reality. To fill in this gap, we introduce a new setting, namely Underspecified vision-and-Language Navigation (ULN), and associated evaluation datasets. ULN evaluates agents using multi-level underspecified instructions instead of purely fine-grained or coarse-grained, which is a more realistic and general setting. As a primary step toward ULN, we propose a VLN framework that consists of a classification module, a navigation agent, and an Exploitation-to-Exploration (E2E) module. Specifically, we propose to learn Granularity Specific Sub-networks (GSS) for the agent to ground multi-level instructions with minimal additional parameters. Then, our E2E module estimates grounding uncertainty and conducts multi-step lookahead exploration to improve the success rate further. Experimental results show that existing VLN models are still brittle to multi-level language underspecification. Our framework is more robust and outperforms the baselines on ULN by ~10% relative success rate across all levels.
An Empirical Study of End-to-End Video-Language Transformers with Masked Visual Modeling
Sep 04, 2022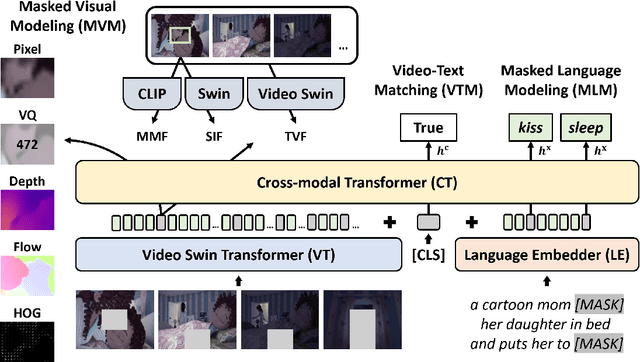
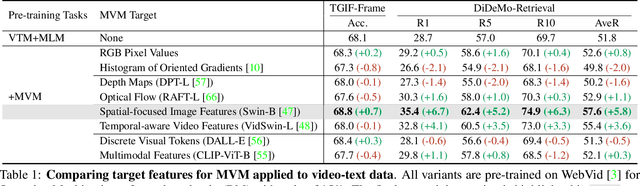
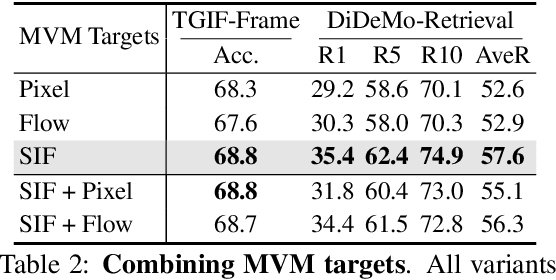

Masked visual modeling (MVM) has been recently proven effective for visual pre-training. While similar reconstructive objectives on video inputs (e.g., masked frame modeling) have been explored in video-language (VidL) pre-training, the pre-extracted video features in previous studies cannot be refined through MVM during pre-training, and thus leading to unsatisfactory downstream performance. In this work, we systematically examine the potential of MVM in the context of VidL learning. Specifically, we base our study on a fully end-to-end VIdeO-LanguagE Transformer (VIOLET), which mitigates the disconnection between fixed video representations and MVM training. In total, eight different reconstructive targets of MVM are explored, from low-level pixel values and oriented gradients to high-level depth maps, optical flow, discrete visual tokens and latent visual features. We conduct comprehensive experiments and provide insights on the factors leading to effective MVM training. Empirically, we show VIOLET pre-trained with MVM objective achieves notable improvements on 13 VidL benchmarks, ranging from video question answering, video captioning, to text-to-video retrieval.
VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling
Nov 24, 2021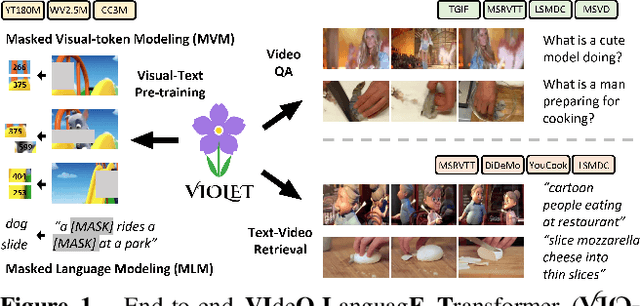
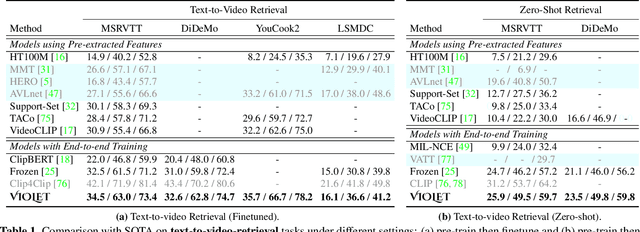
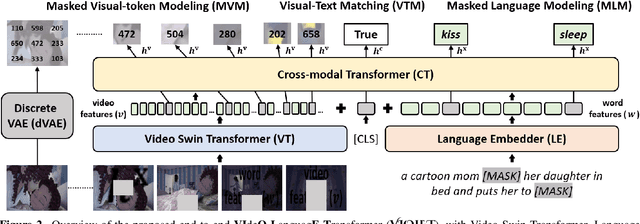
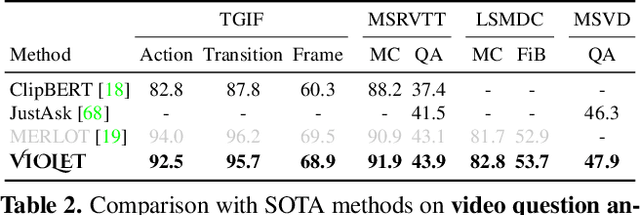
A great challenge in video-language (VidL) modeling lies in the disconnection between fixed video representations extracted from image/video understanding models and downstream VidL data. Recent studies try to mitigate this disconnection via end-to-end training. To make it computationally feasible, prior works tend to "imagify" video inputs, i.e., a handful of sparsely sampled frames are fed into a 2D CNN, followed by a simple mean-pooling or concatenation to obtain the overall video representations. Although achieving promising results, such simple approaches may lose temporal information that is essential for performing downstream VidL tasks. In this work, we present VIOLET, a fully end-to-end VIdeO-LanguagE Transformer, which adopts a video transformer to explicitly model the temporal dynamics of video inputs. Further, unlike previous studies that found pre-training tasks on video inputs (e.g., masked frame modeling) not very effective, we design a new pre-training task, Masked Visual-token Modeling (MVM), for better video modeling. Specifically, the original video frame patches are "tokenized" into discrete visual tokens, and the goal is to recover the original visual tokens based on the masked patches. Comprehensive analysis demonstrates the effectiveness of both explicit temporal modeling via video transformer and MVM. As a result, VIOLET achieves new state-of-the-art performance on 5 video question answering tasks and 4 text-to-video retrieval tasks.
Language-Driven Image Style Transfer
Jun 01, 2021
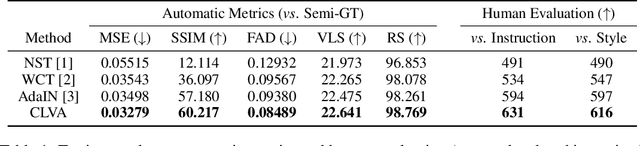
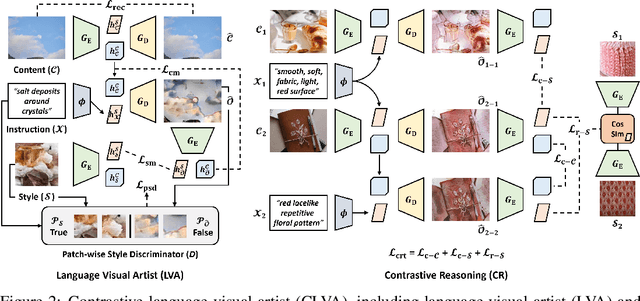
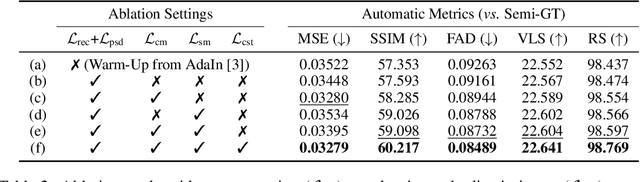
Despite having promising results, style transfer, which requires preparing style images in advance, may result in lack of creativity and accessibility. Following human instruction, on the other hand, is the most natural way to perform artistic style transfer that can significantly improve controllability for visual effect applications. We introduce a new task -- language-driven image style transfer (\texttt{LDIST}) -- to manipulate the style of a content image, guided by a text. We propose contrastive language visual artist (CLVA) that learns to extract visual semantics from style instructions and accomplish \texttt{LDIST} by the patch-wise style discriminator. The discriminator considers the correlation between language and patches of style images or transferred results to jointly embed style instructions. CLVA further compares contrastive pairs of content image and style instruction to improve the mutual relativeness between transfer results. The transferred results from the same content image can preserve consistent content structures. Besides, they should present analogous style patterns from style instructions that contain similar visual semantics. The experiments show that our CLVA is effective and achieves superb transferred results on \texttt{LDIST}.