 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuxiliary Task Reweighting for Minimum-data Learning
Oct 16, 2020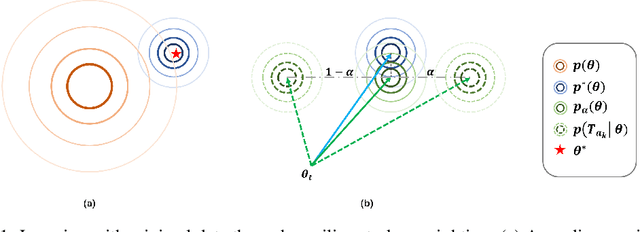
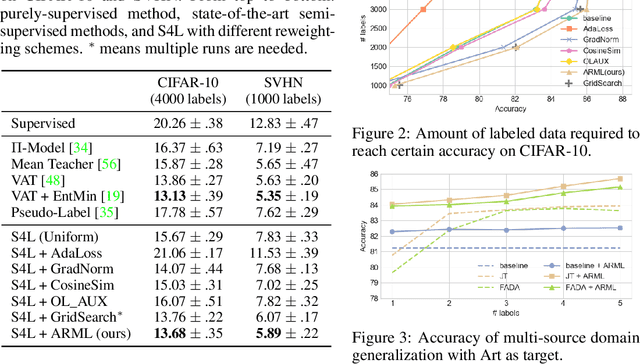
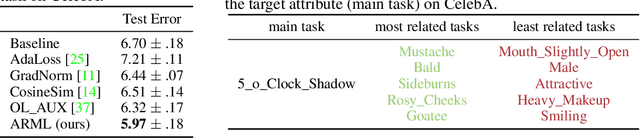
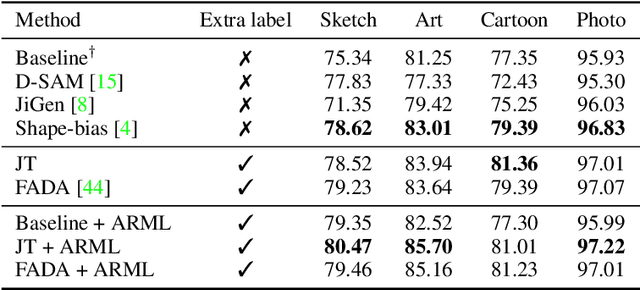
Supervised learning requires a large amount of training data, limiting its application where labeled data is scarce. To compensate for data scarcity, one possible method is to utilize auxiliary tasks to provide additional supervision for the main task. Assigning and optimizing the importance weights for different auxiliary tasks remains an crucial and largely understudied research question. In this work, we propose a method to automatically reweight auxiliary tasks in order to reduce the data requirement on the main task. Specifically, we formulate the weighted likelihood function of auxiliary tasks as a surrogate prior for the main task. By adjusting the auxiliary task weights to minimize the divergence between the surrogate prior and the true prior of the main task, we obtain a more accurate prior estimation, achieving the goal of minimizing the required amount of training data for the main task and avoiding a costly grid search. In multiple experimental settings (e.g. semi-supervised learning, multi-label classification), we demonstrate that our algorithm can effectively utilize limited labeled data of the main task with the benefit of auxiliary tasks compared with previous task reweighting methods. We also show that under extreme cases with only a few extra examples (e.g. few-shot domain adaptation), our algorithm results in significant improvement over the baseline.
Learning Invariant Representations and Risks for Semi-supervised Domain Adaptation
Oct 12, 2020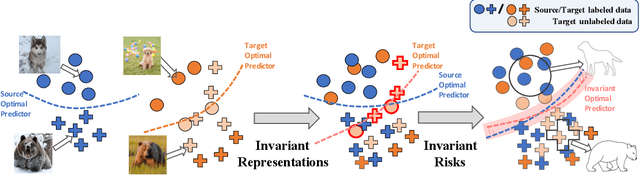
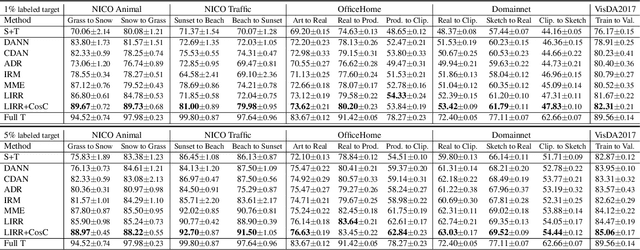
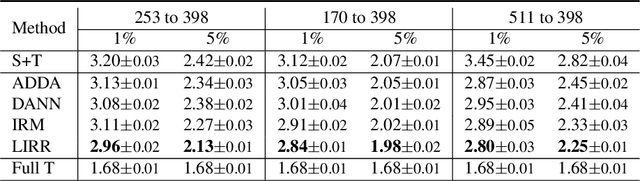
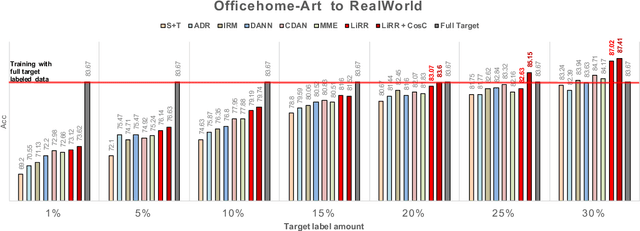
The success of supervised learning hinges on the assumption that the training and test data come from the same underlying distribution, which is often not valid in practice due to potential distribution shift. In light of this, most existing methods for unsupervised domain adaptation focus on achieving domain-invariant representations and small source domain error. However, recent works have shown that this is not sufficient to guarantee good generalization on the target domain, and in fact, is provably detrimental under label distribution shift. Furthermore, in many real-world applications it is often feasible to obtain a small amount of labeled data from the target domain and use them to facilitate model training with source data. Inspired by the above observations, in this paper we propose the first method that aims to simultaneously learn invariant representations and risks under the setting of semi-supervised domain adaptation (Semi-DA). First, we provide a finite sample bound for both classification and regression problems under Semi-DA. The bound suggests a principled way to obtain target generalization, i.e. by aligning both the marginal and conditional distributions across domains in feature space. Motivated by this, we then introduce the LIRR algorithm for jointly \textbf{L}earning \textbf{I}nvariant \textbf{R}epresentations and \textbf{R}isks. Finally, extensive experiments are conducted on both classification and regression tasks, which demonstrates LIRR consistently achieves state-of-the-art performance and significant improvements compared with the methods that only learn invariant representations or invariant risks.
Remembering for the Right Reasons: Explanations Reduce Catastrophic Forgetting
Oct 04, 2020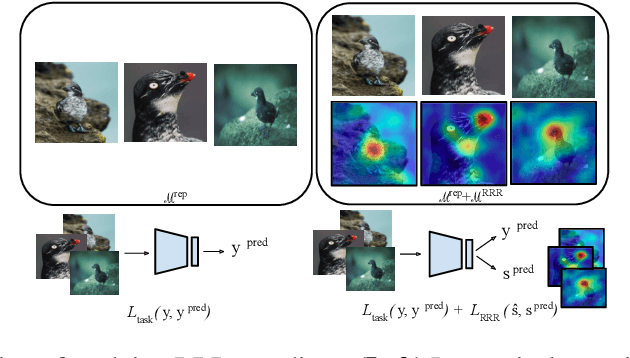

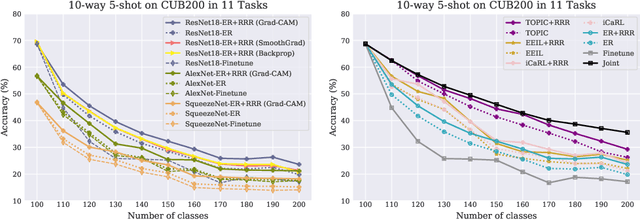

The goal of continual learning (CL) is to learn a sequence of tasks without suffering from the phenomenon of catastrophic forgetting. Previous work has shown that leveraging memory in the form of a replay buffer can reduce performance degradation on prior tasks. We hypothesize that forgetting can be further reduced when the model is encouraged to remember the \textit{evidence} for previously made decisions. As a first step towards exploring this hypothesis, we propose a simple novel training paradigm, called Remembering for the Right Reasons (RRR), that additionally stores visual model explanations for each example in the buffer and ensures the model has "the right reasons" for its predictions by encouraging its explanations to remain consistent with those used to make decisions at training time. Without this constraint, there is a drift in explanations and increase in forgetting as conventional continual learning algorithms learn new tasks. We demonstrate how RRR can be easily added to any memory or regularization-based approach and results in reduced forgetting, and more importantly, improved model explanations. We have evaluated our approach in the standard and few-shot settings and observed a consistent improvement across various CL approaches using different architectures and techniques to generate model explanations and demonstrated our approach showing a promising connection between explainability and continual learning. Our code is available at https://github.com/SaynaEbrahimi/Remembering-for-the-Right-Reasons.
Evaluating Self-Supervised Pretraining Without Using Labels
Sep 16, 2020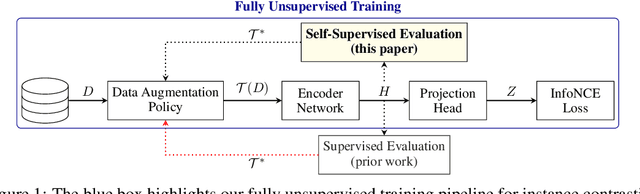
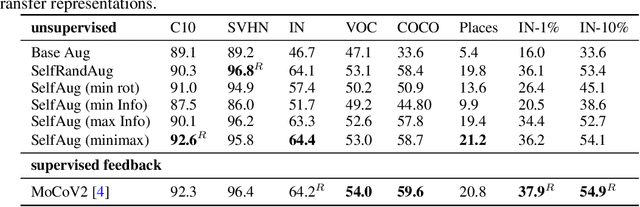
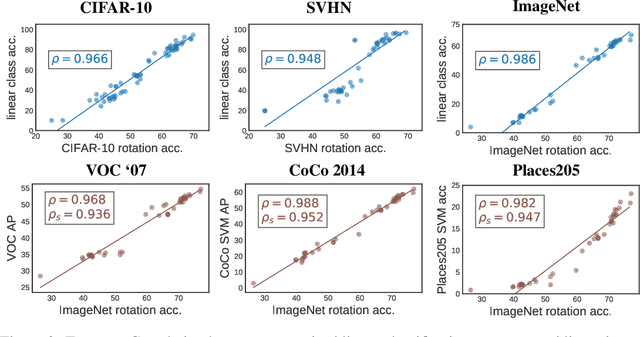
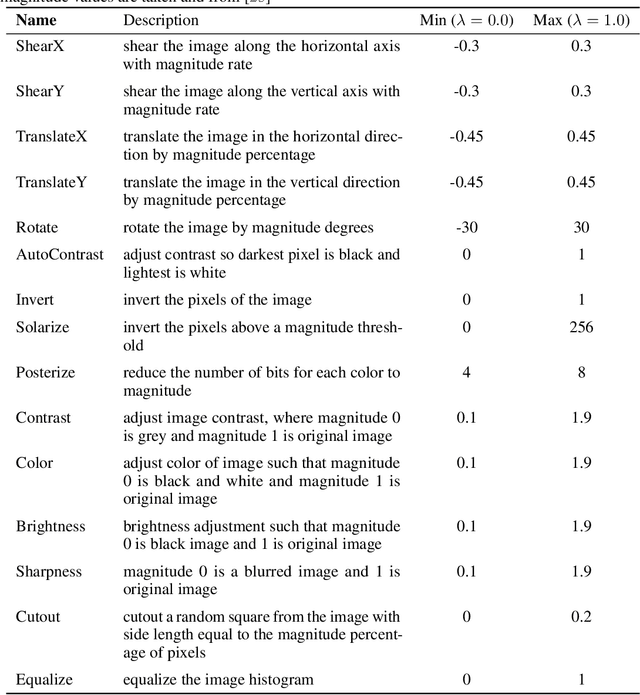
A common practice in unsupervised representation learning is to use labeled data to evaluate the learned representations - oftentimes using the labels from the "unlabeled" training dataset. This supervised evaluation is then used to guide the training process, e.g. to select augmentation policies. However, supervised evaluations may not be possible when labeled data is difficult to obtain (such as medical imaging) or ambiguous to label (such as fashion categorization). This raises the question: is it possible to evaluate unsupervised models without using labeled data? Furthermore, is it possible to use this evaluation to make decisions about the training process, such as which augmentation policies to use? In this work, we show that the simple self-supervised evaluation task of image rotation prediction is highly correlated with the supervised performance of standard visual recognition tasks and datasets (rank correlation > 0.94). We establish this correlation across hundreds of augmentation policies and training schedules and show how this evaluation criteria can be used to automatically select augmentation policies without using labels. Despite not using any labeled data, these policies perform comparably with policies that were determined using supervised downstream tasks. Importantly, this work explores the idea of using unsupervised evaluation criteria to help both researchers and practitioners make decisions when training without labeled data.
ePointDA: An End-to-End Simulation-to-Real Domain Adaptation Framework for LiDAR Point Cloud Segmentation
Sep 07, 2020
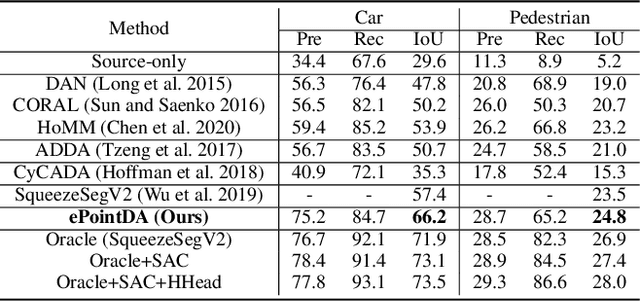
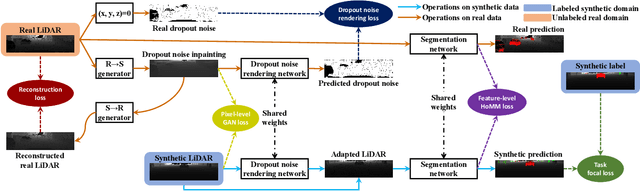
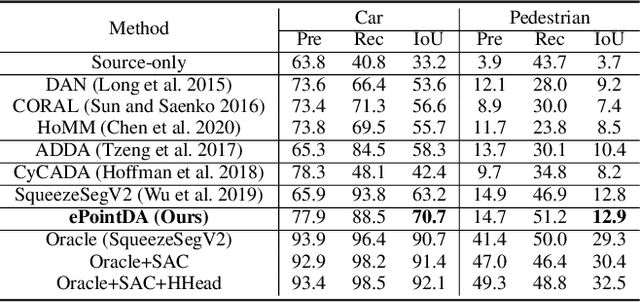
Due to its robust and precise distance measurements, LiDAR plays an important role in scene understanding for autonomous driving. Training deep neural networks (DNNs) on LiDAR data requires large-scale point-wise annotations, which are time-consuming and expensive to obtain. Instead, simulation-to-real domain adaptation (SRDA) trains a DNN using unlimited synthetic data with automatically generated labels and transfers the learned model to real scenarios. Existing SRDA methods for LiDAR point cloud segmentation mainly employ a multi-stage pipeline and focus on feature-level alignment. They require prior knowledge of real-world statistics and ignore the pixel-level dropout noise gap and the spatial feature gap between different domains. In this paper, we propose a novel end-to-end framework, named ePointDA, to address the above issues. Specifically, ePointDA consists of three components: self-supervised dropout noise rendering, statistics-invariant and spatially-adaptive feature alignment, and transferable segmentation learning. The joint optimization enables ePointDA to bridge the domain shift at the pixel-level by explicitly rendering dropout noise for synthetic LiDAR and at the feature-level by spatially aligning the features between different domains, without requiring the real-world statistics. Extensive experiments adapting from synthetic GTA-LiDAR to real KITTI and SemanticKITTI demonstrate the superiority of ePointDA for LiDAR point cloud segmentation.
Hierarchical Style-based Networks for Motion Synthesis
Aug 24, 2020

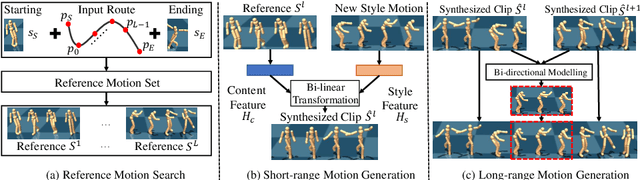
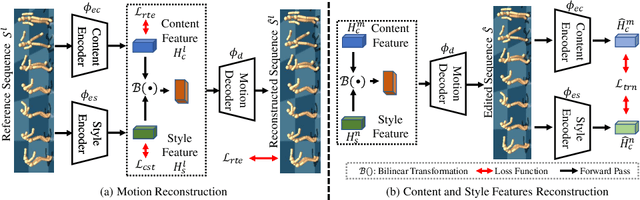
Generating diverse and natural human motion is one of the long-standing goals for creating intelligent characters in the animated world. In this paper, we propose a self-supervised method for generating long-range, diverse and plausible behaviors to achieve a specific goal location. Our proposed method learns to model the motion of human by decomposing a long-range generation task in a hierarchical manner. Given the starting and ending states, a memory bank is used to retrieve motion references as source material for short-range clip generation. We first propose to explicitly disentangle the provided motion material into style and content counterparts via bi-linear transformation modelling, where diverse synthesis is achieved by free-form combination of these two components. The short-range clips are then connected to form a long-range motion sequence. Without ground truth annotation, we propose a parameterized bi-directional interpolation scheme to guarantee the physical validity and visual naturalness of generated results. On large-scale skeleton dataset, we show that the proposed method is able to synthesise long-range, diverse and plausible motion, which is also generalizable to unseen motion data during testing. Moreover, we demonstrate the generated sequences are useful as subgoals for actual physical execution in the animated world.
Identity-Aware Multi-Sentence Video Description
Aug 22, 2020
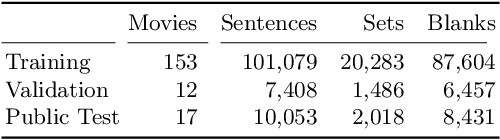


Standard video and movie description tasks abstract away from person identities, thus failing to link identities across sentences. We propose a multi-sentence Identity-Aware Video Description task, which overcomes this limitation and requires to re-identify persons locally within a set of consecutive clips. We introduce an auxiliary task of Fill-in the Identity, that aims to predict persons' IDs consistently within a set of clips, when the video descriptions are given. Our proposed approach to this task leverages a Transformer architecture allowing for coherent joint prediction of multiple IDs. One of the key components is a gender-aware textual representation as well an additional gender prediction objective in the main model. This auxiliary task allows us to propose a two-stage approach to Identity-Aware Video Description. We first generate multi-sentence video descriptions, and then apply our Fill-in the Identity model to establish links between the predicted person entities. To be able to tackle both tasks, we augment the Large Scale Movie Description Challenge (LSMDC) benchmark with new annotations suited for our problem statement. Experiments show that our proposed Fill-in the Identity model is superior to several baselines and recent works, and allows us to generate descriptions with locally re-identified people.
What Should Not Be Contrastive in Contrastive Learning
Aug 13, 2020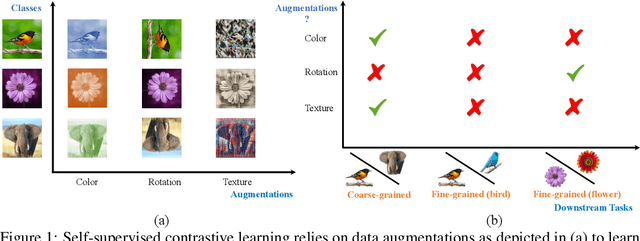
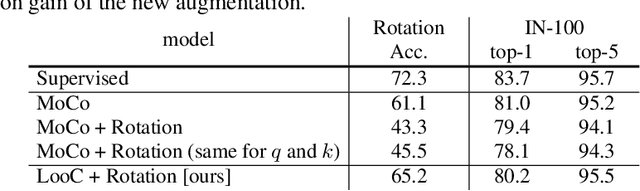
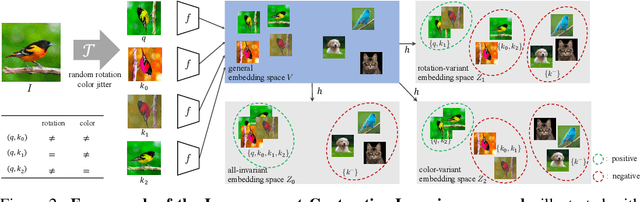
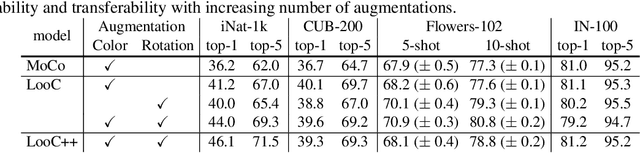
Recent self-supervised contrastive methods have been able to produce impressive transferable visual representations by learning to be invariant to different data augmentations. However, these methods implicitly assume a particular set of representational invariances (e.g., invariance to color), and can perform poorly when a downstream task violates this assumption (e.g., distinguishing red vs. yellow cars). We introduce a contrastive learning framework which does not require prior knowledge of specific, task-dependent invariances. Our model learns to capture varying and invariant factors for visual representations by constructing separate embedding spaces, each of which is invariant to all but one augmentation. We use a multi-head network with a shared backbone which captures information across each augmentation and alone outperforms all baselines on downstream tasks. We further find that the concatenation of the invariant and varying spaces performs best across all tasks we investigate, including coarse-grained, fine-grained, and few-shot downstream classification tasks, and various data corruptions.
Body2Hands: Learning to Infer 3D Hands from Conversational Gesture Body Dynamics
Jul 23, 2020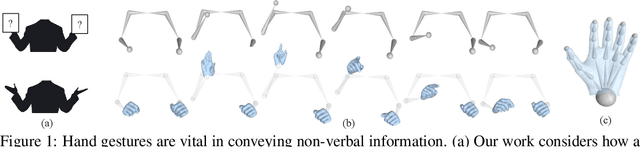
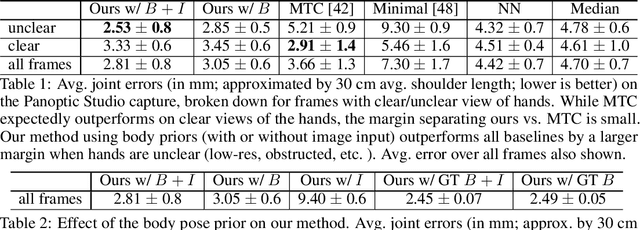
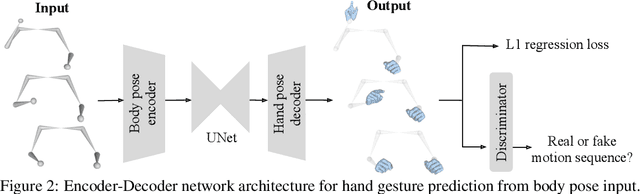
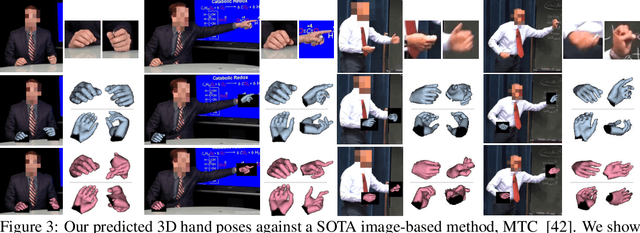
We propose a novel learned deep prior of body motion for 3D hand shape synthesis and estimation in the domain of conversational gestures. Our model builds upon the insight that body motion and hand gestures are strongly correlated in non-verbal communication settings. We formulate the learning of this prior as a prediction task of 3D hand shape over time given body motion input alone. Trained with 3D pose estimations obtained from a large-scale dataset of internet videos, our hand prediction model produces convincing 3D hand gestures given only the 3D motion of the speaker's arms as input. We demonstrate the efficacy of our method on hand gesture synthesis from body motion input, and as a strong body prior for single-view image-based 3D hand pose estimation. We demonstrate that our method outperforms previous state-of-the-art approaches and can generalize beyond the monologue-based training data to multi-person conversations. Video results are available at http://people.eecs.berkeley.edu/~evonne_ng/projects/body2hands/.
Seeing the Un-Scene: Learning Amodal Semantic Maps for Room Navigation
Jul 20, 2020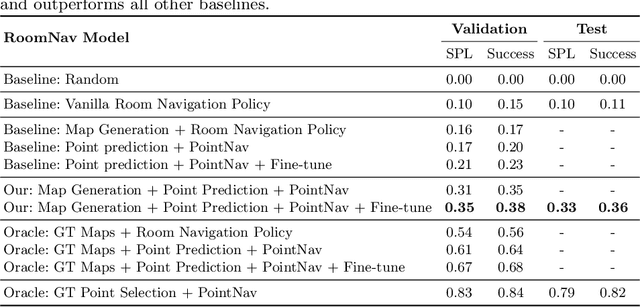
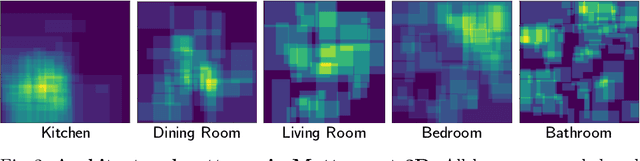
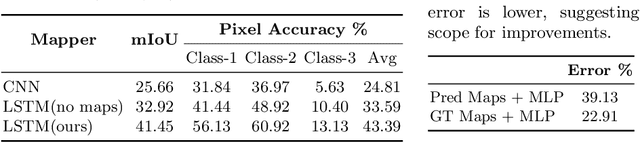
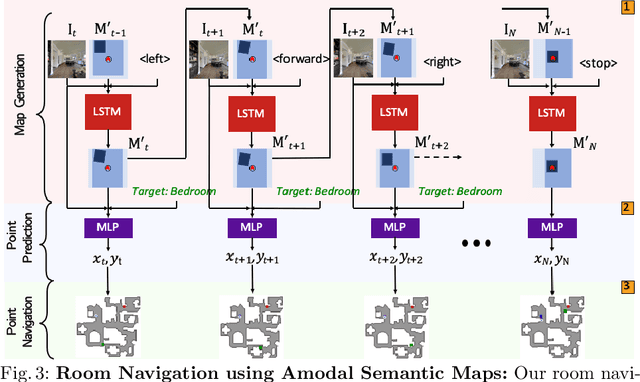
We introduce a learning-based approach for room navigation using semantic maps. Our proposed architecture learns to predict top-down belief maps of regions that lie beyond the agent's field of view while modeling architectural and stylistic regularities in houses. First, we train a model to generate amodal semantic top-down maps indicating beliefs of location, size, and shape of rooms by learning the underlying architectural patterns in houses. Next, we use these maps to predict a point that lies in the target room and train a policy to navigate to the point. We empirically demonstrate that by predicting semantic maps, the model learns common correlations found in houses and generalizes to novel environments. We also demonstrate that reducing the task of room navigation to point navigation improves the performance further.